









需求
本文通过一个案例讲解组装树形结构的思路
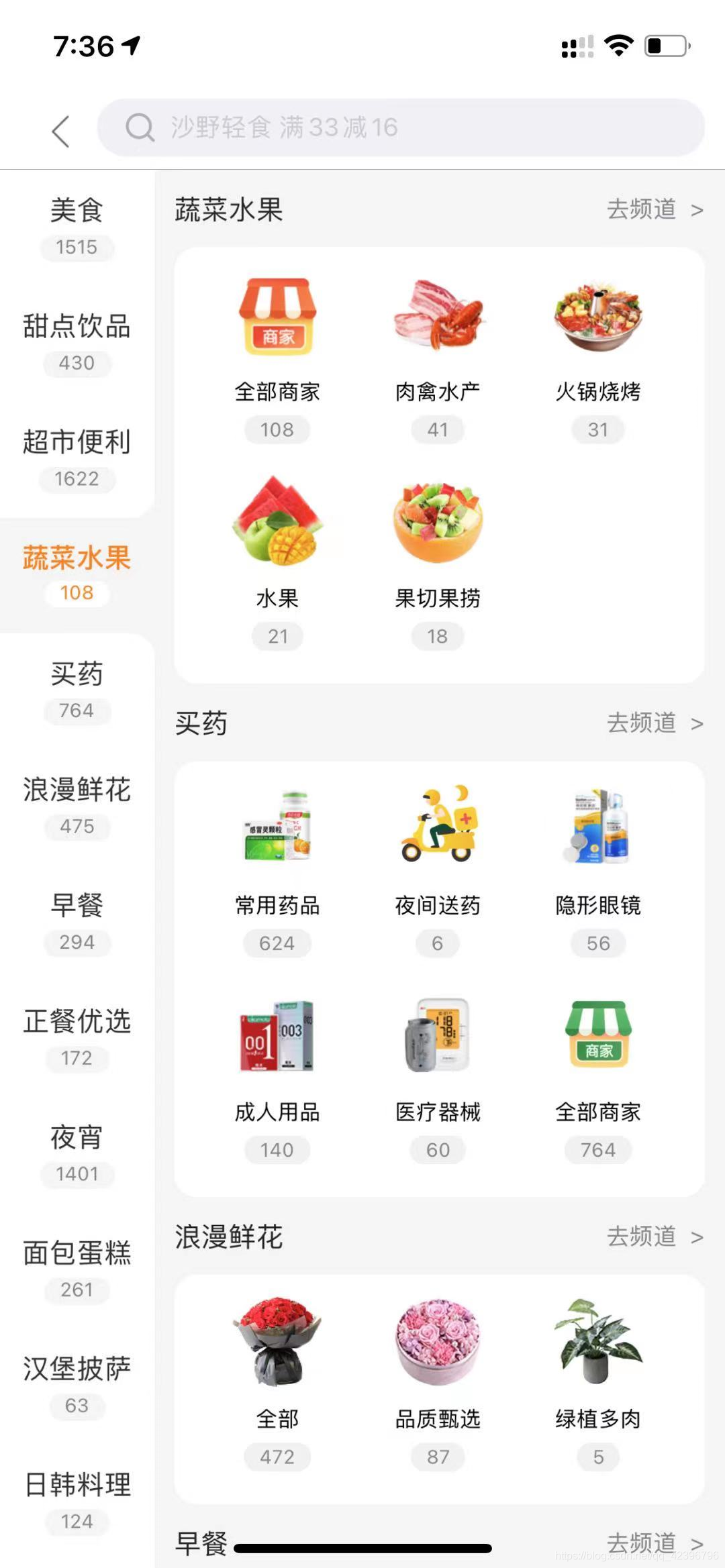
需求是返回该页面数据供前端展示,可以看到左侧一列是美团的一级分类,点击对应的一级分类右侧会展示对应的二级分类。但是图中除了分类名称还多了数量,这个会是这个案例最难解决的点。如果解决好了是一层循环,如果解决不好就是两层循环。
表结构及数据
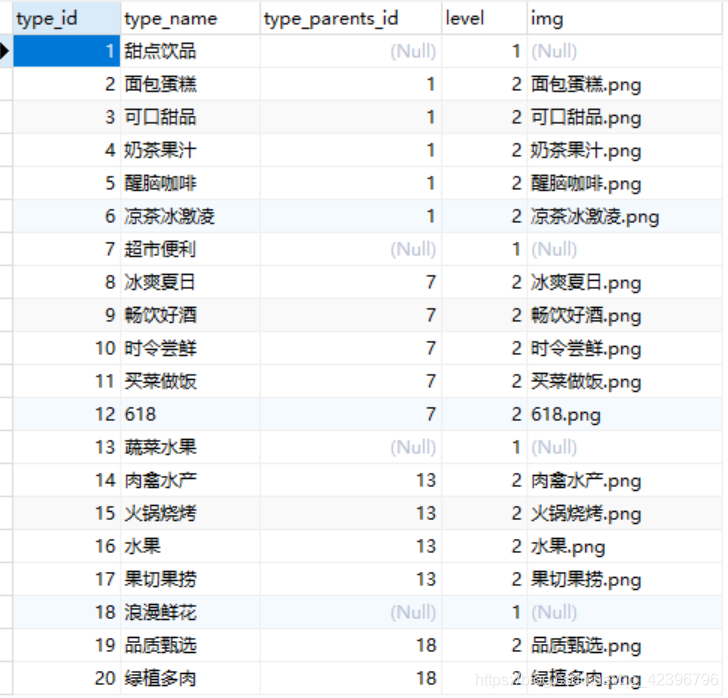
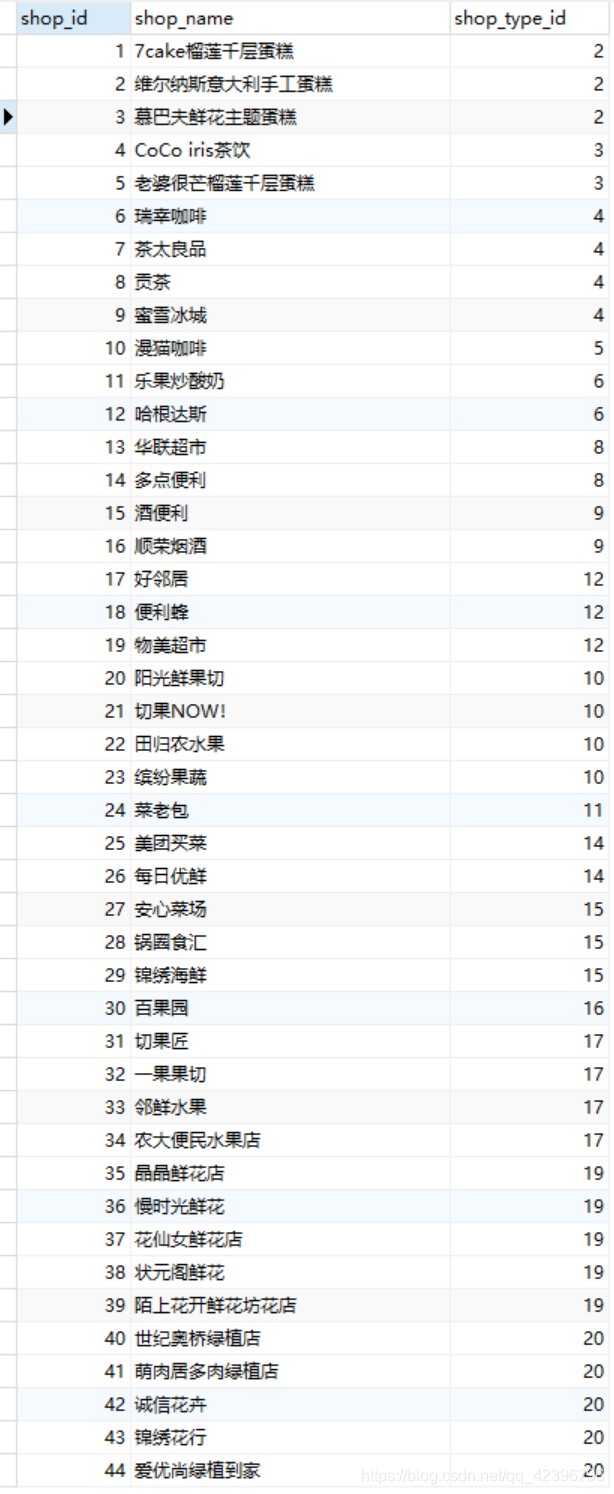
案例我建了两张表,分别是shop(商店表)跟type(分类表)。在type中有个字段shop_type_id对应的是分类表中分类id。
分析
通过对需求图与表结构的分析,第一反应返回的数据是一个树形结构。所谓树形结构在Java中一般就是List包List,我们来看不懂Java8新特性的写法:
- 查询出分类表中所有的一级分类
- 查询出分类表中所有的二级分类
- 遍历一级分类集合
- 遍历二级分类集合,通过二级分类的id与其父id建立联系将二级分类放到一级分类下
- 数据组装完毕,结果返回前端
优化前写法
public List<FirstTypeInfo> selectTypeListTwo() {
// 查询所有一级分类与二级分类
List<Type> firstLevelList = typeMapper.selectByLevel(1);
List<Type> secondLevelList = typeMapper.selectByLevel(2);
// 创建返回结果集集合
List<FirstTypeInfo> firstTypeInfoList = new ArrayList<>();
// 一级分类循环
for (Type firstType : firstLevelList) {
FirstTypeInfo firstTypeInfo = new FirstTypeInfo();
List<SecondTypeInfo> secondTypeInfoList = new ArrayList<>();
// 统计一级分类总数量
int firstShopCount = 0;
// 二级分类循环
for (Type secondType : secondLevelList) {
if (secondType.getTypeParentsId().equals(firstType.getTypeId())) {
SecondTypeInfo secondTypeInfo = new SecondTypeInfo();
secondTypeInfo.setSecondTypeId(secondType.getTypeId());
secondTypeInfo.setSecondTypeName(secondType.getTypeName());
// 查询当前二级分类的店铺数量
int secondShopCount = shopMapper.selectSecondShopCount(secondType.getTypeId());
secondTypeInfo.setSecondTypeCount(secondShopCount);
