







神经网络语言模型
本文一共回答了六个问题,这六个问题可以分为两个部分:
- 神经网络基本原理
- 神经网络+语言模型 = 神经网络语言模型
第一部分:
- 一、什么是神经网络?
- 二、神经网络的基本结构是什么?
- 三、神经网络为什么能解决问题?
- 四、卷积神经网络跟经典的神经网络有什么差异?
第二部分:
- 五、神经网络怎么在语言模型层面进行应用?
- 六、为什么会想到用神经网络来构件语言模型?
什么是神经网络?
神经网络是一种模拟人脑神经元连接结构的机器学习模型。
如果之前听过什么输入层、隐藏层、输出层,那这些概念就是来自神经网络。
如果没听过,那就简单理解神经网络就是用一堆矩阵来模拟某一个连续函数,我们可能不知道这个函数是长什么样的,但是我们猜有这么一个函数F(X),当我们给定输入X,F(X)有一个输出G,G就是神经网络根据输入预测的输出。
神经网络的基本结构是什么?
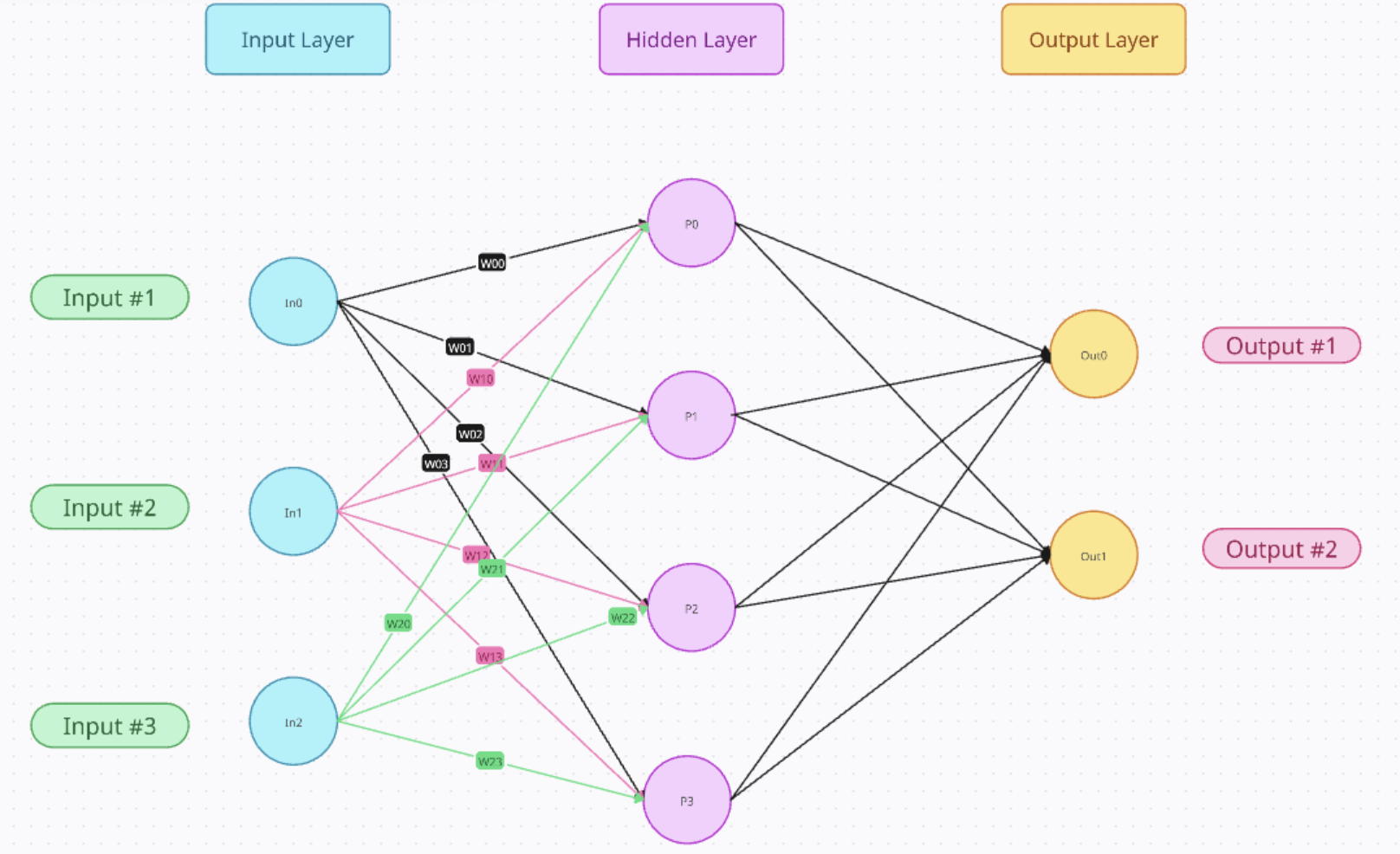
神经网络的结构包括:
- 层数(几层隐藏层)
- 每层的神经元数目
- 相邻层之间神经元相连的权重
- 每层使用的激活函数
输入层
接受原始数据(如图像像素、音频、文本向量)
所谓的输入层,就是将输入数据用离散的数据表示,为什么需要离散,因为现实世界是连续的,有些概念是抽象的,例如文字的“你”、“我”,我们告诉计算机说输入一个“你”、“我”,实际上也是将“你”、“我”变成一堆010101010…,我理解这就是离散的过程,也就是输入层的作用:将现实中的数据以向量/矩阵等计算机可以进行运算的格式进行表示。
隐藏层
通过加权和+激活函数提取特征
隐藏层很"简单",就是外界数据通过输入层之后,变成了一堆计算机可以运算的数据,隐藏层对数据刷刷一堆操作,最后输出到输出层。
输出层
输出预测结果
输出层可以简单理解为函数的输出值,只不过输出值可以用输出层的节点来组合表示。最简单的是如果F(X)的结果只可能是0~9十个数,那么输出层的节点个数就可以设为10。
神经网络为什么能解决问题?
通用近似定理
依据理论为“通用近似定理”,经典论述为:
