







1、集合体系图
1.1、Collection 接口
单列集合
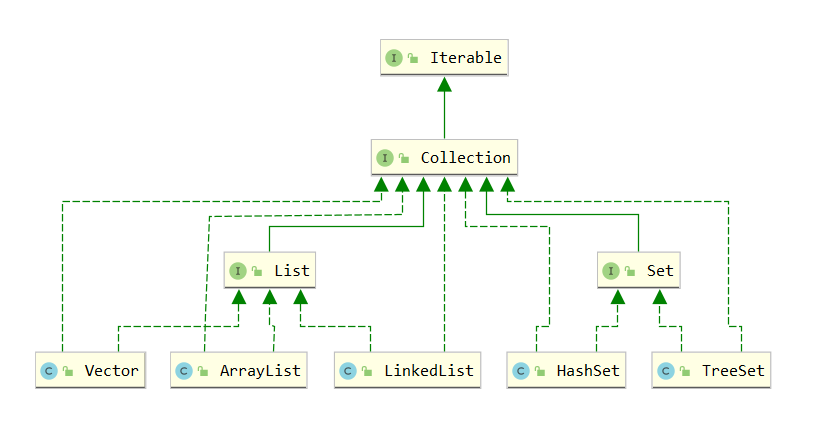
1、 Iterator对象称为迭代器,主要用于遍历Collection 集合中的元素。
2、所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了lterator接口的对象,即可以返回一个迭代器。
3、Iterator仅用于遍历集合,Iterator本身并不存放对象。
4、增强for可以理解成就是简化版本的迭代器遍历。
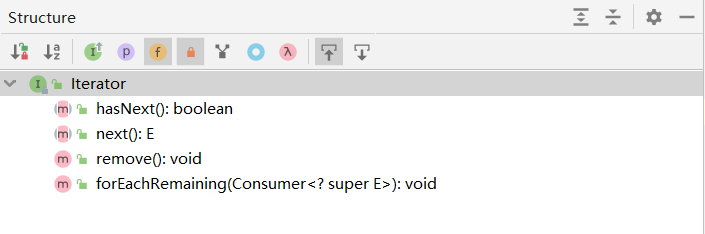
1.2、Map 接口
双列集合
2、List 集合
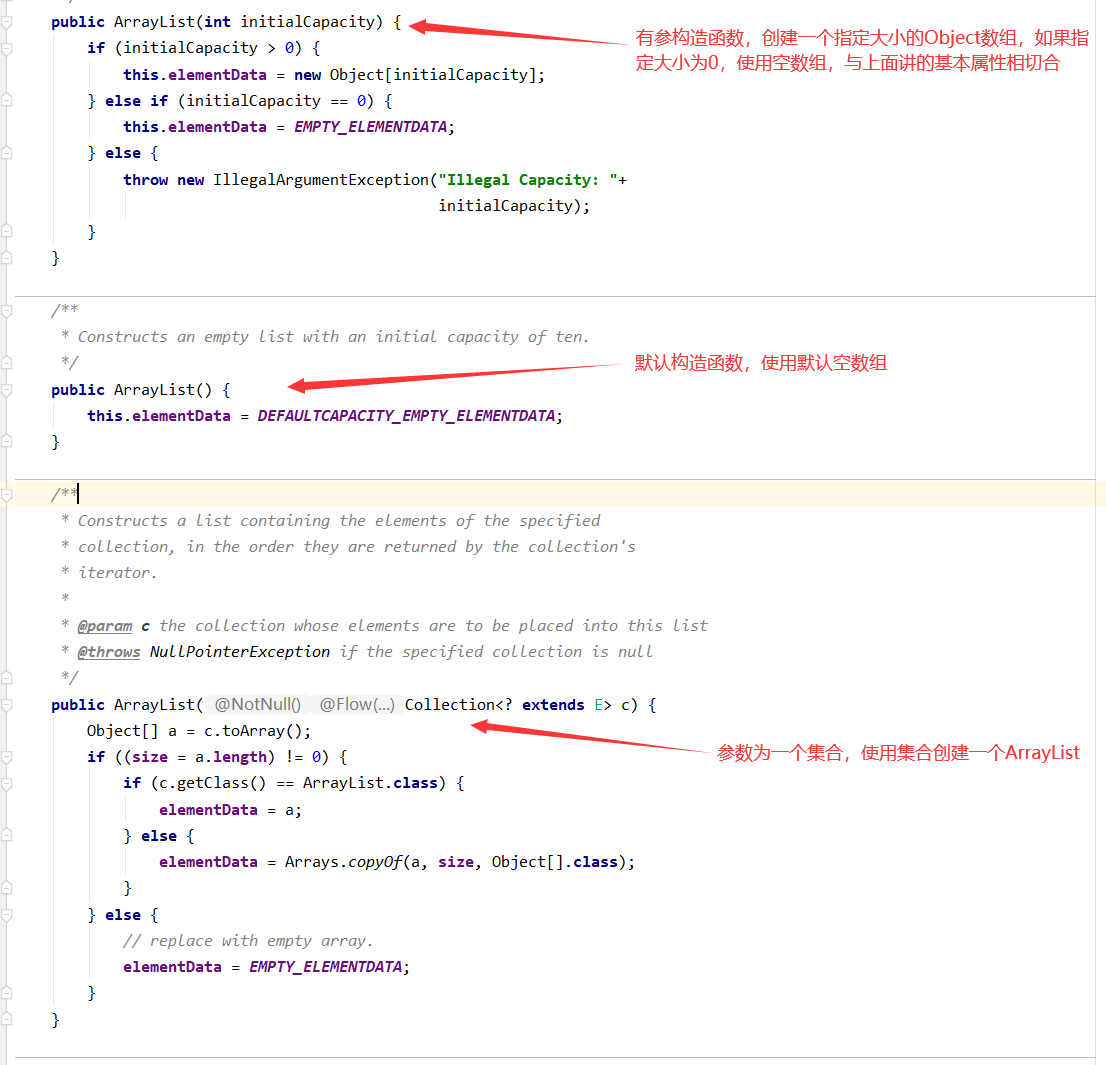
一、ArrayList 源码
1、作者前言

2、基本属性
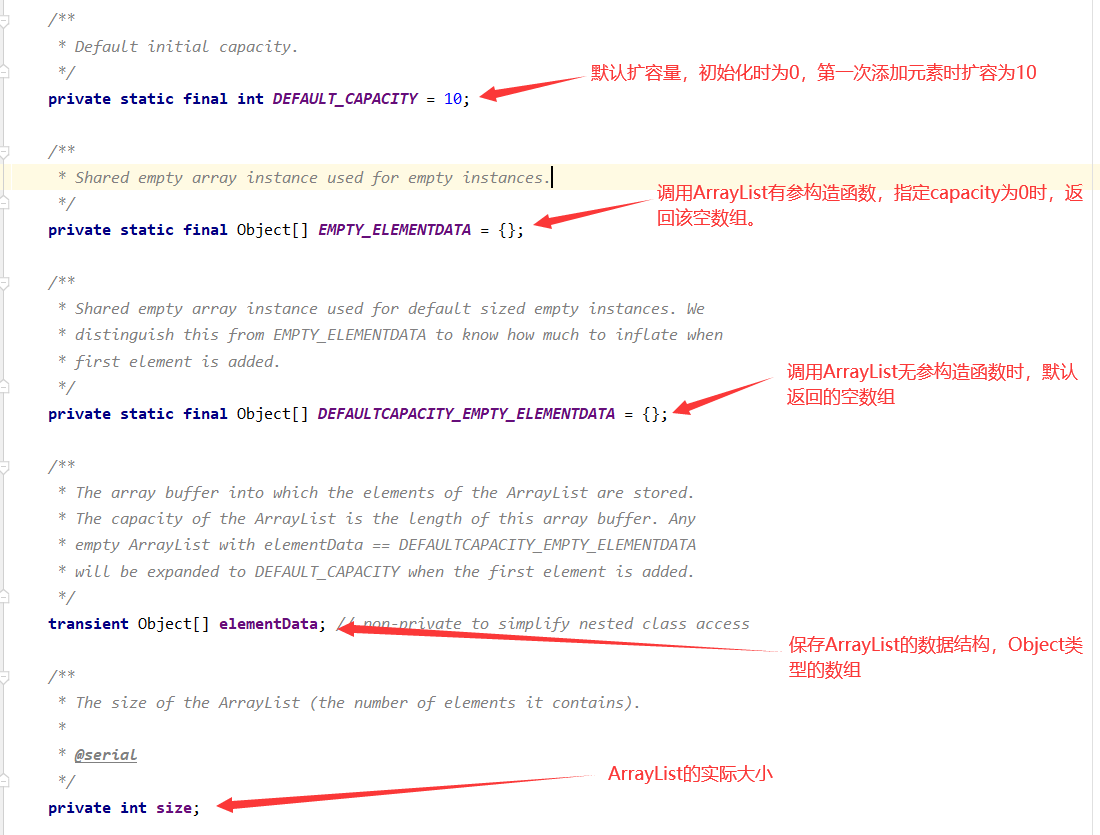