secondTypeInfo.setSecondTypeParentsId(secondType.getTypeParentsId());
secondTypeInfoList.add(secondTypeInfo);
firstShopCount += secondShopCount;
}
}
firstTypeInfo.setFirstTypeId(firstType.getTypeId());
firstTypeInfo.setFirstTypeName(firstType.getTypeName());
firstTypeInfo.setFirstTypeCount(firstShopCount);
firstTypeInfo.setSecondTypeInfoList(secondTypeInfoList);
firstTypeInfoList.add(firstTypeInfo);
}
// 返回结果集
return firstTypeInfoList;
}
存在的问题
- 第一个问题是在循环中使用了查询语句selectSecondShopCount(),这 意味着有多少个分类我就要执行多少条查询语句,还是在循环中执行的!这是严重影响性能的,在数据量小且单体项目不会出错,就是时间长点。但是在微服务架构下,服务之间存在调用关系,对接口的时间是有要求,请求时间太长会响应超时,调用失败。
- 第二个问题是这里使用了两层循环,实际上二级分类我们可以做整体处理,通过图我们可以看到二级分类的数据完全可以通过group by 语句查询出来,通过Stream流来对集合进行塞选,塞选的标准是分析中的第4点
- 第三个算是一个优化点,我们不单单有二级分类的数量,还有一级分类的数量,二级分类的数量可以count但是一级分类没有办法,它是二级分类的加和,刚开始我的做法是循环外定义一个变量firstShopCount,通过这个变量来统计一级分类的总和
以上写法没有使用Java 8新特性,Stream流与Lambda表达式,另一个就是没有灵活使用SQL知识
如何优化
- 利用group by根据所需字段进行分组,得到二级分类的集合(省去第二层循环)
- 集合操作使用Stream流,配合Lambda简化代码
- 求一级分类总和依旧使用Stream,通过父id进行联系,减少与数据库的交互次数
最终版代码
主要逻辑
public List<FirstTypeInfo> selectTypeList() {
// 查询所有的分类(含一级分类与二级分类)
List<Type> typeList = typeMapper.selectAll();
// 筛选出所有的一级分类
List<Type> firstTypes = typeList.stream()
.filter(type -> "1".equals(type.getLevel().toString()))
.collect(Collectors.toList());
// 批量查询店铺信息以及数量(sql见下个代码块)
List<SecondTypeInfo> secondTypeInfoList = shopMapper.selectShopInfoAndCount();
