







前言
分区表是数据库中的一种表设计方式,它将表的数据分割成多个,称之为分区的逻辑存储单元。
每个分区可以独立管理,包括存储、备份、维护和查询,从而提高了更高效的数据管理和查询性能。
通俗来说,就是当表中的数据不断地增大时,查询速度就会变得非常慢,应用程序的性能就就会下降,
这个时候就应该考虑对表进行分区。表进行分区以后,逻辑上仍然是一张完整的表,只是将表里的数据
在物理上存放到多个表空间中,这样在查询数据时,就不用每次查询都进行整张表的扫描,提高了查询速度。
拆分分区是指将一个现有的分区进一步划分成多个子分区的操作。通常来说,这是为了进一步更好的管理数据,
以便将大分区拆分为更小的部分,以适应增长的大数据量。
分区的优点是:
性能提升:当一个分区中的数据量持续增长,可能会影响查询性能的和数据维护的时候,
拆分分区可以将大分区划分成较小的子分区,以改善性能。
数据管理:拆分分区可以更好的管理数据,使其组织更加合理,降低数据的碎片化程度
拆分分区的类型:
范围分区表
列表分区
hash分区
一、说明
1.此文章使用的是
- 一级分区的语法一:
在创建普通表后面加上指定的分区信息的语法 - 范围分区
2.语法
CREATE TABLE 表名
(
列名1 数据类型,
列名2 数据类型,
...
)
PARTITION BY RANGE (分区键) --要分区的列名
(
PARTITION 分区名1 VALUES LESS THAN (分区值), --存储的范围
PARTITION 分区名2 VALUES LESS THAN (分区值), --存储的范围
...
);
二、使用
1.自动创建分区:使用CREATE 和 INTERVAL 命令,数据类型为NUMBE
语句如下(示例):
--使用函数 generate_series 快速插入多行数据
--generate_series(起始大小, 结束大小, 步进)
SELECT generate_series(1, 200);
--MD5(RANDOM()):通过随机数 random 来生成,将随机数转换为32位的哈希值
--SUBSTRING(MD5(RANDOM()), 1, 20):再通过 SUBSTRING 函数来截取前20位
SELECT SUBSTRING(MD5(RANDOM()), 1, 20);
--创建
CREATE TABLE ncc_apples (
apple_id BIGSERIAL NOT null PRIMARY KEY, --ID
