






大数据开发面试笔记
本篇博客是本人学习大数据开发各种框架和经历各种面试总结的一些笔记,不全在面试中遇到,可以当做知识复习巩固,如果您希望查看重点,可以重点看kafka和flink相关的问题(本人在面试中遇到比较多),或者重点看在您的项目中出现比较多的框架。可以配合另一篇博客java面试笔记,会让您在面试中更有信心,希望能对您有启发。
一、hadoop
1、HDFS的写数据流程

(1) 客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件, NameNode 检查目标文件是否已存在,父目录是否存在。
(2) NameNode 返回是否可以上传。
(3) 客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
(4) NameNode 返回 3 个 DataNode 节点, 分别为 dn1、 dn2、 dn3。
(5) 客户端通过 FSDataOutputStream 模块请求 dn1 上传数据, dn1 收到请求会继续调用dn2,然后 dn2 调用 dn3,将这个通信管道建立完成。
(6) dn1、 dn2、 dn3 逐级应答客户端。
(7)客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet 为单位, dn1 收到一个 Packet 就会传给 dn2, dn2 传给 dn3; dn1 每传一个 packet会放入一个应答队列等待应答。
(8) 当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务器。(重复执行 3-7 步)。
2、HDFS的读数据流程
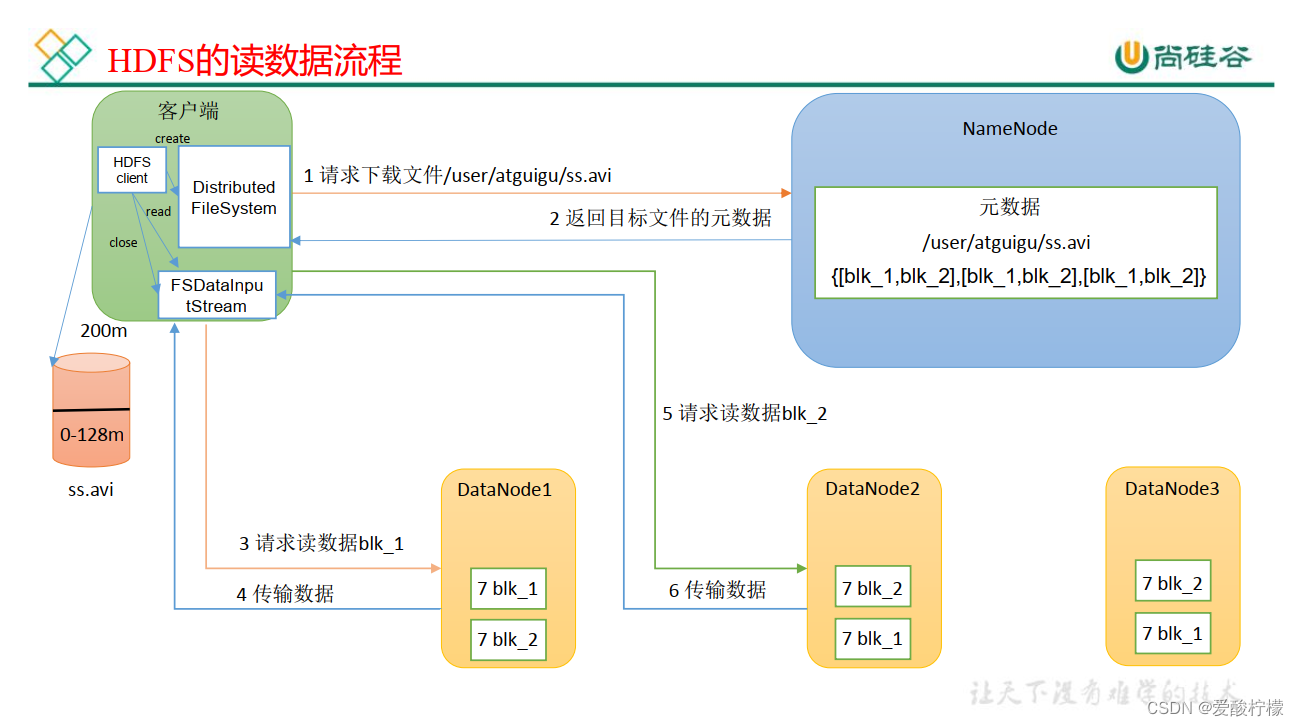
(1) 客户端通过 DistributedFileSystem 向 NameNode 请求下载文件, NameNode 通过查询元数据,找到文件块所在的 DataNode 地址。
(2) 挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。
(3) DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。
(4) 客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
3、NN 和 2NN 工作机制
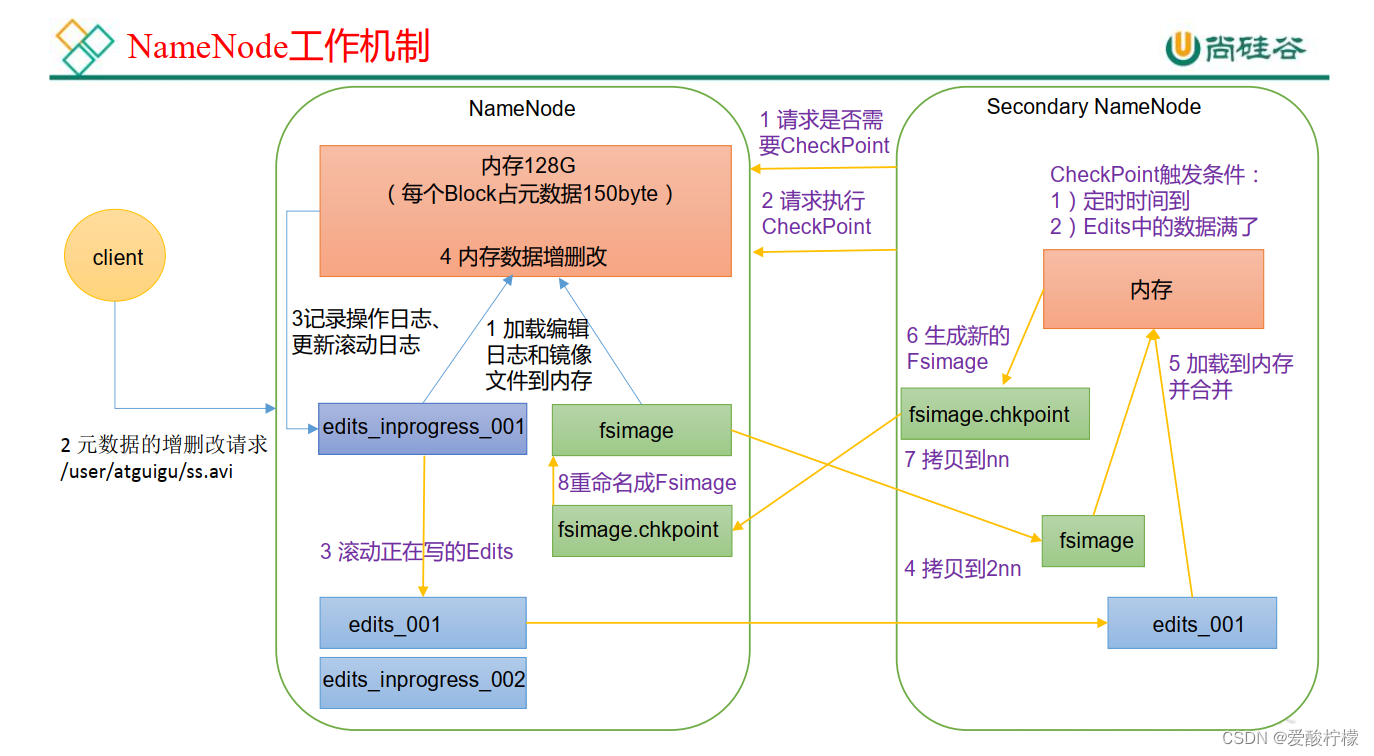
1) 第一阶段: NameNode 启动
(1) 第一次启动 NameNode 格式化后, 创建 Fsimage 和 Edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2) 客户端对元数据进行增删改的请求。
(3) NameNode 记录操作日志,更新滚动日志。
(4) NameNode 在内存中对元数据进行增删改。
2) 第二阶段: Secondary NameNode 工作
(1) Secondary NameNode 询问 NameNode 是否需要 CheckPoint。 直接带回 NameNode是否检查结果。
(2) Secondary NameNode 请求执行 CheckPoint。
(3) NameNode 滚动正在写的 Edits 日志。
(4) 将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode。
(5) Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
(6) 生成新的镜像文件 fsimage.chkpoint。
(7) 拷贝 fsimage.chkpoint 到 NameNode。
(8) NameNode 将 fsimage.chkpoint 重新命名成 fsimage。
4、DataNode 工作机制
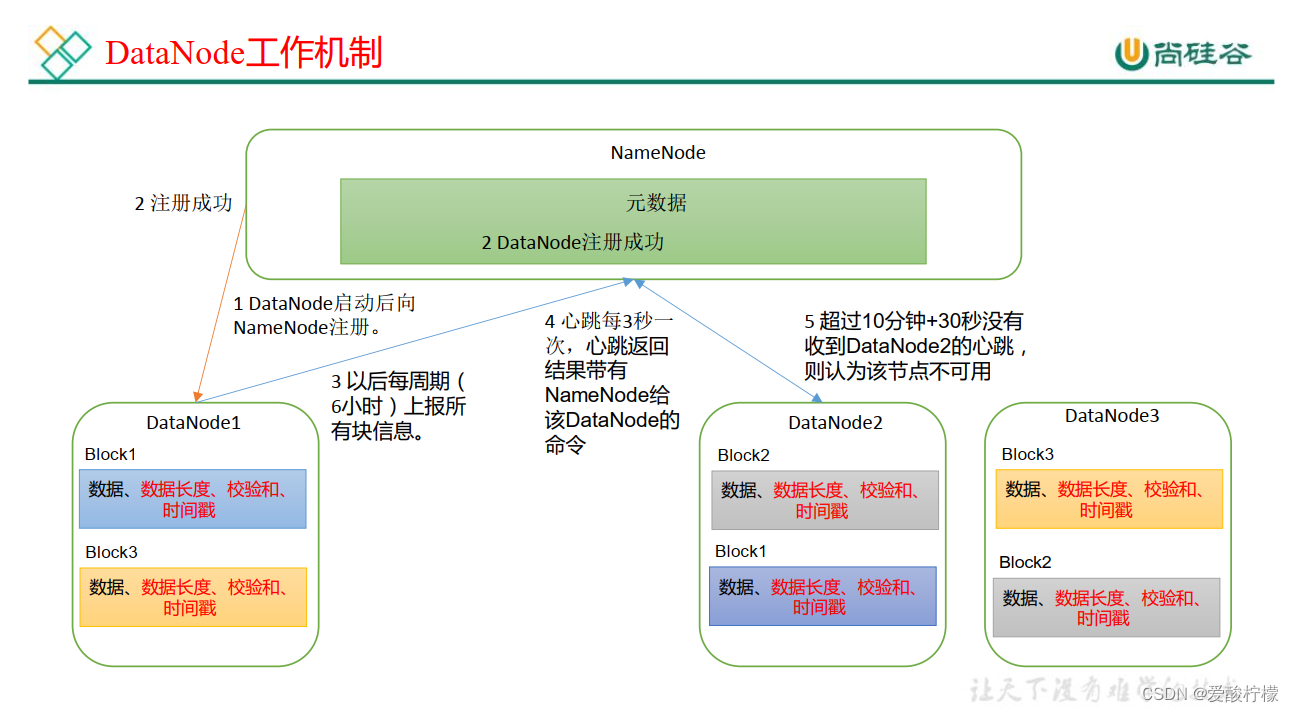
(1) 一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2) DataNode 启动后向 NameNode 注册,通过后,周期性(6 小时) 的向 NameNode 上报所有的块信息。
(3) 心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。 如果超过 10 分钟没有收到某个 DataNode 的心跳,则认为该节点不可用。
(4) 集群运行中可以安全加入和退出一些机器。
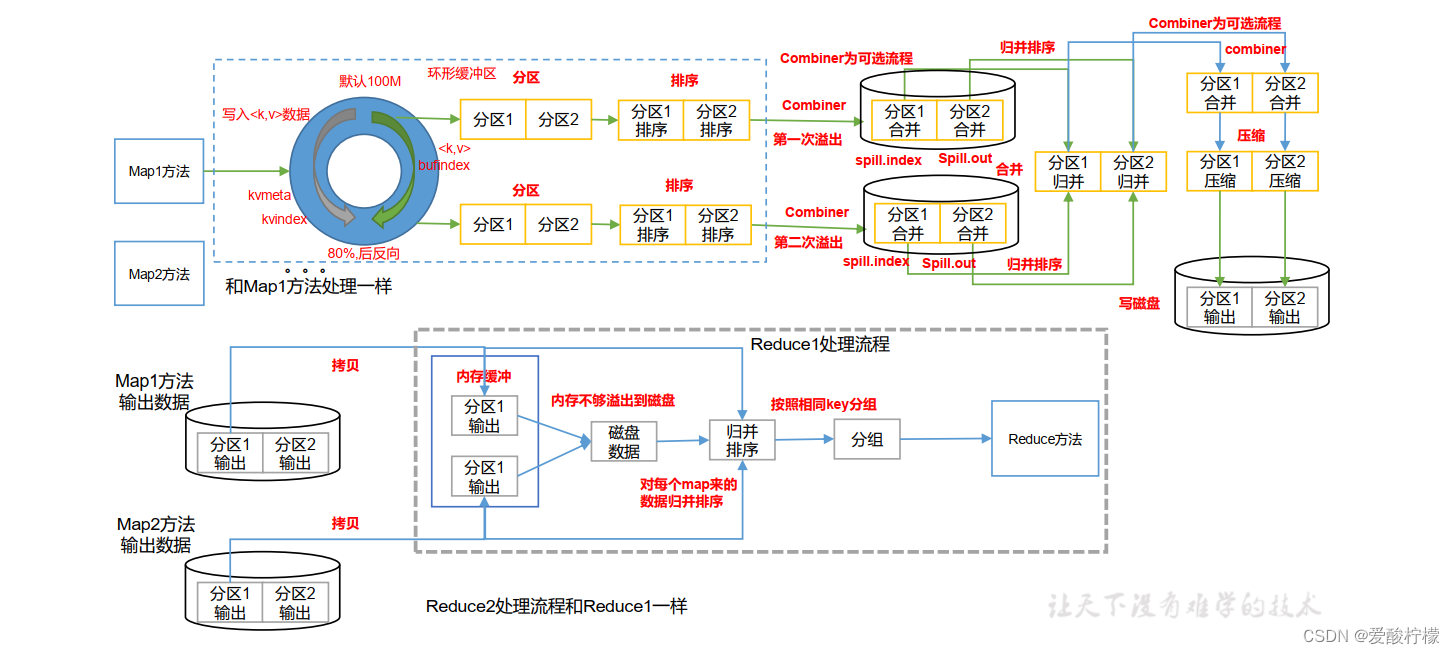
5、shuffle过程
(17条消息) Mapreduce的工作流程以及Shuffle机制_大数据YYDS的博客-CSDN博客
一、Map方法出来之后,首先进入getPartition方法,标记数据的分区;
二、进入环形缓冲区,存放数据和索引,然后溢写到磁盘,再溢写之前有一个快排过程;其中排序方法是快排,排序对象是索引,排序顺序是按字典顺序排;
三、溢写文件包括spill.index和spill.out,前者为索引文件,后者为实际kv数据;(combiner为可选过程)Reduce下载数据时的依据就是通过这个index文件来判断;
四、对溢写出来的文件进行归并排序,这里也有可能产生combiner过程,也能设置压缩过程,减少IO消耗;
五、压缩后的数据写到磁盘中,等待ReduceTask的拉取;
Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
(1)Copy阶段:Reducer通过Http方式得到输出文件的分区。
(reduce端可能从n个map的结果中获取数据)ReduceTask会把Mapper端的输出数据复制过来,先把同一分区(对应自身分区)数据拉到内存中,如果内存不够则移除到磁盘中。
(2)sort阶段:
拉取好之后,对内存和磁盘中所有的数据再做合并和归并排序(把不同map阶段输出的同一分区的数据再做归并排序),然后按照key分组,同组数据进入到Reduce方法中;(内存溢出则做合并保存到磁盘,磁盘中的文件过多做归并排序,分组排序不是一定发生的)
(3)Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。(一般来说是等待Map阶段完成后才会开始reduce方法)
最后就是Reduce过程了,执行Reducer中的计算逻辑,并将结写到HDFS上。
6、yarn工作机制