根据上⾯我们可以清晰的发现:ArrayList底层其实就是⼀个Object数组,且能够实现动态扩容。
3、构造函数
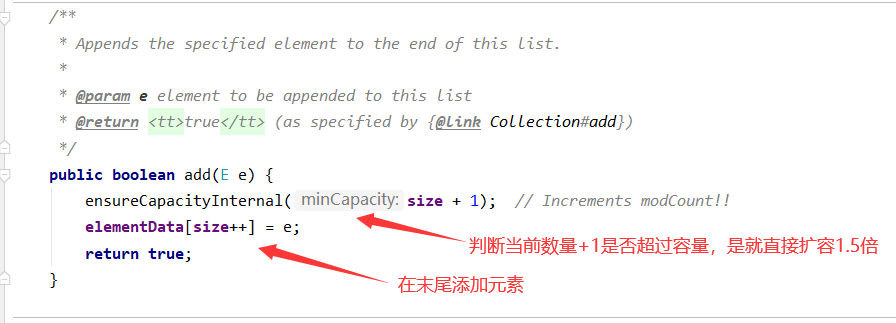
4、添加元素
add(E e)
步骤:
- 检查是否需要扩容
- 插入元素

计算集合最少需要的容量

判断是否需要扩容
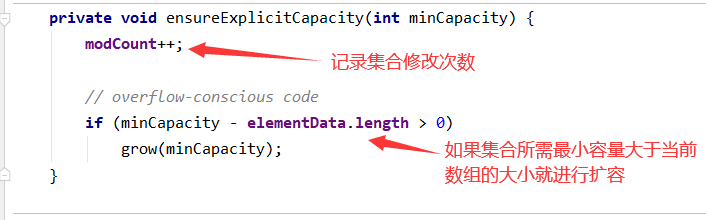
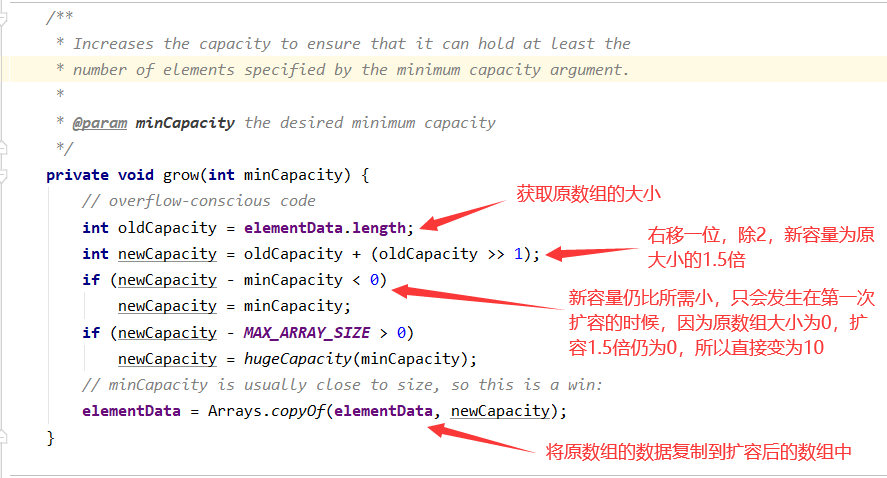
所以,接下来看看 grow() 是怎么实现的~
再来看看copyOf是如何实现的
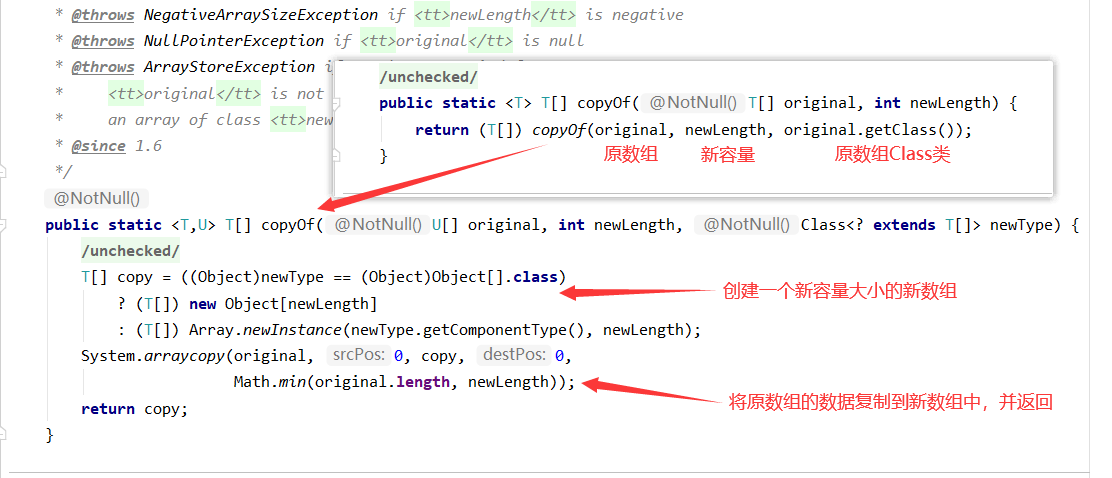
其中System.arraycopy是native方法
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
到⽬前为⽌,我们就可以知道 add(E e) 的基本实现了:
扩容原理:
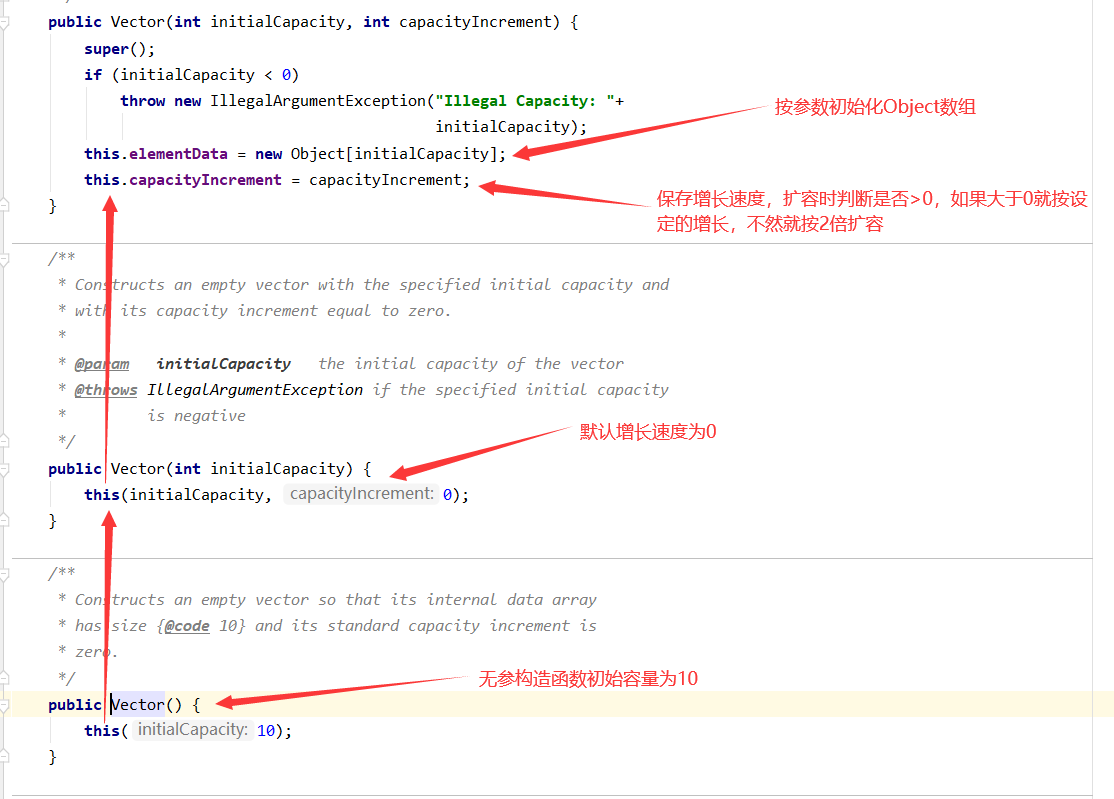