一个具有足够数量隐藏单元、非线性激活函数 的前馈神经网络,可以以任意精度逼近定义在紧致空间上的任意连续函数。
换句话说,只要网络足够大,它就能学会从输入到输出的任意连续映射。
所以有时候我们会听到类似“算的不够准?再加节点!再加一层!”的说法。
【一些思考】我个人理解这个过程有点像多项式拟合一个连续函数,我只要把多项式的项数加的够多,总能拟合出来的,不够准确?那就再加一项!
为什么需要权重和偏置?为什么需要激活函数?
首先是权重和偏置,他们两是线性的,是根据上一层的数据简单的线性组合。例如输入是In0、In1、In2,想要知道他们对P0结果的贡献,
r
e
s
0
=
I
n
0
∗
W
00
+
I
n
1
∗
W
10
+
I
n
2
∗
W
20
+
B
0
res0 = In0 * W00 + In1 * W10 + In2 * W20 + B0
res0=In0∗W00+In1∗W10+In2∗W20+B0
这里使用res0代表他不是最终值,而只是一个中间值,Wxx代表权重,B0代表偏置,这里只是想要表达一个大概的计算流程
可以看出来,都是线性组合,如果只有权重和偏置,没有激活函数,神经网络是一个线性变换堆叠(即矩阵乘法),只能拟合线性关系。为了求得可以拟合的更多结果,需要加入激活函数。
加入非线性激活函数(如 ReLU、Sigmoid、Tanh)后,网络就可以表达更复杂、非线性的函数。
激活函数有很多种,这里随便放一张图来表示激活函数的样式
A
c
t
F
u
n
c
(
r
e
s
0
)
【
A
c
t
F
u
n
c
代表激活函数】
ActFunc(res0) 【ActFunc代表激活函数】
ActFunc(res0)【ActFunc代表激活函数】
【一些思考】我对权重、偏置和激活函数的理解就是:线性+非线性=非线性。
通过激活函数引入非线性,使得神经网络可以表达非线性的函数,因为生活中需要用到神经网络来解决的问题基本都是非线性的。
而神经网络不同层之间节点的权重连接,以及在节点上的偏置,其实就是加入了更多排列组合后引入了更多的可能变化,通过引入变化来使得神经网络更能描述复杂的事物。
权重是如何确定的?
