爬虫案例
运行环境需求
pip install -i https://mirrors.aliyun.com/pypi/simple pymongo
pip install -i https://mirrors.aliyun.com/pypi/simple bs4
pip install -i https://mirrors.aliyun.com/pypi/simple requests
网页
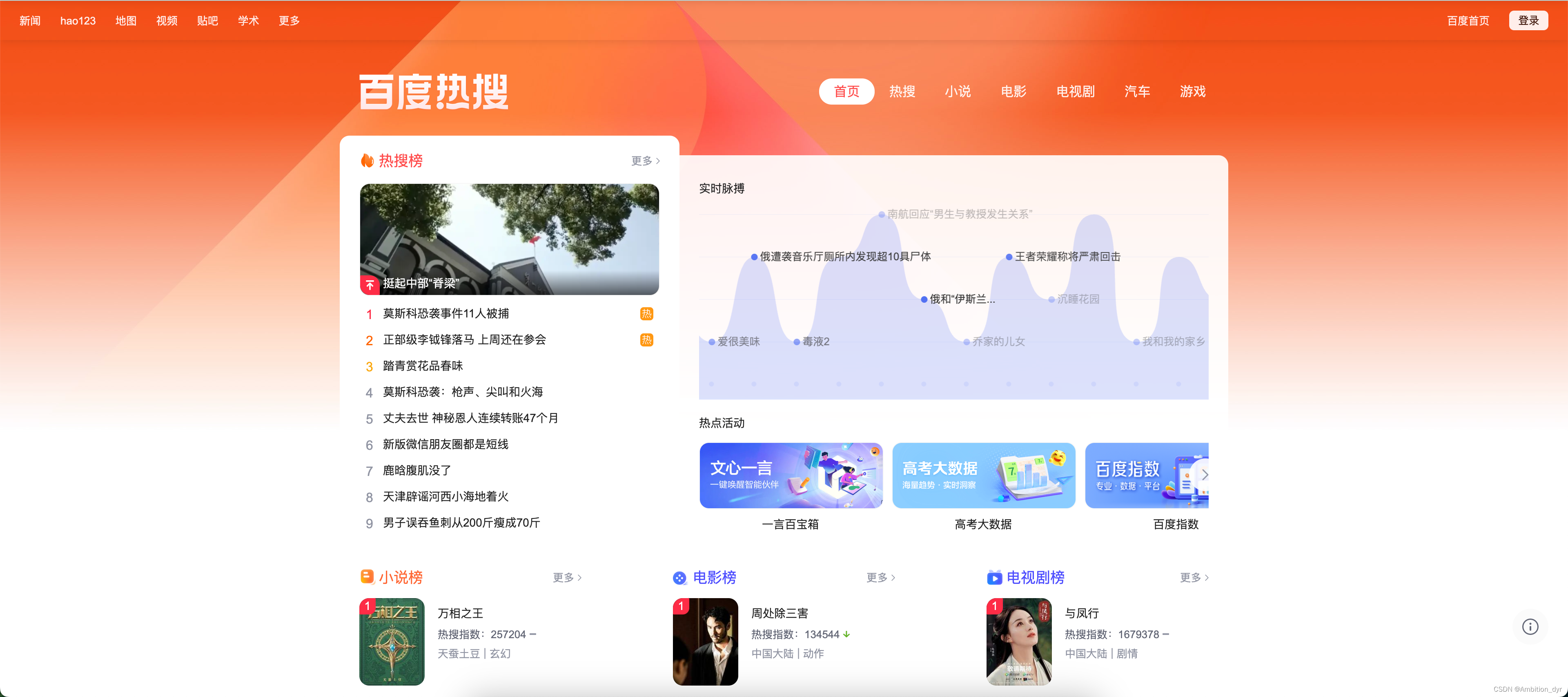
运行结果
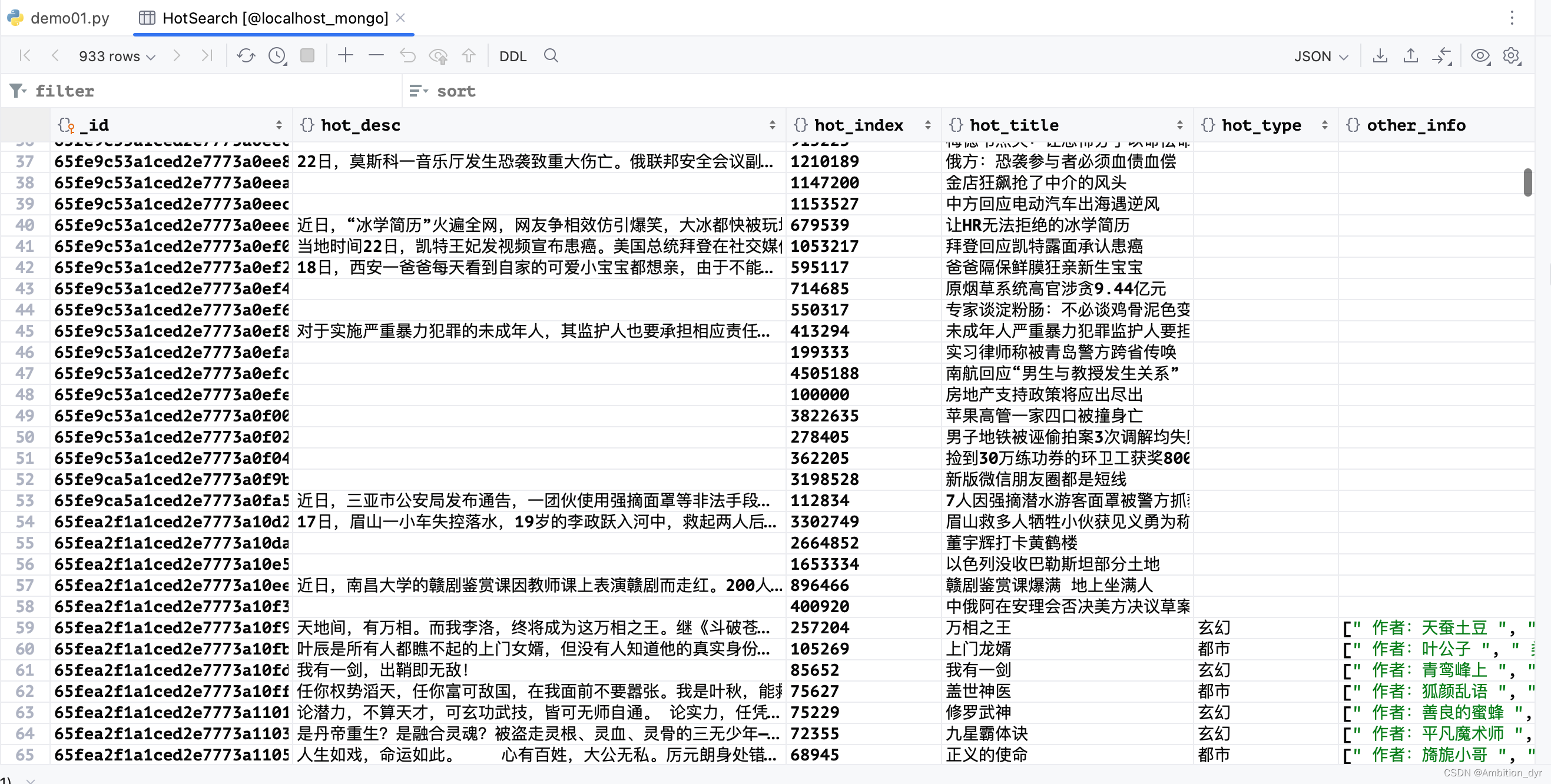
存储到mongobd数据库中
打印logging日志
完整代码
import requests
import pymongo
import logging
from bs4 import BeautifulSoup
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'HotSearch'
MONGO_COLLECTION_NAME = 'HotSearch'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
BASIC_URL = 'https://top.baidu.com/board?tab={tab}'
TABS = {'realtime': '热搜', 'novel': '小说', 'movie': '电影', 'teleplay': '电视剧', 'car': '汽车', 'game': '游戏'}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'Cookie': 'MCITY=-347%3A340%3A; BIDUPSID=5D2236FCE5AE77A4AF18DEC7101EB1FD; PSTM=1681993925; BAIDUID=9954744949E87AC2DBF345CA48AB5C5A:FG=1; BAIDUID_BFESS=9954744949E87AC2DBF345CA48AB5C5A:FG=1; BAIDU_WISE_UID=wapp_1684411055932_533; __bid_n=18e139f9b041152d01bc85; RT="z=1&dm=baidu.com&si=4cacbf4e-bd8e-4a69-96bd-59a02b3c590b&ss=ltu5kkjt&sl=0&tt=0&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&nu=1a26w12