(1) MR 程序提交到客户端所在的节点。
(2) YarnRunner 向 ResourceManager 申请一个 Application。
(3) RM 将该应用程序的资源路径返回给 YarnRunner。
(4)该程序将运行所需资源提交到 HDFS 上。
(5)程序资源提交完毕后,申请运行 mrAppMaster。
(6) RM 将用户的请求初始化成一个 Task。
(7)其中一个 NodeManager 领取到 Task 任务。
(8)该 NodeManager 创建容器 Container, 并产生 MRAppmaster。
(9) Container 从 HDFS 上拷贝资源到本地。
(10) MRAppmaster 向 RM 申请运行 MapTask 资源。
(11) RM 将运行 MapTask 任务分配给另外两个 NodeManager, 另两个 NodeManager 分别领取任务并创建容器。
(12) MR 向两个接收到任务的 NodeManager 发送程序启动脚本, 这两个 NodeManager分别启动 MapTask, MapTask 对数据分区排序。
(13)MrAppMaster 等待所有 MapTask 运行完毕后,向 RM 申请容器, 运行 ReduceTask。
(14) ReduceTask 向 MapTask 获取相应分区的数据。
(15)程序运行完毕后, MR 会向 RM 申请注销自己。
7、数据库中olap和oltp的区别
1、OLTP的概述:On-Line Transaction Processing 联机事务处理过程(OLTP),也称为面向交易的处理过程。
2、OLAP的概述:联机分析处理OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。
1、基本含义不同:OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,记录即时的增、删、改、查,比如在银行存取一笔款,就是一个事务交易。OLAP即联机分析处理,是数据仓库的核心部心,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态报表系统。
2、实时性要求不同:OLTP实时性要求高,OLTP 数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务。OLAP的实时性要求不是很高,很多应用顶多是每天更新一下数据。
3、数据量不同:OLTP数据量不是很大,一般只读/写数十条记录,处理简单的事务。OLAP数据量大,因为OLAP支持的是动态查询,所以用户也许要通过将很多数据的统计后才能得到想要知道的信息,例如时间序列分析等等,所以处理的数据量很大。
4、用户和系统的面向性不同:OLTP是面向顾客的,用于事务和查询处理。OLAP是面向市场的,用于数据分析。
5、数据库设计不同:OLTP采用实体-联系ER模型和面向应用的数据库设计。OLAP采用星型或雪花模型和面向主题的数据库设计。
我认为这也对应着行存储和列存储两种存储方式,行存储有利于增删,列存储有利于查询,因为行存储会查询到我们不需要的列,并且查询出来的各个列的值类型都不同,比较难以处理这些不同类型的数据。列存储则正好相反,其存储类型一致,有利于压缩。
8、Maper的个数是怎么确定的
map个数的确定
map的个数等于被处理的目录中所有文件划分的 split 的个数。我们知道,mapreduce在处理大文件的时候,会根据一定的规则,把大文件划分成多个,这样能够提高map的并行度。
划分出来的就是InputSplit,每个map处理一个InputSplit。因此,有多少个InputSplit,就有多少个map数。
很多文档中描述,Mapper的数量在默认情况下不可直接控制干预,因为Mapper的数量由输入的大小和个数决定。在默认情况下,最终input占据了多少block,就应该启动多少个Mapper。如果输入的文件数量巨大,但是每个文件的size都小于HDFS的blockSize,那么会造成启动的Mapper等于文件的数量(即每个文件都占据了一个block),那么很可能造成启动的Mapper数量超出限制而导致崩溃。这些逻辑确实是正确的,但都是在默认情况下的逻辑。
其他hadoop面试题:(17条消息) Hadoop高频面试题(建议收藏)_无精疯的博客-CSDN博客
二、Spark
1、RDD 任务划分
Spark:RDD任务切分之Stage任务划分(图解和源码)-技术圈 (proginn.com)
RDD 任务切分中间分为: Application、 Job、 Stage 和 Task
⚫ Application:初始化一个 SparkContext 即生成一个 Application;
⚫ Job:一个 Action 算子就会生成一个 Job;
⚫ Stage: Stage 等于宽依赖(ShuffleDependency)的个数加 1;
⚫ Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
注意: Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
2、缓存和检查点区别
原文链接:https://blog.csdn.net/qq_17685725/article/details/123038224
RDD数据可以持久化缓存,比如 cache()、persist(),虽然快速但也是最不可靠的,比如内存损坏、磁盘损坏。
Checkpoint 的持久化是存储在HDFS上的,因为具备高可用,所以非常可靠,但会切断执行 checkpoint RDD的依赖关系。Checkpoint 常用于RDD数据备份,以便从HDFS中恢。
“checkpoint() 检查点” 和 “cache() / persist() 持久化缓存” 的区别
位置区别:persist 或 cache 会将RDD的数据保存在内存、磁盘、堆外内存中,但是 checkpoint 机制将RDD数据保存在HDFS上。
生命周期:当 Application 执行完毕,或者调用 unpersist,那么 persist 或 cache 的数据会被自动清除。但是 checkpoint 目录的内容不会自动清除,需要手动清除。
血缘关系:persist 或 cache 会保留RDD的血缘关系,如果某个分区的数据丢失,那么可以借助血缘关系重新计算出来。但 checkpoint 会切断依赖链不保留依赖关系,因为即使一个分区的数据丢失损坏,也能直接从HDFS的另外2个副本恢复。
3、RDD、 DataFrame、 DataSet 三者的关系
三者的共性
➢ RDD、 DataFrame、 DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数
据提供便利;
➢ 三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到
Action 如 foreach 时,三者才会开始遍历运算;
➢ 三者有许多共同的函数,如 filter,排序等;
➢ 在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:import spark.implicits._(在
创建好 SparkSession 对象后尽量直接导入)
➢ 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会
内存溢出
➢ 三者都有 partition 的概念
➢ DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
2.5.2 三者的区别
\1) RDD
➢ RDD 一般和 spark mllib 同时使用
➢ RDD 不支持 sparksql 操作
\2) DataFrame
➢ 与 RDD 和 Dataset 不同, DataFrame 每一行的类型固定为 Row,每一列的值没法直
接访问,只有通过解析才能获取各个字段的值
➢ DataFrame 与 DataSet 一般不与 spark mllib 同时使用
➢ DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select, groupby 之类,还能
注册临时表/视窗,进行 sql 语句操作
➢ DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表
头,这样每一列的字段名一目了然(后面专门讲解)
\3) DataSet
➢ Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
➢ DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪
些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共
性中的第七条提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是
不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息
4、Yarn Cluster 模式
Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于实际生产环境。
➢ 在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster,
➢ 随后 ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
➢ Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动 Executor 进程
➢ Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数,
➢ 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
5、spark中的shuffle流程
https://www.jianshu.com/p/542b243d24e9
在Spark Shuffle的具体实现上,主要经历了:hash-based shuffle、sort-based shuffle、Tungsten-sort shuffle 三个大的阶段。
1、hash-based shuffle
(1)Shuffle Write
在Shuffle Write过程会按照hash的方式重组partition的数据,不进行排序。每个map端的任务为每个reduce端的任务都生成一个文件,通过会产生大量的文件(假如map端task数量为m,reduce端task数量为n,则对应 m * n个中间文件),其中伴随着大量的随机磁盘IO操作与大量的内存开销。
(2)Shuffle Read
Reduce端任务首先将Shuffle write生成的文件fetch到本地节点,如果Shuffle Read阶段有combiner操作,则它会把拉到的数据保存在一个Spark封装的哈希表(AppendOnlyMap)中进行合并。

