







一、Set接口
Set集合代表一个无序集合,集合中的元素不可以重复,访问集合中的元素只能根据元素本身来访问。
即Set集合无索引、不可以重复(元素唯一)、无序(存取顺序不一致)。
实现Set接口的集合主要有:HashSet、LinkedHashSet、TreeSet。
HashSet类
HashSet是一种没有重复元素的无序集合,HashSet继承于AbstractSet,实现接口Set,内部使用HashMap来存储数据,数据存储在HashMap的key中,value只是同一个默认值,所以HashSet存储的值是不能重复的。
1、HashSet类的原理
(1)底层是哈希表(散列/hash)算法的封装。
(2)HashSet是线程不安全的。如果需要多线程访问,文档推荐如下:

截取的一段源码:

2、HashSet类的常用方法(父类重写了toString()方法)具体查看API
测试demo
public static void main(String[] args) {
Set<String> set1 = new HashSet<>();
set1.add("d");
set1.add("b");
set1.add("c");
set1.add("c");
set1.add("a");
System.out.println(set1.size());// 4
System.out.println(set1);// [a, b, c, d]
set1.remove("b");
System.out.println(set1);// [a, c, d]
// 遍历删除
Iterator<String> it = set1.iterator();
while (it.hasNext()) {
Object ele = it.next();
if ("c".equals(ele)) {
it.remove();
}
}
System.out.println(set1); // [a, d]
}3、HashSet类中元素不重复原理
由源码分析中add()方法可知,HashSet集合中添加元素,实际是作为HashMap的Key存储,
由于 HashMap 的 put() 方法添加 key-value 时,当新放入 HashMap 的 Entry 中 key 与集合中原有 Entry 的 key 相同(hashCode()返回值相等,通过 equals 比较也返回 true),新添加的 Entry 的 value 会将覆盖原来 Entry 的 value,但 key 不会有任何改变,因此如果向 HashSet 中添加一个已经存在的元素时,新添加的集合元素将不会被放入 HashMap中,原来的元素也不会有任何改变,这也就满足了 Set 中元素不重复的特性。
如果添加元素在 HashSet 中不存在的,则返回 true;如果添加的元素已经存在,返回 false。其原因在于 HashMap 的 put 方法。该方法在添加 key 不重复的键值对的时候,会返回 null。
4、HashSet中判断两个元素对象是否相同:
当添加新的对象到HashSet集合中时,二者缺一不可:
1)先判断该对象与集合对象中的hashCode值是否相同,如果不相同,则添加,否则,进行步骤2
2)再继续判断该对象与集合对象中的equals进行比较,如果返回false,则添加,否则,表示重复,不添加。
5、对象的hashCode和equals方法的重要性:
每一个存储到hash表中的对象,都得提供hashCode和equals方法,用来判断是否是同一个对象。存储在哈希表中的对象,都应该覆盖equals方法和hashCode方法,并且保证equals相等的时候,hashCode也应该相等。
public class SetDemo {
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
set.add(new Student("赵云",1,17));
set.add(new Student("赵云2",3,18));
set.add(new Student("赵云3",1,19));
System.out.println(set.size());// 2 序号重复就判断为同一个人
System.out.println(set);
// [Student{name='赵云', studentNumber=1, age=17}, Student{name='赵云2', studentNumber=3, age=18}]
}
}
public class Student{
private String name;
private int studentNumber;
private int age;
public Student(String name, int studentNumber, int age) {
this.name = name;
this.studentNumber = studentNumber;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", studentNumber=" + studentNumber +
", age=" + age +
'}';
}
//判断学号一样的就为同一个对象 (还可以同时判断学号和名字或者年龄)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return studentNumber == student.studentNumber;
}
@Override
public int hashCode() {
return Objects.hash(studentNumber);
}
}LinkedHashSet类
LinkedHashSet类继承于 HashSet类
1、LinkedHashSet类的原理
(1)底层是哈希表和链表算法。
哈希表:来保证唯一性,.此时就是HashSet,在哈希表中元素没有先后顺序.
链表:来记录元素的先后添加顺序.
