









一、部署规划
| 部署节点 | 部署内容 | 节点 IP |
|---|---|---|
| spark1 | scala-2.12.2、spark-3.2.0 | 10.52.1.1 |
| spark2 | scala-2.12.2、spark-3.2.0 | 10.52.1.2 |
| spark3 | scala-2.12.2、spark-3.2.0 | 10.52.1.3 |
二、安装前的准备:
1、关闭Selinux、防火墙和THP,三台服务器都要操作一次
关闭防火墙
systemctl stop firewalld
永久关闭防火墙
systemctl disable firewalld
sed -i ‘s/^SELINUX=enforcing$/SELINUX=disabled/’ /etc/selinux/config && setenforce 0
2、配置hosts,三台机器都要操作一次
vim /etc/hosts
新增
10.52.1.1 spark1
10.52.1.2 spark2
10.52.1.3 spark3
3、三台机器配置root账号免密钥
(1) 生成密钥,三台机器都执行
ssh-keygen
(2)公钥复制
比如在spark1上执行完ssh-keygen后,执行
ssh-copy-id root@spark2
ssh-copy-id root@spark3
在spark2上执行:
ssh-copy-id root@spark1
ssh-copy-id root@spark3
在spark3上执行:
ssh-copy-id root@spark1
ssh-copy-id root@spark2
(3)自己ssh自己
在spark2上执行:
cd ~/.ssh/
cat id_rsa.pub >> authorized_keys
4、Spark版本的选择
1.Spark版本的选择,附Spark官网的地址,http://spark.apache.org/downloads.html, https://archive.apache.org/dist/spark/
2.Scala版本的选择,附Scala官网的地址,https://www.scala-lang.org/download/2.12.2.html
