







selenium自动化框架入门
0、简单说明原理
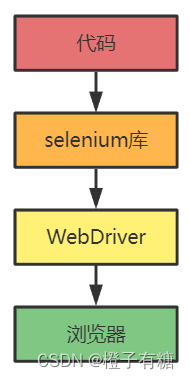
简单来讲,代码调用selenium库的一些方法,selenium库发送http请求给WebDriver,WebDriver解析请求之后打开浏览器,操作网页。
字不如表、表不如图
1、安装selenium及相关工具
1.1安装selenium
比较简单,进入命令提示符之后直接使用pip命令即可安装
pip install selenium
注意,现在(2023年2月9号)selenium最新版本是selenium 4.x,如果你想安装selenium 4的版本,需要保持Python版本在3.7以上,我之前Python是3.6的,就一直不能安装selenium 4的版本,直接安装就是selenium 3的版本,也无法升级到selenium 4.
1.2安装浏览器
这里我平常用的就是谷歌浏览器。
附一个链接吧:
谷歌浏览器官网
国内也可以到一些软件网站上去下载,不过往往不是最新版
腾讯软件中心谷歌浏览器
1.3下载浏览器驱动
需要下载与自己的浏览器匹配的驱动,我这里用的就是谷歌浏览器驱动
谷歌浏览器驱动
2、简单体验selenium
2.1使用selenium自动打开百度首页
要实现这个功能,可以这样写
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 创建 WebDriver 对象,指明chrome浏览器驱动文件路径
wd = webdriver.Chrome(service=Service(r"D:\ChromeDriver\chromedriver_win32\chromedriver.exe"))
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get(r"https://www.baidu.com/")
input()#加上一个阻塞,避免程序快速执行完毕之后网页关闭
上述代码运行之后可以自动打开你电脑上的谷歌浏览器,并且输入百度的网址访问它
2.2添加环境变量,简化代码
不过这样每次想操作浏览器都需要去写一遍浏览器驱动的路径,就很麻烦,可以把浏览器驱动所在目录【不包含文件名】添加到环境变量中,selenium库会自动在环境变量Path中搜索chromedriver.exe,这样就不用再在代码中指明浏览器驱动的文件路径了,
