







先来看一下相关概念
爬虫的定义
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
只要是浏览器能做的事情,原则上,爬虫都能够做
通用爬虫和聚焦爬虫
通用爬虫:通用爬虫是搜索引擎抓取系统(百度、谷歌、搜狗等)的重要组成部分。主要是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
聚焦爬虫:是面向特定需求的一种网络爬虫程序,他与通用爬虫的区别在于:聚焦爬虫在实施网页抓取的时候会对内容进行筛选和处理,尽量保证只抓取与需求相关的网页信息。
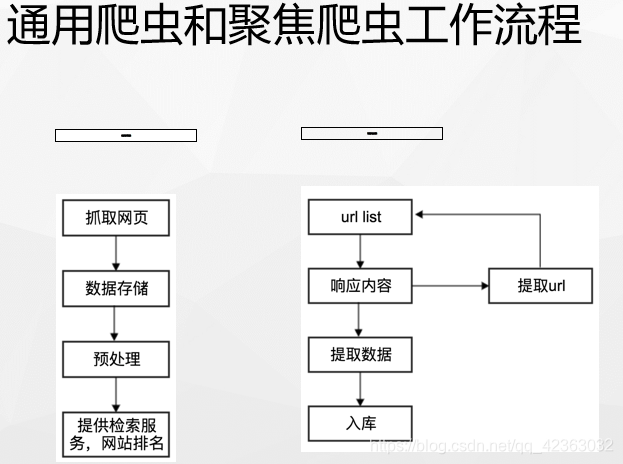
通用爬虫的局限性
- 通用搜索引擎所返回的网页里90%的内容无用。
- 图片、音频、视频多媒体的内容通用搜索引擎无能为力
- 不同用户搜索的目的不全相同,但是返回内容相同
robots协议
Robots协议:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
例如:https://www.taobao.com/robots.txt
(没有法律效应,只能从道德上规范)
http和https
- http
- 超文本传输协议
- 默认端口号:80
- https
- http + ssl(安全套接字层)
- 默认端口号:443



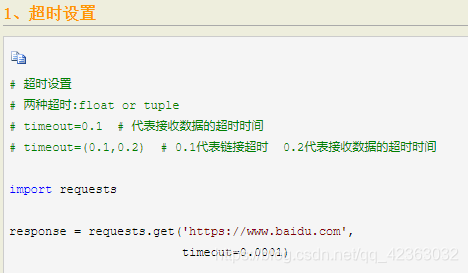
GET请求
爬百度首页
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
# 使用requests对百度首页发送get请求
response = requests.get(url="https://www.baidu.com", headers=headers)
# 修改响应的编码格式
response.encoding = "utf-8"
print(type(response.text))
print(response.text)
# print(response.content.decode())
下载百度首页logo
res = requests.get("https://www.baidu.com/img/bd_logo1.png")
r = res.content
with open("百度logo.png", "wb") as fb:
fb.write(r)
下载音频
res = requests.get(url="http://m7.music.126.net/20200417205744/f2c9453922920974ceebe76d4643d905/ymusic/025b/525d/040c/51958d1f13e76f9787173fe94bdca8fc.mp3")
with open("与我无关.mp3", "wb") as fb:
fb.write(res.content)
下载视频
res = requests.get("https://vdept.bdstatic.com/4966507a78694a51494a376476763847/5731313372494872/e9fb83f3ad6585df24fa02299409d5538c91f56f918e0216bd1f8b0747ebf46a7aea32ecd49d34ce11bbc9cfed7e56788fa24c177211c2aa2b51b9d92d5afef2.mp4?auth_key=1587134240-0-0-620b397d617996e1da54f3a9593e6308")
with open("111.mp4", "wb") as fb:
fb.write(res.content)
传参
1.直接拼到地址后面
res = requests.get('http://httpbin.org/get?name=zhangsan&pwd=123')
print(res.text)
2.使用params参数传递
params = {
'wd':'lisi',
'pwd':'456'
}
res = requests.get('http://httpbin.org/get',params=params)
print(res.text)