3. Java版本的选择,附Java官网的地址https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html
三、部署过程
1、部署Scala
-
上传scala压缩包scala-2.12.2.tgz,并解压到指定位置
tar -xvf scala-2.12.2.tgz -C /opt/modules/
解压完在/opt/modules/下出现scala-2.12.2 -
修改名称
mv /opt/modules/scala-2.12.2 /opt/modules/scala -
配置scala的环境变量
vim /etc/profile
添加:export HADOOP_HOME=/opt/modules/hadoop export SCALA_HOME=/opt/modules/scala export PATH=$PATH:$SCALA_HOME/bin使环境变量生效
source /etc/profile -
验证版本
scala -version
-
分发到其他两个节点(spark2和spark3都要分发)
scp -r /opt/modules/scala root@spark2:/opt/modules/
scp /etc/profile root@spark2:/etc/profile在三个节点都执行source /etc/profile
2、部署Java环境
-
上传java压缩包jdk-8u261-linux-x64.tar.gz,并解压到指定位置
tar -xvf jdk-8u261-linux-x64.tar.gz -C /opt/modules/
解压完在/opt/modules/下出现jdk1.8.0_261 -
修改名称
mv /opt/modules/jdk1.8.0_261 /opt/modules/jdk8 -
配置Java的环境变量
vim /etc/profile
添加:export JAVA_HOME=/opt/modules/scala export PATH=$PATH:$JAVA_HOME/bin使环境变量生效
source /etc/profile -
验证版本