无参构造函数:
1、初始化时为空数组容量为0,如果是第一次扩容1.5倍仍为0,所以使用DEFAULT_CAPACITY = 10默认初始化容量进行扩容
2、之后按照当前容量的1.5倍进行扩容
无参构造函数的扩容来说是固定的:0→10→15→22→33→49→73→109…
有参构造函数(自定义容量):
假设initialCapacity=8,则之后的容量都按1.5倍进行扩容,8→12→18→27→40→60→90→135…
add(int index, E element)
在列表中的指定位置插入指定的元素。将当前位于该位置的元素(如果有的话)和随后的元素向右移动(下标加1)。
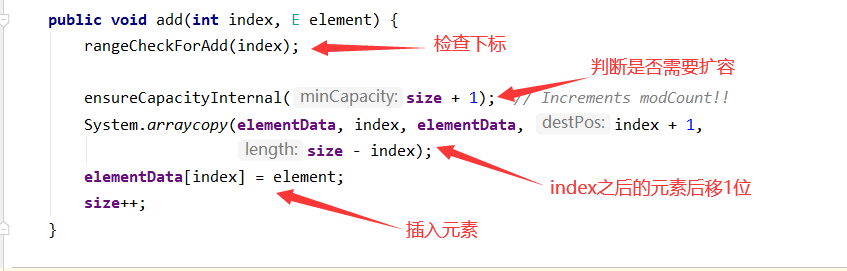
我们发现,与扩容相关ArrayList的add方法底层其实都是 arraycopy() 来实现的,该方法是由C/C++来编写的。
5、get(int index)
public E get(int index) {
rangeCheck(index); // 检查⻆标