2、Hash Shuffle V2
在Spark 0.8.1 针对原来的hash-based shuffle机制,引入了 File Consolidation 机制。
一个 Executor 上所有的 Map Task 生成的分区文件只有一份,即将所有的 Map Task 相同的分区文件合并,这样每个 Executor 上最多只生成 N 个分区文件。

这样就减少了文件数,但是假如下游 Stage 的分区数 N 很大,还是会在每个 Executor 上生成 N 个文件,同样,如果一个 Executor 上有 K 个 Core,还是会开 K*N 个 Writer Handler,所以这里仍然容易导致OOM。
是否采用File Consolidation机制,需要配置 spark.shuffle.consolidateFiles 参数。
3、Hash Shuffle V3
在Spark 0.9 引入了ExternalAppendOnlyMap。
在combine的时候,可以将数据spill到磁盘,然后通过堆排序merge。
4、Sort Shuffle V1
每个 Task 不会为后续的每个 Task 创建单独的文件,而是将所有对结果写入同一个文件。该文件中的记录首先是按照 Partition Id 排序,每个 Partition 内部再按照 Key 进行排序,Map Task 运行期间会顺序写每个 Partition 的数据,同时生成一个索引文件记录每个 Partition 的大小和偏移量。
在Reduce阶段,Reduce Task拉取数据做Combine时不再是采用HashMap,而是采用ExternalAppendOnlyMap,该数据结构在做Combine时,如果内存不足,会刷写磁盘,很大程度上保证了系统的鲁棒性,避免了大数据情况下的OOM。
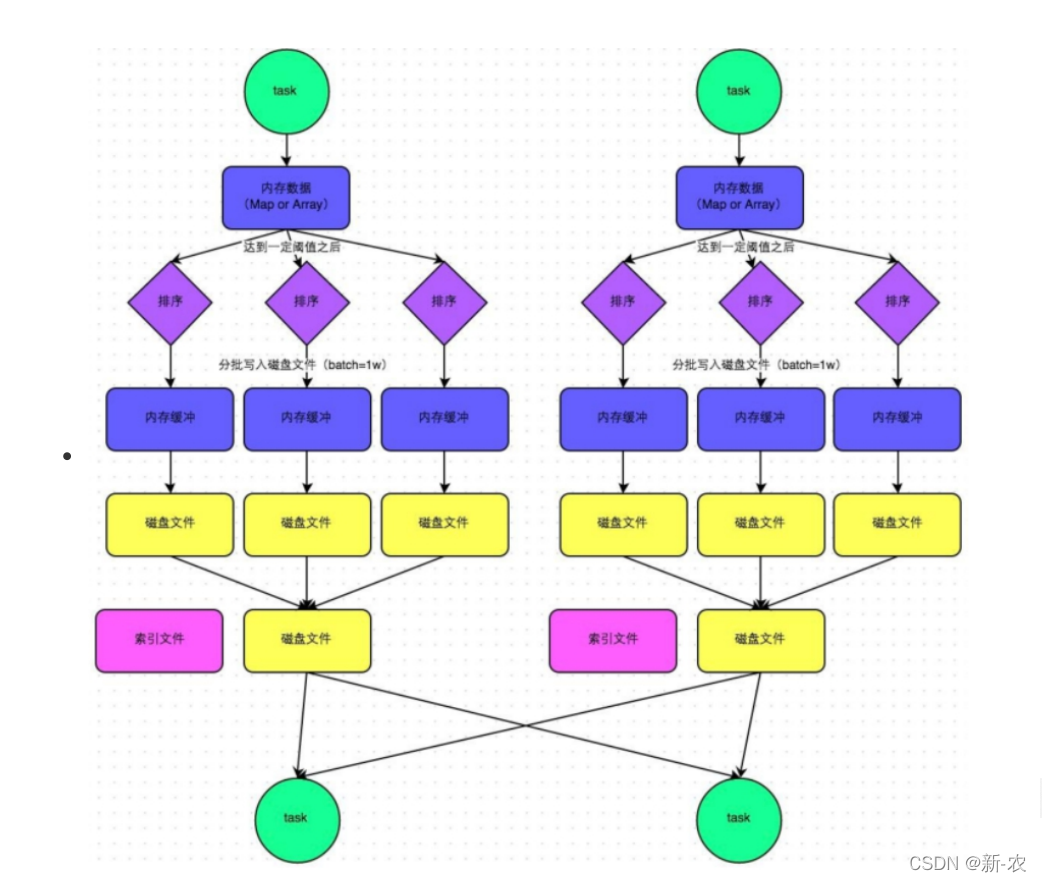
5、Tungsten-Sort Based Shuffle
从 Spark 1.5.0 开始,Spark 开始了钨丝计划(Tungsten),目的是优化内存和CPU的使用,进一步提升spark的性能。由于使用了堆外内存,而它基于 JDK Sun Unsafe API,故 Tungsten-Sort Based Shuffle 也被称为 Unsafe Shuffle。
它的做法是将数据记录用二进制的方式存储,直接在序列化的二进制数据上 Sort 而不是在 Java 对象上,这样一方面可以减少内存的使用和 GC 的开销,另一方面避免 Shuffle 过程中频繁的序列化以及反序列化。在排序过程中,它提供 cache-efficient sorter,使用一个 8 bytes 的指针,把排序转化成了一个指针数组的排序,极大的优化了排序性能。
但是使用 Tungsten-Sort Based Shuffle 有几个限制,Shuffle 阶段不能有 aggregate 操作,分区数不能超过一定大小(2^24-1,这是可编码的最大 Parition Id),所以像 reduceByKey 这类有 aggregate 操作的算子是不能使用 Tungsten-Sort Based Shuffle,它会退化采用 Sort Shuffle。
6、Sort Shuffle V2
从 Spark-1.6.0 开始,把 Sort Shuffle 和 Tungsten-Sort Based Shuffle 全部统一到 Sort Shuffle 中,如果检测到满足 Tungsten-Sort Based Shuffle 条件会自动采用 Tungsten-Sort Based Shuffle,否则采用 Sort Shuffle。从Spark-2.0.0开始,Spark 把 Hash Shuffle 移除,可以说目前 Spark-2.0 中只有一种 Shuffle,即为 Sort Shuffle。
spark其他面试题:(17条消息) Spark高频面试题(建议收藏)_无精疯的博客-CSDN博客
三、HBase
1、HBase写流程

写流程:
1) Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以
及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)将数据顺序写入(追加)到 WAL;
5)将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
6)向客户端发送 ack;
7) 等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
2、HBase读流程

读流程
1) Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4) 分别在 Block Cache(读缓存), MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5) 将从文件中查询到的数据块(Block, HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。
6) 将合并后的最终结果返回给客户端。
其他HBase面试题:(17条消息) Hbase面试题(面经)整理__Kafka_的博客-CSDN博客_hbase面试题
(19条消息) HBase常见面试题(建议收藏)_无精疯的博客-CSDN博客
四、Kafka
1、producer ack 为 0, 1, -1 的时候代表啥
原文链接:https://blog.csdn.net/qq_28900249/article/details/90346599
1(默认) 数据发送到Kafka后,经过leader成功接收消息的的确认,就算是发送成功了。在这种情况下,如果leader宕机了,则会丢失数据。
0 生产者将数据发送出去就不管了,不去等待任何返回。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
-1 producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。当ISR中所有Replica都向Leader发送ACK时,leader才commit,这时候producer才能认为一个请求中的消息都commit了。
2、Kafka中的分区细节
(1)指明partition的情况下,直接将指明的值作为partition值;例如partition=0,所有数据写入分区0
( 2) 没有指明partition值但有key的情况下, 将key的hash值与topic的partition数进行取余得到partition值;例如: key1的hash值=5, key2的hash值=6 , topic的partition数=2, 那么key1 对应的value1写入1号分区, key2对应的value2写入0号分区。
(3) 既没有partition值又没有key值的情况下, Kafka采用Sticky Partition(黏性分区器) , 会随机选择一个分区, 并尽可能一直
使用该分区, 待该分区的batch已满或者已完成, Kafka再随机一个分区进行使用(和上一次的分区不同) 。
例如:第一次随机选择0号分区, 等0号分区当前批次满了(默认16k) 或者linger.ms设置的时间到, Kafka再随机一个分区进
行使用(如果还是0会继续随机) 。
3、生产经验——生产者如何提高吞吐量
修改下面的参数:
• batch.size:批次大小,默认16k
• linger.ms:等待时间,修改为5-100ms
• compression.type:压缩snappy生产经验——生产者如何提高吞吐量
• RecordAccumulator:缓冲区大小,修改为64m
4、Kafka怎么保证幂等性
幂等性就是指Producer不论向Broker发送多少次重复数据, Broker端都只会持久化一条, 保证了不重复。
精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2)
重复数据的判断标准: 具有**<PID, Partition, SeqNumber>**相同主键的消息提交时, Broker只会持久化一条。 其
中PID是Kafka每次重启都会分配一个新的; Partition 表示分区号; Sequence Number是单调自增的。
所以幂等性只能保证的是在单分区单会话内不重复。

