






我本硕都是双非计算机专业,从研一下开始学习大数据开发的相关知识,从找实习到秋招,我投递过100+公司,拿到了10+的offer,包括滴滴、字节、蚂蚁、携程、蔚来、去哪儿等大厂。经过无数场的面试,不断总结,终于摸清了面试官到底喜欢问哪些问题。今天把自己总结的一些内容分享给大家,欢迎大家补充讨论!!!
ps:这里仅提供了部分大数据开发面试的相关内容
1. MapReduce的原理
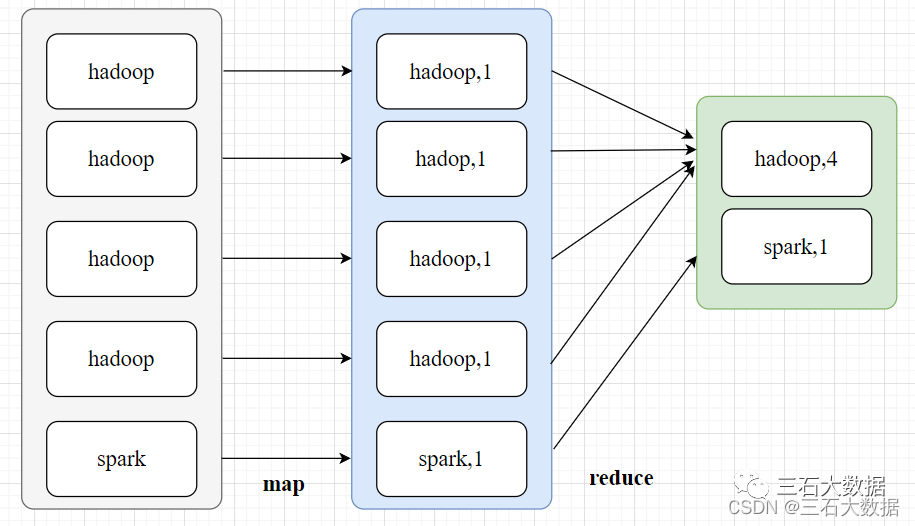
- map阶段:首先通过InputFormat把输入目录下的文件进行逻辑切片,默认大小等于block大小,并且每一个切片由一个maptask来处理,同时将切片中的数据解析成<key,value>的键值对,k表示偏移量,v表示一行内容;紧接着调用Mapper类中的map方法。将每一行内容进行处理,解析为<k,v>的键值对,在wordCount案例中,k表示单词,v表示数字1 ;
- shuffle阶段:map端shuffle:将map后的<k,v>写入环形缓冲区【默认100m】,一半写元数据信息(key的起始位置,value的起始位置,value的长度,partition号),一半写<k,v>数据,等到达80%的时候,就要进行spill溢写操作,溢写之前需要对key按照分区进行快速排序【分区算法默认是HashPartitioner,分区号是根据key的hashcode对reduce task个数取模得到的。这时候有一个优化方法可选,combiner合并,就是预聚合的操作,将有相同Key 的Value 合并起来, 减少溢写到磁盘的数据量,只能用来累加、最大值使用,不能在求平均值的时候使用】;然后溢写到文件中,并且进行merge归并排序(多个溢写文件);reduce端shuffle:reduce会拉取copy同一分区的各个maptask的结果到内存中,如果放不下,就会溢写到磁盘上;然后对内存和磁盘上的数据进行merge归并排序(这样就可以满足将key相同的数据聚在一起);【Merge有3种形式,分别是内存到内存,内存到磁盘,磁盘到磁盘。默认情况下第一种形式不启用,第二种Merge方式一直在运行(spill阶段)直到结束,然后启用第三种磁盘到磁盘的Merge方式生成最终的文件。】
- reduce阶段:key相同的数据会调用一次reduce方法,每次调用产生一个键值对,最后将这些键值对写入到HDFS文件中。
2.遇见过数据倾斜
是什么?
- 绝大部分任务都很快完成,只有一个或者少数几个任务执行的很慢甚至最终执行失败(通过spark ui可以看见,特别明显)
为什么?