return elementData(index); // 返回元素
}
E elementData(int index) {
return (E) elementData[index];
}
6、set(int index, E element)
public E set(int index, E element) {
rangeCheck(index); // // 检查⻆标
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
注意:如果以上两个函数的index的范围是 [0,size],超过就会提示IndexOutOfBoundsException
比如以下两种情况都会报错:
public class testList {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList(8);
arrayList.add(0, 1); // size=1
arrayList.add(2, 3);
}
}
public class testList {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList(8); // size=0
arrayList.set(1, "zhangsan");
}
}
7、remove(int index)
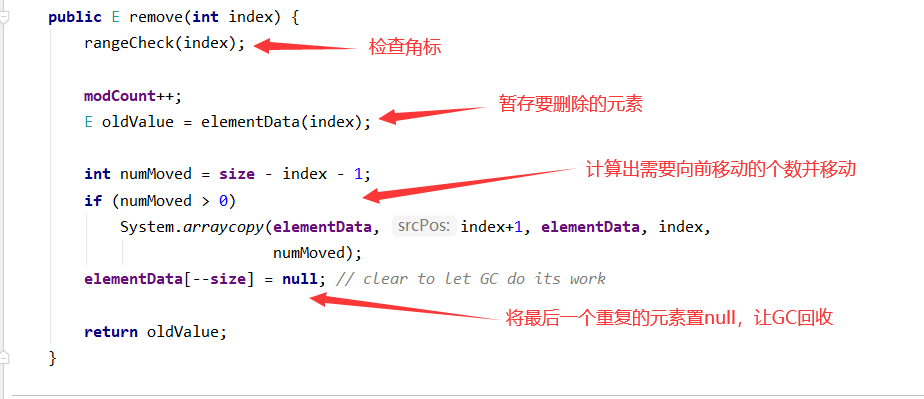
8、总结
-
ArrayList是基于动态数组实现的,在扩容时候,需要数组的拷贝复制。
-
ArrayList的无参构造函数初始化容量是0,第一次默认扩容10,之后每次扩容时候增加原先容量的⼀半,也就是变为原来的1.5倍。
-
删除元素时不会减少容量,若希望减少容量则调⽤trimToSize()。
-
不是线程安全的。它能存放null值。
二、Vector 源码
1、构造函数
2、添加元素

则Vector的扩容机制是咋样的呢,让我们来看看~

3、get(int index)