5、leader的选举流程

controller的选举【broker的leader】
controller的选举是通过broker在zookeeper的"/controller"节点下创建临时节点来实现的,并在该节点中写入当前broker的信息 {“version”:1,”brokerid”:1,”timestamp”:”1512018424988”} ,利用zookeeper的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的broker即为controller,即"先到先得"。
当controller宕机或者和zookeeper失去连接时,zookeeper检测不到心跳,zookeeper上的临时节点会被删除,而其它broker会监听临时节点的变化,当节点被删除时,其它broker会收到通知,重新发起controller选举。
leader的选举【分区副本的leader】
分区leader的选举由 controller 负责管理和实施,当leader发生故障时,controller会将leader的改变直接通过RPC(远程过程调用协议RPC)的方式通知需要为此作出响应的broker,需要为此作出响应的broker即该分区的ISR集合中follower所在的broker,kafka在zookeeper中动态维护了一个ISR,只有ISR里的follower才有被选为Leader的可能。
具体过程是这样的:按照AR集合中副本的顺序 查找到 第一个 存活的、并且属于ISR集合的 副本作为新的leader。一个分区的AR集合在创建分区副本的时候就被指定,只要不发生重分配的情况,AR集合内部副本的顺序是保持不变的,而分区的ISR集合上面说过因为同步滞后等原因可能会改变,所以注意这里是根据AR的顺序而不是ISR的顺序找。
※ 对于上面描述的过程我们假设一种极端的情况,如果partition的所有副本都不可用时,怎么办?这种情况下kafka提供了两种可行的方案:
1、选择 ISR中 第一个活过来的副本作为Leader;
2、选择第一个活过来的副本(不一定是ISR中的)作为Leader;
这就需要在可用性和数据一致性当中做出选择,如果一定要等待ISR中的副本活过来,那不可用的时间可能会相对较长。选择第一个活过来的副本作为Leader,如果这个副本不在ISR中,那数据的一致性则难以保证。kafka支持用户通过配置选择,以根据业务场景在可用性和数据一致性之间做出权衡。
6、Kafka真实数据和索引的查询机制

1、index为稀疏索引,大约每往log文件写入4kb数据,回望index文件写入一条索引。
2、index文件找那个保存的offset为相对offset,这样能确保offset的值所占得空间不会太大。
7、页缓存 + 零拷贝技术
零拷贝: Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。 Kafka Broker应用层不关心存储的数据, 所以就不用走应用层, 传输效率高。
我们看到“零拷贝”是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式。
零拷贝给我们带来的好处
减少甚至完全避免不必要的CPU拷贝,从而让CPU解脱出来去执行其他的任务,减少内存带宽的占用,通常零拷贝技术还能够减少用户空间和操作系统内核空间之间的上下文切换零拷贝的实现。
零拷贝实际的实现并没有真正的标准,取决于操作系统如何实现这一点。零拷贝完全依赖于操作系统。操作系统支持,就有;不支持,就没有。不依赖Java本身。
PageCache页缓存: Kafka重度依赖底层操作系统提供的PageCache功能。 当上层有写操作时, 操作系统只是将数据写入
PageCache。 当读操作发生时, 先从PageCache中查找, 如果找不到, 再去磁盘中读取。 实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。

8、消费者组消费流程
1、初始化

1、 coordinator:辅助实现消费者组的初始化和分区的分配。coordinator节点选择 = groupid的hashcode值 % 50( __consumer_offsets的分区数量)例如: groupid的hashcode值 = 1, 1% 50 = 1,那么__consumer_offsets 主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
1)每个consumer都发送JoinGroup请求 。
2)选出一个consumer作为leader
3)把要消费的topic情况发送给leader 消费者
4) leader会负责制定消费方案
5)把消费方案发给coordinator
6) Coordinator就把消费方案下发给各个consumer
7)每个消费者都会和coordinator保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;
或者消费者处理消息的时间过长(max.poll.interval.ms5分钟),也会触发再平衡 。
9、分区的分配以及再平衡
1、一个consumer group中有多个consumer组成, 一个 topic有多个partition组成, 现在的问题是, 到底由哪个consumer来消费哪个partition的数据。
2、 Kafka有四种主流的分区分配策略: Range、 RoundRobin、 Sticky、 CooperativeSticky。可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。 Kafka可以同时使用多个分区分配策略。
1) Range 分区策略原理
首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。假如现在有 7 个分区, 3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2。 通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。 如果除不尽,那么前面几个消费者将会多消费 1 个分区。

Range 分区分配再平衡案例
(1)停止掉 0 号消费者, 快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 3、 4 号分区数据。
2 号消费者:消费到 5、 6 号分区数据。
0 号消费者的任务会整体被分配到 1 号消费者或者 2 号消费者。
说明: 0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2) 再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、 1、 2、 3 号分区数据。
2 号消费者:消费到 4、 5、 6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。
2)RoundRobin 以及再平衡
RoundRobin 针对集群中所有Topic而言。RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者 。
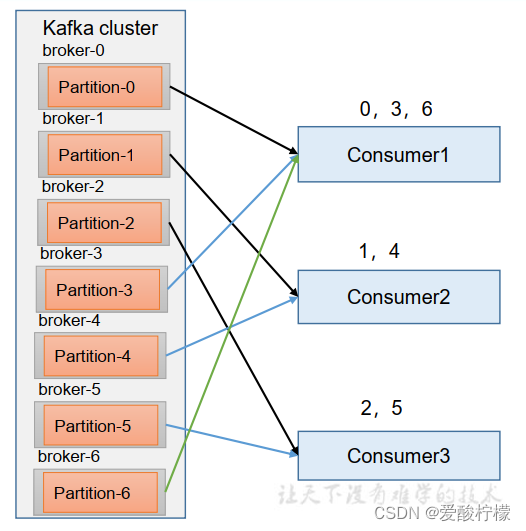
1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、 5 号分区数据
2 号消费者:消费到 4、 1 号分区数据
0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 、 6 和 3 号分区数据,
分别由 1 号消费者或者 2 号消费者消费。
说明: 0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、 2、 4、 6 号分区数据
2 号消费者:消费到 1、 3、 5 号分区数据
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
3)Sticky 以及再平衡
粘性分区定义: 可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。 粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略, 首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化 。
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、 5、 3 号分区数据。
2 号消费者:消费到 4、 6 号分区数据。
0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别
由 1 号消费者或者 2 号消费者消费。
说明: 0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 2、 3、 5 号分区数据。
2 号消费者:消费到 0、 1、 4、 6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配。
10、offset 位移
从0.9版本开始, consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets 。
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。 key 是 group.id+topic+分区号, value 就是当前 offset 的值。 每隔一段时间, kafka 内部会对这个 topic 进行compact,也就是每个 group.id+topic+分区号就保留最新数据。
重复消费: 已经消费了数据,但是 offset 没提交。
漏消费: 先提交 offset 后消费,有可能会造成数据的漏消费。
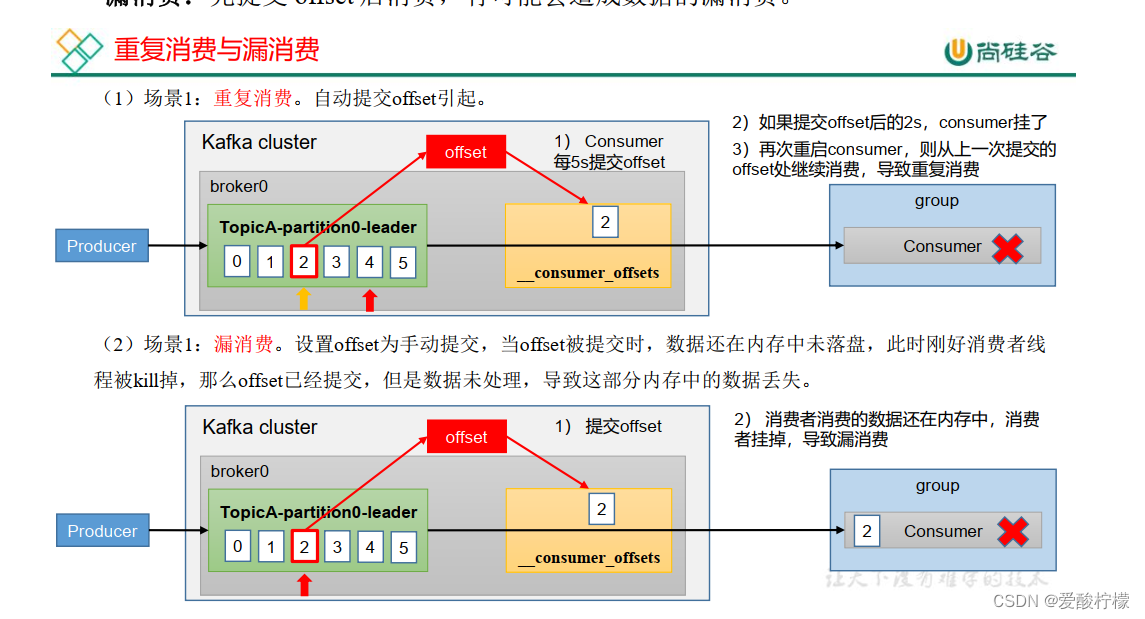
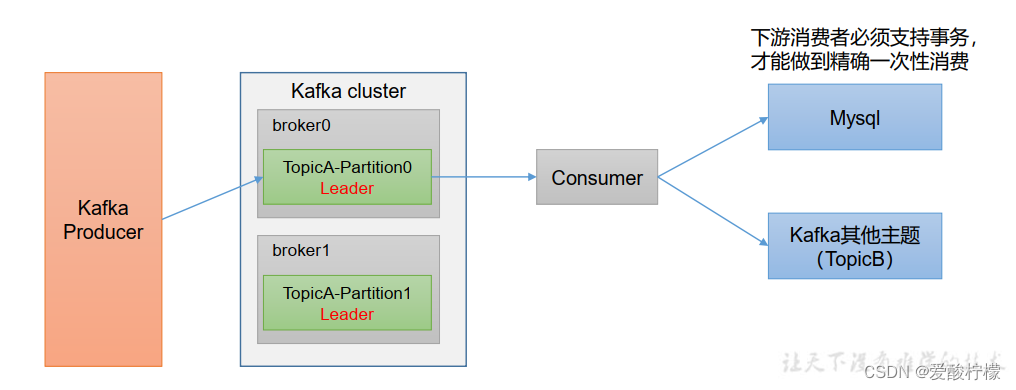
如果想完成Consumer端的精准一次性消费, 那么需要Kafka消费端将消费过程和提交offset过程做原子绑定。 此时我们需要将Kafka的offset保存到支持事务的自定义介质( 比如MySQL) 。
其他Kafka面试题:20道经典的Kafka面试题详解 - 简书 (jianshu.com)
(19条消息) 精心整理了Kafka 高频面试题(建议收藏)_无精疯的博客-CSDN博客
五、Hive
(17条消息) Hive面试题汇总(2021)_「已注销」的博客-CSDN博客_hive面试题
(23条消息) Hive SQL面试题(附答案)_无精疯的博客-CSDN博客
1、hive sql转换为MR程序

