






任务:
一、基于高斯分布概率密度函数,对两个维度数据进行分析、计算概率密度函数,寻找异常点并剔除
二、统计分析各维度数据分布
三、对数据进行主成分分析,计算各维度方差比例
四、数据分离,数据分离参数:random_state=1, test_size=0.4
五、建立KNN模型(K=3)完成分类,可视化分类边界
六、计算测试数据集对应的混淆矩阵,准确率、召回率、特异度、精确率、F1分数
七、尝试不同的K值(1-20),计算其在训练数据集、测试数据集上的准确率并作图
步骤:
任务一基于高斯分布概率密度函数,对两个维度数据进行分析、计算概率密度函数,寻找异常点并剔除
1.加载数据:
import pandas as pd
import numpy as np
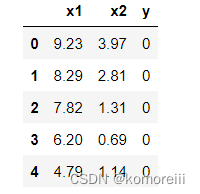
data = pd.read_csv('task2_data.csv')
data.head()
2.x,y赋值
x = data.drop(['y'],axis=1)
y = data.loc[:,'y']
x.head()
y.head()
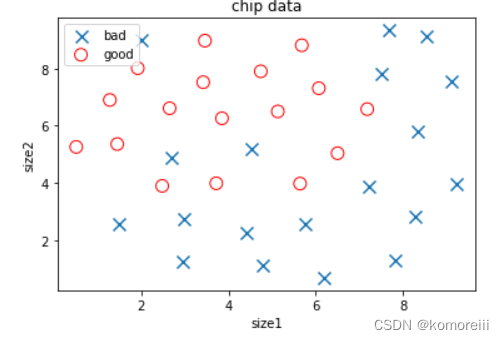
3.数据可视化
from matplotlib import pyplot as plt
fig1 = plt.figure()
bad = plt.scatter(x.loc[:,'x1'][y==0],x.loc[:,'x2'][y==0],marker='x',s=100,label='bad')
good = plt.scatter(x.loc[:,'x1'][y==1],x.loc[:,'x2'][y==1],marker='o',facecolor='none',edgecolor='red',s=100,label='good')
plt.title('chip data')
plt.xlabel('size1')
plt.ylabel('size2')
plt.legend()
plt.show()
4.计算y0,y1对应的高斯分布的概率密度函数
import math
x1 = data.loc[:,'x1'][y==0]
x2 = data.loc[:,'x2'][y==0]
#计算均值与标准差
u1 = x1.mean()
sigma1 = x1.std()
u2 = x2.mean()
sigma2 = x2.std()
print(u1,sigma1,u2,sigma2)
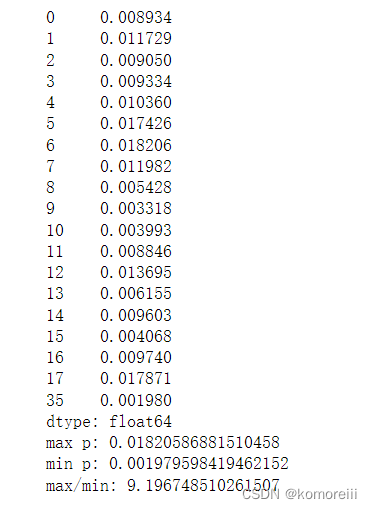
p1 = 1/sigma1/math.sqrt(2*math.pi)*np.exp(-np.power((x1-u1),2)/2/math.pow(sigma1,2))
p2 = 1/sigma2/math.sqrt(2*math.pi)*np.exp(-np.power((x2-u2),2)/2/math.pow(sigma2,2))
p = np.multiply(p1,p2)
print(p)
print('max p:',max(p))
print('min p:',min(p))
print('max/min:',max(p)/min(p))
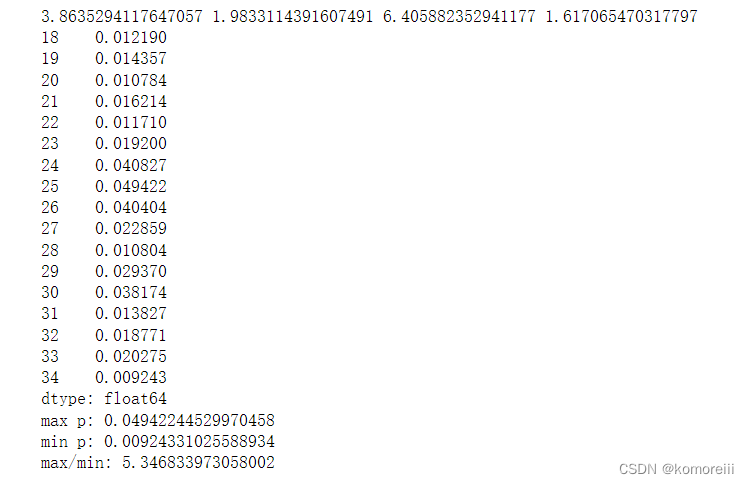
import math
x1 = data.loc[:,'x1'][y==1]
x2 = data.loc[:,'x2'][y==1]
#计算均值与标准差
u1 = x1.mean()
sigma1 = x1.std()
u2 = x2.mean()
sigma2 = x2.std()
print(u1,sigma1,u2,sigma2)
#计算高斯分布的概率密度函数
p1 = 1/sigma1/math.sqrt(2*math.pi)*np.exp(-np.power((x1-u1),2)/2/math.pow(sigma1,2))
p2 = 1/sigma2/math.sqrt(2*math.pi)*np.exp(-np.power((x2-u2),2)/2/math.pow(sigma2,2))
p = np.multiply(p1,p2)
print(p)
print('max p:',max(p))
print('min p:',min(p))
print('max/min:',max(p)/min(p))
5.异常数据点检测及可视化分布
from sklearn.covariance import EllipticEnvelope
ad_model = EllipticEnvelope(contamination=0.02)
ad_model.fit(x[y==0])
y_predict_bad = ad_model.predict(x[y==0])
print(y_predict_bad)

