








此步骤假设大家的 Hadoop 集群已经能够无碍的运行, 并且 Linux 的防火墙和 SELinux 已经关闭, 时钟也已经同步, 如果还没有, 请参考 Hadoop 集群搭建部分, 完成以上三件事
下载 Spark 安装包, 下载时候选择对应的 Hadoop 版本(资料中已经提供了 Spark 安装包, 直接上传至集群 Master 即可, 无需遵循以下步骤)
官网下载地址:https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
安装Spark
下载和解压
cd /export/softwares
wget https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
解压并拷贝到export/servers
解压 Spark 安装包
tar xzvf spark-2.2.0-bin-hadoop2.7.tgz
移动 Spark 安装包
mv spark-2.2.0-bin-hadoop2.7 spark
mv spark /export/servers
修改配置文件spark-env.sh, 以指定运行参数
进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
cd /export/servers/spark/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
将以下内容复制进配置文件末尾
#指定 Java Home
export JAVA_HOME=/export/servers/jdk1.8.0_141
#指定 Spark Master 地址
export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077
配置
修改配置文件 slaves
以指定从节点为止, 从在使用 sbin/start-all.sh 启动集群的时候, 可以一键启动整个集群所有的 Worker
进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
cd /export/servers/spark/conf
cp slaves.template slaves
vim slaves
配置所有从节点的地址
node2
node3
配置 HistoryServer
1.默认情况下, Spark 程序运行完毕后, 就无法再查看运行记录的 Web UI 了, 通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程
2.复制 spark-defaults.conf, 以供修改
cd /export/servers/spark/conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
3.将以下内容复制到spark-defaults.conf末尾处, 通过这段配置, 可以指定 Spark 将日志输入到 HDFS 中