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
由synchronized修饰可知,读写都只能有一个线程进行,效率低。
4、Vector与ArrayList区别
- Vector和ArrayList底层数据结构都是Object数组,但Vector是线程安全的,而ArrayList不是。
- ArrayList在底层数组不够用时在原来的基础上乘以1.5倍,Vector是乘以2倍。
注意:如果想要ArrayList实现同步,可以使用Collections的方法: List list = Collections.synchronizedList(new ArrayList(…))
三、LinkedList 源码
1、作者前言
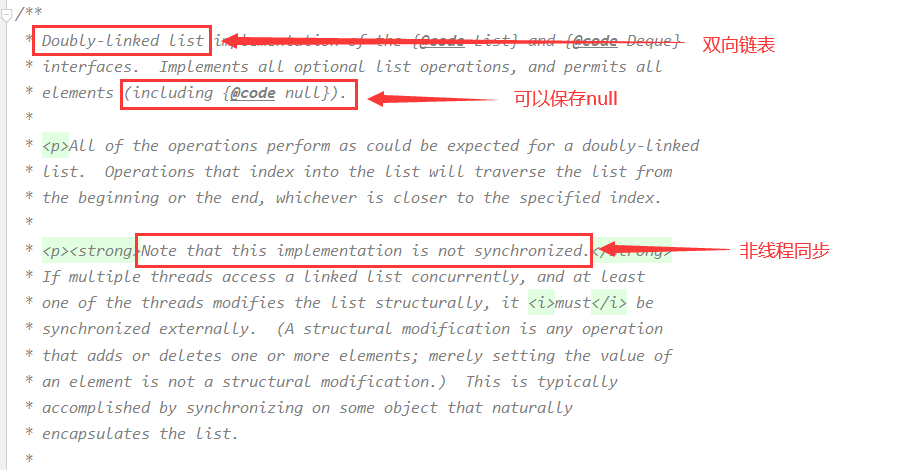
由此可知LinkedList底层数据结构是双向链表,可以保存null值,是非线程同步的
2、基本属性
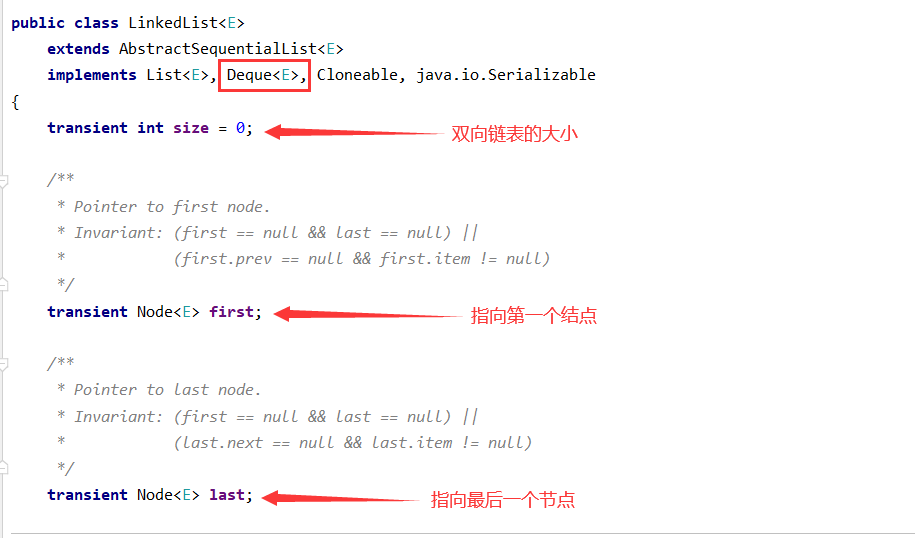