一个神经网络想要算得准,那就需要进行调整,但是对于神经网络来说,网络结构一旦确定下来,可以调整的空间就局限在权重和偏置了。
为什么不调整节点数量和激活函数?也有,这样相当于重新确定一个神经网络算法,我们从控制变量法的思想出发,先考虑权重和偏置的改变。
下边为了方便说明,我就统一用权重来表示权重+偏置
既然要确定权重的值,那么就需要考虑一个问题:
我为什么要选择这个值作为权重具体的参数值,而不是那个值?
也就是需要一个评价标准来评价权重的选择,这个标准就是:
最小化损失函数输出,即网络预测值和真实值之间的误差。
说人话就是,我选择这一批权重值能猜的准。
借用3blue1brown的比喻:
想象一个“有很多旋钮的机器”,你要不断调整这些旋钮(即权重),直到输出结果最接近你想要的答案。
下边有两种选择权重的方法:
1. 穷举
对应的权重是要调高,还是要调低,最简单的办法就是穷举!
毕竟只要给足够长的时间,一只猴子也能在打字机上打出一本《哈姆雷特》(狗头)。
不过这种方法用的比较少,因为在参数比较多的情况下,我们很难说运气好刚好找到一组合适的参数,加上人类的生命目前还是有限的,我们比较期望能够有一个方法来指导我们进行,尽快找到合适的权重。
2. 反向传播
反向传播是一种使用链式法则(Chain Rule)计算误差梯度的方法。
主要步骤:
假定神经网络很简单:
【输入x】—w1(权重)----【隐藏层】----w2(权重)—【输出】
- 前向传播:
- 将输入数据通过神经网络,得到预测输出。
这个正向的过程可以是:
- x*w1 = z1,作为隐藏层的中间结果
- σ ( z 1 ) = a 1 \sigma(z1) = a1 σ(z1)=a1,表示进行激活
- a1 * w2 = z2,作为输出层的中间结果
- σ ( z 2 ) = a 2 \sigma(z2) = a2 σ(z2)=a2,a2表示激活后输出层的最终结果,也被称为预测值 y pred y_{\text{pred}} ypred
- 计算损失:
- 使用损失函数 L ( y true , y pred ) L(y_{\text{true}}, y_{\text{pred}}) L(ytrue,ypred) 评估预测的好坏。
- 反向传播计算梯度:
- 对每一层的参数求偏导(链式法则)。
L是a2的函数,a2是z2的函数,z2是a1的函数,a1是z1的函数,z1是w1的函数,但是只要每一层都有表达式关系,我们就可以通过链式法则求得偏导数:
∂ L / ∂ w 1 = ∂ L / ∂ a 2 ⋅ ∂ a 2 / ∂ z 2 ⋅ ∂ z 2 / ∂ a 1 ⋅ ∂ a 1 / ∂ z 1 ⋅ ∂ z 1 / ∂ w 1 ∂L/∂w1 = ∂L/∂a2 ⋅ ∂a2/∂z2 ⋅ ∂z2/∂a1 ⋅ ∂a1/∂z1 ⋅ ∂z1/∂w1 ∂L/∂w1=∂L/∂a2⋅∂a2/∂z2⋅∂z2/∂a1⋅∂a1/∂z1⋅∂z1/∂w1
- 参数更新:
- 使用梯度下降等优化器来更新参数。
能使用梯度来优化参数的原因
- 误差L跟神经网络中可以调节的权重W有关,L可以表示为W和输入X的函数。
- 因此 ∂ L ∂ W \frac{∂L}{∂W} ∂W∂L就能得到L对参数W的梯度,按照梯度的定义,梯度是函数值增长最快的方向,因此梯度的反方向,就是误差L降低最快的方向。
- 函数是复杂的,我们得到的方向只是在当前这个局部点的最快下降方向,因此为了避免“走过头”,我们还需要选择“步长” : η \eta η, η \eta η同时也被称为“学习率”。
- 最终更新后的权重就是: W n e w = W o l d − ∂ L ∂ W ∗ η W_{new} = W_{old} - \frac{∂L}{∂W} * \eta Wnew=Wold−∂W∂L∗η
【一些思考】 反向传播为什么叫反向传播?因为他是通过向前传播计算之后,欸,发现算出来的值跟真实值(这里的真实值指的是训练材料给的值)有误差,就通过这个误差,把误差当成一个输入,反着来更新权重。
问题是我要怎么用这个误差,让误差来指导我更新参数,使得下一次算的时候能更贴近真实值?