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/spark_log
spark.eventLog.compress true
4.将以下内容复制到spark-env.sh的末尾, 配置 HistoryServer 启动参数, 使得 HistoryServer 在启动的时候读取 HDFS 中写入的 Spark 日志
# 指定 Spark History 运行参数
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node1:8020/spark_log"
5.为 Spark 创建 HDFS 中的日志目录
hdfs dfs -mkdir -p /spark_log
分发和运行
将 Spark 安装包分发给集群中其它机器
cd /export/servers
scp -r spark root@node2:$PWD
scp -r spark root@node3:$PWD
启动 Spark Master 和 Slaves, 以及 HistoryServer
cd /export/servers/spark
sbin/start-all.sh
sbin/start-history-server.sh
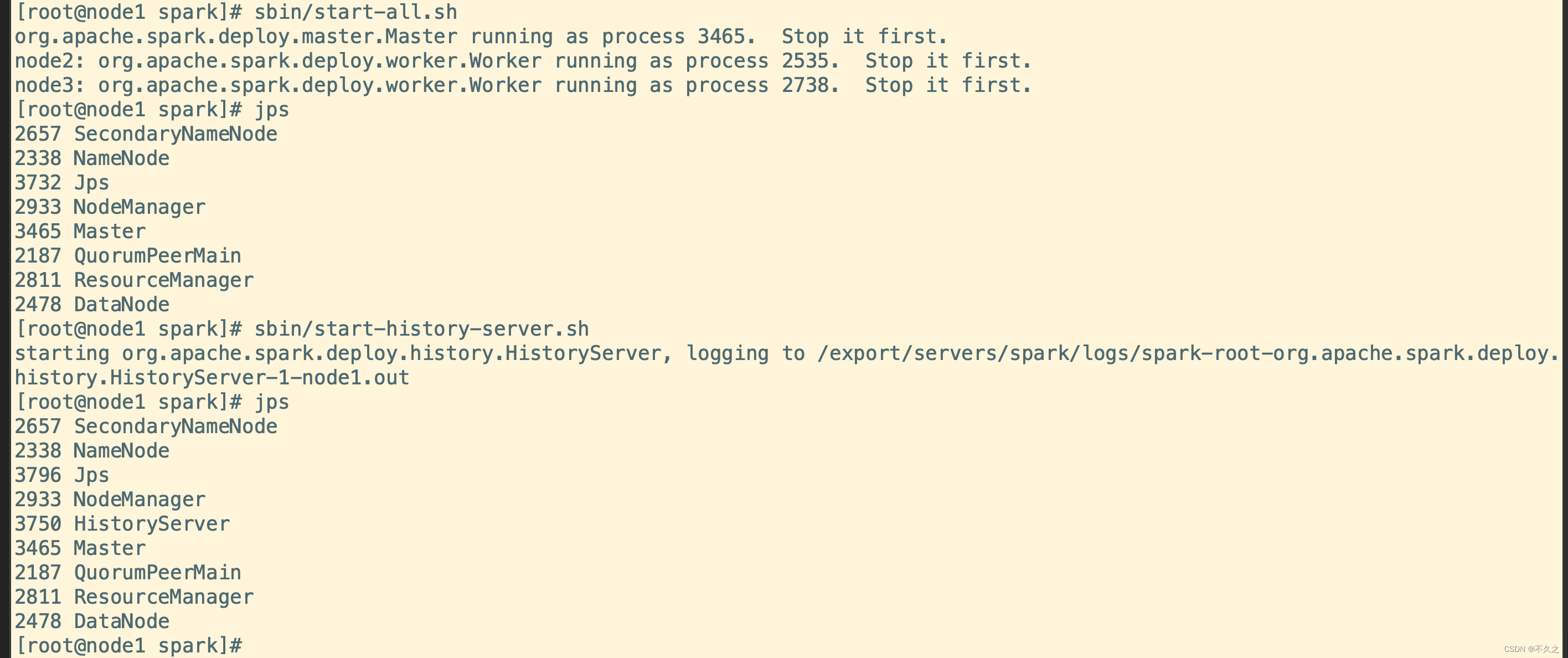
Spark 集群高可用搭建
Step 1
停止 Spark 集群
cd /export/servers/spark
sbin/stop-all.sh
Step 2
修改配置文件, 增加 Spark 运行时参数, 从而指定 Zookeeper 的位置
进入 spark-env.sh 所在目录, 打开 vim 编辑
cd /export/servers/spark/conf
vim spark-env.sh
编辑 spark-env.sh, 添加 Spark 启动参数, 并去掉 SPARK_MASTER_HOST 地址
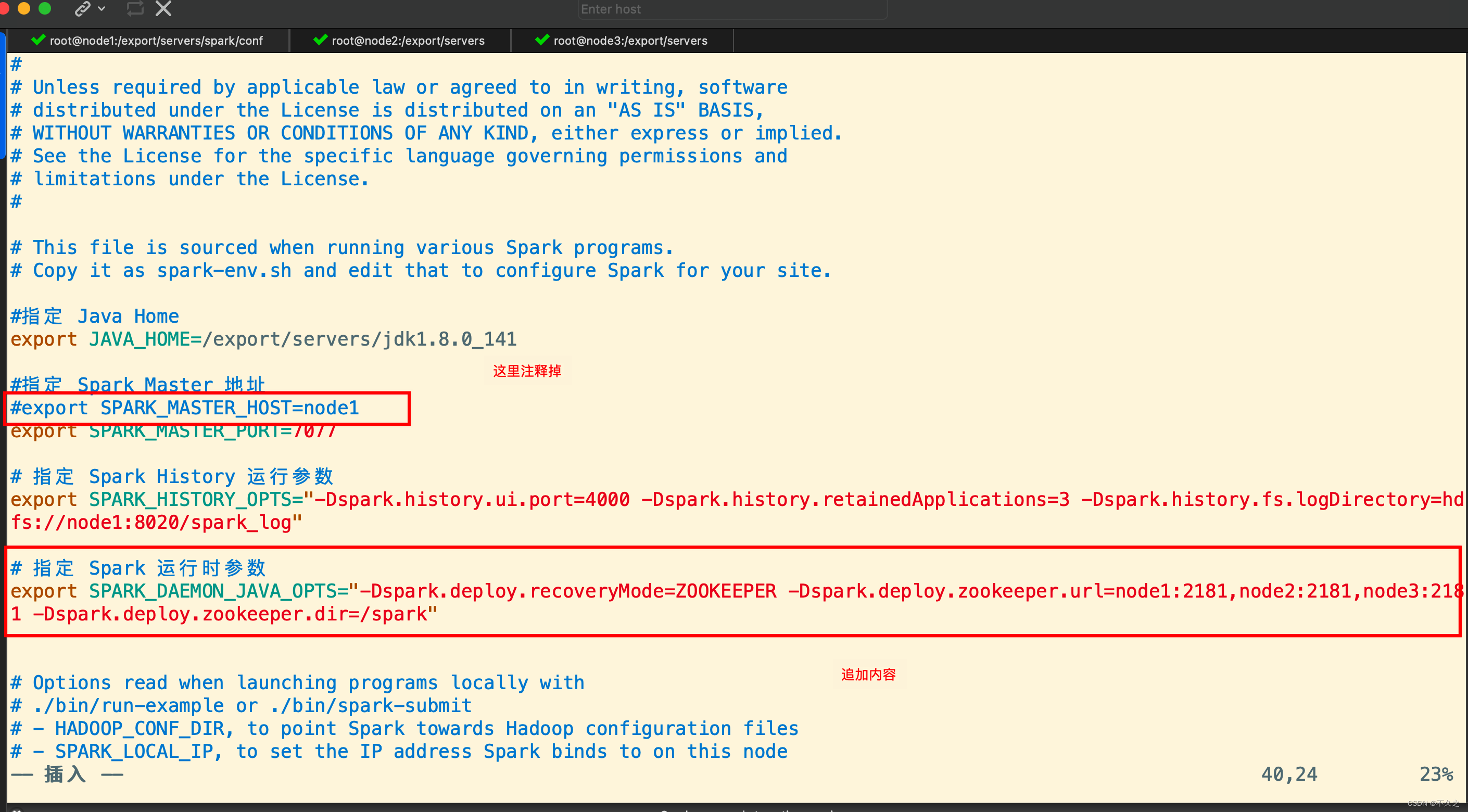
