









「Redis」Redis面试全攻略:常见问题与高级技巧解析
- 1. Redis是什么?它的优点是什么?
- 2. Redis与Memcached有什么区别?
- 3. Redis的数据淘汰策略有哪些?
- 4. Redis的主从复制是怎样工作的?
- 5. 如何保证Redis的高可用性?
- 6. Redis的缓存击穿、雪崩和穿透是什么?如何解决这些问题?
- 7. Redis如何处理大量写入请求?
- 8. Redis的并发竞争问题如何解决?
- 9. Redis的数据持久化机制对性能有什么影响?
- 10. Redis的主从复制是否存在延迟?如何减少延迟?
- 11. 介绍一下Redis 集群的原理和工作方式。
- 12. Redis的集群模式和哨兵模式有何区别?
- 13. Redis的事务是否支持回滚?
- 14. 如何在Redis中实现分布式锁,避免死锁和竞争条件?
- 怎么理解“分布式锁”
- 15. Redis的Lua脚本是如何执行的?有什么优势?
- 16. Redis的LRU算法是如何实现的?是否有缺陷?
- 17. Redis的内存使用情况如何监控和优化?
- 18. Redis如何处理热点数据的访问?
- 19. Redis的持久化和备份策略是怎样的?
- 20. Redis的网络模型是什么?如何保证高性能?
- 21. 介绍一下Redis的数据类型和应用场景
Java操作方法:redisTemplate
1. Redis是什么?它的优点是什么?
Redis是一个开源的内存数据库,用于存储和访问数据。它具有以下优点:
- 高性能:Redis将数据存储在内存中,可实现快速的读写操作。
- 支持丰富的数据类型:Redis支持字符串、列表、哈希表、集合等多种数据结构。
- 数据持久化:Redis可以将数据持久化到硬盘上,以便在重启后恢复数据。
- 高可用性:Redis支持主从复制和Sentinel机制,确保系统的高可用性。
- 分布式:Redis Cluster可以将数据分布在多个节点上,提高系统的吞吐量和可扩展性。
Redis是一个开源的内存数据库,用于读写数据,具备的优点有:高性能、高可用、数据丰富、持久化、分布式
2. Redis与Memcached有什么区别?
- 数据类型:Redis支持多种数据类型,而Memcached只支持简单的键值对。
- 持久化:Redis支持持久化数据到硬盘上,而Memcached不支持持久化。
- 高级功能:Redis支持发布/订阅、事务和Lua脚本等高级功能,而Memcached不支持。
- 数据库支持:Redis支持丰富的数据结构,可以作为独立的数据库使用,而Memcached只能作为缓存使用。
3. Redis的数据淘汰策略有哪些?
- 到期时间:设置一个过期时间,到期自动删除。
- 最大内存策略:设置最大内存,当内存超过限制时,可通过LRU(最近最少使用)或LFU(最不常用)算法淘汰部分数据。
- 随机淘汰:随机选择一部分键进行淘汰。
- 手动删除:通过删除命令手动删除指定键。
到期时间自动删除、手动删除、最大内存策略(包括LRU 最近最少使用;LFU 最不常用进行删除数据)、随机淘汰
4. Redis的主从复制是怎样工作的?
Redis的主从复制通过将主节点的写操作同步到从节点来实现数据的复制。主节点将写操作以命令的形式发送给从节点,并通过异步或半同步方式复制数据。从节点在接收到写操作后会执行相同的操作,并向主节点报告自己的复制进度,主节点根据此信息进行相应的处理。
redis通过主节点向从节点发送复制指令,从节点接收到指令后进行复制操作,并将复制进度发送给主节点,主节点根据进度进行相应的处理
5. 如何保证Redis的高可用性?