(2)LinkedHashSet是线程不安全的。如果需要多线程访问,参考文档
截取的一段源码:

即 LinkedHashSet 底层是依靠 LinkedHashMap 来实现数据存取的,而 LinkedHashMap 继承于 HashMap,在内部自己维护了一条双向链表用于保存元素的插入顺序,因此使得 LinkedHashSet 也具有了存取有序,元素唯一的特点。LinkedHashSet类的常用方法使用同HashSet类一样。测试demo
public static void main(String[] args) {
Set<String> set1 = new LinkedHashSet<>();
set1.add("d");
set1.add("b");
set1.add("c");
set1.add("c");
set1.add("a");
System.out.println(set1.size());// 4
System.out.println(set1);// [d, b, c, a] 记录插入顺序
set1.remove("b");
System.out.println(set1);// [d, c, a]
// 遍历删除
Iterator<String> it = set1.iterator();
while (it.hasNext()) {
Object ele = it.next();
if ("c".equals(ele)) {
it.remove();
}
}
System.out.println(set1); // [d, a]
}TreeSet类
TreeSet是基于TreeMap实现的一个保证元素有序的集合,所以弄清楚TreeMap是关键。
注意:必须保证TreeSet集合中的元素对象是相同的数据类型,否则报错,
1、TreeSet类的原理
(1)底层是采用红黑树算法,会对存储的元素默认使用自然排序(从小到大).
(2)TreeSet是线程不安全的。如果需要多线程访问,参考文档
截取的一段源码:

2、TreeSet类的常用方法,具体查看api
测试demo
public static void main(String[] args) {
TreeSet<String> s = new TreeSet<>();
s.add("c");
s.add("f");
s.add("6");
s.add("9");
System.out.println(s); // [6, 9, c, f]
System.out.println(s.first()); // 6
// 遍历删除
Iterator<String> it = s.iterator();
while (it.hasNext()) {
Object ele = it.next();
if ("c".equals(ele)) {
it.remove();
}
}
System.out.println(s); // [6, 9, f]
}3、TreeSet的排序规则
1)自然排序(从小到大):
TreeSet调用集合元素的compareTo方法来比较元素的大小关系,然后将集合元素按照升序排列(从小到大).
注意:要求TreeSet集合中对象元素得实现 java.util.Comparable接口(可比较的)
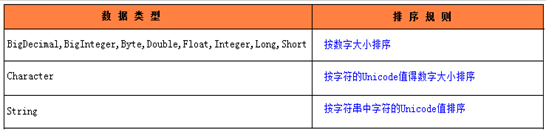
覆盖 public int compareTo(Object o)方法,在该方法中编写比较规则(当前对象(this)和参数对象o做比较)。
在TreeSet的自然排序中,认为如果两个对象做比较的compareTo方法返回的是0,则认为是同一个对象.
public class ListDemo {
public static void main(String[] args) {
Set<Student> set = new TreeSet<>();
set.add(new Student("赵云",1,17));
set.add(new Student("赵云2",3,19));
set.add(new Student("赵云3",5,18));
set.add(new Student("赵云4",6,18));
System.out.println(set);
//[Student{name='赵云', studentNumber=1, age=17}, Student{name='赵云3', studentNumber=5, age=18}, Student{name='赵云2', studentNumber=3, age=19}]
}
}
public class Student implements Comparable<Student>{
private String name;
private int studentNumber;
private int age;
public Student(String name, int studentNumber, int age) {
this.name = name;
this.studentNumber = studentNumber;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", studentNumber=" + studentNumber +
", age=" + age +
'}';
}
// 自定义的编写比较规则 (按照年龄来排序) 自然排序
@Override
public int compareTo(Student o) {
if (this.age > o.age) {
return 1;
} else if (this.age < o.age) {
return -1;
} else {
return 0;
}
}
}2)定制排序(从大到小,按照名字的长短来排序):
在TreeSet构造器中传递 java.lang.Comparator对象,并覆盖 public int compare(Object o1, Object o2)再编写比较规则。
public class ListDemo {
public static void main(String[] args) {
Set<Student> set = new TreeSet<>(new Comparator<Student>() {
// 自定义编写 定制排序的规则.名字长度升序比较器
@Override
public int compare(Student o1, Student o2) {
if (o1.getName().length() > o2.getName().length()) {
return 1;
} else if (o1.getName().length() < o2.getName().length()) {
return -1;
} else {
if (o1.getAge() < o2.getAge() ) { // 当名字长度相等的时候 按年龄降序来排序
return 1;
} else if (o1.getAge() > o2.getAge() ) {
return -1;
} else {
return 0;
}
}
}
});
set.add(new Student("赵云",1,17));
set.add(new Student("赵云2",3,19));
set.add(new Student("赵云3",5,18));
set.add(new Student("赵云4",6,18));
System.out.println(set);
//[Student{name='赵云', studentNumber=1, age=17}, Student{name='赵云2', studentNumber=3, age=19}, Student{name='赵云3', studentNumber=5, age=18}]
}
}
class Student{
private String name;
private int studentNumber;
private int age;
public Student(String name, int studentNumber, int age) {
this.name = name;
this.studentNumber = studentNumber;
this.age = age;
}
// get/set/toString方法
}3)对于TreeSet集合来说,要么使用自然排序,要么使用定制排序.