java -version

-
分发到其他两个节点(spark2和spark3都要分发)
scp -r /opt/modules/jdk8 root@spark2:/opt/modules/
scp /etc/profile root@spark2:/etc/profile在三个节点都执行source /etc/profile
3、部署Spark
-
上传Spark压缩包spark-3.2.0-bin-hadoop3.2.tgz,并解压到指定位置
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /opt/modules/
解压完在/opt/modules/下出现spark-3.2.0-bin-hadoop3.2 -
修改名称
mv /opt/modules/spark-3.2.0-bin-hadoop3.2 /opt/modules/spark -
配置Spark的环境变量
vim /etc/profile
添加:
export SPARK_HOME=/opt/modules/spark
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
使环境变量生效
source /etc/profile
- 配置slaves文件
cd /opt/modules/spark/conf
cp workers.template slaves
vim slaves
加入三个节点的主机名
spark1
spark2
spark3 - 配置spark-evn.sh文件
cp spark-env.sh.template spark-env.sh
编辑配置文件:
添加:
export SPARK_PID_DIR=${HADOOP_HOME}/pids
export JAVA_HOME=/opt/modules/jdk8
export HADOOP_HOME=/opt/modules/hadoop
export HADOOP_CONF_DIR=/opt/modules/hadoop/etc/hadoop
export SCALA_HOME=/opt/modules/scala-2.12.2
export SPARK_HOME=/opt/modules/spark