异常点可视化:
fig2 = plt.figure()
bad = plt.scatter(x.loc[:,'x1'][y==0],x.loc[:,'x2'][y==0],marker='x',s=100,label='bad')
good = plt.scatter(x.loc[:,'x1'][y==1],x.loc[:,'x2'][y==1],marker='o',facecolor='none',edgecolor='red',s=100,label='good')
plt.scatter(x.loc[:,'x1'][y==0][y_predict_bad==-1],x.loc[:,'x2'][y==0][y_predict_bad==-1],marker='o',s=150)
plt.title('chip data')
plt.xlabel('size1')
plt.ylabel('size2')
plt.legend()
plt.show()
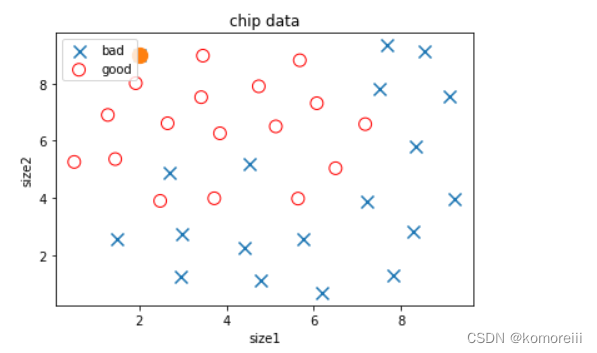
6.剔除异常数据点