// 新建一个List存放组装的数据
List<FirstTypeInfo> firstTypeInfoList = new ArrayList<>();
// 组装数据
for (Type firstType : firstTypes) {
FirstTypeInfo firstTypeInfo = new FirstTypeInfo();
firstTypeInfo.setFirstTypeId(firstType.getTypeId());
firstTypeInfo.setFirstTypeName(firstType.getTypeName());
// 判断一级分类下是否有二级分类,没有就不展示一级分类
int sum = secondTypeInfoList.stream()
.filter(secondTypeInfo -> firstType.getTypeId().equals(secondTypeInfo.getSecondTypeParentsId()))
.mapToInt(SecondTypeInfo::getSecondTypeCount)
.sum();
if (sum == 0) {
continue;
}
firstTypeInfo.setFirstTypeCount(sum);
// 二级列表
List<SecondTypeInfo> secondTypeInfos = secondTypeInfoList.stream()
.filter(secondTypeInfo -> firstType.getTypeId().equals(secondTypeInfo.getSecondTypeParentsId()))
.collect(Collectors.toList());
firstTypeInfo.setSecondTypeInfoList(secondTypeInfos);
firstTypeInfoList.add(firstTypeInfo);
}
return firstTypeInfoList;
}
关键SQL
<select id="selectShopInfoAndCount" resultType="com.evader.generator.model.SecondTypeInfo">
select t.type_id as secondTypeId, t.type_name as secondTypeName, t.type_parents_id as secondTypeParentsId,count(s.shop_type_id) as secondTypeCount
from type t
left join shop s
on t.type_id = s.shop_type_id
group by t.type_id, t.type_name, t.type_parents_id
</select>
结果

留个问题
其实美团的商户不止一种类型,这种情况下,商店的类型存的就是数组,这个时候应该如何统计呢?有兴趣的可以思考一下。


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