export SPARK_MASTER_IP=spark1
export MASTER=spark://spark1:7077
export SPARK_MASTER_WEBUI_PORT=8090
export SPARK_WORKER_MEMORY=16g
export SPARK_WORKER_CORES=16
export YARN_CONF_DIR=/opt/modules/hadoop/etc/hadoop
##zookeeper+spark高可用 ,没有装zookeeper的下边可以不配置
-Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181
-Dspark.deploy.zookeeper.dir=/export/spark-ha"
- 将spark1的spark分发到spark2和spark3
scp -r /opt/modules/spark root@spark2:/opt/modules/
scp -r /opt/modules/spark root@spark3:/opt/modules/
- 修改spark2和spark3的环境变量
vim /etc/profile
添加
export SPARK_HOME=/opt/modules/spark
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
source /etc/profile
- 启动集群(standalone方式)
sh /opt/modules/spark/sbin/start-all.sh
- 验证启动结果
主节点

从节点


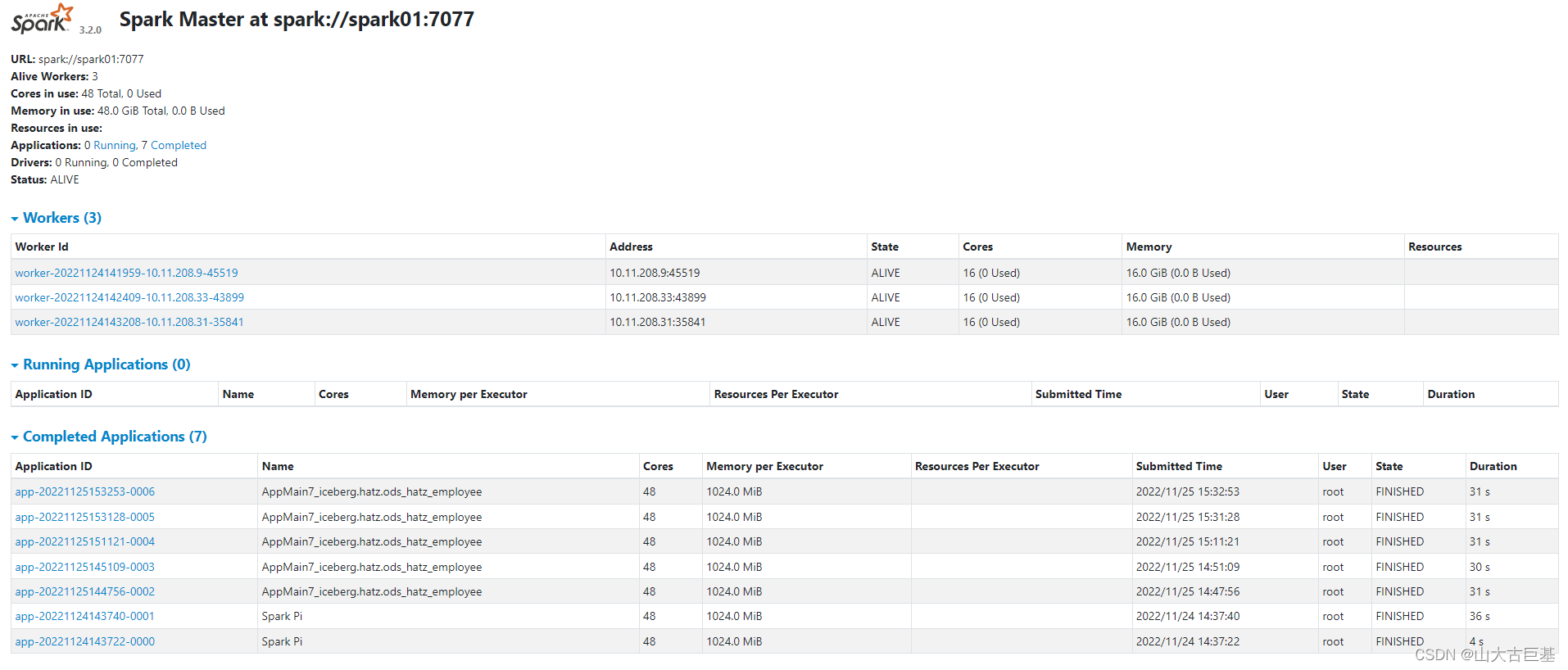
- 在页面上验证UI的启动结果
访问http://spark1:8090/ 是否出现类似的界面
- Standalone方式验证计算圆周率PI
spark-submit --master spark://spark1:7077 --class org.apache.spark.examples.SparkPi /opt/modules/spark/examples/jars/spark-examples_2.12-3.2.0.jar 12