从结构上,我们还看到了LinkedList实现了Deque接⼝,因此,我们可以操作LinkedList像操作队列和栈⼀样~
3、构造函数

4、添加元素
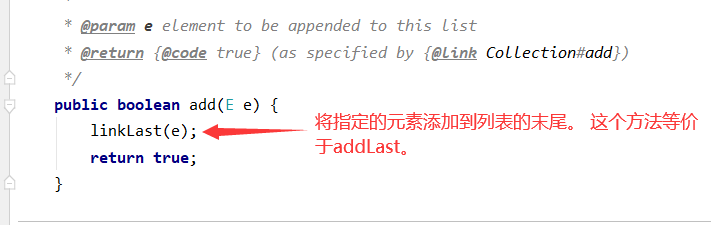
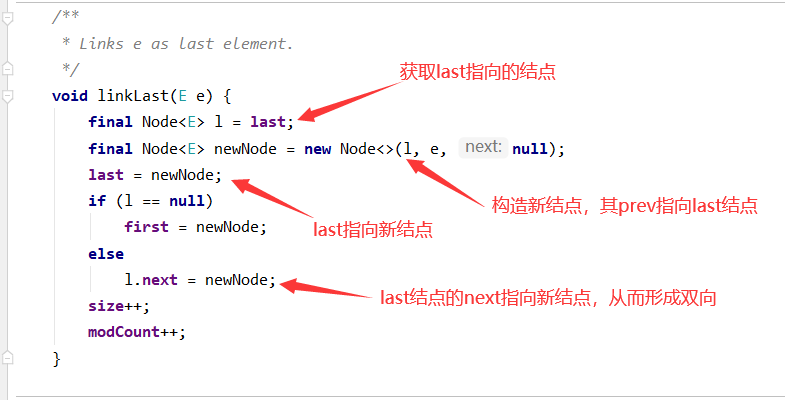
下面我们来看看linkLast是如何实现的
5、查询元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
从源码中我们可以发现获取数据居然可以根据索引,但是链表是没有索引的概念的,它并不支持随机访问。
我们来看看他是如何实现的。
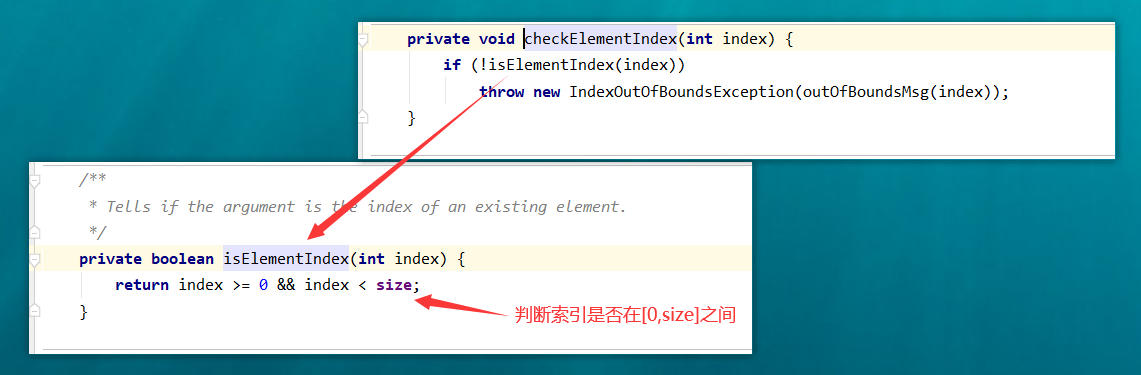
可以看到仅仅是判断了索引是否在[0,size]之间而已,之后根据索引获取数据。
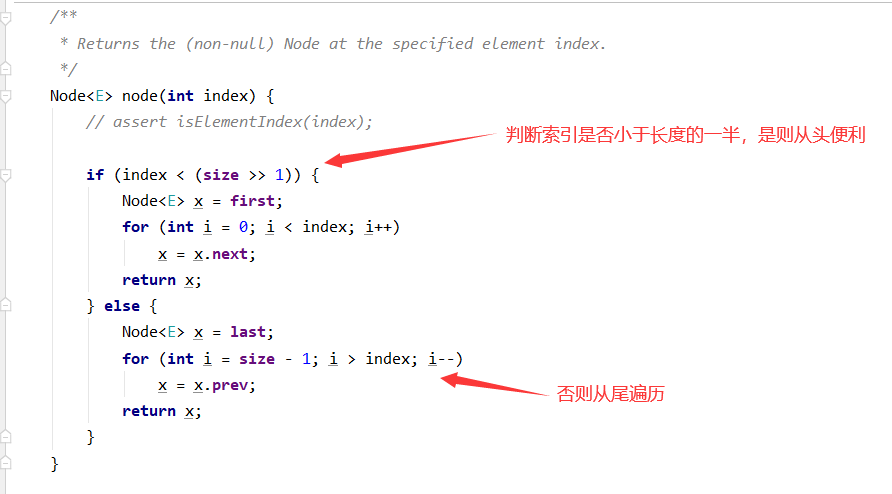
只是顺序遍历访问到该索引的结点而已,如果链表进行增删操作,那么根据索引取值可能不会获取到正确的数据。
四、List 集合总结
ArrayList:
- 底层实现是数组
- 无参初始化时为空数组容量为0,如果是第一次扩容1.5倍仍为0,所以使用DEFAULT_CAPACITY = 10默认初始化容量进行扩容,之后按照当前容量的1.5倍进行扩容;有参是按初始参数的1.5倍进行扩容。
- 在扩容的时候,需要数组的拷贝复制(navite ⽅法由C/C++实现)
Vector:
- 底层是数组,现在已少用,被ArrayList替代,原因有两个:
- Vector所有⽅法都是同步,有性能损失。
- Vector初始length是10 超过length时 以100%⽐率增⻓,相⽐于ArrayList更多消耗内存。
LinkedList:
- 底层实现是双向链表[双向链表方便实现往前遍历]
总的来说:查询多⽤ArrayList,增删多⽤LinkedList。














 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









