






一、《Uncertainty-based adaptive learning for reading comprehension 》
1、标注数据费时费力,并且有时因为其他特殊原因也不能标注,因此本文提出了一种基于不确定性的阅读理解自适应学习算法,该算法将数据注释和模型更新组织在一起,以减轻标记的需求。本文包括两个关键技术:一种基于无监督不确定性的抽样方案,它根据当前学习的模型查询信息量最大的实例的标签;一种自适应损失最小化范式,可同时拟合数据并控制模型更新的程度。
2、本文的策略像active learning,总是专注于只拟合最有信息量的例子而不会降低性能,基于无监督不确定性的采样策略是自适应的,它选择当前模型最不确定的样例,MRC问题就是判断文章中的每个词是不是答案,理想化的,我们想要是答案就标1,不是标0,这样正确与不正确之间的差距特别大,很容易区分,但是,如果算法将 0.5 分配给两个不同的答案,并将 0 分配给其他答案,那么它的答案就非常不确定——这时候就需要向专家询问正确答案,即执行主动标记。 本文这个策略就是基于这个出来的:实例的不确定性被定义为最佳候选答案与次佳答案的权重之间的差距。
3、在识别出这些最不确定、因此信息量最大的实例后,我们查询它们的标签并使用它们来更新模型。 本文没有使用交叉熵损失函数,而是使用一个自适应正则化器:它可以使新模型不会偏离当前模型,因为使用合理的初始化使模型不会表现太差,和不会使其过度拟合数据。其次,正则化器的系数随着迭代而增加。 也就是说,随着算法的进行,模型更新的稳定性超过了损失最小化。 因为在每次迭代中,模型只拟合不确定的数据,模型更新的速度会加快,
4、对于很多无标注文本,得到不确定样本和非常确定的样本,把不确定的样本让专家标注答案,用带标签的数据更新MRC模型。计算Metric Of Informativeness的时候,计算最大概率和最小概率之间的差作为衡量依据。筛选不确定性样本的时候,不是选择差值最小的前n个,这样是因为样本之间的差值很小,容易选择一个丢弃另一个。在这里使用的是一个采样公式,计算每个被选择的概率,然后再进行选择。

二、《 Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension 》
1、Natural Questions是MRC中新的具有挑战性的数据集,它里面要找出长段答案和短的答案,目前的方法把这两个任务分开建模,没有考虑他们之间的依赖关系,为了解决这个问题,本文提出一个新的多粒度机器阅读理解框架,它侧重于按层次性质对文档进行建模,这些层次具有不同的粒度级别:文档、段落、句子和token。本文使用GAT得到不同级别的表示,并且他们之间可以互相学习,长答案和段答案可以分别从段落级表示和token级表示中得到。这样,本模型可以得到这两个粒度的依赖关系,两种答案之间可以互相提供依据。在推测阶段,本文使用pipeline策略,先找出长答案,然后在长答案中找出短答案。
2、本文使用5种标签,short判断是否是短答案,yes和no判断哪个实例含有长答案,long判断是否含有长答案,no-answer表示没有答案。因为文档是层级结构,这里把文档可以分为段落,段落可以分为句子和token,然后他们之间连接无向边,构建图。此图有4种类型的节点:token节点、句子节点、段落节点、文档节点。不同的节点表示不同粒度的信息,因为长答案可能在段落、表格和列表中,因此段落节点也表示长答案的信息。
3、Graph Encoder每一层包含3个自注意力层,一个图集成层,一个全连接层。自注意力层作用在同一个粒度下的节点之间,图集成层使用GAT从不同粒度收集信息,这里的注意力系数用自注意力计算,原GAT中使用的是拼接后进入全连接层。
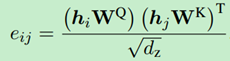

4、多头注意力的输出是连接每一头的输出,每一头的输出是其所有一阶邻居求和
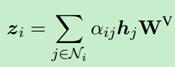
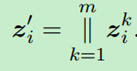

三、《Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension 》
1、对于长句子的阅读理解,目前的方法是把文档分成相等的几段,然后针对每一段预测答案,但是这种方法没有考虑段落之间存在的信息,在组成的片段中可能不含有正确答案,并且在正确答案两旁没有足够的文本支撑它,或者被分出的片段中包含的答案不完整,并且本文发现模型对在边界处的答案判断能力较差,对于在中间文本中的片段判断较好(因为其含有丰富的文本信息),其次,本文发现以一个较小的stride切分片段不太能增加模型的性能,有时候还会减小。并且这种方法不太能回答需要交叉段落问题的答案。本文提出使用强化学习的方法,让模型决定它需要的下一个片段,并引入“循环机制”,让片段之间的信息可以流动。
2、本文提出recurrent chunking mechanisms (RCM),它以transformer为基础,此模型可以通过强化学习学习如何选择stride的大小,它可以阻止提取不完整的答案,在答案旁保有足够的文本信息。其次,本文的“循环机制”可以使信息在片段之间流动,这样模型可以获得全局文本信息,实验证明RCM可以生成更有可能包含全部答案的片段,并在答案两旁提供充足的上下文信息。
3、循环层可以在片段之间集合信息,并预估片段包含答案的概率。取出BERT的输出v后,经过循环层f,那么每个片段就包含片段之间的信息,本文包括两个循环层(门控循环和LSTM)
门控循环:
![]()
![]()
LSTM循环层:
![]()
得到增强后的片段表示,计算片段包含答案的得分:
![]()
4、阶段策略是给定状态s,得到固定行为的概率,这里状态s代表每个片段,行为a代表doc_stride,决策的过程用一个全连接网络实现。从一个片段到下一个片段移动的距离是由分块策略得出的概率中采样的,使用有监督训练答案提取和块得分,使用强化学习训练分块决策网络。

