







- 链表是一种数据结构,是一种数据存放的方式
- 链表是由结构体形成的,每个结构体内部有一个结构体指针指向下一个结构体,结构体的存储地址不连续
-------------结构体A----------- ------------结构体B-----------
| | | \ | | |
| data | *next |--------------| data | *next |
| | | / | | |
------------------------------ ------------------------------
结构体A中的结构体指针NEXT存放了结构体B的地址
struct Node{
int data; //链表中元素数据
struct Node *next; //元素中存放下一个元素的地址
}*pNode,node ;
- 将结构体中的结构体指针指向下一个同类型的结构体,直到链接所有的指定的结构体,这就是链表。最后一个元素中的指针指向NULL
struct Node head = {1,&dot1};
struct Node dot1 = {2,&dot2};
struct Node dot2 = {3,&dot3};
struct Node dot3 = {4,NULL};
- 相对于数组,具有更加灵活的数据更改能力(包括增,减内部元素),只需要将NEXT指针指向指定的下一个结构体,后面顺序依然保持不变
链表遍历
因为链表每个元素中都有一个指向自己结构体类型的指针,且这个指针指向下一个元素。设一个该结构体指针sign指向头节点(第一个节点),对其操作完成后,sign指针指向头节点中的结构体指针指向的位置(sign指针移动到了下一个结点),以此类推,直到指针指向尾节点的next指针指向的NULL,遍历结束。
struct Node *sign = &head;
while(sign != NULL){
printf("%d\t",sign->data);
sign = sign->next;
}
*对链表的查找和节点统计也是相同道理
节点增加
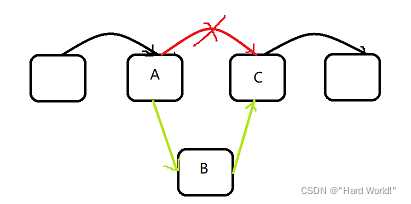
节点的增加主要通过改变节点的结构体指针来实现,如下图下方节点B插入A,C节点之间
- 先将A中next指向的地址给B的next指针
- 再将A的next指向B节点
两个语句的顺序不能改变
后插
新节点加在指定节点后方,同样需要遍历链表,如当前节点是否是指定的节点,就将当前节点的next赋值给新节点的next,再将当前节点的next指向新节点
void insertNode(struct Node *p, struct Node *new, int position){
while(p != NULL){
if(p->data == position){
new->next = p->next; //节点添加
p->next = new;
return;
}
p=p->next; //移动到下一个节点
}
assert(false); //没有改节点,错误退出
return;
}
前插
这是需要考虑,当添加位置是链表第一个节点时,此时需要更换链表的头节点,如下实验代码对头节点进行单独判断,这里犯了个错误,指针变量在函数中的改变,不会影响该变量在main中的指针变量(多思考理解)。为了改变指针,这里需要使用二级指针,将指针的地址传进来,再改变二级指针以至于指针改变,将头结点指针指向新的节点
//错误示范
void insertNode(pNode p, pNode new, int posit){
if(posit == 1){
new->next = p;
return ;
}
while(p->next != NULL){
if(p->next->data == posit){
new->next = p->next;
p->next = new;
return;
}
p=p->next;
}
puts("no such position for inserting! ");
return;
}
二级指针实现
在main中定义一个指向头结点的指针phead,将其地址传递给函数。函数得到的是一个二级指针,指向一个指针,该指针指向节点,cur等价于head,方便理解。循环遍历整个链表,直至指向节点的指针指向空NULL(*cur != NULL;);
如果当前节点中的数据匹配,此时要将一个新的节点放当前节点前面,所以新节点的next存储当前节点的地址(new->next = *cur),重点是要让指向当前节点的指针指向新节点,因为使用的二级指针,所以取二级指针的内容就可以改动main中指向节点的指针了【这个指针等价于它前一个节点的next,因为上了一轮循环的最后将上一次节点的next(下次循环的节点地址)的地址赋给了二级指针】;
将新节点的地址(new指针变量存放的地址)给这个通过二级指针访问的一级指针(*cur = new)【后期看帮助理解:此时cur相当于head(两个二级指针),这个二级指针存放的地址是main中指向头结点的指针的地址 的复制品,但通过取它的值就可以访问带这个指向头节点的指针,以及后面的节点并更改该指针的方向(写这么多都在重复,也是为了重温时能有到多角度的引导,不懂要细看)】
pNode phead = &head; //main中的指针
void insertN(pNode *head,pNode new,int posit){
pNode *cur = head; //指向的指针指向头节点
while(*cur != NULL){ //指向节点的指针不为空就遍历
if((*cur)->data == posit){ //当前节点为插入节点
new->next = *cur; //当前节点的地址给新节点的next
/*这里注意跟cur = &new区别*/
*cur = new; //指向新节点的地址
return ;
}
/*不是指定的位置*/
cur = &((*cur)->next); //指向下一个节点的地址给二级指针指针
}
return ;
}
带返回值实现
使用返回值进行插入相对于二级指针要易理解一些,通过返回值就可以将头节点的指针返回到主函数中头节点。因为是在指定节点的前面插入,所以定义一个pre指针用来保存上一个节点,使用当前指针pCurrt遍历链表。
pNode insertReVa(pNode p,pNode new,int position){
pNode pCurrt = p;
pNode pre = NULL; //结构体指针用来存放当前节点的前一个节点
while(pCurrt != NULL){
if(pCurrt->data == position){
if(pre == NULL){ //前一个节点为空则为第一个节点
new->next = pCurrt; //添加头节点
return new;
}else{
new->next = pre->next; //插入节点
pre->next = new;
return p;
}
}
pre = pCurrt; //前节点等于当前节点,当前节点后移
pCurrt = pCurrt->next;
}
return p;
}
节点删除
二级指针实现
看懂了上面 节点增加->前插->二级指针法,这里就可以轻松理解了,方法是雷同的。不用添加新的节点,所以找到期望的位置就将指向当前节点的指针指向 当前节点的next的指向,这样就相当于上一个节点的next就跳过当前被删除的节点,直接指向下一个节点;
这里定义了一个结构体指针temp指向当前节点,链接了上一个节点与下一个节点后,对这个节点进行释放。
完成删除后,如果只用删除一个数,就可以直接返回;但如果需要删除所有相同的数就需要continue来跳过下一句的赋值:删掉节点后被指向的指针已经移到后一个节点,如果要删除的数在相邻的两个节点,就会出现漏删除,如果指定的数据在最后一个节点,就会造成非法访问。
void deletNode(pNode *head,int position){
pNode *cur = head;
while((*cur) != NULL){
if((*cur)->data == position){
pNode temp = *cur; //存放当前的节点
*cur = (*cur)->next;
free(temp); //释放被删除的当前节点
return; //删除链表中第一个指定数据的节点
//continue; //删除链表中所有这个数据的节点
}
cur = &((*cur)->next);
}
return;
}
*有一点注意,这里如果节点的定义不是通过malloc进行空间分配的而是普通变量,free()操作会导致其报错出现重复释放空间!