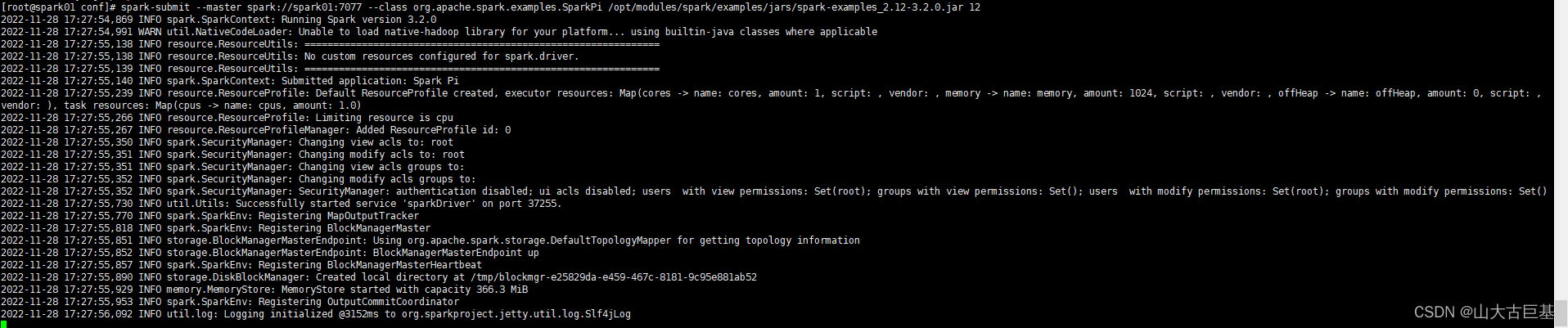
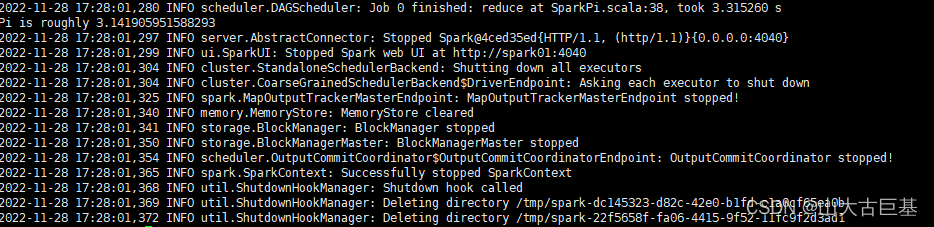
看是否能执行成功
11. Yarn方式提交集群计算圆周率PI
spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi /opt/modules/spark/examples/jars/spark-examples_2.12-3.2.0.jar 12
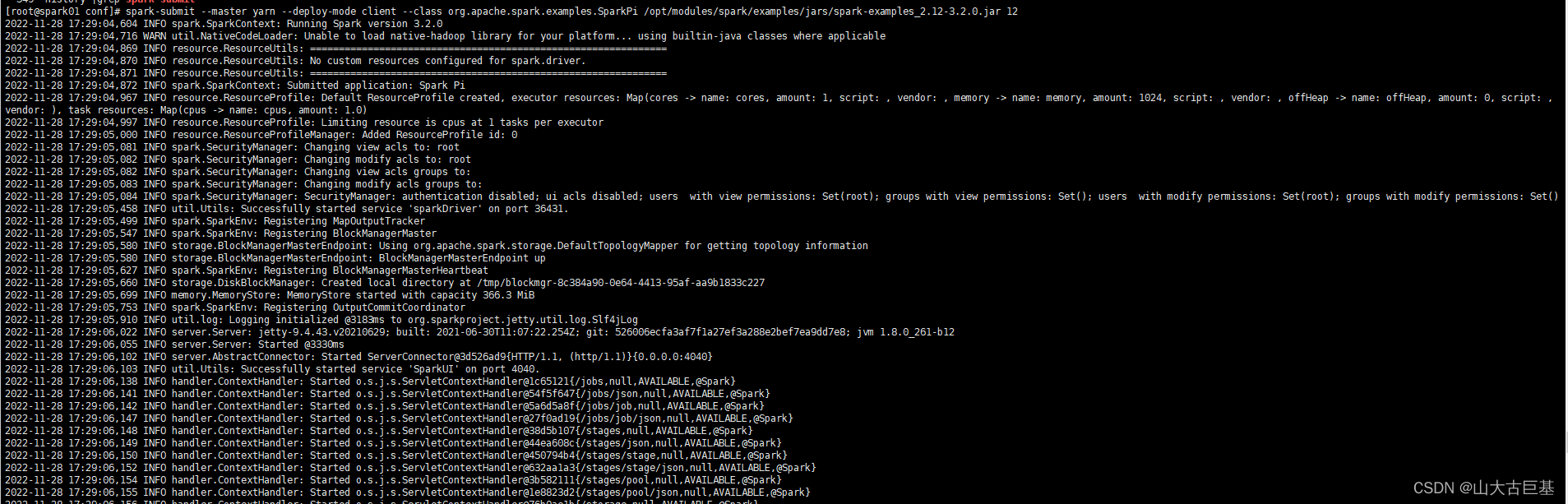
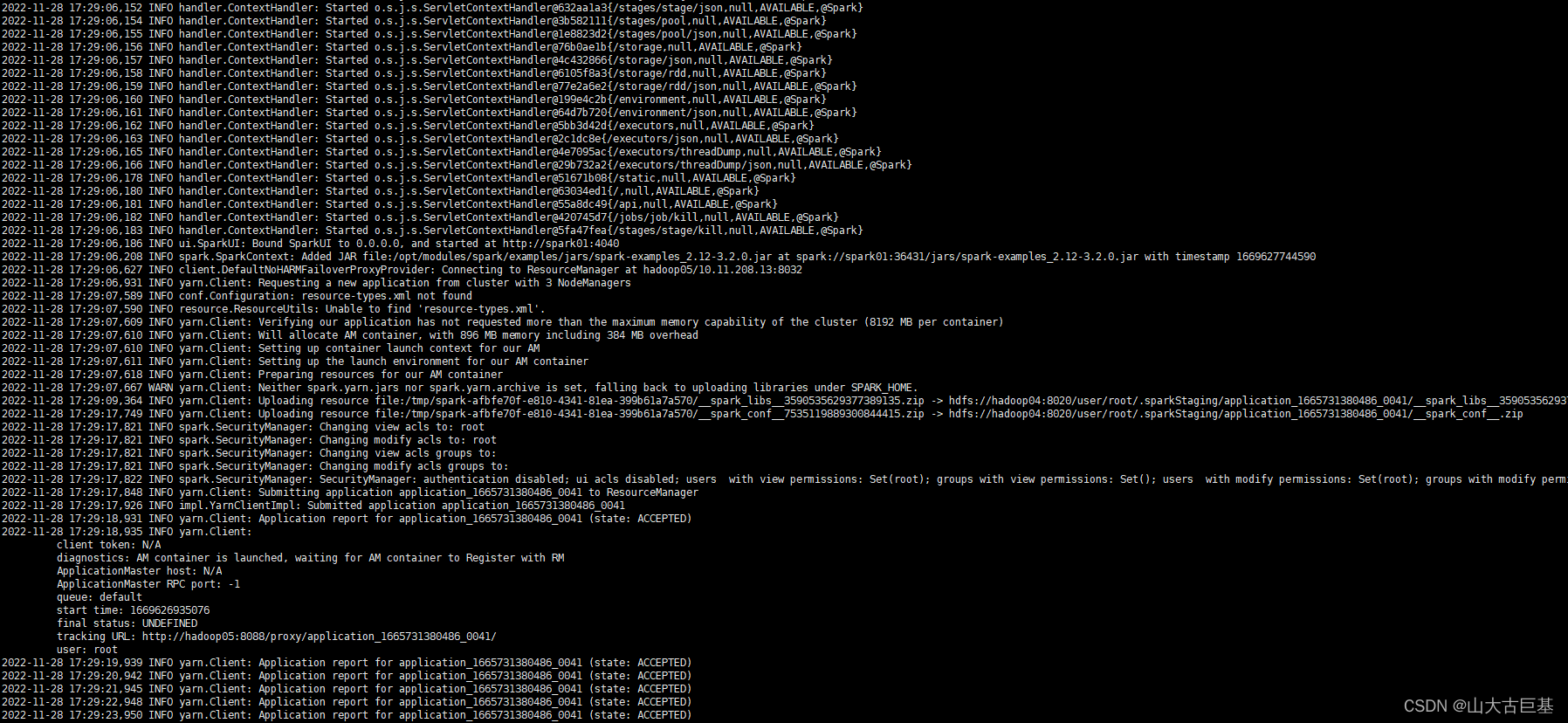
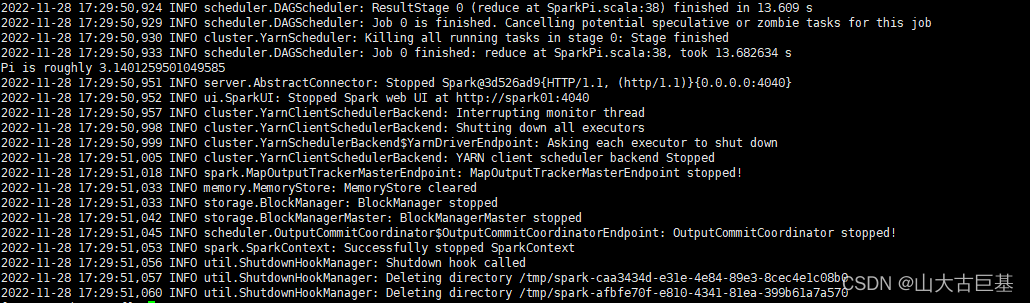
- Spark客户端提交Spark程序(客户端不在Spark集群中)
需要先在客户端服务器配置hosts
vim /etc/hosts
添加
10.52.1.1 spark1
10.52.1.2 spark2
10.52.1.3 spark3
客户端机器安装jdk8和scala2.12,将Hadoop集群中的/opt/modules/hadoop直接拷贝到客户端中
/opt/modules/ 下
将spark1上安装的spark分发到客户端上,修改spark/conf下的
spark-env.sh
vim spark-env.sh
把Java、Scala、Hadoop改为客户端的安装路径
export SPARK_PID_DIR=${HADOOP_HOME}/pids
export JAVA_HOME=/opt/modules/jdk8
export HADOOP_HOME=/opt/modules/hadoop
export HADOOP_CONF_DIR=/opt/modules/hadoop/etc/hadoop
export SCALA_HOME=/opt/modules/scala-2.12.2
export SPARK_HOME=/opt/modules/spark
export SPARK_MASTER_IP=spark1