四、《Few-Shot NLG with Pre-Trained Language Model 》
1、目前基于神经网络的NLG算法都是用的结构化的数据或知识,而这样的数据是稀缺的,无法应用在真实的应用中,本次,提出一个新的任务“小样本文本生成”,受人们经常总结一些表格化的数据的启发,本文提出一个新的模型,其包含两方面:从输入数据和语言模型中选择内容以组成连贯的句子,这些可以从先验知识中获得。
2、为了描述表格中的信息,需要两个技巧,一是从表格中选择和复制事实内容,这可以通过阅读一些表格来快速学习。而是把这些事实信息组成语法正确的句子。存在一个潜在的“变换”,可以使这两种技巧相互中和,以得到事实正确且连贯的句子。本文使用一个预训练模型,其作为天生的语言能力,它提供了很好的先验知识去知道怎么组成事实且连贯的句子。之前表现很好的模型是基于大量数据训练的,没有使用本文的“转换”机制,在小样本上表现很差。因为本次模型是在小样本上做的,本模型力求简化,可以延伸到现实世界中,
3、这里通过构造一个函数来代表“转换策略”,其表示是从词库中生成还是从表格中抽取答案。
五、《A Self-Training Method for Machine Reading Comprehension with Soft Evidence Extraction 》
1、MRC模型一般包括两个组件:证据提取和答案预测。证据标签很重要,但是不容易获得。特别是对于一些非抽取MRC任务,例如YES/NO问题和多答案任务。为了解决这个问题,本文提出一个自训练方法,它可以自动生成证据的标签。在每次迭代中,一个基本的MRC模型用正确答案和噪声证据标签进行训练,然后模型预测伪证据标签用于下一次的训练。
2、MRC任务可以分为两大类:抽取式和非抽取式。对于有监督而言,缺少证据标签,并且人工标注太费事费力,近期,很多研究解决噪音证据标签问题。一些使用手工设计的规则或者外部工具产生远程标签。一些使用强化学习产生标签。但是强化学习训练不稳定,远程监督工具也会产生噪音标签,并且很难应用到其他任务中。因此提高证据提取还是很难,因为正确的标签数据不足。
3、之前的MRC工作主要聚焦在建模问题和文档之间的语义匹配信息,为了模仿人类的阅读模式,提出分层的从粗到细的方法,这种模型把全部文本读进去,然后选择有关的文本span,然后从这些相关的span中推测答案。证据提取旨在提取相关信息为了任务接下来的流程,它可以很好的提取效果。证据提取已经在事实证明、多选择阅读理解、开放领域问答、多条阅读理解、自然语言推断等任务中。证据提取在MRC任务中根据训练方法可以被分为四种类型:无监督方法(不提供任何指引)、监督方法(用带正确标签的证据进行训练证据提取模型)、弱监督方法(依赖噪音证据标签,这些标签可以通过启发式规则获得)、如果一个弱提取器是使用无监督或弱监督预训练的,强化学习可以为证据提取被用于学习一个好的策略。
六、《Structured neural summarization》
1、本文用GNN去扩展目前存在的序列encoder,从而可以捕获例如文本这种弱结构数据的长距离关系。目前的摘要模型都是基于序列到序列的模型,序列encoder通常是RNN,或1DCNN或自注意力,尽管经典的encoder理论上可以解决长距离关系,实际上他们不能很好的处理长文本句子,而且经常受一些噪音影响。为了解决长距离关系问题,并且受最近在高结构上的工作的启发,在本项工作中,高维结构数据例如实体关系、分子和程序可以建模为图结构,GNN可以很好的从这种图结构上学习到这些图表示。对于文本这种弱结构数据,可以使用外部工具构造图,
2、本文研究三项任务:提取代码名字(MethodNaming)、总结代码的思路(MethodDoc)、文本摘要。
3、本文模型首先用双向RNN encoder得到token的表示,然后将这个表示作为GNN的初始节点表示输入GNN,然后将其输出再输入到一个未修改的decoder。构建图的时候,把句子作为一个节点,句子和词之间连接边,词与词之间存在“下一个词”的边。
















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









