






1.多层感知机模型框架
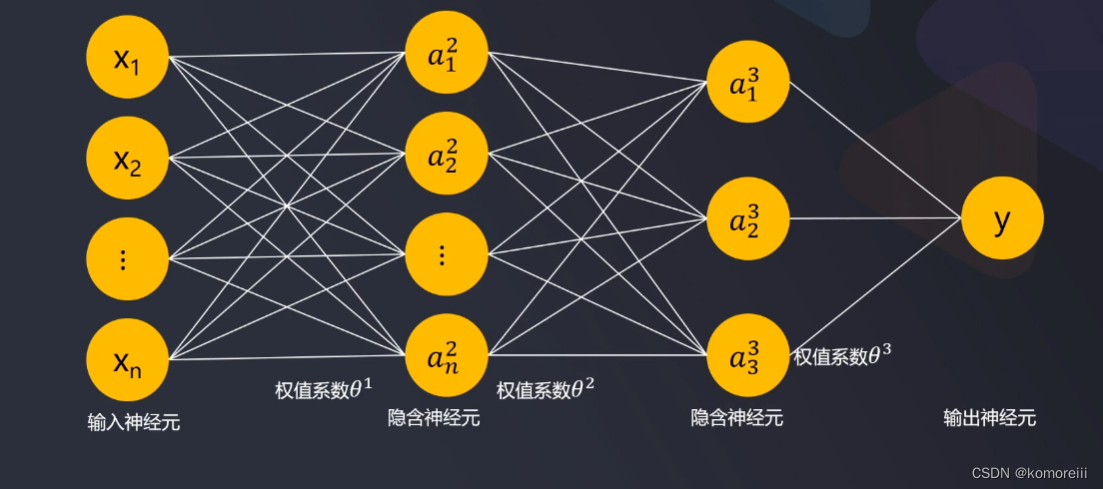
多层感知机正向传播(forward propagation)