就想到了L可以表示为w的函数,那么我通过求梯度,梯度的反向是函数值降低最快的方向,通过叠加梯度和步长,更新权重w,来力求让L趋于0。
这样通过反复迭代,也就能得到一个比较好的权重参数了。
卷积神经网络跟经典的神经网络有什么差异?
卷积神经网络采用了“滑动窗口”和参数共用的概念,专业点的话为
使用一个小窗口(卷积核)在图像上滑动,对局部区域执行加权求和(即卷积运算),并使用相同的权重(权重共享)。
挖个坑,后续再用一个独立的章节单独说明。
神经网络怎么在语言模型层面进行应用?
本质上,神经网络语言模型和N-Gram一样,都是预测下一个词的概率,因为神经网络是用来拟合函数的,这句话也可以表述为:
用神经网络拟合一个“下一个词的概率函数”
输入层的不同
神经网络的输入层接受的是数字,有些的场景下可以直接提供离散的数值,例如图像/音频等,可以直接用像素点的值或者频率。
但是神经网络能接受的其实是离散的数字,所以需要将输入的词转化为向量,便于后续操作,这一步称之为嵌入。
如何将词拼接成语句作为输入?
通过嵌入我们只能获取单个词的词向量,但是作为神经网络语言模型的输入,当个词肯定是不够的,起码一定量的词组成的语句才能很好的预测下一个词,毕竟“我打你”和“你打我”是不一样的,虽然他们组成的词是一样的。
参照 N-Gram 的建模方式,为了将语句中的顺序信息传入神经网络语言模型,前馈神经网络语言模型(Feedforward Neural Network Language Model) 对输入层的处理采用了嵌入+向量拼接的方式:
每个词先通过词嵌入层(Embedding Layer)转化为嵌入向量,例如:
“我” → v_我 = [0.2, 0.1, -0.3, 0.7]
“打” → v_打 = [-0.1, 0.3, 0.8, 0.2]
然后将这些向量按词语顺序拼接成一个大向量:
[v_我 ; v_打] = [0.2, 0.1, -0.3, 0.7, -0.1, 0.3, 0.8, 0.2]
这个拼接后的向量作为输入层的输入传入神经网络。因此,必须先确定上下文窗口大小 N(例如使用 N-1 个词预测下一个词),才能确定输入层的维度,即 N-1 个词 × 每个词的嵌入维度。
不过,这种方式也存在缺陷:
- 输入的上下文长度是固定的,不能适应变长句子;
- 难以建模长距离依赖;
- 对于超出窗口的上下文信息无法捕捉。
可以发现这些限制和N-Gram是很像的,因为前馈神经网络语言模型输入层的节点数量跟N-Gram依据前N-1个词预测下一个词的N-1数量是成比例的。(假设是依靠前两个词预测下一个词,嵌入向量的长度是4,前馈神经网络语言模型输入层的节点数量就是4*2 = 8)
这些限制正是后续引入循环神经网络(RNN)和 Transformer 架构的动因。
如何确定词要转化的向量值是多少?
- 第一步:生成随机的向量值
- 第二步:正向传播
- 第三步:计算损失函数
- 第四步:反向传播更新参数
不过在反向传播更新参数的时候,神经网络一般不会更新到入参,因为入参本来就是确定的。
但是!“嵌入”流程一开始生成的向量值是随机的,所以他也是可以进行更新的!