添加环境变量的方法:
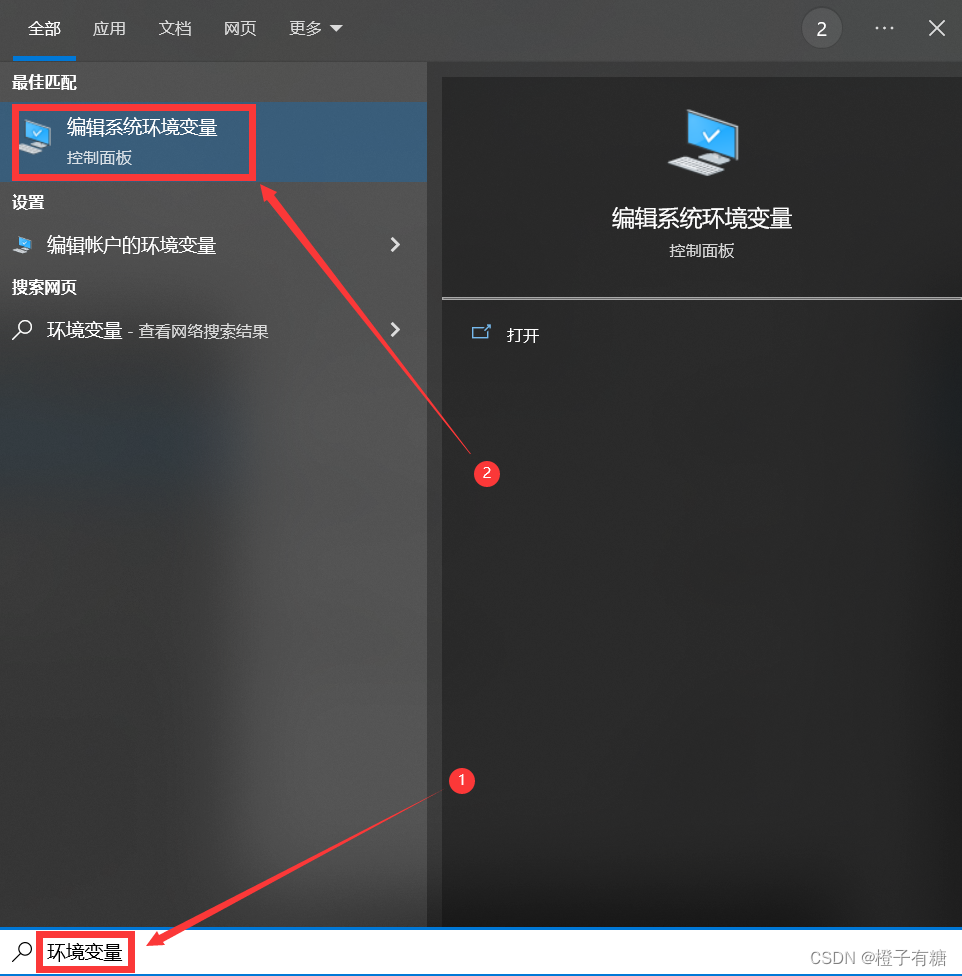
1、按win,输入【环境变量】
2、点击【编辑系统环境变量】
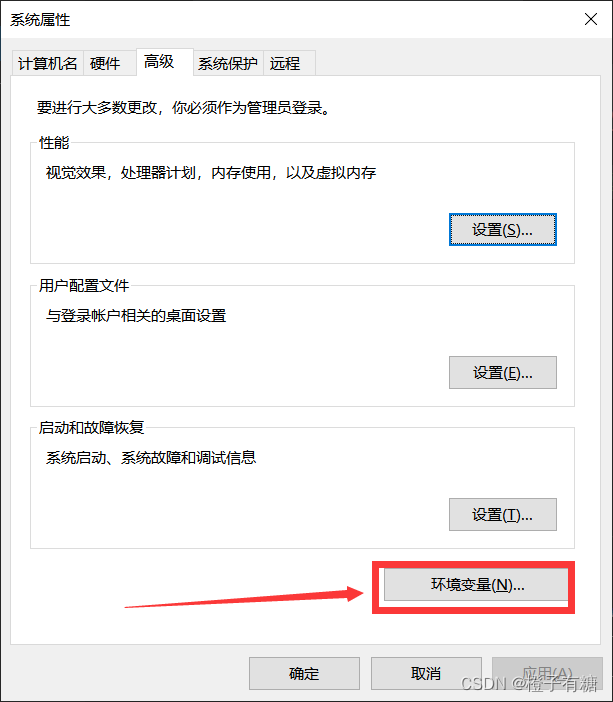
3、点击环境变量
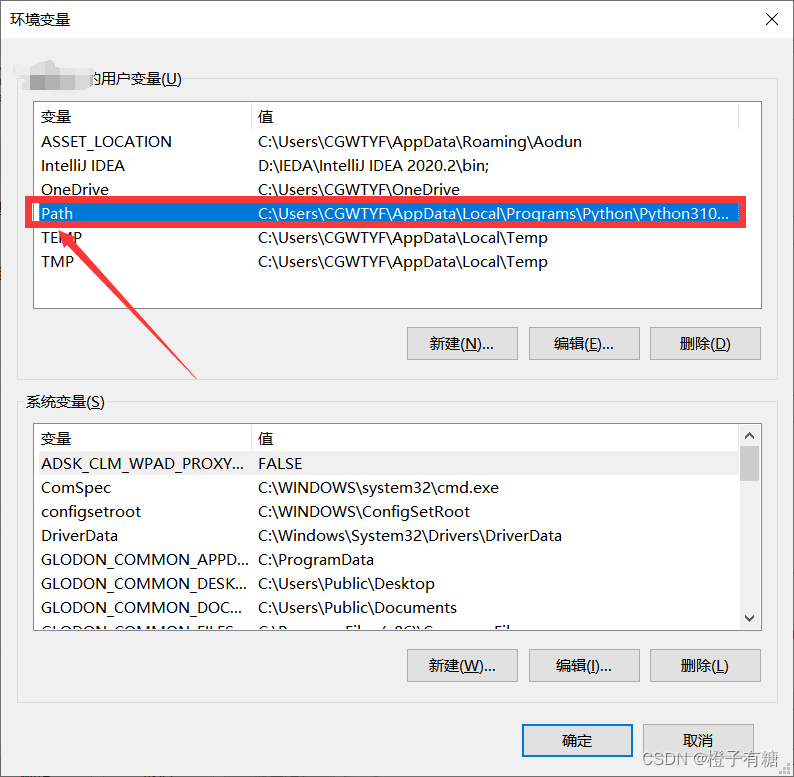
4、双击Path
5、点击新建
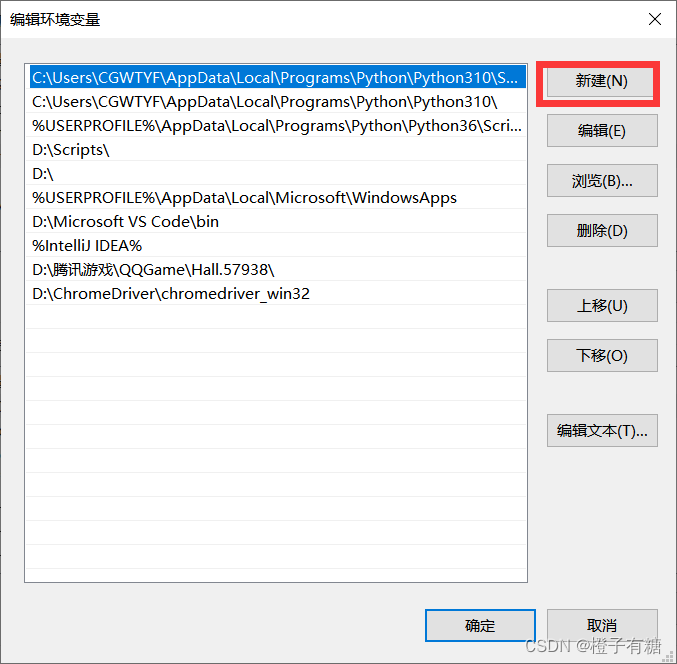
6、把自己的浏览器驱动所在文件夹的路径粘贴进来即可
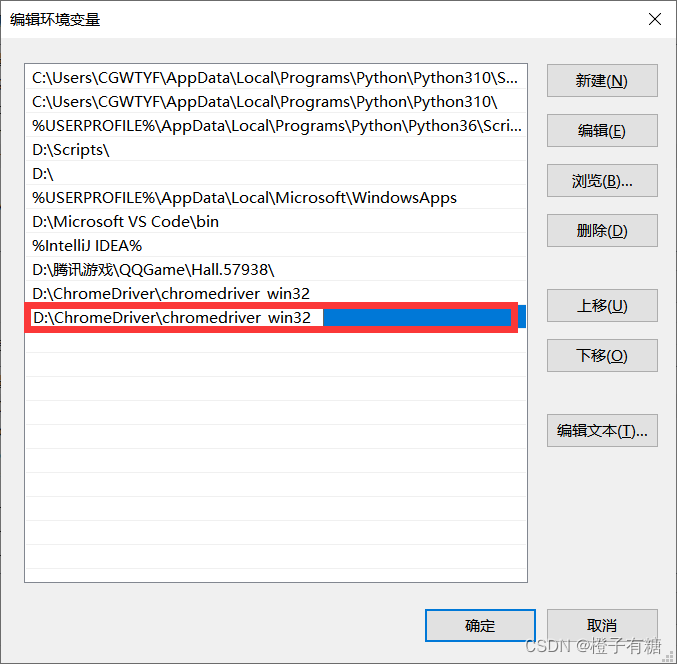
注意,这里不能把驱动文件名一起写进来,路径只到驱动文件所在的文件夹就可以了。
比如这样写就是错的:
D:\ChromeDriver\chromedriver_win32\chromedriver.exe
应该这样写:
D:\ChromeDriver\chromedriver_win32
另外,添加完之后,需要一层层点击【确定】退出编辑
添加好环境变量之后,上述代码就可以优化为这样:
from selenium import webdriver
# from selenium.webdriver.chrome.service import Service
# 创建 WebDriver 对象,指明chrome浏览器驱动文件路径
wd = webdriver.Chrome()
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get(r"https://www.baidu.com/")
input()#加上一个阻塞,避免程序快速执行完毕之后网页关闭
第二行代码不需要了,第五行代码的参数也可以不用了。
3、定位页面元素
学会打开页面之后,我们可能会想操作这个页面,而操作之前,你得先告诉浏览器你要操作的元素是哪一个,比如你想点击某个按钮,你想在某个输入框输入内容,这些都需要你提前告诉浏览器你要点击的按钮是【哪一个】,你要输入内容的输入框是【哪一个】
3.1按照id定位元素
这需要一点前端的知识,在html文件中很多标签都有自己的id,这个id是唯一对应这一个标签的(当然,有些程序员可能不遵守这个规范,导致一个id对应多个标签),我们只需要给出我们想要找的标签的id,就可以定位这个元素。