# 指定 Java Home
export JAVA_HOME=/export/servers/jdk1.8.0_141
# 指定 Spark Master 地址
# export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077
# 指定 Spark History 运行参数
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
# 指定 Spark 运行时参数
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark"
Step 3
分发配置文件到整个集群
cd /export/servers/spark/conf
scp spark-env.sh node2:$PWD
scp spark-env.sh node3:$PWD
Step 4
启动
在 node1 上启动整个集群
cd /export/servers/spark
sbin/start-all.sh
sbin/start-history-server.sh
在 node2 上单独再启动一个 Master
cd /export/servers/spark
sbin/start-master.sh
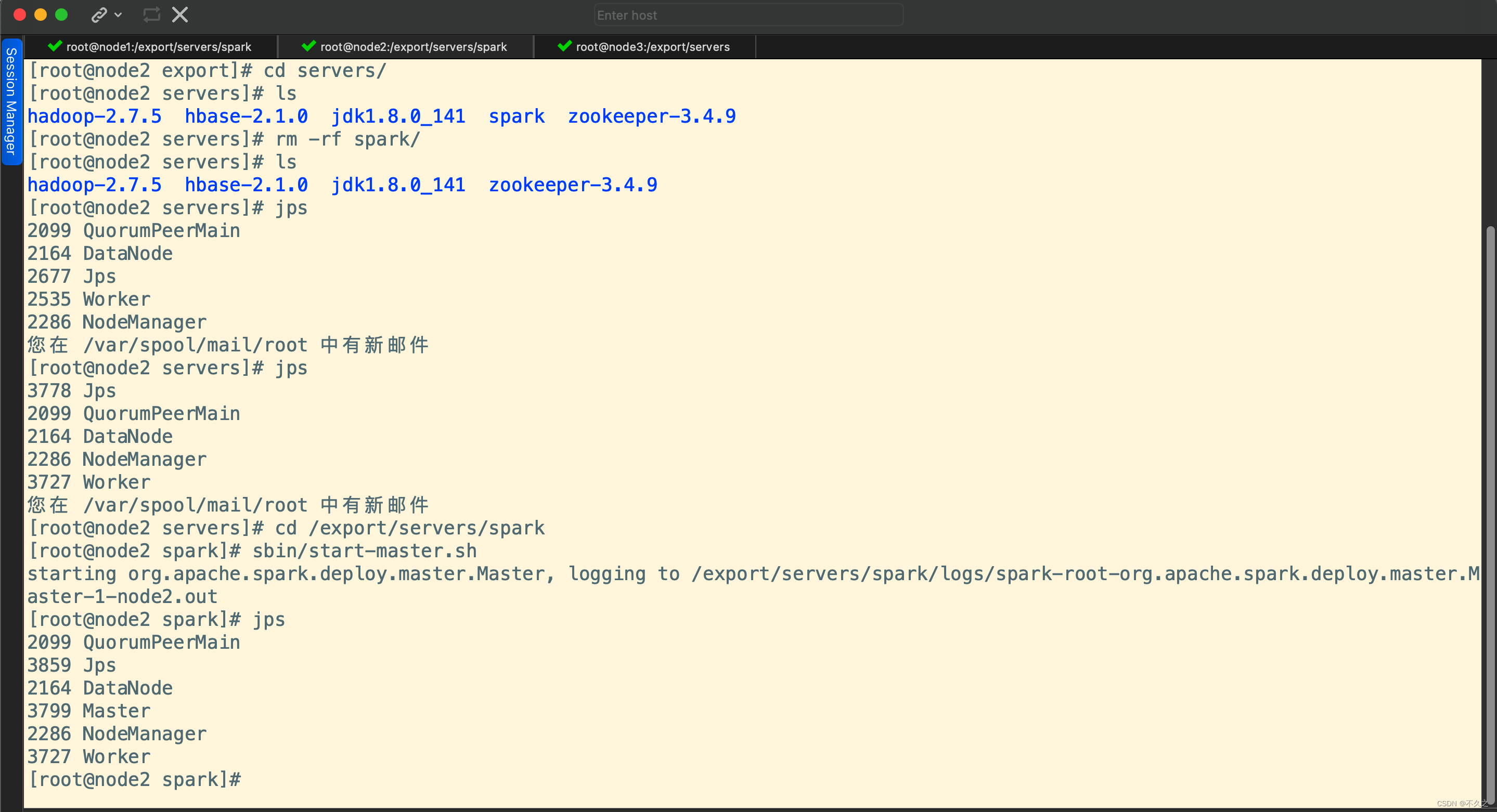
Step 5
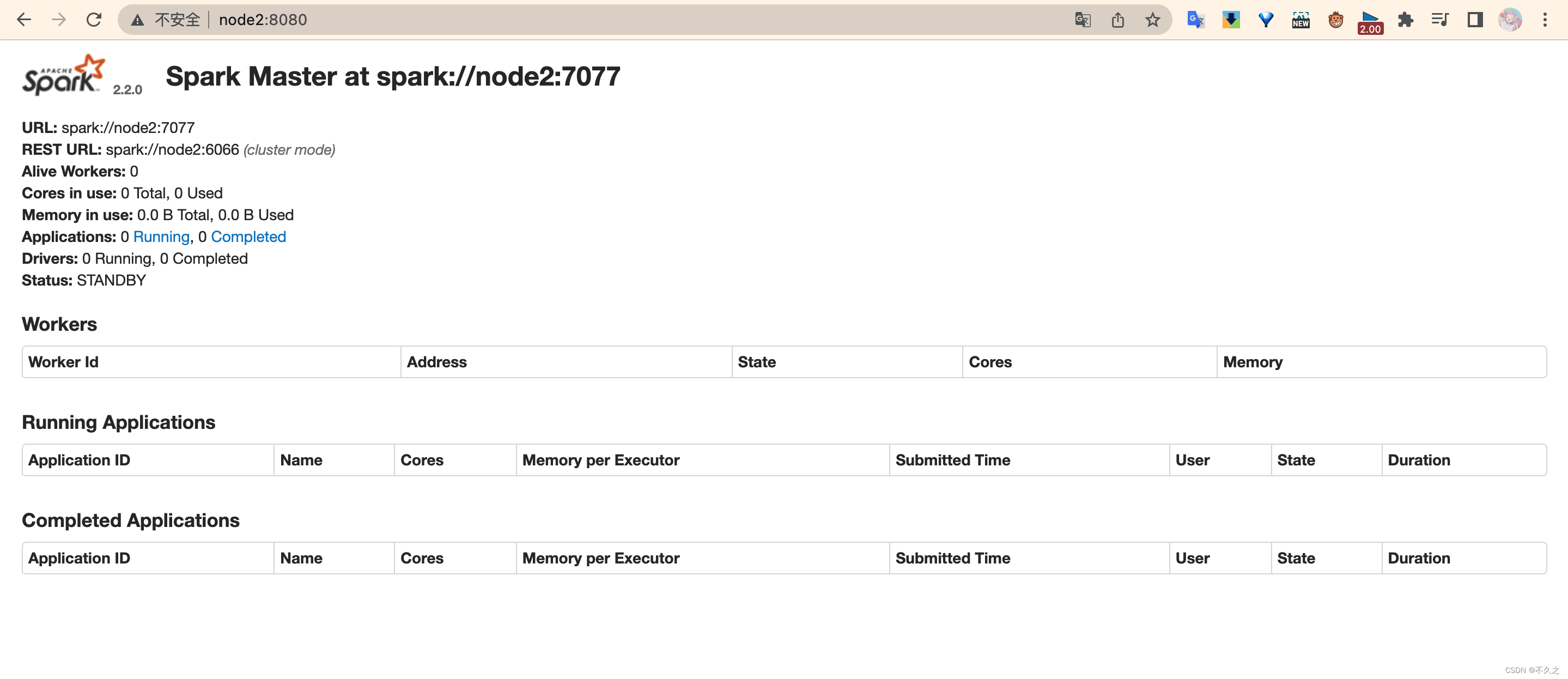
查看 node1 master 和 node2 master 的 WebUI
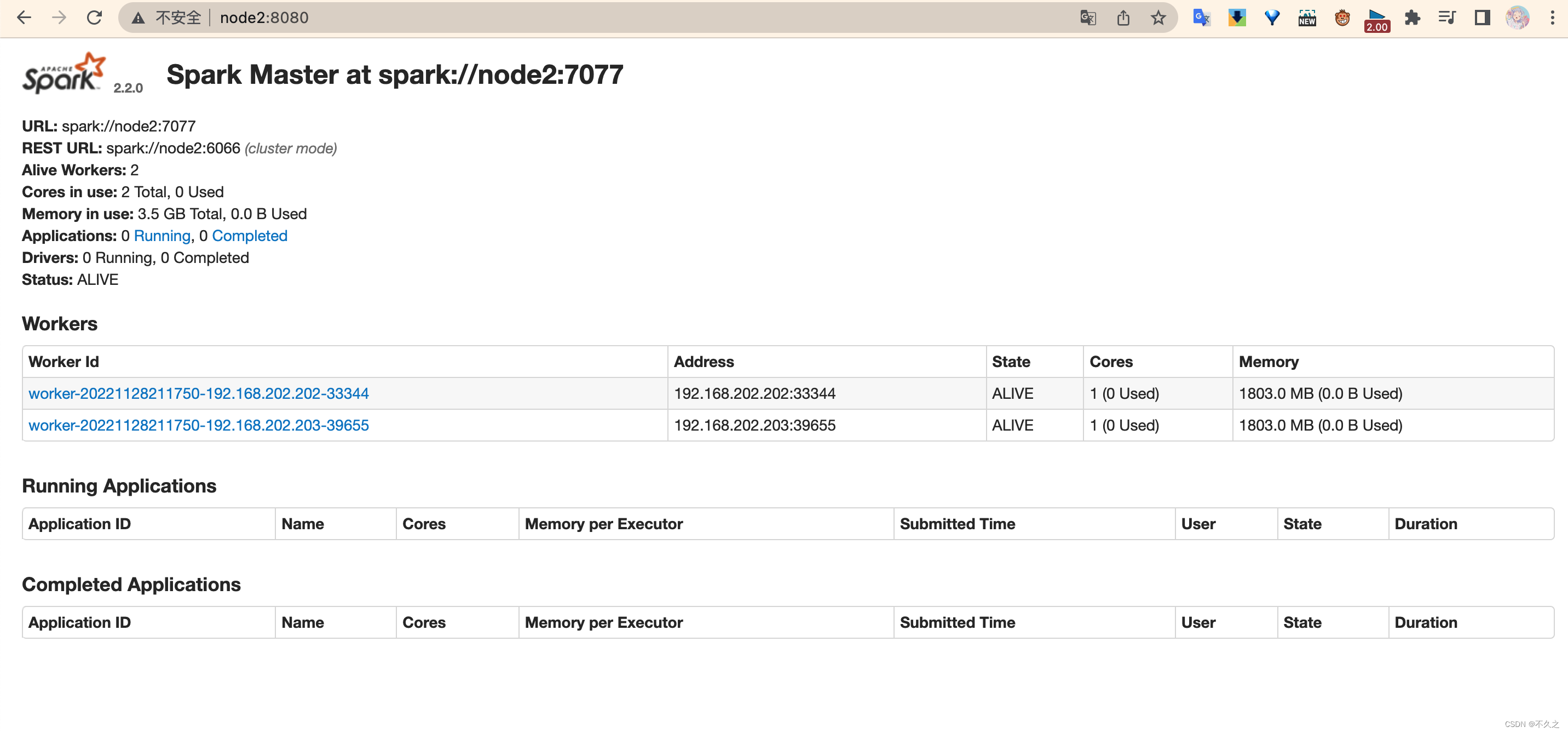
你会发现一个是 ALIVE(主), 另外一个是 STANDBY(备)
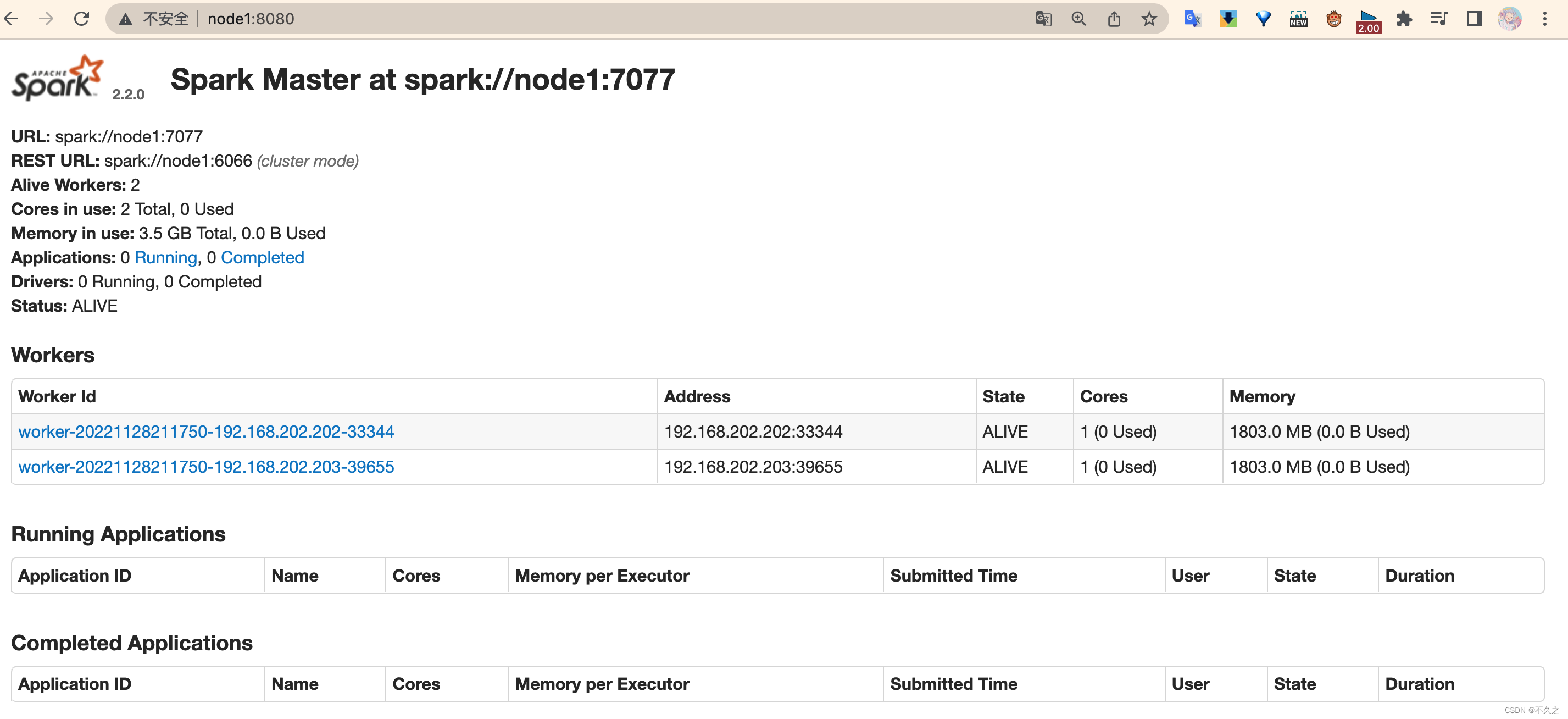
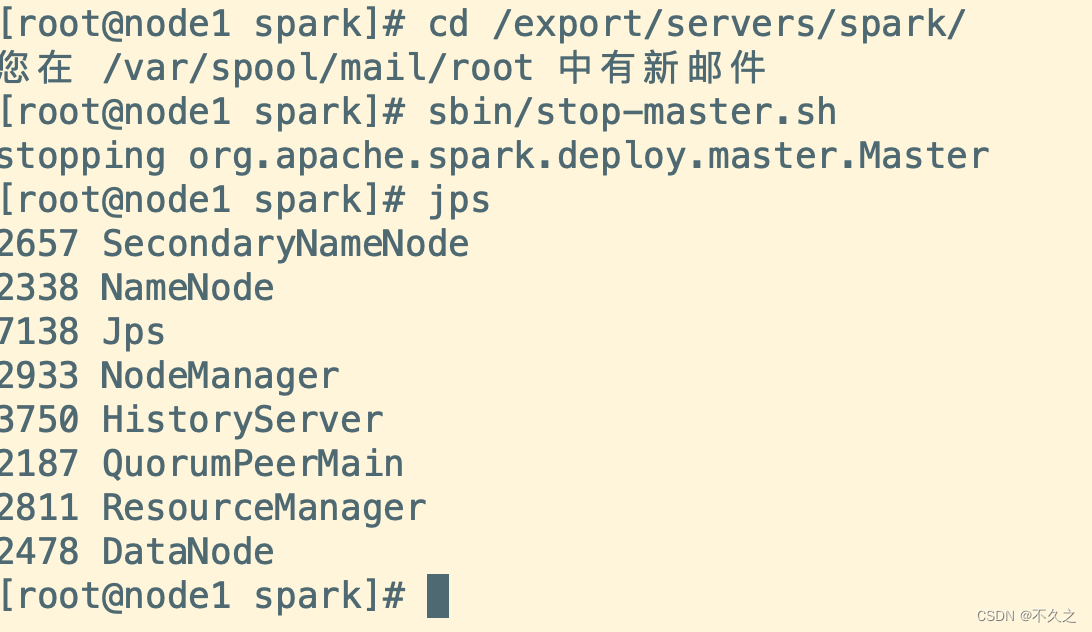
如果关闭一个, 则另外一个成为ALIVE, 但是这个过程可能要持续两分钟左右, 需要耐心等待