带返回值实现
这与插入的结构体指针返回法有一些不同,这里先对第一个节点进行了单独判断,非首个节点就对其下一个节点进行匹配,这样就不用定义一个结构体指针变量来记录前一个节点的地址
pNode deltNode(pNode head, int position){
pNode p = head;
pNode tmp = head; //记录要删除的节点为了将其释放
if(p->data == position){ //相对第一个值进行判断
p = p->next;
free(tmp);
return p;
}
while(p->next != NULL){
if(p->next->data == position){ //对下一个节点的值进行判断
tmp = p->next;
p->next = p->next->next;
free(tmp); //非malloc节点不可用
return head;
}
p = p->next;
}
puts("no such data!");
return head;
}
链表的动态创建
静态创建链表十分麻烦,且需要大篇幅的重复的内容,所以动态创建成了创建链表的必经路,同时动态创建又分为从头插入和从尾插入
头插法
带返回值实现
新插入的节点放在最前面,对当前头节点进行判断,如果为空,当前新节点就为头节点;另外头插函数还可以单独调用
/*头插法-返回值法*/
//头插实现
pNode insertHead(pNode head,pNode new){
if(head == NULL){ //无头节点则新节点为头
head = new;
}else{
new->next = head;
head = new; //新节点为头
}
return head;
}
//创建节点
pNode creatLnkList(pNode head){
while(1){
pNode new = (pNode)malloc(sizeof(node));
puts("enter the data for this node:");
scanf("%d",&new->data); //初始化新节点
new->next = NULL;
if(new->data == 0){
return head;
}
head = insertHead(head,new);
}
return head;
}
二级指针实现
以下是用二级指针实现的,相对来说比在指定位置插入简单,创建节点代码几乎一样,只是注意传入的参数是指针的地址以实现更改指针指向的位置,头插法的实现基本类似返回值法。
//二级指针法
void insertHeadP(pNode *pCur,pNode new){
if(*pCur == NULL){
*pCur = new; //新节点为头节点
}else{
new->next = *pCur; //原头节点接在新节点后
*pCur = new;
}
return ;
}
//创建节点
void creatLnkListP(pNode *head){
pNode *cur = head;
while(1){
pNode new = (pNode)malloc(sizeof(node));
puts("enter the data for this node:");
scanf("%d",&new->data); //初始化新节点
new->next = NULL;
if(new->data == 0){
return;
}
insertHeadP(cur,new);
}
}
尾插法
尾插发分开实现是为了完整性,如下代码可以无返回值,且只用传递一级指针的情况下实现尾插。
void insertTail(pNode head,pNode new){
pNode p = head;
if(head == NULL){ //无头节点则新节点为头
head->data = new->data;
head->next = NULL;
return;
}
while(p->next != NULL){
p = p->next;
}
p->next = new;
return ;
}
但是如果是从头创建链表则不可以使用这段代码,因为要将头节点指着指向新的节点,这就需要改动指针的值或者将新的头节点地址作为返回值传回来,两种方式实现如下:
带返回值实现
尾插区别在于要先对链表进行遍历,当判断到达最后一个节点是,将新节点地址给当前节点的next里即可
/*尾插法*/
//带返回值实现
pNode insertTail(pNode head,pNode new){
pNode p = head;
if(head == NULL){ //无头节点则新节点为头
head = new;
return head;
}
while(p->next != NULL){
p = p->next;
}
p->next = new;
return head;
}
二级指针实现
使用二级指针尾插其实和头插基本一模一样,因为二级指针需要指向头不变,所以定义变量指向二级指针中指针的指向,如果只是使用尾插插入元素,那可以直接使用 带参数返回值方法 那段代码,无需另写,本段代码只是为了
void insertTailP(pNode *pCur,pNode new){
pNode cur = *pCur; //定义结构体指针变量存放二级指针中指针指向的变量
if(*pCur == NULL){
*pCur = new;
return ;
}
while(cur->next != NULL){
cur = cur->next;
}
cur->next = new;
return ;
}














 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