比如,下图中百度首页的【百度一下】按钮,他的id就是【su】

那我们根据id为su即可找到这个按钮,同样的方法我们可以找到输入框的id,于是我们可以写出下面的代码。
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome()
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get("https://www.baidu.com/")
#找到输入框
inpt=wd.find_element(By.ID,"kw")
#在输入框中输入内容
inpt.send_keys("大橙子\n")#发送一段文本进输入框
input()
这个代码可以打开百度首页,在输入框里面输入【大橙子】并回车,结果就是搜索出关键词为【大橙子】的一些网页,like this。

其中find_element()方法就是定位页面元素的方法,第一个参数指的是通过id定位,第二个参数给出需要定位的元素的id。send_keys()方法则是向该输入框中写入一串文本,文本作为参数给出。
3.2按照class名定位元素
比如要实现把百度左上角这些文字全部打印出来,可以这样写
from selenium import webdriver
from selenium.webdriver.common.by import By
wd=webdriver.Chrome()#打开浏览器驱动
wd.get("https://www.baidu.com")#打开网址
elements=wd.find_elements(By.CLASS_NAME,"mnav")#获取页面元素
for i in elements:
print(i.text)
input()
运行结果如下:
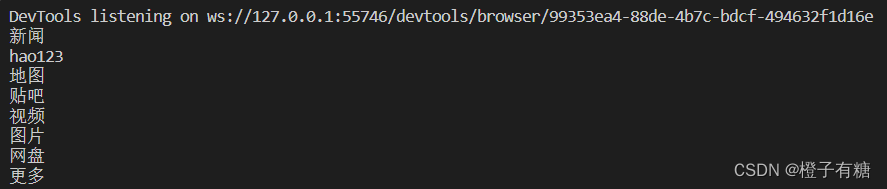
其中find_elements()方法可以找到符合要求的所有元素,结果存到一个列表里,作为返回值。如果没有符合要求的元素就返回空列表。
3.3按照标签名定位元素
对于需要定位多个元素,我们还可以使用By.TAG_NAME作为find_elements的参数,这是按照页面中的标签名作为参数来定位匹配的元素,下面的代码可以打印出页面中所有div元素的text。
from selenium import webdriver