1.进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);
2.遍历AST,抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元;
3.遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;
4.使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;
5.遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;
6.使用物理优化器对TaskTree进行物理优化;
7.生成最终的执行计划,提交任务到Hadoop集群运行。
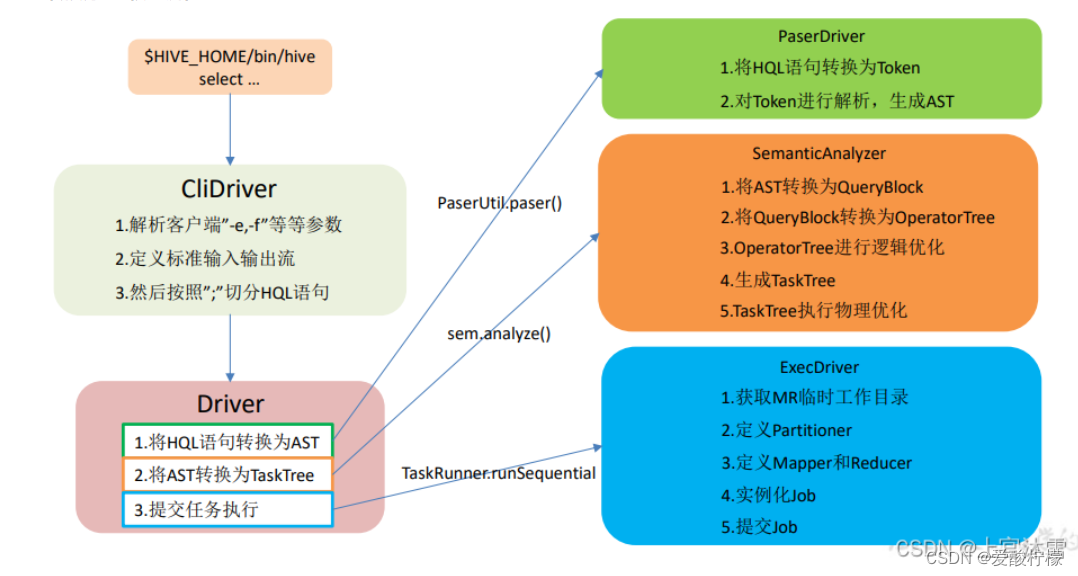
2、hsql 练习题
(23条消息) Hive SQL面试题(附答案)_无精疯的博客-CSDN博客
六、Flink
1、Flink 相比传统的 Spark Streaming 有什么区别?
这个问题是一个非常宏观的问题,因为两个框架的不同点非常之多。但是在面试时有非常重要的一点一定要回答出来:Flink 是标准的实时处理引擎,基于事件驱动。而 Spark Streaming 是微批(Micro-Batch)的模型。
下面我们就分几个方面介绍两个框架的主要区别:
- 架构模型
Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
- 任务调度
Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。
Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
- 时间机制
Spark Streaming 支持的时间机制有限,只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
2、Flink的部署模式
https://www.modb.pro/db/128796
Flink 为各种场景提供了不同的程序部署模式,主要有以下三种:
⚫ 会话模式(Session Mode)
集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
⚫ 单作业模式(Per-Job Mode)
为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。
如果通过远程实体(Deployer)提交,此过程包括:在本地下载应用程序的依赖项,执行main()方法来提取job graph,将job graph及其依赖发送到集群执行,等待结果。这一系列过程使得客户机资源消耗高,因为它可能需要大量的网络带宽来下载依赖,并将二进制文件发送到集群,以及CPU周期来执行main()方法。随着越来越多的用户共享相同的客户机,这个问题将更加明显。
⚫ 应用模式(Application Mode)
应用代码都是在客户端上执行,然后由客户端提交给 JobManager 的。
Application模式将Per-Job模式的资源隔离与轻量级、可扩展的作业提交过程结合起来。Application模式为每个提交的作业创建一个集群,但作业的main()方法将在JobManager上执行,以节省提取job graph所需的CPU周期,也节省客户端下载依赖及将job graph及其依赖关系传送到群集所需的带宽。
按资源管理分类Flink集群的部署模式:
⚫ 独立模式:部署 Flink 最基本也是最简单的方式:所需要的所有 Flink 组件,都只是操作系统上运行的一个 JVM 进程。
⚫ YARN模式:客户端把 Flink 应用提交给 Yarn 的 ResourceManager,Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署 JobManager 和 TaskManager 的实例,从而启动集群。
⚫ K8S模式
3、作业提交流程
1、高层级抽象视角
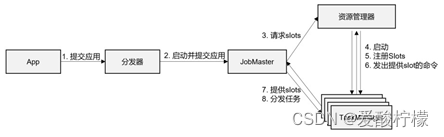
具体步骤如下:
(1) 一般情况下,由客户端(App)通过分发器提供的 REST 接口,将作业提交给JobManager。
(2) 由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3) JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后向资源管理器请求资源(slots)。
(4) 资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
(5) TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)。
(6) 资源管理器通知 TaskManager 为新的作业提供 slots。
(7) TaskManager 连接到对应的 JobMaster,提供 slots。
(8) JobMaster 将需要执行的任务分发给 TaskManager。
(9) TaskManager 执行任务,互相之间可以交换数据。
如果部署模式不同,或者集群环境不同(例如 Standalone、YARN、K8S 等),其中一些步骤可能会不同或被省略,也可能有些组件会运行在同一个 JVM 进程中。
2、独立模式
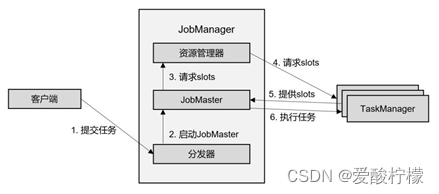
在独立模式(Standalone)下,只有会话模式和应用模式两种部署方式。两者整体来看流程是非常相似的:TaskManager 都需要手动启动,所以当 ResourceManager 收到 JobMaster 的请求时,会直接要求 TaskManager 提供资源。而 JobMaster 的启动时间点,会话模式是预先启动,应用模式则是在作业提交时启动。除去第 4 步不会启动 TaskManager,而且直接向已有的 TaskManager 要求资源,其他步骤与上一节所讲抽象流程完全一致。
3、YARN集群
①会话模式

