






ㅤㅤㅤ
ㅤㅤㅤ
ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ(获取信用是要付出很高代价的。——杰罗尔德)
ㅤㅤㅤ
ㅤㅤㅤ
ㅤㅤㅤㅤㅤㅤㅤㅤㅤ
ElasticSearch 数据迁移方案
ElasticSearch 常用api
ElasticSearch 模糊搜索方案
问题场景
使用es检索文本时,有时无法得到预期结果,检索带中文的文本时,只有中文部分可以模糊搜索,但英文和数字却不行,比如全英文,全数字,英文+数字。
优化方案
使用新的索引结构解决,配置了ngram分词器,limit,unique分词过滤器
配置环境
es可视化工具链接
- 仓储地址:https://github.com/mobz/elasticsearch-head.git
- 配置连接地址

索引结构
{
"settings": {
"number_of_shards": 7,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"default": {
"tokenizer": "1_25_tokenizer_grams",
"filter": [
"unique",
"500_limit_filter"
]
}
},
"tokenizer": {
"1_25_tokenizer_grams": {
"type": "ngram",
"min_gram": 1,
"max_gram": 25
}
},
"filter": {
"500_limit_filter": {
"type": "limit",
"max_token_count": 500
}
}
}
},
"mappings": {
"business": {
"numeric_detection": false,
"date_detection": false,
"properties": {
"account": {
"type": "string",
"index": "not_analyzed"
},
"number": {
"type": "string",
"index": "not_analyzed"
},
"flow": {
"type": "string",
"index": "not_analyzed"
},
"createTime": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
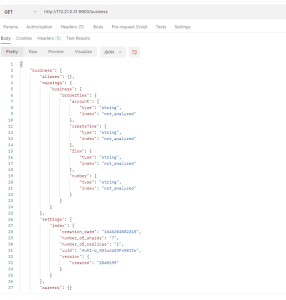
插入索引数据的索引结构
{
"state":"open",
"settings":{
"index":{
"creation_date":"1646724159602",
"analysis":{
"filter":{
"500_limit_filter":{
"type":"limit",
"max_token_count":"500"
}
},
"analyzer":{
"default":{
"filter":[
"unique",
"500_limit_filter"
],
"tokenizer":"1_25_tokenizer_grams"
}
},
"tokenizer":{
"1_25_tokenizer_grams":{
"type":"ngram",
"min_gram":"1",
"max_gram":"25"
}
}
},
"number_of_shards":"7",
"number_of_replicas":"1",
"uuid":"xehbLr2-TH-8WEt3Ptn9CA",
"version":{
"created":"2040199"
}
}
},
"mappings":{
"business":{
"date_detection":false,
"properties":{
"2aadb33c-de2e-11ea-9a63-210593f52d68":{
"type":"string"
},
"0eae0e80-5f81-11eb-a75b-b3919f758643":{
"type":"string"
},
"dbf32100-019d-11ec-b3b4-d9a8f9085a2e":{
"type":"string"
},
"d78430c0-9f31-11ea-83ed-a34974eec164":{
"type":"string"
},
"e5ca8500-fbd6-11eb-9b56-fb75f73c50dc":{
"type":"string"
},
"42f94240-959b-11e6-9917-2d95033366e1":{
"type":"string"
},
"2aadda43-de2e-11ea-9a63-210593f52d68":{
"type":"string"
},
"3baaae30-1e93-11ec-b7ca-9d88fef23a2a":{
"type":"string"
},
"80f268d0-fbd8-11eb-9b56-fb75f73c50dc":{
"type":"string"
},
"number":{
"index":"not_analyzed",
"type":"string"
},
"createTime":{
"index":"not_analyzed",
"type":"string"
},
"d115eb70-9f31-11ea-bb50-8b404e7d32bf":{
"type":"string"
},
"3da8d4b0-e38d-11ea-bba7-b5a306bc2148":{
"type":"string"
},
"def45310-019d-11ec-8372-1f0ef8ecd3d5":{
"type":"string"
},
"account":{
"index":"not_analyzed",
"type":"string"
},
"flow":{
"index":"not_analyzed",
"type":"string"
},
"2aadda44-de2e-11ea-9a63-210593f52d68":{
"type":"string"
},
"43030560-1e93-11ec-b7ca-9d88fef23a2a":{
"type":"string"
}
}
}
},
"aliases":[
]
}
索引结构说明
官方文档:
settings https://www.elastic.co/guide/en/elasticsearch/reference/8.0/index-modules.html
mappings https://www.elastic.co/guide/en/elasticsearch/reference/8.0/mapping.html
settings //索引设置
settings.number_of_shards //索引的主分片数
settings.number_of_replicas //每个主分片具有的副本数
settings.analysis //索引分析器
settings.analysis.analyzer //索引分析器设置
settings.analysis.analyzer.default //索引分析器默认设置,除指定配置外的字段全部使用该配置
settings.analysis.analyzer.default.tokenizer //索引分词器 1_25_tokenizer_grams(自定义的分词器,逐字分词)
settings.analysis.analyzer.default.filter //索引过滤器,可以同时使用多个 unique(重复分词过滤器) limit_filter(自定义的分词结果限制器,限制返回结果数量)
settings.analysis.tokenizer //索引分词器设置
settings.analysis.tokenizer.1_25_tokenizer_grams //索引分词器自定义名称key
settings.analysis.tokenizer.1_25_tokenizer_grams.type // 自定义分词的类型
settings.analysis.tokenizer.1_25_tokenizer_grams.min_gram // ngram分词器的属性,最小分词数
settings.analysis.tokenizer.1_25_tokenizer_grams.max_gram // ngram分词器的属性,最大分词数
settings.analysis.filter //索引分词过滤器设置
settings.analysis.filter.limit_filter //索引分词过滤器自定义名称key
settings.analysis.filter.limit_filter.type //自定义分词过滤器的类型
settings.analysis.filter.limit_filter.max_token_count //limit分词过滤器的属性,最多分词结果数
mappings //索引映射设置
mappings.business //自定义的索引映射名称
mappings.business.numeric_detection //数字自动转换 比如字符串1.0会被转换成1
mappings.business.date_detection //日期自动转换 会被转换成"yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"格式
mappings.business.account //自定义索引字段
mappings.business.account.type //自定义索引字段类型 string(字符串)
mappings.business.account.index //自定义索引字段类型 not_analyzed(不会分词,精确搜索,存储的时候存的是一个) 默认是analyzed(根据配置的分词器规则进行存储和检索)
相关文档:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_exact_values_versus_full_text.html#_exact_values_versus_full_text
https://www.elastic.co/guide/cn/elasticsearch/guide/current/mapping-intro.html
minimum_should_match:should语句中的最少匹配数,类型为数字,用于或的查询
排查过程
- 先查看原索引结构,发现对account,number还有flow等字段没有进行分词,对自定义字段"80f268d0-fbd8-11eb-9b56-fb75f73c50dc"等没有设置,所以默认是分词的
{
"settings":{
"number_of_shards":7,
"number_of_replicas":1
},
"mappings":{
"business":{
"properties":{
"account":{
"type":"string",
"index":"not_analyzed"
},
"number":{
"type":"string",
"index":"not_analyzed"
},
"flow":{
"type":"string",
"index":"not_analyzed"
},
"createTime":{
"type":"string",
"index":"not_analyzed"
},
"80f268d0-fbd8-11eb-9b56-fb75f73c50dc":{
"type":"string"
}
}
}
}
}
- 使用es的api _analyze来分别对account(不分词)和80f268d0-fbd8-11eb-9b56-fb75f73c50dc(分词)进行分析
- 分析"account",只有一个词组,因为没有使用分词,所以是符合预期的