from selenium.webdriver.common.by import By
wd=webdriver.Chrome()#打开浏览器驱动
wd.get("https://www.baidu.com")#打开网址
elements=wd.find_elements(By.TAG_NAME,"div")#获取页面元素
for i in elements:
print(i.text)
input()
运行结果:
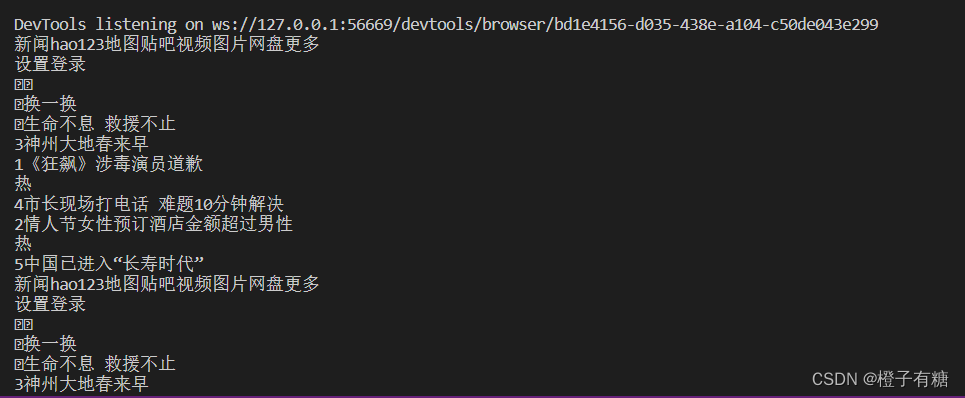
3.4从页面元素中定位元素
上面讲的方法都是直接从页面中寻找我们想要的元素,但是有些情况下我们可能需要在某个或者某些特定的元素内部去寻找元素,这个时候就不能直接用WebDriver对象的find_element或者find_elements方法了。而是要使用WebElement对象的find_element或者find_elements方法。
比如下面这个代码也可以实现打印出百度左上角所有文字的功能,不过定位的过程是不太一样的。
from selenium import webdriver
from selenium.webdriver.common.by import By
wd=webdriver.Chrome()#打开浏览器驱动
wd.get("https://www.baidu.com")#打开网址
leftTop=wd.find_element(By.ID,"s-top-left")#定位到左上角的div
elements=leftTop.find_elements(By.TAG_NAME,"a")#定位到左上角的a标签
for i in elements:
print(i.text)
input()
3.5等待浏览器返回结果
有时候,我们操作浏览器搜索某些内容时,浏览器发送请求给服务器,服务器再返回结果给浏览器渲染,这个时间会比较长,以至于我们的程序想操作搜索出来的结果就不得不等待一下,如果你不等待有可能就会找不到这个页面元素而抛出NoSuchElementException异常。
比如我想搜索【橙子有糖的csdn博客】,并且点击进第一个搜索结果,那么我们现在学到的知识就可以这样写:
from selenium import webdriver
from selenium.webdriver.common.by import By