a
1
2
=
f
(
θ
10
1
x
0
+
θ
11
1
x
1
+
θ
12
1
x
2
+
θ
13
1
x
3
)
=
f
(
θ
1
x
)
=
f
(
z
1
2
)
a^2_1=f(\theta^1_{10}x_0+\theta^1_{11}x_1+\theta^1_{12}x_2+\theta^1_{13}x_3)=f(\theta^1x)=f(z^2_1)
a12=f(θ101x0+θ111x1+θ121x2+θ131x3)=f(θ1x)=f(z12)
a
2
2
=
f
(
θ
20
1
x
0
+
θ
21
1
x
1
+
θ
22
1
x
2
+
θ
23
1
x
3
)
=
f
(
θ
2
x
)
=
f
(
z
2
2
)
a^2_2=f(\theta^1_{20}x_0+\theta^1_{21}x_1+\theta^1_{22}x_2+\theta^1_{23}x_3)=f(\theta^2x)=f(z^2_2)
a22=f(θ201x0+θ211x1+θ221x2+θ231x3)=f(θ2x)=f(z22)
a
3
2
=
f
(
θ
30
1
x
0
+
θ
31
1
x
1
+
θ
32
1
x
2
+
θ
33
1
x
3
)
=
f
(
θ
3
x
)
=
f
(
z
3
2
)
a^2_3=f(\theta^1_{30}x_0+\theta^1_{31}x_1+\theta^1_{32}x_2+\theta^1_{33}x_3)=f(\theta^3x)=f(z^2_3)
a32=f(θ301x0+θ311x1+θ321x2+θ331x3)=f(θ3x)=f(z32)
y
=
f
(
θ
10
2
a
0
2
+
θ
11
2
a
1
2
+
θ
12
2
a
2
2
+
θ
13
2
a
3
2
)
=
f
(
θ
2
x
2
)
=
f
(
z
1
3
)
y=f(\theta^2_{10}a^2_0+\theta^2_{11}a^2_1+\theta^2_{12}a^2_2+\theta^2_{13}a^2_3)=f(\theta^2x^2)=f(z^3_1)
y=f(θ102a02+θ112a12+θ122a22+θ132a32)=f(θ2x2)=f(z13)
模型求解:寻找到合适的参数θ,使总样本预测y与实际y的误差总和最小。
2.损失函数:从逻辑回归到mlp
逻辑回归损失函数(J)
J
=
1
m
∑
i
=
1
m
J
(
i
)
=
−
1
m
[
∑
i
=
1
m
(
y
i
l
o
g
(
h
(
x
i
)
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
h
(
x
i
)
)
)
]
J=\frac{1}{m}{\sum_{i=1}^mJ^{(i)}}=-\frac{1}{m}[\sum_{i=1}^m(y^{i}log(h(x^{i}))+(1-y^{(i)})log(1-h(x^{i})))]
J=m1i=1∑mJ(i)=−m1[i=1∑m(yilog(h(xi))+(1−y(i))log(1−h(xi)))]
多层感知器损失函数损失函数(J):
J
=
1
m
∑
i
=
1
m
∑
k
=
1
K
J
(
i
)
=
−
1
m
[
∑
i
=
1
m
∑
k
=
1
K
(
y
k
(
i
)
l
o
g
(
h
(
x
i
)
)
k
+
(
1
−
y
k
(
i
)
)
l
o
g
(
1
−
(
h
(
x
i
)
)
k
)
)
]
J=\frac{1}{m}{\sum_{i=1}^m\sum_{k=1}^KJ^{(i)}}=-\frac{1}{m}[\sum_{i=1}^m\sum_{k=1}^K(y^{(i)}_klog(h(x^{i}))_k+(1-y^{(i)}_k)log(1-(h(x^{i}))_k))]
J=m1i=1∑mk=1∑KJ(i)=−m1[i=1∑mk=1∑K(yk(i)log(h(xi))k+(1−yk(i))log(1−(h(xi))k))]
梯度下降法寻找参数
f
(
x
)
=
{
t
e
m
p
θ
j
=
θ
j
−
α
δ
δ
θ
j
J
(
θ
)
θ
j
=
t
e
m
p
θ
j
}
f(x)=\left\{ \begin{aligned} temp_{\theta_j}=\theta_j-\alpha\frac{\delta}{\delta\theta_j}J(\theta)\\ \theta_j=temp_{\theta_j} \end{aligned} \right\}
f(x)=⎩⎪⎨⎪⎧tempθj=θj−αδθjδJ(θ)θj=tempθj⎭⎪⎬⎪⎫
以一个神经元为例:x=3,Y=10
y
=
θ
1
x
+
θ
0
y=\theta_1x+\theta_0
y=θ1x+θ0
初始参数:θ 0=2,θ1=2,α=0.2
J
=
∣
Y
−
y
∣
=
Y
−
(
θ
1
x
+
θ
0
)
=
10
−
8
=
2
J=|Y-y|=Y-(\theta_1x+\theta_0) =10-8=2
J=∣Y−y∣=Y−(θ1x+θ0)=10−8=2
θ
01
=
θ
0
−
α
δ
J
(
θ
)
δ
θ
0
=
2
−
0.2
∗
(
−
1
)
=
2.2
θ
11
=
θ
1
−
α
δ
J
(
θ
)
δ
θ
1
=
2
−
0.2
∗
(
−
3
)
=
2.6
\theta_{01}=\theta_0-\alpha\frac{\delta J(\theta)}{\delta\theta_0}=2-0.2*(-1)=2.2\\ \theta_{11}=\theta_1-\alpha\frac{\delta J(\theta)}{\delta\theta_1}=2-0.2*(-3)=2.6\\
θ01=θ0−αδθ0δJ(θ)=2−0.2∗(−1)=2.2θ11=θ1−αδθ1δJ(θ)=2−0.2∗(−3)=2.6
Y
1
=
2.6
x
+
2.2
=
10
Y_1=2.6x+2.2=10
Y1=2.6x+2.2=10
3.多层感知机反向传播(backpropagation)

如上图,只有三层:
δ
j
l
代
表
第
l
层
递
j
个
神
经
元
的
偏
差
δ
1
3
=
a
3
−
Y
δ
2
=
(
θ
2
)
T
⊙
δ
3
f
′
(
z
3
)
\delta^l_j代表第l层递j个神经元的偏差\\ \delta^3_1=a^3-Y\\ \delta^2=(\theta^2)^T\odot\delta^3f'(z^3)
δjl代表第l层递j个神经元的偏差δ13=a3−Yδ2=(θ2)T⊙δ3f′(z3)
如果有更多的隐藏层:
δ
l
=
(
θ
l
)
T
θ
(
l
+
1
)
⊙
f
′
(
z
l
+
1
)
\delta^l=(\theta^l)^T\theta^{(l+1)}\odot f'(z^{l+1})
δl=(θl)Tθ(l+1)⊙f′(zl+1)
核心思想:从后往前依次计算每层神经元的数值偏差,然后通过梯度下降法寻找到使偏差最小的参数θ,完成模型求解。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