可以通过以下两种方式来提高Redis的高可用性:
- 主从复制:通过配置主从复制,将数据复制到多个从节点,当主节点故障时,可以切换到其中一个从节点作为新的主节点。
- Sentinel机制:Sentinel是Redis自带的监控和故障转移解决方案,可以监控主节点和从节点的状态,并在主节点故障时自动进行故障转移。
实现主从复制,将主节点的数据同步给多个从节点进行复制,当主节点故障的时候,利用Redis自带的Sentinel机制,从这几个从节点中选择一个主节点
6. Redis的缓存击穿、雪崩和穿透是什么?如何解决这些问题?
-
缓存击穿:指一个查询非常热门的key,
当这个key在缓存中不存在时,大量的请求会直接访问数据库,导致数据库压力过大。
解决方法:使用互斥锁或设置短暂的过期时间来保护热门key的访问,使得只有一个请求能够查询数据库并将结果写入缓存。 -
缓存雪崩:指缓存中的
大量数据在同一时间失效,导致大量请求直接访问数据库,造成数据库压力过大。
解决方法:设置不同的过期时间,使得缓存数据的失效时间错开;使用热点数据预加载或提前刷新缓存。 -
缓存穿透:指
恶意请求查询一个不存在于缓存和数据库中的key,导致每次请求都直接访问数据库。
解决方法:在查询时进行参数校验,拦截无效请求;针对不存在的key返回默认值或空值,避免对数据库的频繁访问。
缓存击穿:在同一时间多个请求访问某个接口取数据,但数据过期Key被删除,这些请求全部访问到了数据库,增加了数据库的访问压力;这就要缓存击穿。解决方案:加锁机制,同一时刻只有一个线程可以进入方法访问数据库,从数据库取得数据之后设置缓存
缓存雪崩:在同一时刻大量的Key同时过期,key被删除,导致大量的请求全部访问到了数据库,导致数据库的访问压力增大,这就要缓存雪崩。解决办法:为这些key都设置随机的过期时间,错开失效时间避免同时访问数据库,增加访问压力;第二个是缓存预热,在启动程序的时候就将数据保存在Redis中
缓存穿透:恶意请求一个在Redis和数据库都不存在的key,导致请求直接访问到数据库,增加了数据库的访问压力;解决方案:当数据库返回空数据时,也将空数据写入缓存中,避免恶意请求一个不存在的key
7. Redis如何处理大量写入请求?
Redis单线程模型下,通过异步将写入操作放入队列中,并使用内存缓冲区进行批量写入,以提高写入性能。此外,可以通过数据分片和Redis集群来横向扩展写入操作的处理能力。
如果是大量写入请求,会将写入操作放进队列,然后利用内存缓存区进行异步的批量写入操作,提高写入的性能
关键词:队列、内存缓冲区
8. Redis的并发竞争问题如何解决?
可以使用Redis的事务和WATCH命令来解决并发竞争问题。通过对需要更新的键进行WATCH,监视键的变化状态(不是指建内容改变),在执行事务之前检查键是否被其他客户端修改,如果被修改则取消事务,避免竞争条件。
使用redis的事务机制和watch命令进行操作,在执行事务操作前利用watch命令监听这个键的变化,如果键在执行事务前发生了变化则取消事务操作,确保了同一时刻只有一个事务可以进行操作
关键词:事务、watch命令
public void performTransaction(String key) {
// 监视指定键
redisTemplate.watch(key);
try {
// 开启事务
TransactionOperations transaction = redisTemplate.opsForValue().getOperations().multi();
// 执行事务中的命令序列
transaction.opsForValue().set(key, "new value");
// 提交事务
transaction.exec();
} catch (Exception e) {
// 如果监视的键被修改,事务将被取消
System.out.println("Transaction failed: " + e.getMessage());
} finally {
// 取消监视
redisTemplate.unwatch();
}
}
9. Redis的数据持久化机制对性能有什么影响?
RDB持久化方式在指定时间间隔内将数据集快照写入磁盘,对Redis的性能影响较小。AOF持久化方式将每个写操作追加到文件中,相对于RDB会对性能产生一定影响,但可以通过配置不同的fsync策略来平衡数据持久化和性能。