- 分析"def45310-019d-11ec-8372-1f0ef8ecd3d5",发现对于中文能正常分词,但对于数字+英文,没有空格和标点符号的文本,分词的结果只有一个,还是全文的
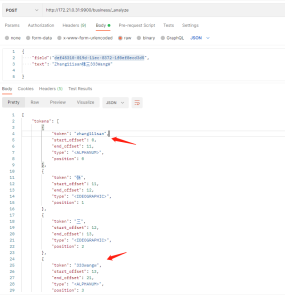
- 这就导致后续的搜索,对于英文和数字部分只能匹配全文而不能模糊搜索
- 于是再查看该索引结构的映射关系,发现没有指定任何的分词器,分词过滤器和字符过滤器
- 搜集资料和测试,发现当没有指定分词器时,es默认的分词器为standard分词器
- 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/8.0/analysis-standard-tokenizer.html
- 该分词器基于Unicode 文本分段算法,去除空格和标点符号等,但对于连续的英文,则不会分词,从而导致对于没有符号的文本不能模糊搜索

- 于是开始从分词器着手,搜集大量的资料并测试,选择了以下分词器 ngram
- 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/8.0/analysis-ngram-tokenizer.html
- 该分词器基于n-ngram,将文本逐字拆分,比如张3w5,会被拆分成张,张3,张3w,张三w5,3,3w等
- 可以很好的应对客户模糊搜索的需求

- 默认分词最小长度为min_gram1,最大为max_gram2,但针对不同需求场景,可以设置不同的分词长度。
- 比如针对工单自定义字段来说,25个长度的字符模糊搜索已经基本满足绝大部分客户的需求,所以在这里我们设置为min_gram1,最大为max_gram25,那么最大的分词长度就是25个
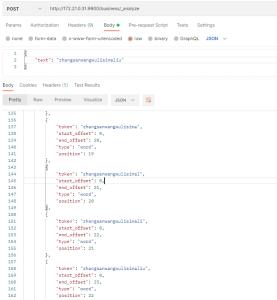
- 现在已知ngram可以解决模糊搜索问题,但发现当设置最小为1,最大为25时出现了性能问题。比如文本长度过长(几千个字符时),分词耗时长,导致查询也耗时长,es索引存储空间占用大
- 但针对工单自定义字段,大多都是短文本,长文本较少,所以可以使用limit分词过滤器,对分析的结果数量进行限制,达到性能优化和节省空间的目的
- 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/8.0/analysis-limit-token-count-tokenfilter.html
- 限制分词的结果集数量,max_token_count默认为1

- 但很明显只有一个分词结果是不合适的,所以我们设置max_token_count为500,可以满足30个字符的模糊搜索,具体的索引结构,在上面有提到
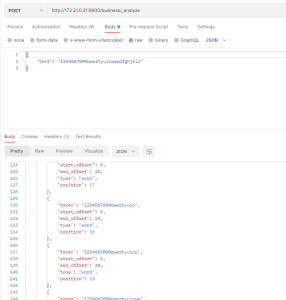

- 现在虽然解决了模糊搜索,也优化了性能,但发现分词结果中有很多重复的结果
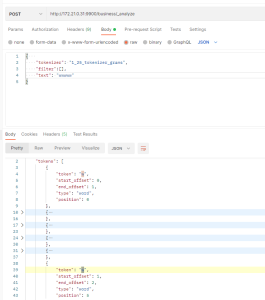
- 这些重复的结果对于检索来说不但浪费性能,而且浪费存储空间,所以需要一个对结果进行去重的过滤器
- 查看官方文档,发现有一个unique去重过滤器可以满足需求
- 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/8.0/analysis-unique-tokenfilter.html

- 完结















 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