判断两个对象是否相等的规则:
自然排序: compareTo方法返回0;
定制排序: compare方法返回0;
二、Map接口
Map接口采用键值对Map<K,V>的存储方式,保存具有映射关系的数据,因此,Map集合里保存两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value,key和value可以是任意引用类型的数据。key值不允许重复。如果添加key-value对时Map中已经有重复的key,则新添加的value会覆盖该key原来对应的value。
Map的常用实现类:
1)HashMap类
采用哈希表算法,此时Map中的key不会保证添加的先后顺序,key也不允许重复. null 可作为键和值
key判断重复的标准是: key1和key2是否equals为true,并且hashCode相等.
2)TreeMap类
采用红黑树算法,此时Map中的key会按照自然顺序或定制排序进行排序,,key也不允许重复. null 不可作为键,可作为值
key判断重复的标准是:compareTo/compare的返回值是否为0.
3)LinkedHashMap类
采用链表和哈希表算法,此时Map中的key会保证先后添加的顺序,key不允许重复.
key判断重复的标准和HashMap中的key的标准相同.
4)Hashtable类
采用哈希表算法,是HashMap的前身(古老的集合)。所有的方法都使用synchronized修饰符,线程安全的,但是性能相对HashMap较低. null 不可作为键和值
5)Properties类
Hashtable的子类,此时要求key和value都是String类型,用来加载资源文件
一般的,我们定义Map时,key都使用不可变的类(String),把key作为value的唯一名称.HashMap和TreeMap以及LinkedHashMap都是线程不安全的,但是性能较高。如果需要多线程访问,文档推荐如下:
解决方案: Map m = Collections.synchronizedMap(Map对象);
Map常见方法,具体查看API
-
-
booleancontainsKey(Object key)如果此映射包含指定键的映射,则返回 true 。
booleancontainsValue(Object value)如果此地图将一个或多个键映射到指定的值,则返回 true 。
Set<Map.Entry<K,V>>entrySet()返回此地图中包含的映射的
Set视图。Vget(Object key)返回到指定键所映射的值,或
null如果此映射包含该键的映射。booleanisEmpty()如果此地图不包含键值映射,则返回 true 。
default voidforEach(BiConsumer<? super K,? super V> action)对此映射中的每个条目执行给定的操作,直到所有条目都被处理或操作引发异常。
Set<K>keySet()返回此地图中包含的键的
Set视图。Vput(K key, V value)将指定的值与该映射中的指定键相关联(可选操作)。
Vremove(Object key)如果存在(从可选的操作),从该地图中删除一个键的映射。
intsize()返回此地图中键值映射的数量。
Collection<V>values()返回此地图中包含的值的
Collection视图。
-
测试demo
public static void main(String[] args) {
Map<String, Object> map = new HashMap<>();
map.put("key1", "v1");
map.put("key2", "v2");
map.put("key3", "v3");
map.put("key3", "v33"); //覆盖上面,即修改key值对应的value
map.put("key4", "v4");
System.out.println(map);
//map.remove("key3");
//System.out.println(map);
// map 不是集合,所以不能使用foreach
// 获取map中的所有key
Set<String> keys = map.keySet(); //类似于一个set
for (String key : keys) {
System.out.println(key + "-" + map.get(key)); // 可以根据key的值,获取相对应的value值
}
// // 获取map中的所有value
Collection<Object> values = map.values(); // 类似于一个list
for (Object value : values) {
System.out.println(value);
}
// 获取map中的键值对key-value 推荐使用
// keySet 其实是遍历了 2 次,一次是转为 Iterator 对象,另一次是从 hashMap 中取出key 所对应的 value。
//而entrySet 只是遍历了一次就把 key 和 value 都放到了 entry 中,效率更高。
Set<Map.Entry<String , Object>> entrys = map.entrySet();
for (Map.Entry<String, Object> entry : entrys) { //entry 里面有获取key和value的方法
String key = entry.getKey();
Object value = entry.getValue();
System.out.println(key + "-" +value);
}
}JDK1.8 的话,可使用Map.forEach(...)遍历