rdb是将数据快照写入到磁盘中,aof是将写入命令追加到文件中,两则比较的话RDB对性能的影响较小
10. Redis的主从复制是否存在延迟?如何减少延迟?
Redis的主从复制存在一定的延迟,取决于网络延迟和复制过程中的数据量。可以通过配置更低的复制延迟参数来减少延迟,并确保主节点和从节点之间的网络稳定性。
会存在延迟,延迟取决于网络和复制的数据量,可以通过配置复制延迟命令来减少延迟
11. 介绍一下Redis 集群的原理和工作方式。
Redis 集群是Redis提供的分布式解决方案,通过分片将数据存储在集群的多个节点上。每个节点负责一部分数据,并通过Gossip协议进行节点间的通信和数据同步。客户端可以直接连接到任何一个节点进行读写操作。
redis集群是redis提供的分布式解决方案,通过分片数据将数据保存在不同的redis节点上,每个节点保存部分数据,当连接某个节点时,都可以进行读写操作,redis分布式集群是通过Gossip进行节点间的通信和数据同步的
12. Redis的集群模式和哨兵模式有何区别?
Redis的集群模式使用了Redis Cluster来实现分布式,具有自动分片和数据复制功能。而哨兵模式使用了Redis Sentinel来实现高可用性,监控主节点状态并在主节点宕机时进行自动切换。
集群模式具有数据分片和数据复制功能,哨兵模式使用了Sentinel机制监听主节点是否发生故障,如果发生故障则将在从节点中选择一个充当主节点
13. Redis的事务是否支持回滚?
Redis的事务是原子性的,但不支持回滚。在执行事务期间,如果出现错误,事务会继续执行,而不会回滚之前的操作。
14. 如何在Redis中实现分布式锁,避免死锁和竞争条件?
可以使用SET命令结合NX(Not Exist)参数来实现分布式锁。通过设置一个带有过期时间的特定值作为锁,保证只有一个客户端能够获取该锁。避免死锁可以通过设置合适的锁超时时间来保证,避免竞争条件可以使用Redlock算法等更复杂的机制。
如何用Redis实现分布式锁:如何实现分布式锁
怎么理解“分布式锁”
分布式锁是一种用于协调分布式系统中多个进程或节点对共享资源的访问的机制。在分布式系统中,多个节点同时访问共享资源可能导致数据不一致或竞争条件的问题。为了确保在任何时刻只有一个节点可以对共享资源进行操作,分布式锁提供了一种机制来实现互斥访问。
理解分布式锁可以从以下几个方面来考虑:
互斥性:分布式锁确保同一时间只有一个节点可以持有锁,其他节点无法获取到锁。这样做可以避免多个节点同时修改共享资源而导致数据不一致。
可重入性:同一个节点在获得锁之后可以再次请求相同的锁,而不会因为自身已持有锁而发生死锁。可重入性使得节点可以在嵌套调用或递归操作时安全地使用分布式锁。
容错性:分布式锁需要考虑节点故障或网络异常等情况下的容错处理。当持有锁的节点失效时,分布式锁应该具备释放锁的机制,以确保其他节点能够继续访问共享资源。
性能和可扩展性:分布式锁的设计需要考虑系统的性能和可扩展性。锁的获取和释放应该是高效的,并且不应该成为系统的瓶颈。
实现方式:分布式锁可以通过基于数据库、缓存(如Redis)、协调服务(如ZooKeeper)等不同的方式来实现。具体选择哪种方式取决于需求和场景的特点。
15. Redis的Lua脚本是如何执行的?有什么优势?
Redis通过将Lua脚本发送给服务器端进行执行。执行过程中,脚本会被编译为字节码并缓存起来,避免了每次执行都重新解析和编译的开销。Lua脚本在执行期间是原子性的,可以调用多个Redis命令,并且可以保证执行期间不被其他客户端打断,具有高效和灵活的特点。
16. Redis的LRU算法是如何实现的?是否有缺陷?
Redis的LRU算法通过近似的方式实现。当内存达到设定的阈值时,Redis会根据近似的访问时间来淘汰最近最少使用的键。LRU算法的主要缺陷是对于长时间未被访问的热点数据或周期性访问的数据,容易被错误地淘汰。
当内存容量达到阈值的时候,redis会根据最近最少使用(叫LRU算法)的方式去删除数据,这个算法的缺陷是会删除长时间没有被访问的数据或者需要周期性访问的数据
17. Redis的内存使用情况如何监控和优化?
可以使用Redis提供的INFO命令获取Redis的内存信息,包括使用的内存量、键数等。通过监控内存占用情况,可以及时采取措施如删除过期数据、优化数据结构、限制内存使用等来降低内存占用。