-
客户端通过REST接口,将作业提交给分发器。
-
分发器启动JobMaster,并将作业(包含JobGraph)提交给JobMaster。
-
JobMaster向资源管理器请求资源(slots)。
-
资源管理器向yarn的资源管理器请求container资源。
-
YARN启动新的TaskManager容器。
-
TaskManager启动之后向Flink的资源管理器注册自己的可用任务槽。
-
资源管理器通知TaskManage为新的作业提供slots。
-
TaskManager连接对应的JobMaster,提供slots。
-
JobMaster将需要执行的任务分发给TaskManager,执行任务。
可见,整个流程除了请求资源时要“上报”YARN 的资源管理器,其他与 4.2.1 节所述抽象流程几乎完全一样。
②单作业模式
在单作业模式下,Flink 集群不会预先启动,而是在提交作业时,才启动新的 JobManager。
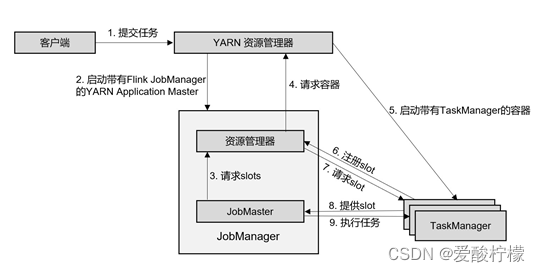
(1) 客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置上传到 HDFS,以便后续启动 Flink 相关组件的容器。
(2) YARN 的资源管理器分配 Container 资源,启动 Flink JobManager,并将作业提交给JobMaster。这里省略了 Dispatcher 组件。
(3) JobMaster 向资源管理器请求资源(slots)。
(4) 资源管理器向 YARN 的资源管理器请求 container 资源。
(5) YARN 启动新的 TaskManager 容器。
(6) TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7) 资源管理器通知 TaskManager 为新的作业提供 slots。
(8) TaskManager 连接到对应的 JobMaster,提供 slots。
(9) JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,区别只在于 JobManager 的启动方式,以及省去了分发器。当第 2 步作业提交给JobMaster,之后的流程就与会话模式完全一样了。
③应用模式
应用模式与单作业模式的提交流程非常相似,只是初始提交给 YARN 资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在 Flink 集群中启动各自对应的 JobMaster。
4、并行度设置优先级
所有的并行度设置方法,它们的优先级如下:
(1) 对于一个算子,首先看在代码中是否单独指定了它的并行度,这个特定的设置优先级最高,会覆盖后面所有的设置。
(2) 如果没有单独设置,那么采用当前代码中执行环境全局设置的并行度。
(3) 如果代码中完全没有设置,那么采用提交时-p 参数指定的并行度。
(4) 如果提交时也未指定-p 参数,那么采用集群配置文件中的默认并行度。
这里需要说明的是,算子的并行度有时会受到自身具体实现的影响。比如之前我们用到的读取 socket 文本流的算子 socketTextStream,它本身就是非并行的 Source 算子,所以无论怎么设置,它在运行时的并行度都是 1,对应在数据流图上就只有一个并行子任务。
5、逻辑流图,作业图,执行图,物理图
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图
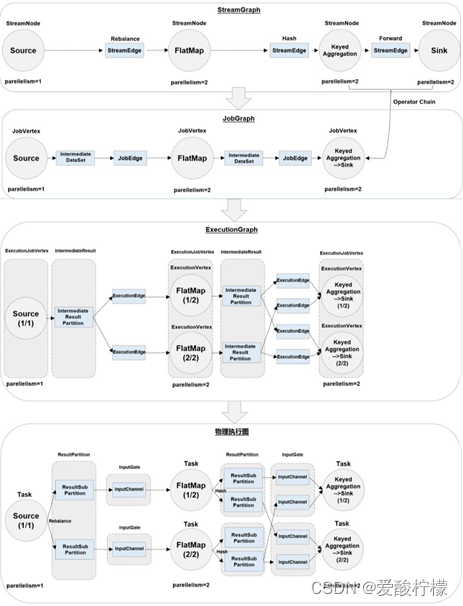
1、逻辑流图
这是根据用户通过 DataStream API 编写的代码生成的最初的 DAG 图,用来表示程序的拓扑结构。这一步一般在客户端完成。
2、作业图
主要的优化为: 将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph 一般也是在客户端生成的,在作业提交时传递给 JobMaster。
3、执行图
jobMaster 收到 JobGraph 后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
4、物理图
物理图主要就是在执行图的基础上,进一步确定数据存放的位置和收发的具体方式。有了物理图,TaskManager 就可以对传递来的数据进行处理计算了
6、基本算子
一、转换算子
1. 映射(map)
简单来说,就是一个“一一映射”,消费一个元素就产出一个元素。MapFunction 实现类的泛型类型,与输入数据类型和输出数据的类型有关。在实现 MapFunction 接口的时候,需要指定两个泛型,分别是输入事件和输出事件的类型,还需要重写一个 map()方法,定义从一个输入事件转换为另一个输出事件的具体逻辑。
stream.map(new MapFunction<Event, String>() {
@Override public String map(Event e) throws Exception {
return e.user;
}
});
2、过滤(filter)
对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉。
stream.filter(new FilterFunction<Event>() {
@Override public boolean filter(Event e) throws Exception {
return e.user.equals("Mary");
}
});
3、扁平映射(flatMap)
flatMap 操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。
stream.flatMap(new MyFlatMap());
public static class MyFlatMap implements FlatMapFunction<Event, String> {
@Override
public void flatMap(Event value, Collector<String> out) throws Exception
{
if (value.user.equals("Mary")) {
out.collect(value.user);
} else if (value.user.equals("Bob")) {
out.collect(value.user);
out.collect(value.url);
}
}
}
二、聚合算子
1. 按键分区(keyBy)
KeyedStream<Event, String> keyedStream = stream.keyBy(e -> e.user);
2. 简单聚合
有了按键分区的数据流 KeyedStream,我们就可以基于它进行聚合操作了。Flink 为我们内置实现了一些最基本、最简单的聚合 API,主要有以下几种:
⚫ sum():在输入流上,对指定的字段做叠加求和的操作。
⚫ min():在输入流上,对指定的字段求最小值。
⚫ max():在输入流上,对指定的字段求最大值。
⚫ minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。
⚫ maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
简单聚合算子使用非常方便,语义也非常明确。这些聚合方法调用时,也需要传入参数;但并不像基本转换算子那样需要实现自定义函数,只要说明聚合指定的字段就可以了。指定字段的方式有两种:指定位置,和指定名称。
//对于元组类型的数据,同样也可以使用这两种方式来指定字段。需要注意的是,元组中字段的名称,是以 f0、f1、f2、…来命名的。
stream.keyBy(r -> r.f0).sum(1).print();
stream.keyBy(r -> r.f0).sum("f1").print();
stream.keyBy(r -> r.f0).max(1).print();
stream.keyBy(r -> r.f0).max("f1").print();
//而如果数据流的类型是 POJO 类,那么就只能通过字段名称来指定,不能通过位置来指定了。
stream.keyBy(e -> e.user).max("timestamp").print(); // 指定字段名称
3、归约聚合(reduce)
reduce 的语义是针对列表进行规约操作,运算规则由 ReduceFunction 中的 reduce 方法来定义,而在 ReduceFunction 内部会维护一个初始值为空的累加器,注意累加器的类型和输入元素的类型相同,当第一条元素到来时,累加器的值更新为第一条元素的值,当新的元素到来时,新元素会和累加器进行累加操作,这里的累加操作就是 reduce 函数定义的运算规则。
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1,
Tuple2<String, Long> value2) throws Exception {
// 每到一条数据,用户pv的统计值加1
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
})
三、用户自定义和富函数类型
Rich Function 有生命周期的概念。典型的生命周期方法有:
⚫ open()方法,是 Rich Function 的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前,open()会首先被调用。所以像文件 IO 的创建,数据库连接的创建,配置文件的读取等等这样一次性的工作,都适合在 open()方法中完成。。
⚫ close()方法,是生命周期中的最后一个调用的方法,类似于解构方法。一般用来做一些清理工作。
需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如 RichMapFunction 中的 map(),在每条数据到来后都会触发一次调用。
// 将点击事件转换成长整型的时间戳输出
clicks.map(new RichMapFunction<Event, Long>() {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println(" 索 引 为 " +getRuntimeContext().getIndexOfThisSubtask() + " 的任务开始");
}
@Override
public Long map(Event value) throws Exception {
return value.timestamp;
}
@Override
public void close() throws Exception {
super.close();
System.out.println(" 索 引 为getRuntimeContext().getIndexOfThisSubtask() + " 的任务结 束"); }
});
7、物理分区
1. 随机分区(shuffle)

stream.shuffle().print("shuffle").setParallelism(4);
2. 轮询分区(Round-Robin)

// 经轮询重分区后打印输出,并行度为4
stream.rebalance().print("rebalance").setParallelism(4);
3. 重缩放分区(rescale)

重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin 算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中,如图 5-11 所示。也就是说,“发牌人”如果有多个,那么 rebalance 的方式是每个发牌人都面向所有人发牌;而 rescale 的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
由于 rebalance 是所有分区数据的“重新平衡”,当 TaskManager 数据量较多时,这种跨节点的网络传输必然影响效率;而如果我们配置的 task slot 数量合适,用 rescale 的方式进行“局部重缩放”,就可以让数据只在当前 TaskManager 的多个 slot 之间重新分配,从而避免了网络传输带来的损耗。
4. 广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
**5.**全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
6. 自定义分区(Custom)
// 将自然数按照奇偶分区
env.fromElements(1, 2, 3, 4, 5, 6, 7, 8)
.partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer key, int numPartitions) {
return key % 2;
}
}, new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer value) throws Exception {
return value;
}
}) s
.print().setParallelism(2);
8、窗口的分类
- 按照驱动类型分类
(1)时间窗口(Time Window)
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。
(2)计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。这相当于座位有限、“人满就发车”,是否发车与时间无关。每个窗口截取数据的个数,就是窗口的大小。
- 按照窗口分配数据的规则分类
(1)滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mn1NvFUZ-1654002484236)(.\大数据面试笔记\image-20220501151820418.png)]](https://img-blog.csdnimg.cn/a35ba227e1d540a3abf828fe3163a28d.png)
(2)滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。所以定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个“滑动步长”(window slide),它其实就代表了窗口计算的频率。所以,滑动窗口其实是固定大小窗口的更广义的一种形式;换句话说,滚动窗口也可以看作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide)

