







最小生成树(Minimum Spanning Tree,简称MST)
- 定义
- 生成树
一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。
- 最小生成树
所有生成树中边的权值之和最小的生成树。
- 生成树
- 性质
- 是一棵树,所以
- 无回路
- 如果有 ∣ V ∣ |V| ∣V∣个顶点,就一定有 ∣ V ∣ − 1 |V|-1 ∣V∣−1条边
- 是生成树,所以
- 包含图的全部顶点
- ∣ V ∣ − 1 |V|-1 ∣V∣−1条边都在图里
- 边的权重和最小
- 是一棵树,所以
- 例:
如图:
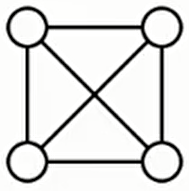
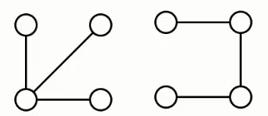
下面这两个都是它的生成树:
求一棵树的最小生成树
-
例:求下图的一棵最小生成树

-
图的表示方法:邻接表
//图的节点表示 typedef struct GNode { int NV;//顶点数 int NE;//边数 WeightType G[MaxVertexNum][MaxVertexNum];//类型为WeightType、大小为MaxVertexNum X MaxVertexNum的二维数组构成邻接矩阵保存边的信息 }GNode, *MGraph;
Prim算法
-
步骤:
- 任选图中一个顶点,收录进集合最小生成树 M S T MST MST里面
- 定义集合 D i s t a n c e [ ] Distance[] Distance[],其中 D i s t a n c e [ V ] Distance[V] Distance[V]表示顶点 V V V到最小生成树 M S T MST MST的最小距离。从未收录进 M S T MST MST的顶点中选一个顶点 V V V,使得 D i s t a n c e [ V ] Distance[V] Distance[V]值最小。
- 收录顶点 V V V可能会使得 V V V的未收录的邻接顶点 W W W到 M S T MST MST的距离改变。所以要刷新 D i s t a n c e [ W ] Distance[W] Distance[W]的值。
- 一直重复第二步第三步,直到图中所有顶点都收录进最小生成树中。
-
伪代码描述
void Prim(Graph G,Vertex S) { MST={S}; while(1) { V=未收录顶点中Distance[]值最小的一个; if(全部顶点都被收录) { break; } Distance[V]=0; //将V收录进MST for(V的每一个邻接点W) { if(Distance != 0) { if(链接顶点V和W的边的权值 < Distance[W]) { Distance[W] = 链接顶点V和W的边的权值; Parent[W] = V; //记录顶点W的在生成树中的父顶点 } } } } } -
代码实现
在未收录的顶点中找出 D i s t e n c e [ ] Distence[] Distence[]值最小的一个,实现方法有两种:一种是使用最小堆实现;另一种是直接用数组排序实现,代码实现类似于有权图的单源最短路径算法。所以下面仅提供第一种方式的代码实现,第二种代码实现可以参考最短路径算法。//Prim算法 void Prim(MGraph G, Vertex SourceV) { MinHeapElementType *Distance = NULL, TempV; Vertex *Parent = NULL; MinHeap H = NULL; Vertex V = 0, AdjV = 0; int i = 0; /******** 申请空间及初始化,其中数组Distance[i]:顶点i到当前生成树的最小距离;Parent[i]:顶点i在生成树中的父节点 ********/ Distance = (MinHeapElementType *)malloc(sizeof(MinHeapElementType)*G->NV); Parent = (Vertex *)malloc(sizeof(Vertex)*G->NV); for (i = 0; i < G->NV; i++) { Distance[i].Distance = INT_MAX; Distance[i].Vertex = i; Parent[i] = -1; } Distance[SourceV].Distance = 0; /************************************** 利用数组Distance里的元素构建最小堆 *****************************************/ H = BuildMinHeap(Distance, G->NV); /******************************** Prim算法求生成树 **********************************/ while (1) { //当最小堆里没有元素的时候,退出循环 if (IsMinHeapEmpty(H)) { break; } //从最小堆输出最小元素 TempV = DeleteMinHeap(H); V = TempV.Vertex; printf("顶点:%d 边权值:%d\n", TempV.Vertex, TempV.Distance);//输出收录的顶点的信息 Distance[TempV.Vertex].Distance = 0; //遍历顶点TempV的邻接顶点 for (AdjV = 0; AdjV < G->NV; AdjV++) { //收录顶点TempV的时候,TempV的临界顶点到当前最小生成树的距离可能缩短,检查 if ((G->G[V][AdjV] != 0) && (Distance[AdjV].Distance != 0) && (G->G[V][AdjV]) < Distance[AdjV].Distance) { Distance[AdjV].Distance = G->G[V][AdjV]; Parent[AdjV] = V; //当Temp的邻接顶点到当前最小生成树的距离改变的时候,更新数组Distance中的值和最小堆中的值 for (i = 1; i <= H->Size; i++) { if (Distance[AdjV].Vertex == H->Element[i].Vertex) { H->Element[i].Distance = Distance[AdjV].Distance; break; } } //最小堆中值改变之后,重新排序最小堆中的元素 TempV = H->Element[i]; for (; H->Element[i / 2].Distance > TempV.Distance; i = i / 2) { H->Element[i] = H->Element[i / 2]; } H->Element[i] = TempV; } } } //打印路径表 printf("\nParent[]:\n"); for (i = 0; i < G->NV; i++) { printf("%3d", Parent[i]); } /*************************** 释放空间 *********************************/ DestroyMinHeap(H); free(Distance); free(Parent); } -
运行结果