使用redis提供的info命令查看内存信息
18. Redis如何处理热点数据的访问?
可以使用Redis的缓存机制来处理热点数据的访问。将经常被访问的数据存储在内存中,可以通过合适的数据结构如哈希表、有序集合等来提高对热点数据的读写性能。
使用redis的内存缓存机制来处理热点数据,提高数据的查询性能
19. Redis的持久化和备份策略是怎样的?
Redis提供了两种持久化方式:RDB和AOF。RDB方式将数据集快照写入磁盘,AOF方式将每个写操作追加到文件中。为了保证数据的安全性,在生产环境中通常会同时使用两种方式进行持久化,并定期进行备份以防止数据丢失。
RDB和AOF是Redis中两种不同的持久化方式。它们保证数据安全性,RDB写入速度快、恢复迅速,AOF提供更精确的数据恢复和更灵活的修改方式。一般备份策略会同时采用两种方式,以确保数据在突发故障时能够及时恢复。使用RDB和AOF可以使Redis在数据安全性、读写性能和备份策略方面更加平衡和优化。
RDB和AOF是两种不同的持久化机制,RDB将数据快照写入磁盘,写入速度快,恢复速度也快。AOF是将命令追加到文件中,数据更准确,但是恢复速度相对较慢,生产环境一般都会采取这两种机制,提供了互补措施
20. Redis的网络模型是什么?如何保证高性能?