&cl=pv9&ul=s8i&hd=s99"; ZFY=SSkp1smgrGY1abkBw4ZUr2oKWuBT:AalKca2DS29wXP8:C; H_PS_PSSID=40010_40171_40212_40080_40365_40351_40381_40369_40415_40311_40465_40471_40317_39661_40514; delPer=0; PSINO=3; BA_HECTOR=24010l202l0h8k0h858k802giekjv61ivt3m41s; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598'
}
def scrape_url(url):
"""
根据提供的url请求信息
:param url:
:return:
"""
logging.info('请求:%s...', url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
logging.error('响应异常:%s', response.status_code)
except requests.RequestException:
logging.error('请求异常:', exc_info=True)
def spider_page(text, tab):
"""
解析url返回的页面内容,获取想要的信息
:param text:
:param tab:
:return:
"""
logging.info('开始解析:%s', TABS[tab])
soup = BeautifulSoup(text, 'lxml')
styles = soup.select('div.tag-item_2erEC')
if len(styles) == 1:
spider_type(soup)
else:
for style in styles:
style_name = style.get_text().strip()
url = ('https://top.baidu.com/board?platform=pc&tab={tab}&tag={"category":"{style_name}"}'.replace(
'{style_name}', style_name).
replace('{tab}', tab))
text = scrape_url(url)
soup = BeautifulSoup(text, 'lxml')
spider_type(soup, style_name)
def spider_type(soup, style=None):
"""