【一些思考】输入层的入参也是损失函数参数的一部分,因此也是能计算随时函数L与输入层参数x的偏导数,进行通过梯度进行更新。只是通常神经网络的输入都是确定的,总不能更新确定的东西吧(狗头)。但是神经网络语言模型不一样!可以认为确定的是“词”,但是“词”到神经网络中间的一层“嵌入”,也可以认为是一个函数变换的过程,因此也是能够进行更新的,更新“词”到对应“嵌入向量值”的过程,就相当于更新神经网络权重的过程。
这里有一个比较好的比喻:“嵌入向量”是”“词”在高维空间中的坐标点,因为我们一开始不知道这个坐标在哪,只能随便猜,但是通过反向转播,我们让这个坐标更加的准确。
嵌入矩阵
嵌入矩阵的概念是从嵌入向量引入的,在做神经网络语言模型的时候,首先需要确认词汇表的大小,也就是我需要认识多少个“词”,这样我可以给每一个词一个单独的嵌入向量,也可以在输出的时候,给出每一个词的概率,而这都需要知道“词汇表的大小”。
嵌入矩阵说白了就是一个向量的向量,
e
m
b
e
d
d
i
n
g
(
w
i
)
=
E
[
i
]
embedding(w_i) = E[i]
embedding(wi)=E[i]
其中
E
E
E是嵌入矩阵,
i
i
i是词汇表中第
i
i
i个词,
E
[
i
]
E[i]
E[i]也就是词汇表中第
i
i
i个词的嵌入向量。
输出层的不同
正如一开始所言,神经网络语言模型希望得到的结果是预测下一个词是什么, 如何表示这个结果呢?我们可以将输出层的大小设置为词汇表的大小,这样才能输出所有词的概率。
softmax
因为输出层的结果不一定是0~1之间的值,所以需要有一个办法将结果转化为概率。
softmax
(
z
i
)
=
e
z
i
∑
j
=
1
K
e
z
j
\text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}
softmax(zi)=∑j=1Kezjezi
其中,
z
i
,
z
j
z_i,z_j
zi,zj代表输出第i, j个的值。
反向传播就可以通过这个概率来计算。
【一些思考】可以将softmax计算出概率的过程看作在输出层节点上的“激活函数”,虽然不太像哈,激活函数只需要这个节点的信息,但是softmax需要所有节点的信息参与计算。
所以,通过神经网络搭建语言模型的过程中,神经网络语言模型多了嵌入计算词向量的过程和softmax计算概率的过程,而计算词向量的过程是一个可以学习的过程,词向量或者说嵌入向量更像是词在高位空间的一个映射,因此这种映射关系是可以学习的;而softmax计算出的概率,又可以跟训练材料的实际输出进行对比,计算损失函数,从而通过反向传播来更新神经网络模型的参数。
为什么会想到用神经网络来构件语言模型?
使用神经网络搭建语言模型的核心动机在于:我们认为语言可以被表示为一种连续的分布式表示,而神经网络恰好擅长拟合这类复杂的函数关系。
换句话说,我们希望构建一个预测函数,能够根据已有的上下文来预测下一个词。这个函数本质上是非线性、高维、难以显式表达的,但神经网络正好能够在数据驱动下自动学习到这种“看不见摸不着”的映射。
用ai的话来总结,就是
- 语言的本质可以用连续空间来建模
各个词之间不是孤立的,是有联系的。通过词嵌入(Word Embedding),我们将词映射到一个连续的高维向量空间,从而可以使用向量运算表达语义关系;
例如:king - man + woman ≈ queen 这样的类比关系。 - 语言可以被看作是“序列”的建模问题
也就是下一词的出现和前面的上下文息息相关 - 神经网络具有强大的表示与泛化能力
能构建“预测函数”,这个比N-Gram强多了,N-Gram只能计算已经出现过的组合,但是神经网络语言模型训练好之后就算是没出现过的组合,也能够进行预测,因为他不是通过简单的概率计算来做的。
【一些思考】我们使用神经网络搭建语言模型,是因为我们认为语言可以嵌入到一个连续空间中,并通过可学习的函数来预测词的分布。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









