









例题描述
编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之前。
给定一个链表的头指针 ListNode* pHead,请返回重新排列后的链表的头指针。
(注意:分割以后保持原来的数据顺序不变)
示例:
- 输入:
9->5->2->7,x = 4 - 输出:
2->9->5->7
结点结构体定义
typedef struct ListNode {
int val;
struct ListNode *next;
} ListNode;
解题思路
创建两条链表,小于此值得放入小链表,大于此值放入大链表,然后通过尾结点指针将两条链表合并起来。
- 判断极端条件,如果链表为空,既给定值也无法分割,直接返回空。
- 创建大链表
bigger,存放所有大于此值的结点。创建小链表samller,存放所有小于此值的结点。但二者的指向都只是一个假结点是存放了一个无效值的头结点,从它们的next结点才开始存放旧链表中的值。因为这样可以更好的使尾指针进行运作。 - 因为需要搬运结点以及链接两链表,所以各自建立一个尾指针,作为搬运工,并初始化为各自头指针的指向。
- 创建当前结点
cur,为循环判断条件,优先级最高,并初始化为链表首结点。
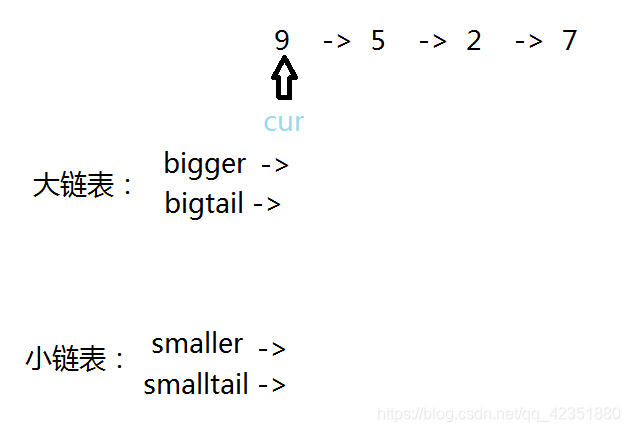
- 通过判断当前指针的有效性来决定是否继续执行循环逻辑。如果不为空,进行判定逻辑:
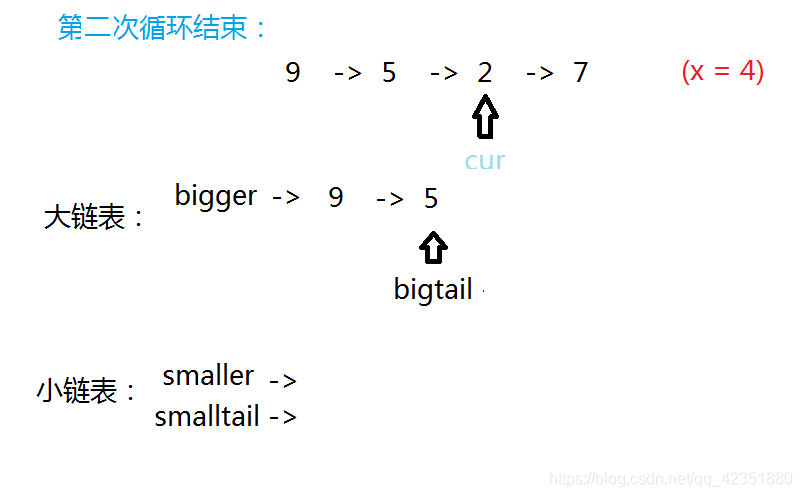
若当前结点值小于给定值,将它尾插入小链表,并更新小链表尾结点及当前指针的指向。
若当前结点值大于等于给定值,将它尾插入大链表,并更新大链表尾结点及当前指针的指向。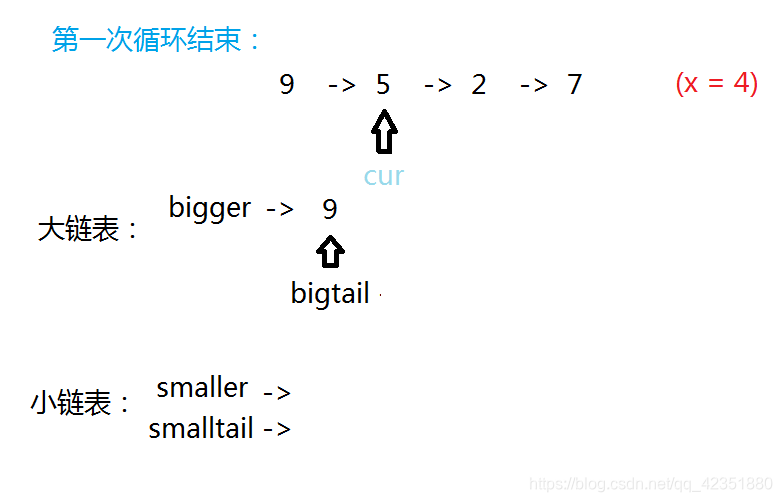
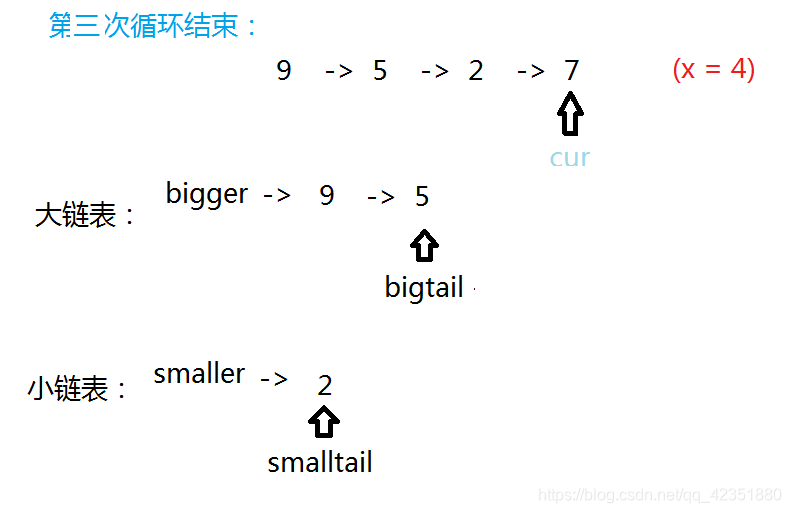
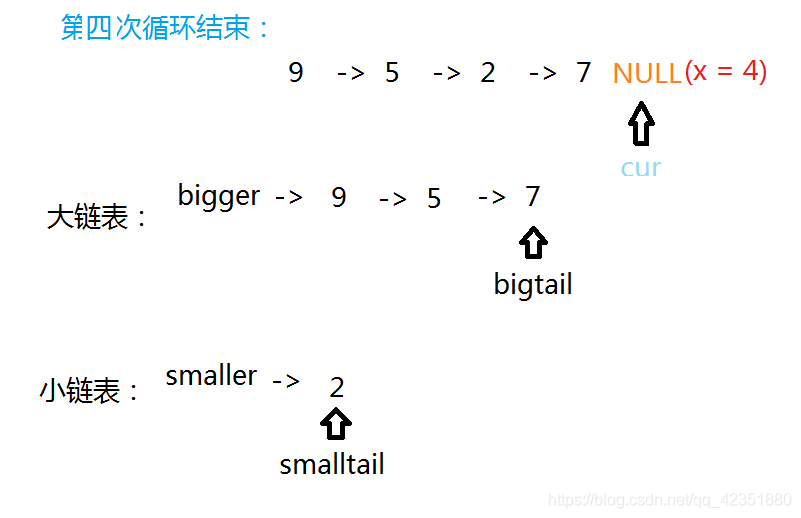
- 最后执行链接逻辑,手动将小链表的尾指针
smalltail的next指向大链表的bigger的next结点。将大链表的尾结点置为NULL,保证链表的有限性。
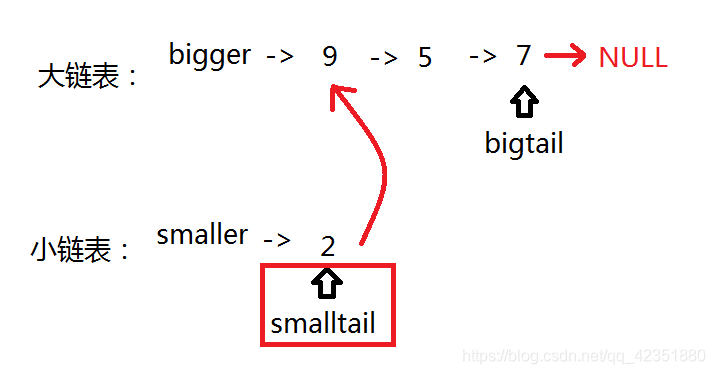
- 最终忽略假结点,返回小链表的
smaller的next结点即可。
实现一
ListNode* partition(ListNode* pHead, int x) {
if (pHead == NULL) {
return NULL;
}
//1. 创建两链表