wd=webdriver.Chrome()
wd.get("https://www.baidu.com")
ipt=wd.find_element(By.ID,"kw")
ipt.send_keys("橙子有糖的csdn博客\n")
first=wd.find_element(By.CLASS_NAME,"result")#定位到第一个搜索结果
tietle=first.find_element(By.TAG_NAME,"a")#定位到第一个搜索结果的a标签
tietle.click()#点击文章标题
input()
结果如下:

你会发现,明明逻辑没有问题,但是还是报了一个NoSuchElementException异常。这就是浏览器发送请求——服务器处理并返回结果——浏览器渲染到页面上,这个过程时间比我们的代码时间长,导致的问题。
那么有人可能会想到我这里等待一会就行了,比如用sleep语句让程序暂停一会,但是这里问题是sleep的时间应该设置为多少?短了有可能还是来不及,长了又浪费时间。
为了解决这个问题,selenium官方提供了一个办法——implicitly_wait,中文叫隐式等待。
我们只需要加一行代码就可以解决:
from selenium import webdriver
from selenium.webdriver.common.by import By
wd=webdriver.Chrome()
wd.get("https://www.baidu.com")
wd.implicitly_wait(3)
ipt=wd.find_element(By.ID,"kw")
ipt.send_keys("橙子有糖的csdn博客\n")
first=wd.find_element(By.CLASS_NAME,"result")#定位到第一个搜索结果
tietle=first.find_element(By.TAG_NAME,"a")#定位到第一个搜索结果的a标签
tietle.click()#点击文章标题
input()
注意第五行代码,加上wd.implicitly_wait(3)就可以让程序在3秒内每隔一段时间就尝试find,如果有结果了就继续往下执行,没结果就一直尝试,直到超过3秒。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