Redis使用基于事件驱动的I/O多路复用模型,通过单线程高效处理网络请求。为了保证高性能,可以采取一些措施如合理配置操作系统参数、设置适当的最大连接数、合理使用连接池、使用Pipeline等技术手段来优化Redis的网络性能。
Redis使用基于事件驱动的I/O多路复用模型,通过一个线程管理多个连接,避免了线程切换和资源浪费,提高了并发处理能力和性能。
21. 介绍一下Redis的数据类型和应用场景
-
字符串(String):适用于缓存、计数器、分布式锁等场景。
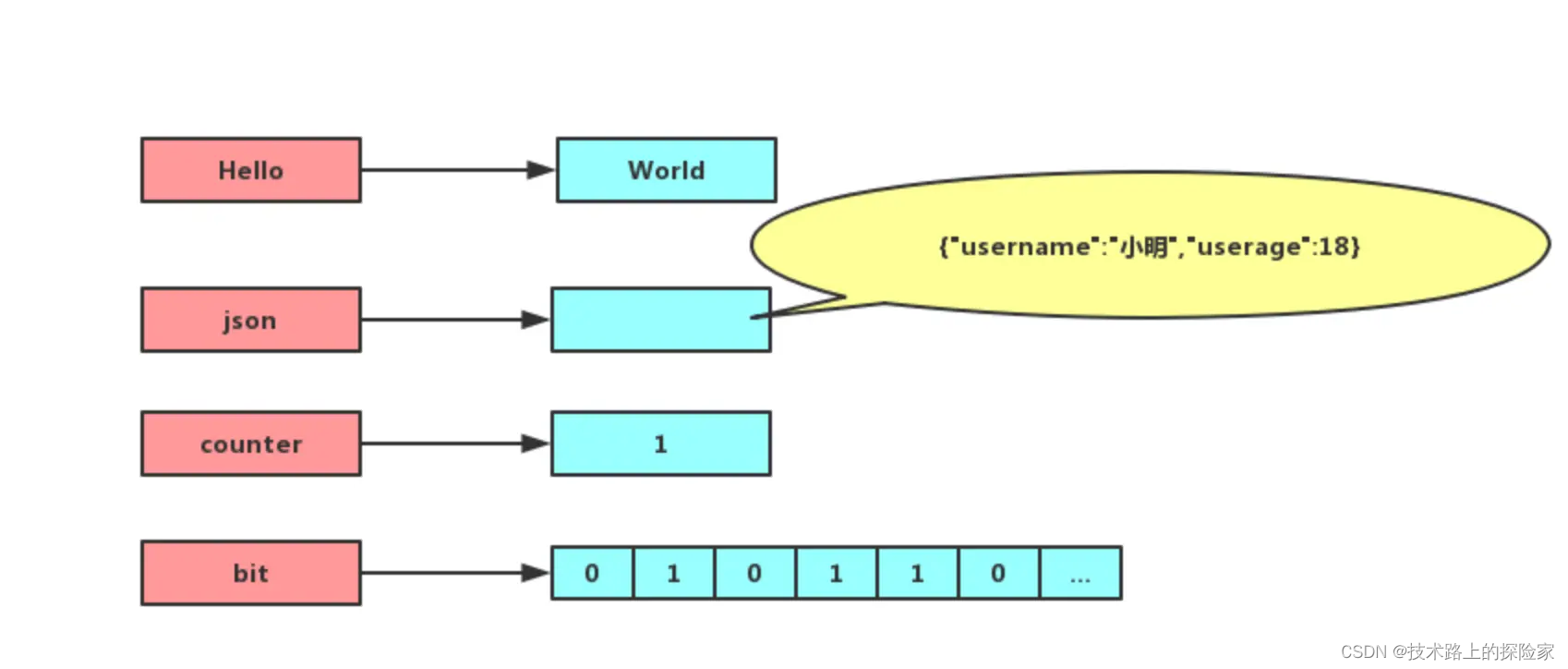
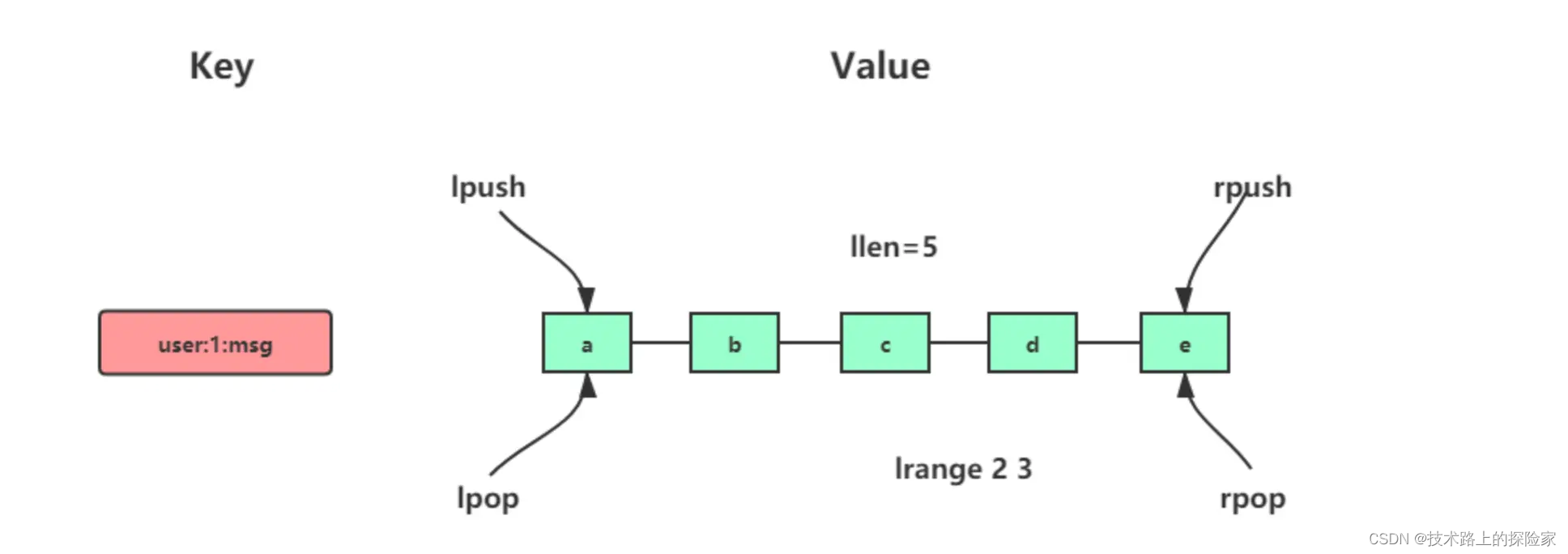
-