apple_name VARCHAR(255) --名称
)
PARTITION BY RANGE (apple_id) INTERVAL ('100'::BIGINT) --自动创建分区('100'::BIGINT指的是apple_id每增长100自动创建1个分区)
(
PARTITION p1 VALUES LESS THAN (100) --小于等于100存储到p1
);
--批量增加数据
insert into ncc_apples values(generate_series(1, 200), SUBSTRING(MD5(RANDOM()), 1, 20));
--包含apple_id字段名的所有表
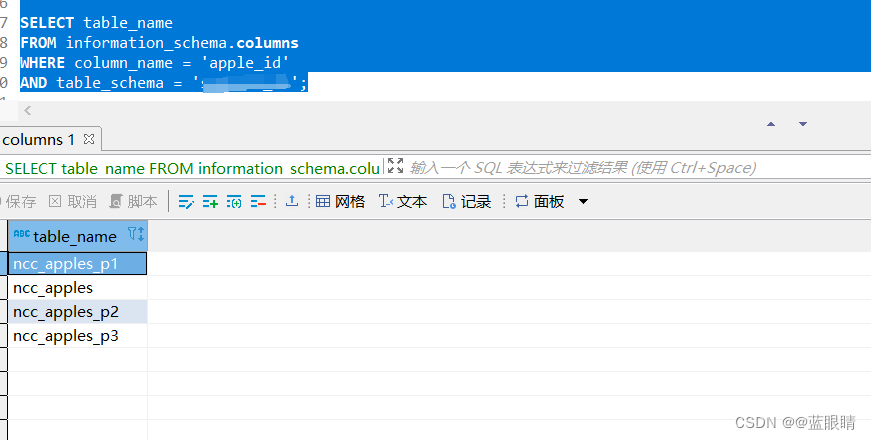
SELECT table_name
FROM information_schema.columns
WHERE column_name = 'apple_id'
AND table_schema = '数据库名称';
--查询数据
SELECT * FROM ncc_apples;
--分区表数据
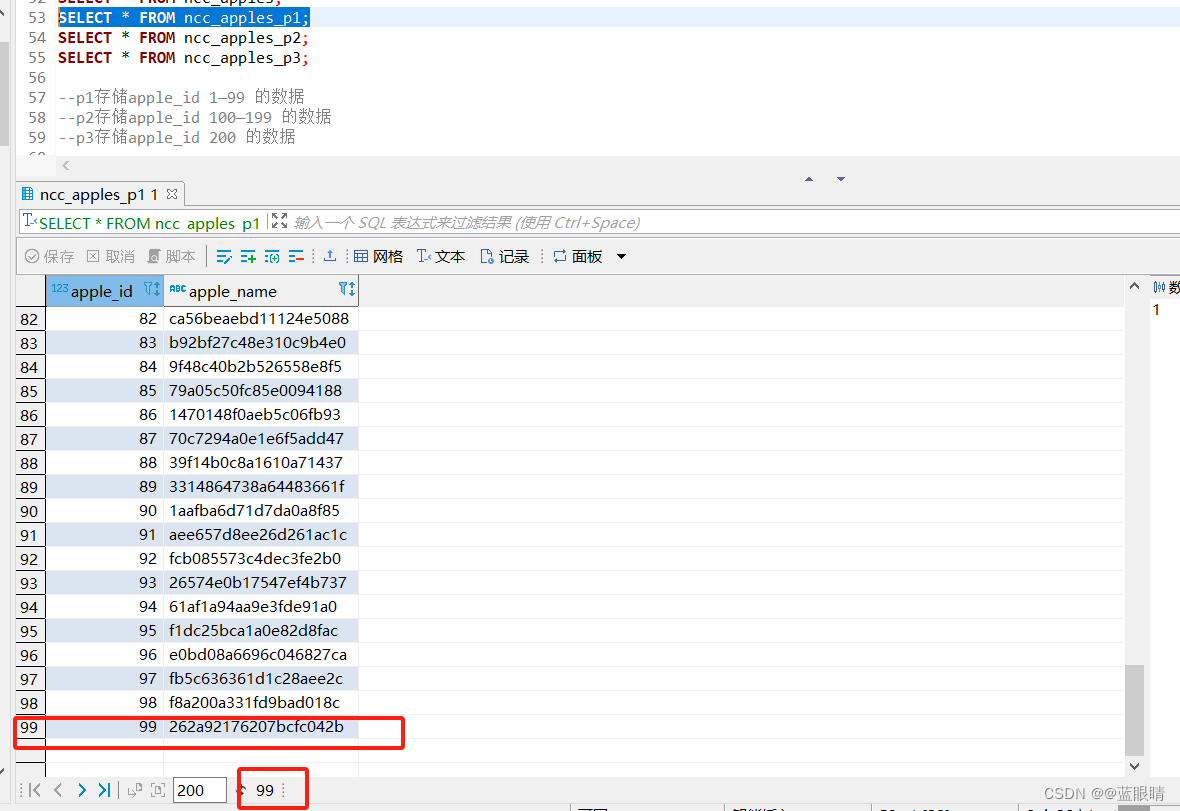
SELECT * FROM ncc_apples_p1;
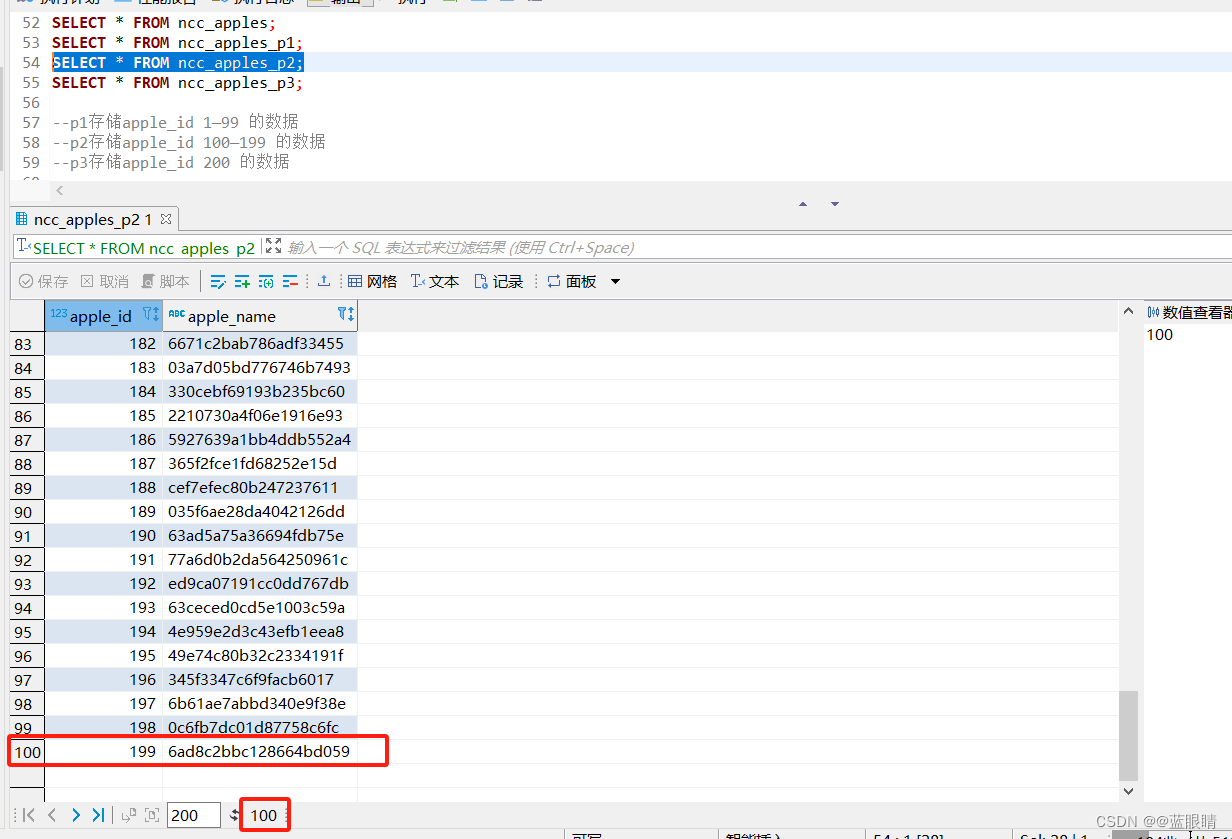
SELECT * FROM ncc_apples_p2;
SELECT * FROM ncc_apples_p3;
--p1存储apple_id 1—99 的数据
--p2存储apple_id 100—199 的数据
--p3存储apple_id 200 的数据
--使用create命令增加表分区时,删除分区表,直接删除DROP TABLE ncc_apples; 即可
DROP TABLE IF EXISTS ncc_apples;


2.自动创建分区:使用CREATE 和 INTERVAL 命令,数据类型必须为DATE
语句如下(示例):
--使用函数 generate_series 快速插入多行数据
--generate_series(起始大小, 结束大小, 步进)
SELECT generate_series(1, 366);
--生成 2024 年之内的随机日期(
--通过TRUNC(random()*365+1) 生成一个1~365的随机数