一个标签有多个分类的情况
:param soup: 解析完的html内容
:param style: 类型,默认就一个的可以不传
:return:
"""
if style:
logging.info('类型:%s', style)
infos = soup.select('div.category-wrap_iQLoo')
for info in infos:
data = {'hot_type': '' if style is None else style,
'hot_title': info.select_one('.c-single-text-ellipsis').get_text().strip(),
'hot_index': info.select_one('.hot-index_1Bl1a').get_text().strip(),
'other_info': [other.get_text() for other in info.select('div.intro_1l0wp')] if info.select('div.intro_1l0wp') else '',
}
if info.select_one('.c-single-text-ellipsis.desc_3CTjT'):
data['hot_desc'] = info.select_one('.c-single-text-ellipsis.desc_3CTjT').get_text().strip().replace(
'查看更多>', '')
elif info.select_one('.hot-desc_1m_jR.large_nSuFU'):
data['hot_desc'] = info.select_one('.hot-desc_1m_jR.large_nSuFU').get_text().strip().replace('查看更多>',
'')
else:
data['hot_desc'] = ''
collection.update_one({'hot_title': data.get('hot_title')}, {'$set': data}, upsert=True)
if __name__ == '__main__':
for tab in TABS.keys():
text = scrape_url(BASIC_URL.format(tab=tab))
spider_page(text, tab)






















 2695
2695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











