




 本文详细介绍了C/C++编程中的字节对齐问题,包括结构体、栈内存和位域对齐的概念、原因、准则及实际应用。通过对不同对齐方式的探讨,揭示了编译器在数据存储中如何处理对齐,以及对齐对程序性能和内存使用的影响。同时,文章提供了多个示例和准则,帮助读者理解字节对齐的复杂性和重要性。
本文详细介绍了C/C++编程中的字节对齐问题,包括结构体、栈内存和位域对齐的概念、原因、准则及实际应用。通过对不同对齐方式的探讨,揭示了编译器在数据存储中如何处理对齐,以及对齐对程序性能和内存使用的影响。同时,文章提供了多个示例和准则,帮助读者理解字节对齐的复杂性和重要性。
引言
考虑下面的结构体定义:

假设这个结构体的成员在内存中是紧凑排列的,且c1的起始地址是0,则s的地址就是1,c2的地址是3,i的地址是4。
现在,我们编写一个简单的程序:
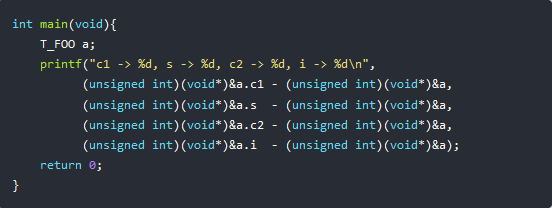
运行后输出:

为什么会这样?这就是字节对齐导致的问题。
本文在参考诸多资料的基础上,详细介绍常见的字节对齐问题。因成文较早,资料来源大多已不可考,敬请谅解。
一,什么是字节对齐
现代计算机中,内存空间按照字节划分,理论上可以从任何起始地址访问任意类型的变量。但实际中在访问特定类型变量时经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序一个接一个地存放,这就是对齐。
二,对齐的原因和作用
不同硬件平台对存储空间的处理上存在很大的不同。某些平台对特定类型的数据只能从特定地址开始存取,而不允许其在内存中任意存放。例如Motorola 68000处理器不允许16位的字存放在奇地址,否则会触发异常,因此在这种架构下编程必须保证字节对齐。
但最常见的情况是,如果不按照平台要求对数据存放进行对齐,会带来存取效率上的损失。比如32位的Intel处理器通过总线访问(包括读和写)内存数据。每个总线周期从偶地址开始访问32位内存数据,内存数据以字节为单位存放。如果一个32位的数据没有存放在4字节整除的内存地址处,那么处理器就需要2个总线周期对其进行访问,显然访问效率下降很多。
因此,通过合理的内存对齐可以提高访问效率。为使CPU能够对数据进行快速访问,数据的起始地址应具有“对齐”特性。比如4字节数据的起始地址应位于4字节边界上,即起始地址能够被4整除。
此外,合理利用字节对齐还可以有效地节省存储空间。但要注意,在32位机中使用1字节或2字节对齐,反而会降低变量访问速度。因此需要考虑处理器类型。还应考虑编译器的类型。在VC/C++和GNU GCC中都是默认是4字节对齐。
三,对齐的分类和准则
主要基于Intel X86架构介绍结构体对齐和栈内存对齐,位域本质上为结构体类型。
对于Intel X86平台,每次分配内存应该是从4的整数倍地址开始分配,无论是对结构体变量还是简单类型的变量。
3.1 结构体对齐
在C语言中,结构体是种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构体、联合等)的数据单元。编译器为结构体的每个成员按照其自然边界(alignment)分配空间。各成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。
字节对齐的问题主要就是针对结构体。
3.1.1 简单示例
先看个简单的例子(32位,X86处理器,GCC编译器):
【例1】设结构体如下定义:

已知32位机器上各数据类型的长度为:char为1字节、short为2字节、int为4字节、long为4字节、float为4字节、double为8字节。那么上面两个结构体大小如何呢?
结果是:sizeof(strcut A)值为8;sizeof(struct B)的值却是12。
结构体A中包含一个4字节的int数据,一个1字节char数据和一个2字节short数据;B也一样。按理说A和B大小应该都是7字节。之所以出现上述结果,就是因为编译器要对数据成员在空间上进行对齐。
3.1.2 对齐准则
先来看四个重要的基本概念:
(1)数据类型自身的对齐值:char型数据自身对齐值为1字节,short型数据为2字节,int/float型为4字节,double型为8字节。
(2)结构体或类的自身对齐值:其成员中自身对齐值最大的那个值。
(3)指定对齐值:#pragma pack (value)时的指定对齐值value。
(4)数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小者,即有效对齐值=min{自身对齐值,当前指定的pack值}。
基于上面这些值,就可以方便地讨论具体数据结构的成员和其自身的对齐方式。
其中,有效对齐值N是最终用来决定数据存放地址方式的值。有效对齐N表示“对齐在N上”,即该数据的“存放起始地址%N=0”。而数据结构中的数据变量都是按定义的先后顺序存放。第一个数据变量的起始地址就是数据结构的起始地址。结构体的成员变量要对齐存放,结构体本身也要根据自身的有效对齐值圆整(即结构体成员变量占用总长度为结构体有效对齐值的整数倍)。
以此分析3.1.1节中的结构体B:
假设B从地址空间0x0000开始存放,且指定对齐值默认为4(4字节对齐)。成员变量b的自身对齐值是1,比默认指定对齐值4小,所以其有效对齐值为1,其存放地
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1735
1735




 到【灌水乐园】发言
到【灌水乐园】发言