// JDK8 可使用 Map.forEach 方法。
// 方式一
map.forEach(new BiConsumer() {
@Override
public void accept(Object key, Object value) {
System.out.println(key + ":" + value);
}
});
// 方式二
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
});1、Map边遍历边删除
public static void main(String[] args) {
Map<String, Object> map = new HashMap<>();
map.put("key1", "v1");
map.put("key2", "v2");
map.put("key3", "v3");
map.put("key3", "v33"); //覆盖上面,即修改key值对应的value
map.put("key4", "v4");
System.out.println(map);
//map.remove("key3");
//System.out.println(map);
// 边遍历边删除,两种方式
//Set<Map.Entry<String , Object>> entrys2 = map.entrySet();
/* Set<String> keys2 = map.keySet();
for(Iterator it2 = keys2.iterator();it2.hasNext();){
String ele = String.valueOf(it2.next());
if("key3".equals(ele)){
it2.remove(); // 使用Iterator接口中的remove() 方法。
}
} */
Set<Map.Entry<String , Object>> entrys2 = map.entrySet();
Iterator<Map.Entry<String, Object>> iterator = entrys2.iterator();
while (iterator.hasNext()){
Map.Entry<String, Object> entry = iterator.next();
if("key4".equals(entry.getKey())){
iterator.remove(); // 使用Iterator接口中的remove() 方法。
}
}
System.out.println(map);
}2、List、Set和Map之间的选用:
选用使用哪个取决于每一种容器的存储特点以及当前业务的需求:
List: 单一元素集合。允许元素重复/记录元素的添加顺序.
Set:单一元素集合。不允许元素重复/不记录元素的添加顺序。既要不重复,又要保证先后顺序.
LinkedHashSet.Map: 双元素集合。用键值对Map<K,V>的存储方式。
3、List、Set和Map之间相互转换问题:
List<String> list = new ArrayList<>();
把List转换为Set:Set<String> set = new HashSet<>(list); //此时会消除重复的元素.
把Set转换为List:List<String> list2 = new ArrayList<>(set );
Map不能直接转换为List或Set(但是Map中的方法可以间接的将键或值转换).
4、一个小需求demo
public static void main(String[] args) {
/**
* 需求 计算一个字符串中每一个字母出现的次数
* 用键值对做: Character-->key ,Integer --> value
*/
String str = "fadjlkfajdaqweiiueoiruoilknvanjvahjknjddslkpd";
char[] arr = str.toCharArray(); //将字符串转为数组
//Map<Character, Integer> map2 = new HashMap<>(); // 无序
Map<Character, Integer> map2 = new LinkedHashMap<>(); // 插入排序
//Map<Character, Integer> map2 = new TreeMap<>(); // 自然排序
for (char ch : arr) {
//判断map中是否包含了该字符的key
if(map2.containsKey(ch)){ //如果存在,取出该字符对应的value值加1 ,再放回去
Integer num = map2.get(ch);
map2.put(ch, num+1);
}else{ //如果不存在,表示当前map不包含该字符的key, 将ch字符保存为 key ,value值设置为1
map2.put(ch, 1);
}
}
System.out.println(map2);
}
HashMap源码分析参考文章:
https://www.cnblogs.com/winterfells/p/8876888.html
https://blog.csdn.net/qq_34433210/article/details/90696751
LinkedHashMap源码分析参考文章:
https://blog.csdn.net/ONROAD0612/article/details/82851060
简单记录下使用,注意点,具体源码分析,上面作者文章写得不错,可参考。
ends~















 3370
3370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