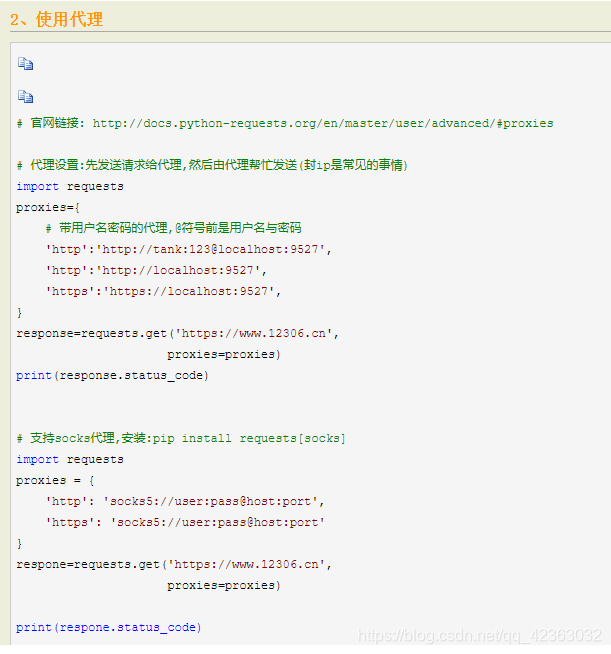
POST请求
传参
使用data参数传递
# params能传递,但还是和拼接到url后面一样
params = {
'a':'b'
}
# data传递的数据是放到formdata里面的,类似页面的form表单提交
data = {
'c':'d'
}
res = requests.post('http://httpbin.org/post',params=params,data=data)
print(res.text)
有道翻译
import requests
import re
key_word = input("请输入你要翻译的内容:")
data = {
'inputtext': key_word,
'type': 'AUTO'
}
res = requests.post('http://wap.youdao.com/translate',data=data)
# print(res.text)
result = re.findall(r'<li>(.*?)</li>',res.text)[-1]
print(result)
有道翻译多种语言
import requests
import re
# strName = input("待翻译:")
strName = '小王王'
print("翻译" + strName)
# 自动检测,即中英
data1 = {
'inputtext': strName,
'type': 'AUTO'
}
# 中->日
data2 = {
'inputtext': strName,
'type': 'ZH_CN2JA'
}
# 中->韩
data3 = {
'inputtext': strName,
'type': 'ZH_CN2KR'
}
# 中->法
data4 = {
'inputtext': strName,
'type': 'ZH_CN2FR'
}
# 中->俄
data5 = {
'inputtext': strName,
'type': 'ZH_CN2RU'
}
# 中->西
data6 = {
'inputtext': strName,
'type': 'ZH_CN2SP'
}
res1 = requests.post("http://wap.youdao.com/translate", data=data1)
res2 = requests.post("http://wap.youdao.com/translate", data=data2)
res3 = requests.post("http://wap.youdao.com/translate", data=data3)
res4 = requests.post("http://wap.youdao.com/translate", data=data4)
res5 = requests.post("http://wap.youdao.com/translate", data=data5)
res6 = requests.post("http://wap.youdao.com/translate", data=data6)
result1 = re.findall("<li>(.*?)</li>", res1.text)[-1]
result2 = re.findall("<li>(.*?)</li>", res2.text)[-1]
result3 = re.findall("<li>(.*?)</li>", res3.text)[-1]
result4 = re.findall("<li>(.*?)</li>", res4.text)[-1]
result5 = re.findall("<li>(.*?)</li>", res5.text)[-1]
result6 = re.findall("<li>(.*?)</li>", res6.text)[-1]
print("中->英", result1)
print("中->日", result2)
print("中->韩", result3)
print("中->法", result4)
print("中->俄", result5)
print("中->西", result6)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