struct ListNode *smaller = (struct ListNode*)malloc(sizeof(ListNode)*x);
struct ListNode *bigger = (struct ListNode*)malloc(sizeof(ListNode)*x);
struct ListNode *cur = pHead;
struct ListNode *smalltail = smaller;
struct ListNode *bigtail = bigger;
while(cur){
if(cur->val < x){
smalltail->next = cur;
smalltail = cur;
}else{
bigtail->next = cur;
bigtail = cur;
}
cur = cur->next;
}
smalltail->next = bigger->next;
bigtail->next = NULL;
return smaller->next;
}
实现二
ListNode* partition(ListNode* pHead, int x) {
struct ListNode *small = NULL;
struct ListNode *smalllast = NULL;
struct ListNode *big = NULL;
struct ListNode *biglast = NULL;
struct ListNode *node = pHead;
while(node){
if(node->val < x){
if(small == NULL){
small = smalllast = node;
}else{
smalllast->next = node;
smalllast = node;
}
}else{
if(big == NULL){
big = biglast = node;
}else{
biglast->next = node;
biglast = node;
}
}
node = node->next;
}
if(smalllast != NULL){ //一个比他小的都没有
smalllast->next = big;
}
if(biglast != NULL){ //一个比他小的都没有
biglast->next = NULL;
}
if(smalllast != NULL){
return small;
}
else{
return big;
}
}















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