-
一个任务通常来说分为map操作和reduce操作(shuffle归在reduce中了),如图所示,这里举了一个wordcount案例,便于辅助理解那么这两个部分就都有可能发生数据倾斜
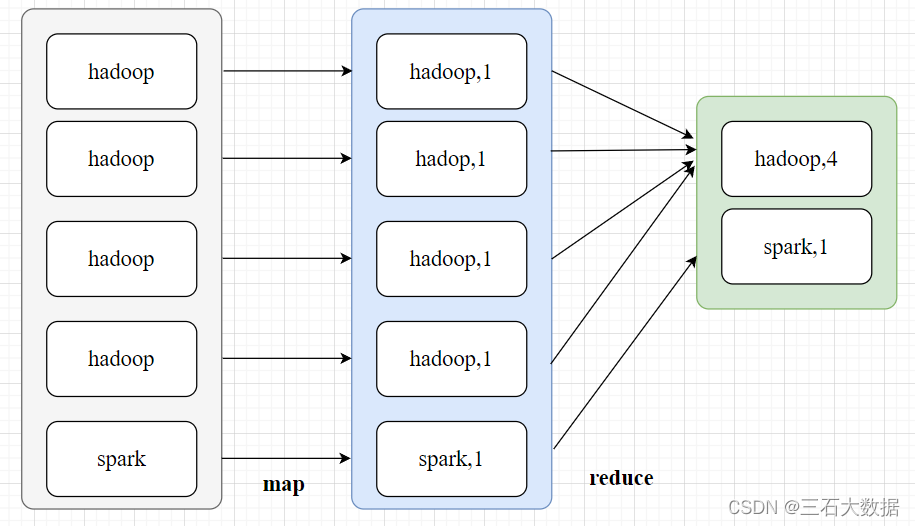
- map端:比如交由每个map task处理的文件大小不一致
- reduce端:key值分布不均匀+shuffle(这两个条件缺一不可)
- 我们也应该进一步思考,key值为什么会分布不均匀数据可能会存在大量的空值业务存在热点数据
怎么办?
- 知道了为什么之后,对症下药就可以了
- map端:在任务之前,我们手动让每个数据文件大小一致如果过滤空值不会对业务产生影响,那么我们应该过滤空值
- reduce端:我们不好直接对key下手,显然就是对shuffle进行下手了
- 最好的手法:干掉shuffle
- 开启map端join
- 适用场景:大表join小表(虽然说小表的阈值可以自己设置,但是设置太大,那么就会占用过多的计算资源,显然是不合适的,通常最多设置在500m以下)
- 万能手法:
- 加盐为数据量特别大的key增加随机前缀或后缀,使得这些key分散到不同的task中;那么此时数据倾斜的key变了,如何join呢?于是可以将另外一份对应相同key的数据与随机前缀或者后缀作笛卡尔积,保证两个表可以join上(当然这是join的场景,对于group by计算也是一样的)
- 最好的手法:干掉shuffle
3.sparksql有几种join方式
- 包括 broadcast hash join,shuffle hash join,sort merge join,前两种都是基于hash join;broadcast 适合一张很小的表和一张大表进行join,shuffle适合一张较大的小表和一张大表进行join,sort适合两张较大的表进行join。
- 先说一下hash join吧,这个算法主要分为三步,首先确定哪张表是build table和哪张表是probe table,这个是由spark决定的,通常情况下,小表会作为build table,大表会作为probe table;然后构建hash table,遍历build table中的数据,对于每一条数据,根据join的字段进行hash,存放到hashtable中;最后遍历probe table中的数据,使用同样的hash函数,在hashtable中寻找join字段相同的数据,如果匹配成功就join到一起。这就是hash join的过程
- broadcast hash join分为broadcast阶段和hash join阶段,broadcast阶段就是 将小表广播到所有的executor上,hash join阶段就是在每个executor上执行hash join,小表构建为hash table,大表作为probe table
- shuffle hash join分为shuffle阶段和hash join阶段,shuffle阶段就是 对两张表分别按照join字段进行重分区,让相同key的数据进入同一个分区中;hash join阶段就是 对每个分区中的数据执行hash join
- sort merge join分为shuffle阶段,sort阶段和merge阶段,shuffle阶段就是 将两张表按照join字段进行重分区,让相同key的数据进入同一个分区中;sort阶段就是 对每个分区内的数据进行排序;merge阶段就是 对排好序的分区表进行join,分别遍历两张表,key相同就join输出,如果不同,左边小,就继续遍历左边的表,反之,遍历右边的表
4.HDFS的读写流程
5.HDFS的架构
6.小文件问题
7.yarn的任务提交流程
8.zab协议
9.kafka的消息存储机制
10.watermark机制的通俗解释
11.如何保证精准一次性语义
…
ps:大家在面试的过程中也需要多去总结被经常问到的问题,当再次被问到的时候,希望你的回答可以惊艳面试官!!!














 3198
3198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









