









概述
HashMap是Java中对Map接口的实现类。是其最常用的实现类中之一。主要有以下几个特性:
- HashMap中的key和value都允许为null,但最多只能拥有一个null的key,再次加入null的key会覆盖上一次的key
- HashMap不保证顺序。
- HashMap非线程安全。
HashMap 包含如下几个构造器:
- HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
- ashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。
- HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
HashMap的数据结构
HashMap(jdk1.7)内部是以数组+链表的方式储存的数据。可以参考下图:
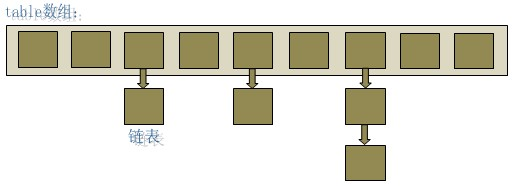
从上图中可以看出,HashMap 底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个 HashMap 的时候,就会初始化一个数组。
我们通过 JDK 中的 HashMap 源码进行一些学习,首先看一下构造函数:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
init();
}
我们着重看一下table = new Entry[capacity];。这不就是 Java 中数组的创建方式吗?也就是说在构造函数中,其创建了一个 Entry 的数组,其大小为 capacity(HashMap默认容量16),那么 Entry 又是什么结构呢?看一下源码:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
……
}
我们目前还是只着重核心的部分,Entry 是一个 static class,其中包含了 key 和 value,也就是键值对,另外还包含了一个 next 的 Entry 指针。我们可以总结出:Entry 就是数组中的元素,每个 Entry 其实就是一个 key-value 对,它持有一个指向下一个元素的引用,这就构成了链表。
HashMap(jdk1.8)开始引入红黑树,HashMap底层变成了数组+链表+红黑树实现

put()方法
put方法被调用时,HashMap会根据key计算出对应的hashcode,然后根据hashcode确定该Entity应该存放在数组的哪个位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
根据hashcode确定该Entity应该存放在数组的哪个位置(即下标)这种设定有一个问题:实际引用中有可能会发生hash碰撞(即两个数据虽然内容不同,但其hashcode有可能是相同的)!因此,HashMap如果发现hashcode已经存在,则会对key进行euqals对比:
- equals结果是true,则认为确实是同一个key,然后将新的value覆盖旧的value(此时put方法将会返回旧value值)。
- equals结果是false,则认为是hash碰撞,此时会将之前的Entity作为新Entity的next,此时形成一个链表,新Entity则处在链表的首位。
get()方法
如果理解了上述的put逻辑,则get方法就很容易理解。主要有以下几个步骤:
- 根据key计算hashcode,然后得出其数组下标(位置)。
- 找到数组中对应位置的某一元素。
- 从头到尾遍历链表的每一个Entity,通过key的equals方法找到对应的Entity。
上述的过程中有一个点未详细说明:如何根据key的hashcode计算出对应的数组坐标呢?
HashMap的内部实现用了一个非常巧妙的方法。HashMap的初始容量被定为16,且每次增长都是2的倍数。这样设计的目的是要保证存入map中的元素尽量分散,尽量避免出现链表中出现链表,这可以有效降低数据查询时的处理速度。
key是这么一步步转化成数组下标的:
第一步:Object Key --> int hash
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
如果key是null,则其hash为0;否则便将 hashcode 与 hashcode的高位 做 异或运算。这是为了尽量避免“低位不变,高位变化”时造成的hash冲突。
第二步:hash --> i
上一步计算出的hash是个长度较长的二进制数字,而通常情况下HashMap的底层数组长度(length)较小,因此如果我们进行 hash % length 计算,则一定能得到一个下标,且相对比较分散。而在源码中使用了性能更高的算法:
i = (length - 1) & hash
这个公式对hash和length进行了按位与运算,等价于取余。
这时就能说清楚另外一件事情:为什么底层数组的长度总要是2的n次方呢?
下表是个示例:
| h & (table.length-1) | hash | table.length-1 | ||
|---|---|---|---|---|
| 8 & (15-1): | 0100 | & | 1110 | = 0100 |
| 9 & (15-1): | 0101 | & | 1110 | = 0100 |
| 8 & (16-1): | 0100 | & | 1111 | = 0100 |
| 9 & (16-1): | 0101 | & | 1111 | = 0101 |
可以看到,如果数组长度是2的n次方,那么length-1的二进制表示中,一定所有位都是1,此时取&运算则可以完整保留hash响应位置的二进制数据。相反的,如果数组长度不是2的n次方,则出现hash碰撞的可能性大大提高。
归纳
简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据 hash 算法来决定其在数组中的存储位置,在根据 equals 方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry 时,也会根据 hash 算法找到其在数组中的存储位置,再根据 equals 方法从该位置上的链表中取出该Entry。















 9292
9292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