Kruskal算法
-
步骤:
- 将图中所有边按权值大小进行排序,每次选出权值最小的一条边。
- 从未被选择的边中选出权值最小的边。
- 如果选出的这条边会使得之前选中的边之中出现回路,就将这条边丢弃,重新选择一条权值最小的边
- 重复第二步和第三步,直到选中 ∣ V ∣ − 1 |V|-1 ∣V∣−1条边。
-
伪代码描述
void Kruskal(Graph G) { MST={}; while(MST中不到|V|-1条边) { 从边集E中取一条权重最小的边E(v,w); /* 最小堆 */ 将E(v,w)从E中删除; if(E(v,w)不在MST中构成回路) /* 查并集 */ { 将E(v,w)加入MST; } else { 无视E(v,w); } } }- 关于是否构成回路,可以用并查集来判断。将有边相连的顶点看作是一个集合当中的顶点,当选中一天边准备插入的时候,如果边的两个顶点在同一个集合之中,那么插入这条边之后一定会形成回路。
-
代码实现
//Kruskal算法 void Kruskal(MGraph G) { MinHeap H = NULL; Edge EdgeSet = NULL, SpanningEdgeSet = NULL; ENode EdgeTemp; List VertexSet = NULL; ListElementType *Temp = NULL; int i = 0, j = 0, k = 0; /*************** 两个集合,EdgeSet存储所有边的信息,SpanningEdgeSet存储生成树边的信息 *****************/ SpanningEdgeSet= (Edge)malloc(sizeof(ENode)*(G->NV - 1)); EdgeSet = (Edge)malloc(sizeof(ENode)*(G->NE)); /****************************** 将图中边的信息存储进数组EdgeSet中 ****************************/ for (i = 0; i < G->NV; i++) { for (j = i+1; j < G->NV; j++) { if (G->G[i][j] != 0) { EdgeSet[k].v1 = i; EdgeSet[k].v2 = j; EdgeSet[k].Weight = G->G[i][j]; k++; } } } /**************************** 用数组VertexSet存储顶点信息,及每个顶点所属的集合 *************************/ VertexSet = CreateList(); Temp = (ListElementType *)malloc(sizeof(ListElementType));//用于暂存数组VertexSet中元素 for (i = 0; i < G->NV; i++) { Temp->Data = i;//数据区存储顶点标号 Temp->Parent = -1;//初始时每个顶点自成一个集合,随着生成树建立时边的确立慢慢将各个集合合并 AddList(VertexSet, *(Temp)); } free(Temp); /********************************** 用EdgeSet中的元素建立一个最小堆 *****************************************/ H = BuildMinHeap(EdgeSet, G->NE); /****************************************** Kruskal算法 *********************************************/ for (i = 0; 1;) { //当收录|V|-1条边的时候,退出循环(生成树的边数 = 顶点数 - 1) if (i == (G->NV - 1)) { break; } //利用最小堆取出权值最小的边 EdgeTemp = DeleteMinHeap(H); //利用并查集判断取出的边是否会让当前的生成树产生回路,如果会,继续取下一条最小边 if (FindRoot(VertexSet, EdgeTemp.v1) != FindRoot(VertexSet, EdgeTemp.v2)) { SpanningEdgeSet[i] = EdgeTemp;//如果不会产生回路,将边保存在数组SpaningEdgeSet中 Union(VertexSet, EdgeTemp.v1, EdgeTemp.v2);//并将该边两顶点所属的两个集合合并 i++; } } /***************************** 打印生成树的变得集合 *******************************/ printf("\n生成树的边:\n"); for (i = 0; i < (G->NV - 1); i++) { printf("v1=%d v2=%d Weight=%d\n", SpanningEdgeSet[i].v1, SpanningEdgeSet[i].v2, SpanningEdgeSet[i].Weight); } /*********************************** 释放空间 ************************************/ DestroyMinHeap(H); DestroyList(VertexSet); free(SpanningEdgeSet); free(EdgeSet); } -
运行结果
















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