# 在 node1 中执行如下指令
cd /export/servers/spark/
sbin/stop-master.sh

第一个应用的运行
目标
从示例应用运行中理解 Spark 应用的运行流程
流程
Step 1 进入 Spark 安装目录中
cd /export/servers/spark/
Step 2 运行 Spark 示例任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077,node2:7077,node3:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \
100
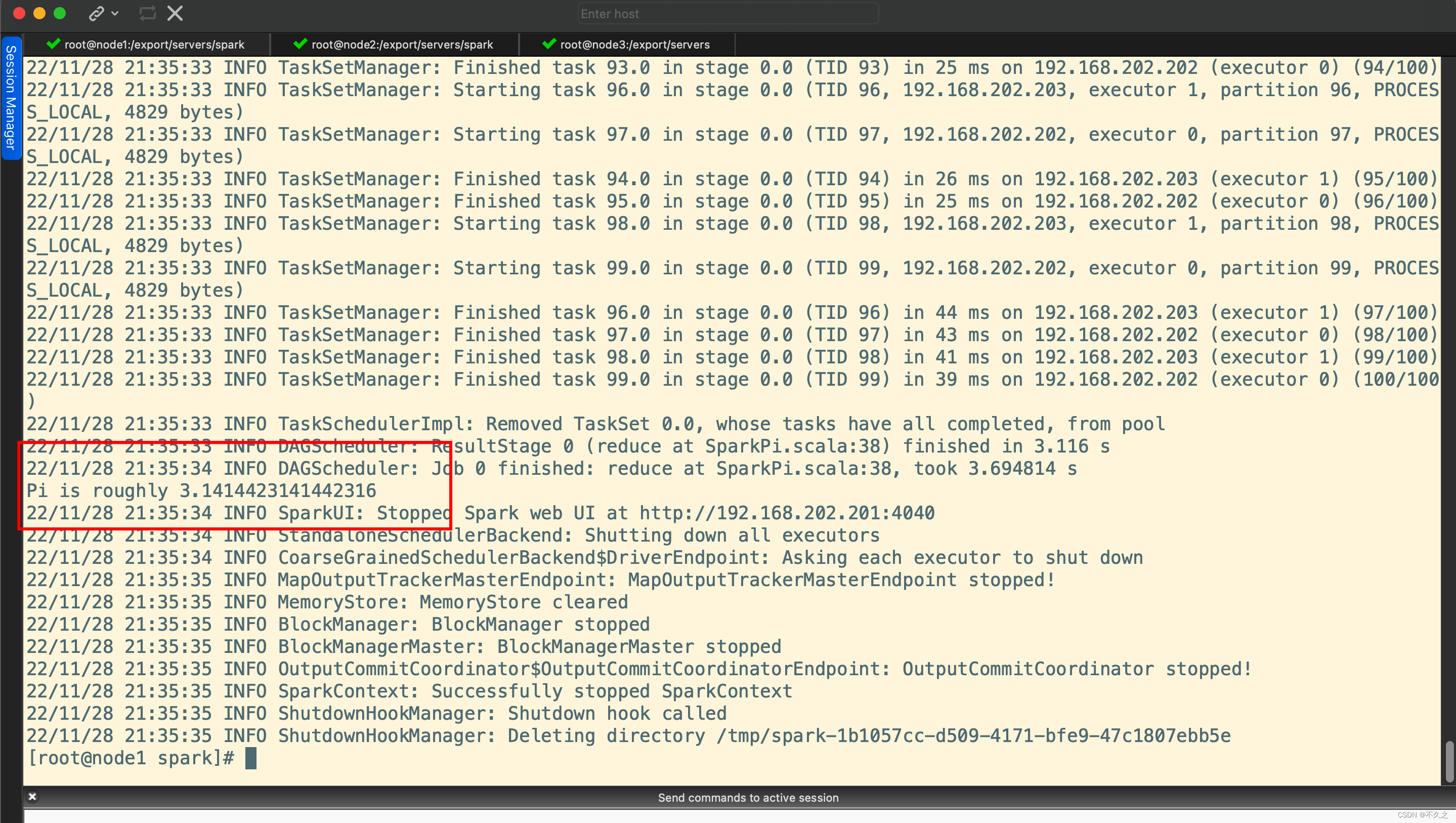
Step3 运行结果
Pi is roughly 3.141550671141551















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