export MASTER=spark://spark1:7077
export SPARK_MASTER_WEBUI_PORT=8090
export SPARK_WORKER_MEMORY=16g
export SPARK_WORKER_CORES=16
export YARN_CONF_DIR=/opt/modules/hadoop/etc/hadoop
export SPARK_PID_DIR=${HADOOP_HOME}/pids
export JAVA_HOME=/opt/modules/jdk8
export HADOOP_HOME=/opt/modules/hadoop
export HADOOP_CONF_DIR=/opt/modules/hadoop/etc/hadoop
export SCALA_HOME=/opt/modules/scala-2.12.2
export SPARK_HOME=/opt/modules/spark
export SPARK_MASTER_IP=spark1
export MASTER=spark://spark1:7077
export SPARK_MASTER_WEBUI_PORT=8090
export SPARK_WORKER_MEMORY=16g
export SPARK_WORKER_CORES=16
export YARN_CONF_DIR=/opt/modules/hadoop/etc/hadoop
测试在yarn上提交spark计算圆周率PI
/nfs/spark/spark/bin/spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi /nfs/spark/spark/examples/jars/spark-examples_2.12-3.2.0.jar 12
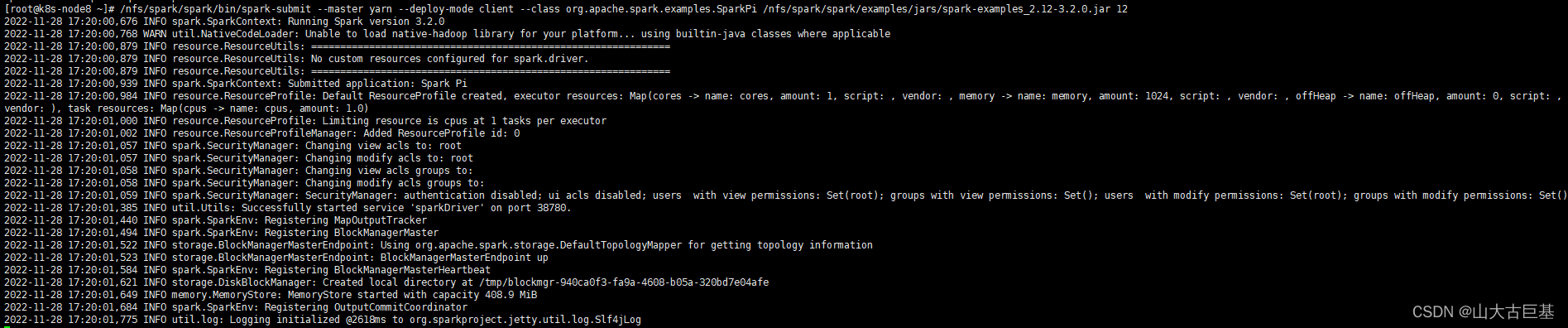
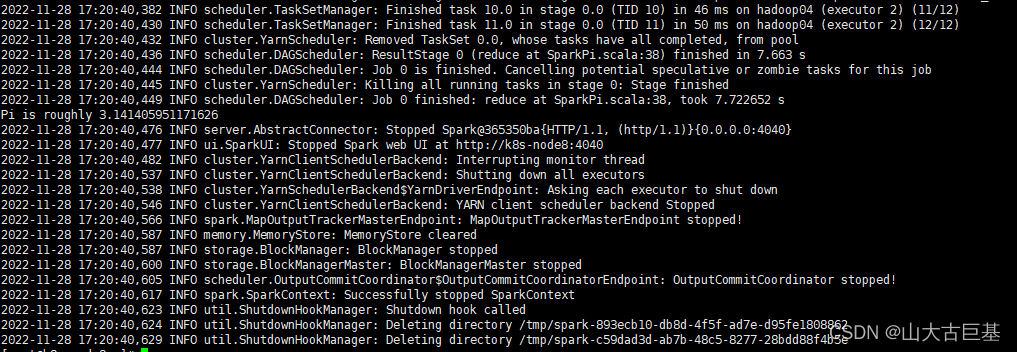

















 2652
2652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