任务二:统计分析各维度数据分布
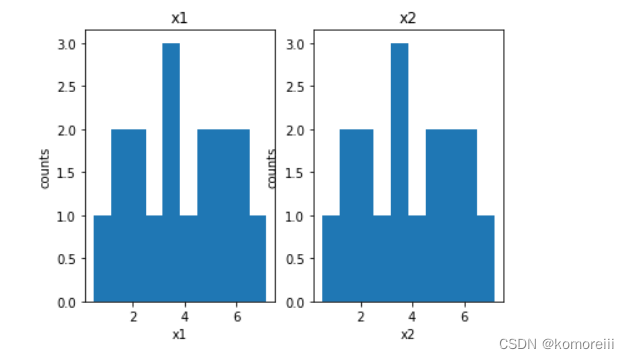
fig3 = plt.figure()
plt.subplot(121)
plt.hist(x1,bins=10)
plt.title('x1')
plt.xlabel('x1')
plt.ylabel('counts')
plt.subplot(122)
plt.hist(x1,bins=10)
plt.title('x2')
plt.xlabel('x2')
plt.ylabel('counts')
plt.show()
任务三:对数据进行主成分分析,计算各维度方差比例
剔除异常点后赋值
x = data.drop(['y'],axis=1)
y = data.loc[:,'y']
print(x.shape)
(35, 2)
主成分分析
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
x_norm = StandardScaler().fit_transform(x)
pca = PCA(n_components=2)
x_reduce = pca.fit_transform(x_norm)
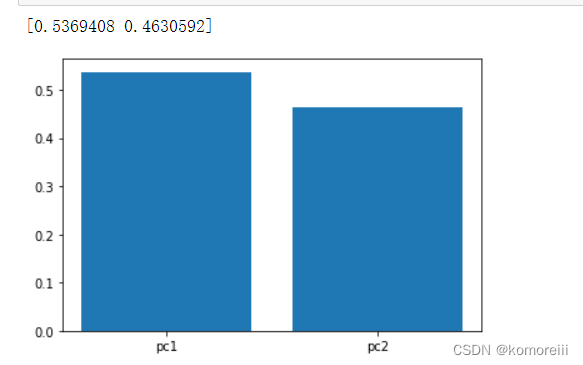
var_ratio = pca.explained_variance_ratio_
print(var_ratio)
fig4 = plt.figure()
plt.bar([1,2],var_ratio)
plt.xticks([1,2],['pc1','pc2'])
plt.show()
四、数据分离,数据分离参数:random_state=1, test_size=0.4
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=1,test_size=0.4)
print(x_train.shape,x_test.shape,x.shape)
(21, 2) (14, 2) (35, 2)
五、建立KNN模型(K=3)完成分类,可视化分类边界
#建立knn模型 k=3
from sklearn.neighbors import KNeighborsClassifier
knn_3 = KNeighborsClassifier(n_neighbors=3)
knn_3.fit(x_train,y_train)
#模型预测
y_train_predict = knn_3.predict(x_train)
y_test_predict = knn_3.predict(x_test)
print(y_train_predict,y_test_predict)

#准确率计算
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(y_train,y_train_predict)
accuracy_test = accuracy_score(y_test,y_test_predict)
print(accuracy_train,accuracy_test)

#结果可视化
#生成用于结果可视化的数据集
xx,yy = np.meshgrid(np.arange(0,10,0.05),np.arange(0,10,0.05))
#数据展开
x_range = np.c_[xx.ravel(),yy.ravel()]
print(x_range.shape)
print(x_range)
 #预测生成的数据对应的类别
#预测生成的数据对应的类别
```python
y_range_predict = knn_3.predict(x_range)
fig4 = plt.figure()
bad_predict = plt.scatter(x_range[:,0][y_range_predict==0],x_range[:,1][y_range_predict==0],label='bad_p')
good_predict = plt.scatter(x_range[:,0][y_range_predict==1],x_range[:,1][y_range_predict==1],label='good_p')
bad = plt.scatter(x.loc[:,'x1'][y==0],x.loc[:,'x2'][y==0],marker='x',s=100,label='bad')
good = plt.scatter(x.loc[:,'x1'][y==1],x.loc[:,'x2'][y==1],marker='o',facecolor='none',edgecolor='red',s=100,label='good')
plt.title('chip data')
plt.xlabel('size1')
plt.ylabel('size2')
plt.legend()
plt.show()

六、计算测试数据集对应的混淆矩阵,准确率、召回率、特异度、精确率、F1分数
#计算混淆矩阵
```python
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_test_predict)
print(cm)