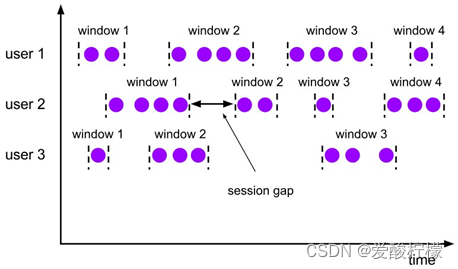
(3)会话窗口(Session Windows)
简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。
考虑到事件时间语义下的乱序流,这里又会有一些麻烦。相邻两个数据的时间间隔 gap 大于指定的 size,我们认为它们属于两个会话窗口,前一个窗口就关闭;可在数据乱序的情况下,可能会有迟到数据,它的时间戳刚好是在之前的两个数据之间的。这样一来,之前我们判断的间隔中就不是“一直没有数据”,而缩小后的间隔有可能会比 size 还要小——这代表三个数据本来应该属于同一个会话窗口。
所以在 Flink 底层,对会话窗口的处理会比较特殊:每来一个新的数据,都会创建一个新的会话窗口;然后判断已有窗口之间的距离,如果小于给定的 size,就对它们进行合并(merge)操作。在 Window 算子中,对会话窗口会有单独的处理逻辑。
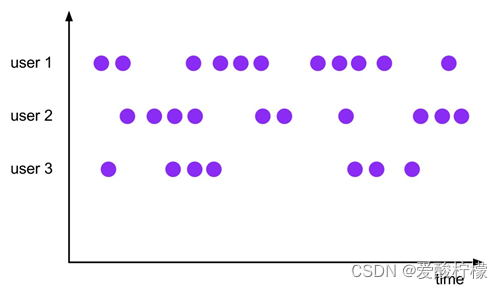
(4)全局窗口(Global Windows)
还有一类比较通用的窗口,就是“全局窗口”。这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中;说直白一点,就跟没分窗口一样。可以看到,全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink 中的计数窗口(Count Window),底层就是用全局窗口实现的。
9、窗口函数
-
增量聚合函数(incremental aggregation functions)
(1)归约函数(ReduceFunction)
最基本的聚合方式就是归约(reduce)。我们在基本转换的聚合算子中介绍过 reduce 的用法,窗口的归约聚合也非常类似,就是将窗口中收集到的数据两两进行归约。
stream..keyBy(r -> r.f0)
// 设置滚动事件时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
// 定义累加规则,窗口闭合时,向下游发送累加结果
return Tuple2.of(value1.f0, value1.f1 + value2.f1); }
})
(2)聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。如果取消类型一致的限制,让输入数据、中间状态、输出结果三者类型都可以不同,不就可以一步直接搞定了吗?Flink 的 Window API 中的 aggregate 就提供了这样的操作。
AggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。
stream.keyBy(data -> true)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(2)))
.aggregate(new AvgPv())
.print();
public static class AvgPv implements AggregateFunction<Event, Tuple2<HashSet<String>, Long>, Double> {
@Override
public Tuple2<HashSet<String>, Long> createAccumulator() {
// 创建累加器
return Tuple2.of(new HashSet<String>(), 0L);
}
@Override
public Tuple2<HashSet<String>, Long> add(Event value,
Tuple2<HashSet<String>, Long> accumulator) {
// 属于本窗口的数据来一条累加一次,并返回累加器
accumulator.f0.add(value.user);
return Tuple2.of(accumulator.f0, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<HashSet<String>, Long> accumulator) {
// 窗口闭合时,增量聚合结束,将计算结果发送到下游
return (double) accumulator.f1 / accumulator.f0.size();
}
@Override
public Tuple2<HashSet<String>, Long> merge(
Tuple2<HashSet<String>, Long> a, Tuple2<HashSet<String>, Long> b) {
return null;
}
}
另外,Flink 也为窗口的聚合提供了一系列预定义的简单聚合方法,可以直接基于 WindowedStream 调用。主要包括.sum()/max()/maxBy()/min()/minBy(),与 KeyedStream 的简单聚合非常相似。它们的底层,其实都是通过 AggregateFunction 来实现的。
- 全窗口函数(full window functions)
(1)窗口函数(WindowFunction)
WindowFunction 字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于 WindowedStream 调用.apply()方法,传入一个 WindowFunction 的实现类。这个类中可以获取到包含窗口所有数据的可迭代集合(Iterable),还可以拿到窗口(Window)本身的信息。
stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function,
Serializable {
void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out)throws Exception;
}
(2)处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction 还可以获取到一个 “上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。
// 将数据全部发往同一分区,按窗口统计UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
/* 自定义窗口处理函数 */
public static class UvCountByWindow extends ProcessWindowFunction<Event, String, Boolean, TimeWindow>{
@Override
public void process( Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out ) throws Exception
{
HashSet<String> userSet = new HashSet<>();
/* 遍历所有数据,放到Set里去重 */
for ( Event event : elements )
{
userSet.add( event.user );
}
/* 结合窗口信息,包装输出内容 */
Long start = context.window().getStart(); Long end = context.window().getEnd();
out.collect( "窗口: " + new Timestamp( start ) + " ~ " + new Timestamp( end )
+ " 的独立访客数量是:" + userSet.size() );
}
}
- 增量聚合和全窗口函数的结合使用
stream.keyBy(data -> data.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
// 同时传入增量聚合函数和全窗口函数
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
.print();
/* 自定义窗口处理函数,只需要包装窗口信息 */
public static class UrlViewCountResult extends ProcessWindowFunction<Long,
UrlViewCount, String, TimeWindow> {
@Override
public void process( String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out ) throws Exception
{
/* 结合窗口信息,包装输出内容 */
Long start = context.window().getStart();
Long end = context.window().getEnd();
/* 迭代器中只有一个元素,就是增量聚合函数的计算结果 */
out.collect( new UrlViewCount( url, elements.iterator().next(), start, end ) );
}
}
10、迟到数据的处理
1、 设置水位线延迟时间
那一般情况就不应该把它的延迟设置得太大,否则流处理的实时性就会大大降低。因为水位线的延迟主要是用来对付分布式网络传输导致的数据乱序,而网络传输的乱序程度一般并不会很大,大多集中在几毫秒至几百毫秒。所以实际应用中,我们往往会给水位线设置一个“能够处理大多数乱序数据的小延迟”,视需求一般设在毫秒~秒级。
2、允许窗口处理迟到数据
Flink 的窗口也是可以设置延迟时间,允许继续处理迟到数据的。
这种情况下,由于大部分乱序数据已经被水位线的延迟等到了,所以往往迟到的数据不会太多。这样,我们会在水位线到达窗口结束时间时,先快速地输出一个近似正确的计算结果;然后保持窗口继续等到延迟数据,每来一条数据,窗口就会再次计算,并将更新后的结果输出。
3、将迟到数据放入窗口侧输出流
用窗口的侧输出流来收集关窗以后的迟到数据。这种方式是最后 “兜底”的方法,只能保证数据不丢失;因为窗口已经真正关闭,所以是无法基于之前窗口的结果直接做更新的。我们只能将之前的窗口计算结果保存下来,然后获取侧输出流中的迟到数据,判断数据所属的窗口,手动对结果进行合并更新。尽管有些烦琐,实时性也不够强,但能够保证最终结果一定是正确的。
11、双流联结
1、窗口联结(Window Join)
窗口联结在代码中的实现,首先需要调用 DataStream 的.join()方法来合并两条流,得到一个 JoinedStreams;接着通过.where()和.equalTo()方法指定两条流中联结的 key;然后通过.window()开窗口,并调用.apply()传入联结窗口函数进行处理计算。通用调用形式如下:
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
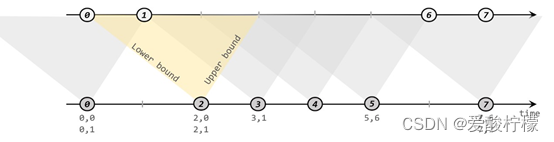
2、间隔联结(Interval Join)
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作 A)中的任意一个数据元素 a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以 a 的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫 B)中的数据元素 b,如果它的时间戳落在了这个区间范围内,a 和 b 就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
间隔联结目前只支持事件时间语义。
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) { out.collect(left + "," + right);
}
});
3、窗口同组联结(Window CoGroup)
除窗口联结和间隔联结之外,Flink 还提供了一个“窗口同组联结”(window coGroup)操作。它的用法跟 window join 非常类似,也是将两条流合并之后开窗处理匹配的元素,调用时只需要将.join()换为.coGroup()就可以了。
内部的.coGroup()方法,有些类似于 FlatJoinFunction 中.join()的形式,同样有三个参数,分别代表两条流中的数据以及用于输出的收集器(Collector)。不同的是,这里的前两个参数不再是单独的每一组“配对”数据了,而是传入了可遍历的数据集合。也就是说,现在不会再去计算窗口中两条流数据集的笛卡尔积,而是直接把收集到的所有数据一次性传入,至于要怎样配对完全是自定义的。
所以能够看出,coGroup 操作比窗口的 join 更加通用,不仅可以实现类似 SQL 中的“内连接”(inner join),也可以实现左外连接(left outer join)、右外连接(right outer join)和全外连接(full outer join)。事实上,窗口 join 的底层,也是通过 coGroup 来实现的。
stream1
.coGroup(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, Long>> iter1, Iterable<Tuple2<String, Long>> iter2, Collector<String> collector) throws Exception { collector.collect(iter1 + "=>" + iter2);
}
})
12、联合(union)和连接(connect)
最基本的合流方式是联合(union)和连接(connect),两者的主要区别在于 union 可以对多条流进行合并,数据类型必须一致;而 connect 只能连接两条流,数据类型可以不同。事实上 connect 提供了最底层的处理函数(process function)接口,可以通过状态和定时器实现任意自定义的合流操作,所以是最为通用的合流方式。
13、Flink中的状态
1、托管状态和原始状态
托管状态是由 Flink 的运行时(Runtime)来托管的;在配置容错机制后,状态会自动持久化保存,并在发生故障时自动恢复。
原始状态就全部需要自定义了。Flink 不会对状态进行任何自动操作,也不知道状态的具体数据类型,只会把它当作最原始的字节(Byte)数组来存储。我们需要花费大量的精力来处理状态的管理和维护。
2、算子状态(Operator State)和按键分区状态(Keyed State)
(1)算子状态(Operator State)
状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个“分区”,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的。