列表(List):适用于消息队列、最新消息列表等场景。
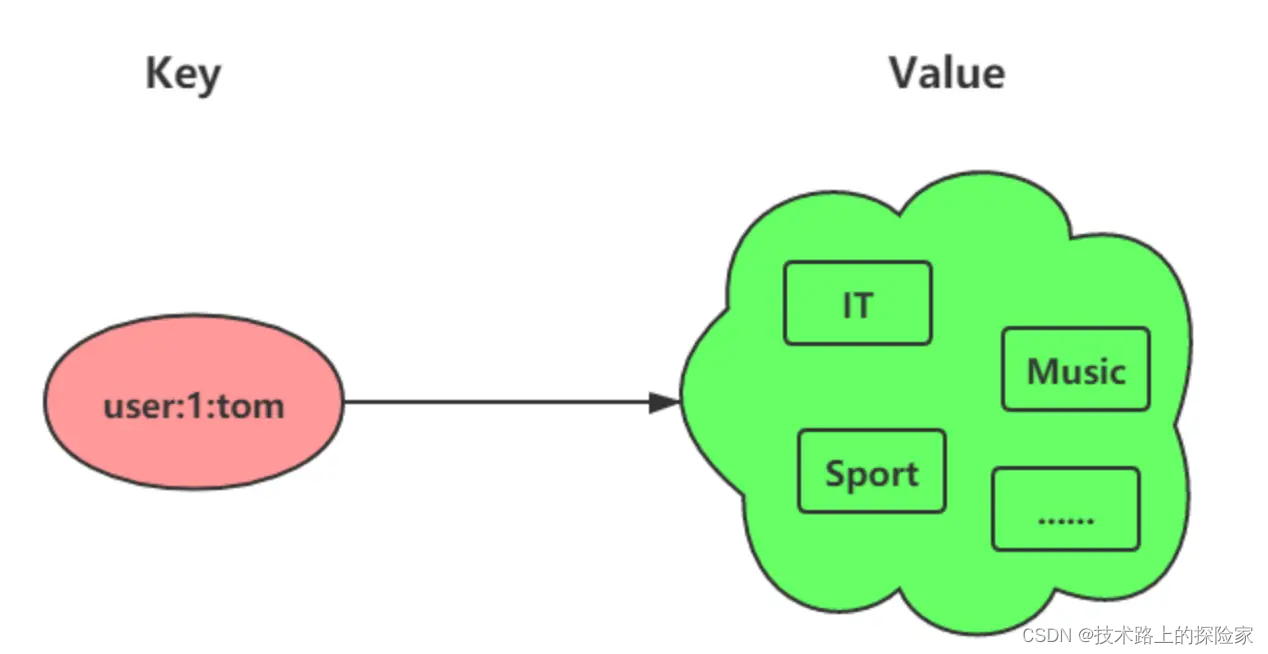
- 集合(Set):适用于数据去重、共同好友、标签系统等场景。
-
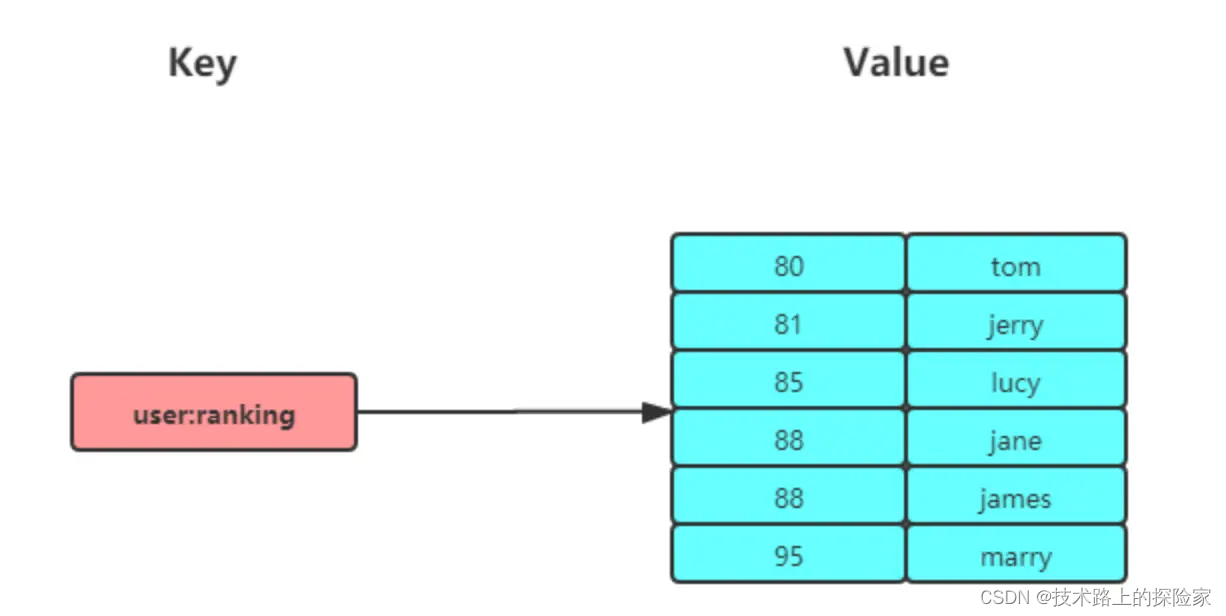
有序集合(Sorted Set):适用于排行榜、优先级队列等场景。
-
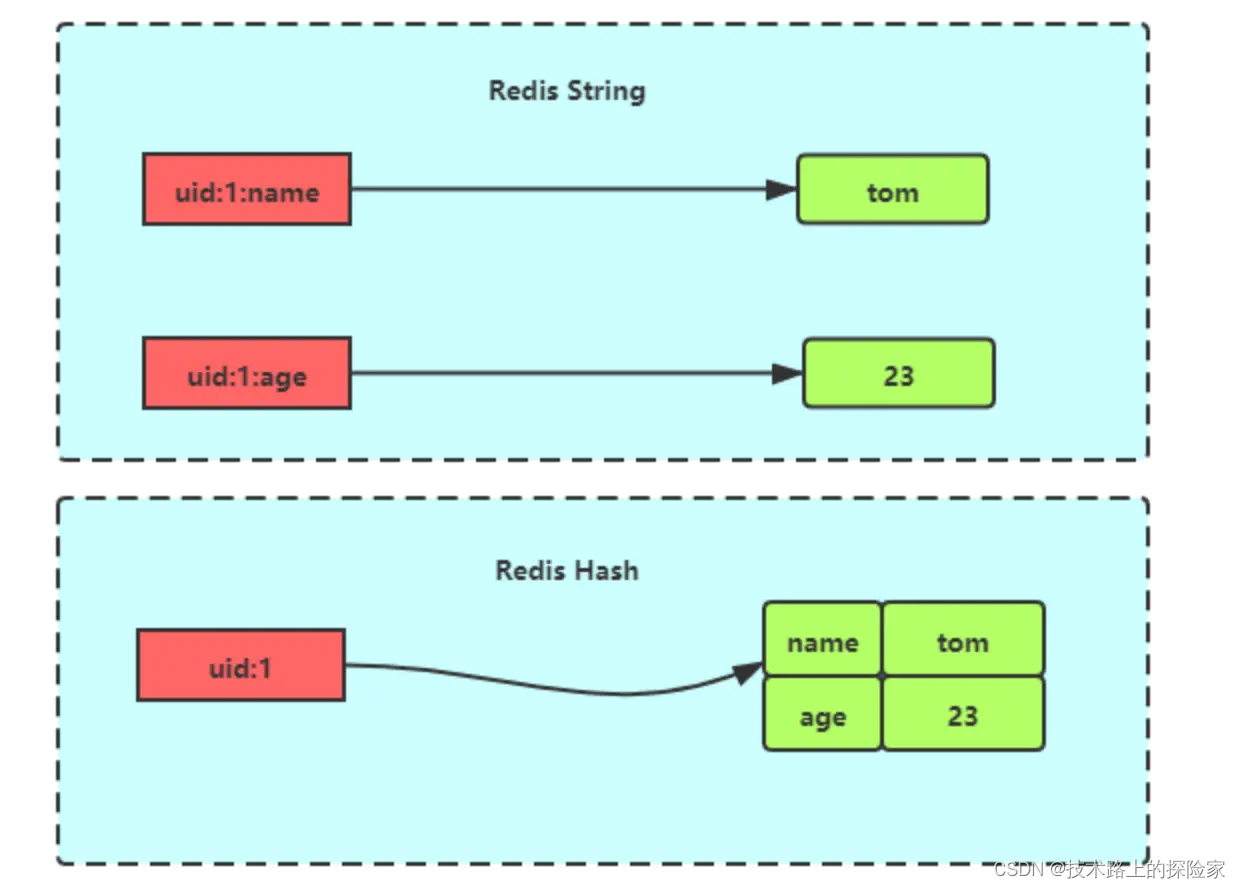
哈希(Hash):适用于存储对象、用户属性等场景。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











