







最近学习了python爬虫,学习了一些解析库,下面就分享一下自己的学习新的吧,因为是新手,如果有错误,欢迎指正!
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story"">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie "class="sisiter" id="link1">Elsie</a>,
<a href = "http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3" >Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#. 直接访问标签
soup = BeautifulSoup( html_doc ,‘lxml’ )
print( soup.p)

直接访问标签时只能访问第一个标签
再查看一下类型
print( type( soup.p) )
结果是:<class ‘bs4.element.Tag’>
可见返回的值仍是一个标签类型
print( soup.p.name )
结果是: p
返回name的值就是标签的名字(soup.name比较特殊)
print( soup.name )
结果是: document
##关于属性
首先明确一下属性:一个标签内包含多少个等号就包含多少个属性
example:
这里面就有一个属性即:class=“title”
BeautifulSoup中有打印标签属性的方法
print( soup.p.attrs )
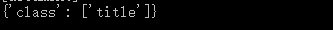
还有直接访问标签的某个属性的方法1:
print( soup.p[‘class’] )

直接返回对应的属性的值
方法2:
print( soup.p.get(‘class’) )
 可见方法一和二得到的结果是完全一样的
可见方法一和二得到的结果是完全一样的
##获得对应的文本信息
print( soup.p.string )
 但是如果选中的标签中包含的信息不止一个时,上述的方法就不能使用
但是如果选中的标签中包含的信息不止一个时,上述的方法就不能使用
example:print( soup.string )

可见结果返回为:None
因为它不知道你到底要选中发一个信息
##可以使用strings方法
print( type(soup.strings) )
 可以看到类型为生成器,可以使用遍历的方法打印
可以看到类型为生成器,可以使用遍历的方法打印
for string in soup.strings:
print( repr(string) )

可以看到返回值里面有很多空白字符,可以是用另一种方法来打印结果
##stripped_strings
for string in soup.stripped_strings:
print( string )

**
搜索文档树
**
find_all( name , attrs , recursive , text , kwargs )
##使用name参数
***主要是查找所有符合的标签
example:for string in soup.find_all( ‘p’ ):
print( string )
 也可以传入正则表达式和列表
也可以传入正则表达式和列表
example: for string in soup.find_all( re.compile(^b)):
print( string )

example: for string in soup.find_all( [‘a’,‘b’]):
print( string )

for string in soup.find_all( True ) :
print( string.name )
打印所有的tag
##keyword参数
使用的是标签内部的属性来匹配的( name匹配的是tag)
example: print( soup.find_all( id=‘link1’))
print( soup.find_all( attrs={‘id’:‘link1’})
使用第二种方法可以匹配除了’id’ 'class_'外的特殊的属性
注意匹配class属性时应该使用class_
print( soup.find_all(class_="*" ) )
因为class为python中的关键字
##limit参数
主要是限制匹配的个数(主要用于能够成功匹配的个数太多时)
example: for p in soup.find_all( ‘p’ ):
print( p )

for p in soup.find_all( ‘p’ , limit = 2 ) :
print( p )
 limit参数限制了匹配的个数
limit参数限制了匹配的个数
##text参数( 匹配文档内容)
example:print( soup.find_all( text=‘Elsie’) )
print( soup.find_all(text=[‘Elsie’,‘Tille’]) )
**其他几个参数大家可以自己查看文档
**
find方法可以看作是find_all方法的一个子集,可以把find_all是由多个find方法重复得到的
css选择器
**通过标签名来寻找
print( soup.select('title) )

**通过类名来查找
print( soup.select(’.sister’) )

**通过id名来查找
print( soup.select(’#link1’)

不在同一节点上的要使用空格分开,在同一节点上的不加空格
**通过组合来查找
print( soup.select(‘p .sister#link1’ )

#下面了解一下对于孩子节点的输出方法
1.使用content使得tag的子节点以列表的方式输出
print( soup.html.contents)

2.使用children生成一个list生成器对象
for child in soup.html.children:
print( child )

3.使用descendants输出所有的子孙节点
for childe in soup.descendants :
print( child )
 总结descendant和前面的两种方法时不相同的,descendant是将所有的节点一个一个遍历,如abcde先访问a包含的即bcde,再访问b包含的cde,以此类推
总结descendant和前面的两种方法时不相同的,descendant是将所有的节点一个一个遍历,如abcde先访问a包含的即bcde,再访问b包含的cde,以此类推
好了,就先总结到这里吧,好累了,大家都加油吧!















 4372
4372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