获取混淆矩阵

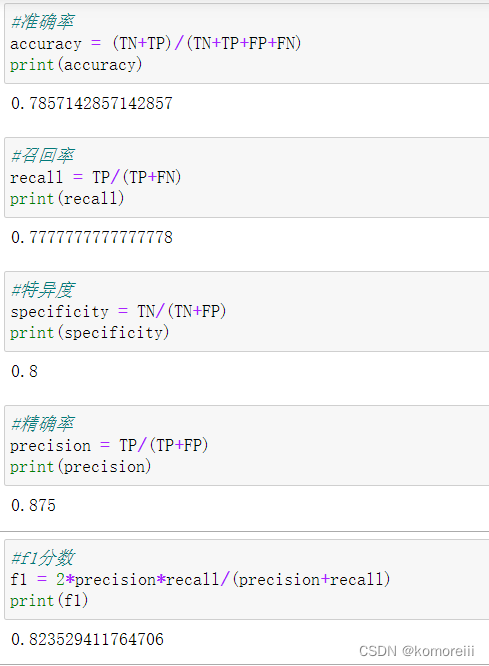
准确率:(TN+TP)/14=11/14=0.7857
召回率:TP/(TP+FN)=7/9=0.7778
特异度:TN/(TN+FP)=4/5=0.8
精确度:TP/(TP+FP)=7/8=0.875
F1分数:2*(7/8)*(7/9)/(7/8+7/9)=0.8235
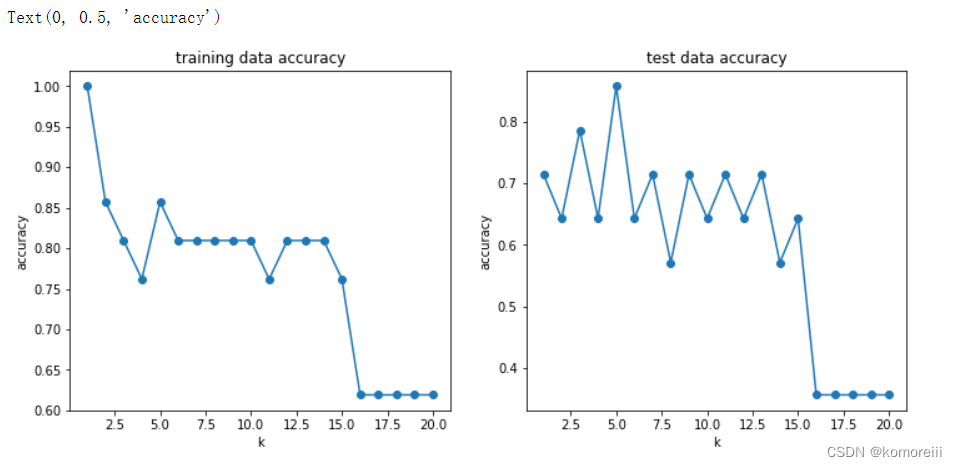
七、尝试不同的K值(1-20),计算其在训练数据集、测试数据集上的准确率并作图
n = [i for i in range(1,21)]
accuracy_train = []
accuracy_test = []
for i in n:
knn_i = KNeighborsClassifier(n_neighbors=i)
knn_i.fit(x_train,y_train)
y_train_predict = knn_i.predict(x_train)
y_test_predict = knn_i.predict(x_test)
accuracy_train_i = accuracy_score(y_train,y_train_predict)
accuracy_test_i = accuracy_score(y_test,y_test_predict)
accuracy_train.append(accuracy_train_i)
accuracy_test.append(accuracy_test_i)
print(accuracy_train)
print(accuracy_test)
i从1到20的准确率:

#k值变化对准确率影响的可视化
fig5 = plt.figure(figsize=(12,5))
plt.subplot(121)
plt.plot(n,accuracy_train,marker='o')
plt.title('training data accuracy')
plt.xlabel('k')
plt.ylabel('accuracy')
plt.subplot(122)
plt.plot(n,accuracy_test,marker='o')
plt.title('test data accuracy')
plt.xlabel('k')
plt.ylabel('accuracy')














 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