--再通过date日期相加(得到一个随机天数偏移量)
--最后通过to_char将日期转换为yyyy-MM-dd HH:mm:ss格式
SELECT to_char((date '2024-01-01' + TRUNC(random()*365+1)), 'yyyy-MM-dd HH:mm:ss');
--创建
CREATE TABLE ncc_devices (
devices_id BIGSERIAL NOT null PRIMARY KEY, --ID
devices_date timestamp DEFAULT CURRENT_TIMESTAMP --日期
)
PARTITION BY RANGE (devices_date) INTERVAL ('1 DAY'::INTERVAL) --自动创建分区('1 DAY'::INTERVAL指的是devices_date每增长1天自动创建1个分区)
--'1 YEAR':每隔1年创建一个分区/'1 MONTH':每个1个月创建一个分区/'1 DAY':每个1天创建一个分区
(
PARTITION p1 VALUES LESS THAN ('2024-01-31') --小于等于2024-01-31存储到p1
);
--批量增加数据
insert into ncc_devices values(generate_series(1, 366), to_char((date '2024-01-01' + TRUNC(random()*365+1)), 'yyyy-MM-dd HH:mm:ss'));
--包含devices_id字段名的所有表
SELECT table_name
FROM information_schema.columns
WHERE column_name = 'devices_id'
AND table_schema = '数据库名称';
--查询数据
SELECT * FROM ncc_devices ORDER BY devices_id asc;
--使用create命令增加表分区时,删除分区表,直接删除DROP TABLE ncc_devices; 即可
DROP TABLE IF EXISTS ncc_devices;

















 906
906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