算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState 和 BroadcastState。
①列表状态(ListState)
当算子并行度进行缩放调整时,算子的列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),与之前介绍的 rebanlance 数据传输方式类似,是通过逐一“发牌”的方式将状态项平均分配的。这种方式也叫作“平均分割重组”(even-split redistribution)。
②联合列表状态(UnionListState)
UnionListState 的重点就在于“联合”(union)。在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。这样,并行度缩放之后的并行子任务就获取到了联合后完整的“大列表”,可以自行选择要使用的状态项和要丢弃的状态项。
③广播状态(BroadcastState)
因为广播状态在每个并行子任务上的实例都一样,所以在并行度调整的时候就比较简单,只要复制一份到新的并行任务就可以实现扩展;而对于并行度缩小的情况,可以将多余的并行子任务连同状态直接砍掉——因为状态都是复制出来的,并不会丢失。
在底层,广播状态是以类似映射结构(map)的键值对(key-value)来保存的,必须基于一个“广播流”(BroadcastStream)来创建。
(2)按键分区状态(Keyed State)
状态是根据输入流中定义的键(key)来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,也就 keyBy 之后才可以使用。
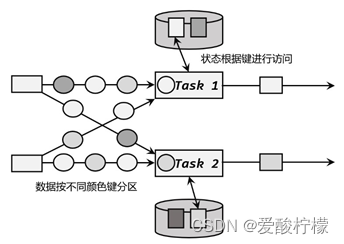
Flink 也提供了值状态(ValueState)、列表状态(ListState)、映射状态(MapState)、聚合状态(AggregateState)、规约状态等多种结构,内部支持各种数据类型。
在富函数中,调用.getRuntimeContext()方法获取到运行时上下文之后,RuntimeContext 有以下几个获取状态的方法:
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<>(
"my state", // 状态名称
Types.LONG // 状态类型
);
ValueState<T> getState(ValueStateDescriptor<T>)
MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
ListState<T> getListState(ListStateDescriptor<T>)
ReducingState<T> getReducingState(ReducingStateDescriptor<T>)
AggregatingState<IN, OUT> getAggregatingState(AggregatingStateDescriptor<IN, ACC, OUT>)
①值状态(ValueState)
我们可以在代码中读写值状态,实现对于状态的访问和更新。
⚫ T value():获取当前状态的值;
⚫ update(T value):对状态进行更新,传入的参数 value 就是要覆写的状态值。
② 列表状态(ListState)
⚫ Iterable get():获取当前的列表状态,返回的是一个可迭代类型 Iterable;
⚫ update(List values):传入一个列表 values,直接对状态进行覆盖;
⚫ add(T value):在状态列表中添加一个元素 value;
⚫ addAll(List values):向列表中添加多个元素,以列表 values 形式传入。
③映射状态(MapState)
⚫ UV get(UK key):传入一个 key 作为参数,查询对应的 value 值;
⚫ put(UK key, UV value):传入一个键值对,更新 key 对应的 value 值;
⚫ putAll(Map<UK, UV> map):将传入的映射 map 中所有的键值对,全部添加到映射状态中;
⚫ remove(UK key):将指定 key 对应的键值对删除;
⚫ boolean contains(UK key):判断是否存在指定的 key,返回一个 boolean 值。另外,MapState 也提供了获取整个映射相关信息的方法:
⚫ Iterable<Map.Entry<UK, UV>> entries():获取映射状态中所有的键值对;
⚫ Iterable keys():获取映射状态中所有的键(key),返回一个可迭代 Iterable 类型;
⚫ Iterable values():获取映射状态中所有的值(value),返回一个可迭代 Iterable 类型;
⚫boolean isEmpty():判断映射是否为空,返回一个 boolean 值。
④归约状态(ReducingState)
⑤聚合状态(AggregatingState)
调用.add()方法添加元素时,会直接使用指定的 AggregateFunction 进行聚合并更新状态。
14、状态后端
在 Flink 中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端(state backend)。状态后端主要负责两件事:一是本地的状态管理,二是将检查点(checkpoint)写入远程的持久化存储。
(1)哈希表状态后端(HashMapStateBackend)
HashMapStateBackend 是将本地状态全部放入内存的,这样可以获得最快的读写速度,使计算性能达到最佳;代价则是内存的占用。它适用于具有大状态、长窗口、大键值状态的作业,对所有高可用性设置也是有效的。
(2)内嵌 RocksDB 状态后端(EmbeddedRocksDBStateBackend)
RocksDB 是一种内嵌的 key-value 存储介质,可以把数据持久化到本地硬盘。配置 EmbeddedRocksDBStateBackend 后,会将处理中的数据全部放入 RocksDB 数据库中,RocksDB 默认存储在 TaskManager 的本地数据目录里。
由于它会把状态数据落盘,而且支持增量化的检查点,所以在状态非常大、窗口非常长、键/值状态很大的应用场景中是一个好选择,同样对所有高可用性设置有效。
保存点和检查点:
从名称就可以看出,这也是一个存盘的备份,它的原理和算法与检查点完全相同,只是多了一些额外的元数据。事实上,保存点就是通过检查点的机制来创建流式作业状态的一致性镜像(consistent image)的。
保存点与检查点最大的区别,就是触发的时机。检查点是由 Flink 自动管理的,定期创建,发生故障之后自动读取进行恢复,这是一个“自动存盘”的功能;而保存点不会自动创建,必须由用户明确地手动触发保存操作,所以就是“手动存盘”。因此两者尽管原理一致,但用途就有所差别了:检查点主要用来做故障恢复,是容错机制的核心;保存点则更加灵活,可以用来做有计划的手动备份和恢复。
15、端到端精确一次
1、输入端保证
想要在故障恢复后不丢数据,外部数据源就必须拥有重放数据的能力。常见的做法就是对数据进行持久化保存,并且可以重设数据的读取位置。一个最经典的应用就是 Kafka。在 Flink 的 Source 任务中将数据读取的偏移量保存为状态,这样就可以在故障恢复时从检查点中读取出来,对数据源重置偏移量,重新获取数据。
2、 输出端保证
(1)幂等(idempotent)写入
所谓“幂等”操作,就是说一个操作可以重复执行很多次,但只导致一次结果更改。也就是说,后面再重复执行就不会对结果起作用了。
需要注意,对于幂等写入,遇到故障进行恢复时,有可能会出现短暂的不一致。因为保存点完成之后到发生故障之间的数据,其实已经写入了一遍,回滚的时候并不能消除它们。如果有一个外部应用读取写入的数据,可能会看到奇怪的现象:短时间内,结果会突然“跳回”到之前的某个值,然后“重播”一段之前的数据。不过当数据的重放逐渐超过发生故障的点的时候,最终的结果还是一致的。
(2)事务(transactional)写入
当 Sink 任务遇到 barrier 时,开始保存状态的同时就开启一个事务,接下来所有数据的写入都在这个事务中;待到当前检查点保存完毕时,将事务提交,所有写入的数据就真正可用了。如果中间过程出现故障,状态会回退到上一个检查点,而当前事务没有正常关闭(因为当前检查点没有保存完),所以也会回滚,写入到外部的数据就被撤销了。
有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
1)预写日志(write-ahead-log,WAL)
简单的方式。具体步骤是:
①先把结果数据作为日志(log)状态保存起来
②进行检查点保存时,也会将这些结果数据一并做持久化存储
③在收到检查点完成的通知时,将所有结果一次性写入外部系统。
我们会发现,这种方式类似于检查点完成时做一个批处理,一次性的写入会带来一些性能上的问题;而优点就是比较简单,由于数据提前在状态后端中做了缓存,所以无论什么外部存储系统,理论上都能用这种方式一批搞定。在 Flink 中 DataStream API 提供了一个模板类
GenericWriteAheadSink,用来实现这种事务型的写入方式。
2)两阶段提交(two-phase-commit,2PC)
顾名思义,它的想法是分成两个阶段:先做“预提交”,等检查点完成之后再正式提交。这种提交方式是真正基于事务的,它需要外部系统提供事务支持。
具体的实现步骤为:
①当第一条数据到来时,或者收到检查点的分界线时,Sink 任务都会启动一个事务。
②接下来接收到的所有数据,都通过这个事务写入外部系统;这时由于事务没有提交,所以数据尽管写入了外部系统,但是不可用,是“预提交”的状态。
③当 Sink 任务收到 JobManager 发来检查点完成的通知时,正式提交事务,写入的结果就真正可用了。
当中间发生故障时,当前未提交的事务就会回滚,于是所有写入外部系统的数据也就实现了撤回。这种两阶段提交(2PC)的方式充分利用了 Flink 现有的检查点机制:分界线的到来,就标志着开始一个新事务;而收到来自 JobManager 的 checkpoint 成功的消息,就是提交事务的指令。
Flink 与 Kafka 连接的两阶段提交
Flink 与 Kafka 连接的两阶段提交,离不开检查点的配合,这个过程需要 JobManager 协调各个 TaskManager 进行状态快照,而检查点具体存储位置则是由状态后端(State Backend)来配置管理的。
实现端到端 exactly-once 的具体过程可以分解如下:
①启动检查点保存
检查点保存的启动,标志着我们进入了两阶段提交协议的“预提交”阶段。当然,现在还没有具体提交的数据。
②算子任务对状态做快照
分界线(barrier)会在算子间传递下去。每个算子收到 barrier 时,会将当前的状态做个快照,保存到状态后端。
③Sink 任务开启事务,进行预提交
分界线(barrier)终于传到了 Sink 任务,这时 Sink 任务会开启一个事务。接下来到来的所有数据,Sink 任务都会通过这个事务来写入 Kafka。对于 Kafka 而言,提交的数据会被标记为“未确认”(uncommitted)。这个过程就是所谓的“预提交”(pre-commit)。
④检查点保存完成,提交事务
当所有算子的快照都完成,也就是这次的检查点保存最终完成时,JobManager 会向所有任务发确认通知,告诉大家当前检查点已成功保存。当 Sink 任务收到确认通知后,就会正式提交之前的事务,把之前“未确认”的数据标为“已确认”,接下来就可以正常消费了。
16、Table API中的窗口
窗口表值函数(Windowing TVFs,新版本)
⚫ 滚动窗口(Tumbling Windows);
⚫ 滑动窗口(Hop Windows,跳跃窗口);
⚫ 累积窗口(Cumulate Windows);
⚫ 会话窗口(Session Windows,目前尚未完全支持)。
(1)滚动窗口(TUMBLE)
在 SQL 中通过调用 TUMBLE()函数就可以声明一个滚动窗口,只有一个核心参数就是窗口大小(size)。在 SQL 中不考虑计数窗口,所以滚动窗口就是滚动时间窗口,参数中还需要将当前的时间属性字段传入;另外,窗口 TVF 本质上是表函数,可以对表进行扩展,所以还应该把当前查询的表作为参数整体传入。具体声明如下:
TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR)
(2) 滑动窗口(HOP)
滑动窗口的使用与滚动窗口类似,可以通过设置滑动步长来控制统计输出的频率。在 SQL 中通过调用 HOP()来声明滑动窗口;除了也要传入表名、时间属性外,还需要传入窗口大小(size)和滑动步长(slide)两个参数。
HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '5' MINUTES, INTERVAL '1' HOURS));
(3)累积窗口(CUMULATE)滚动窗口和滑动窗口
可以用来计算大多数周期性的统计指标。不过在实际应用中还会遇到这样一类需求:我们的统计周期可能较长,因此希望中间每隔一段时间就输出一次当前的统计值;与滑动窗口不同的是,在一个统计周期内,我们会多次输出统计值,它们应该是不断叠加累积的。
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))
17.CEP流程
CEP 的主要处理流程分为三步,对应到 Pattern API 中就是:
(1) 定义一个模式(Pattern);
(2) 将Pattern应用到DataStream上,检测满足规则的复杂事件,得到一个PatternStream;
(3) 对 PatternStream 进行转换处理,将检测到的复杂事件提取出来,包装成报警信息输出。
18、Flink 和 Spark Streaming的区别
1)架构模型
Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,
Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
2)任务调度
Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。
Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
flink一切都是流;
Spark Streaming相当于把流处理转换为批处理,spark Streaming 是伪实时处理,处理延迟一定是秒级别的,不能再低了;
所以对于延迟性非常高的场景必须要用Flink。
3)时间机制Spark Streaming 支持的时间机制有限,只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
前查询的表作为参数整体传入。具体声明如下:
TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR)
(2) 滑动窗口(HOP)
滑动窗口的使用与滚动窗口类似,可以通过设置滑动步长来控制统计输出的频率。在 SQL 中通过调用 HOP()来声明滑动窗口;除了也要传入表名、时间属性外,还需要传入窗口大小(size)和滑动步长(slide)两个参数。
HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '5' MINUTES, INTERVAL '1' HOURS));
(3)累积窗口(CUMULATE)滚动窗口和滑动窗口
可以用来计算大多数周期性的统计指标。不过在实际应用中还会遇到这样一类需求:我们的统计周期可能较长,因此希望中间每隔一段时间就输出一次当前的统计值;与滑动窗口不同的是,在一个统计周期内,我们会多次输出统计值,它们应该是不断叠加累积的。
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))
17.CEP流程
CEP 的主要处理流程分为三步,对应到 Pattern API 中就是:
(1) 定义一个模式(Pattern);
(2) 将Pattern应用到DataStream上,检测满足规则的复杂事件,得到一个PatternStream;
(3) 对 PatternStream 进行转换处理,将检测到的复杂事件提取出来,包装成报警信息输出。
18、Flink 和 Spark Streaming的区别
1)架构模型
Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,
Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
2)任务调度
Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。
Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
flink一切都是流;
Spark Streaming相当于把流处理转换为批处理,spark Streaming 是伪实时处理,处理延迟一定是秒级别的,不能再低了;
所以对于延迟性非常高的场景必须要用Flink。
3)时间机制Spark Streaming 支持的时间机制有限,只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
4)容错机制对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰好一次处理语义。Flink 则使用两阶段提交协议来解决这个问题。














 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









