







目录
场景
对字符类型字段进行模糊搜索,比如用户昵称、备注名等等属性
例如:

方案设计
使用 ngram 分词器 + 短语搜索,ngram 分词器和短语匹配的使用会在下面实践中展示
方案实践
创建 index
PUT user
{
"number_of_shards": "5",
"number_of_replicas": "1",
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "ngram_tokenizer"
}
},
"filter": [
"lowercase"
],
"tokenizer": {
"ngram_tokenizer": {
"token_chars": [
"letter",
"digit",
"symbol",
"punctuation"
],
"min_gram": "1",
"type": "ngram",
"max_gram": "1"
}
}
}
}
自定义分词器:
1、把 min_gram 和 max_gram 都设置成 1 是为了提高搜素精度
2、设置 filter 的值 为 lowercase 是为了保证关键字为大小写都能被匹配到
设置 mapping
PUT user/_doc/_mappings
{
"properties": {
"nick_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ngram_analyzer"
}
}
}
1、使用多类型字段,text类型是为了建立倒排索引,设置 keyword 是为了精确搜素
2、设置一下这个字段创建倒排搜索使用的分词器 为刚才自定义的 ngram_analyzer
插入数据
PUT user/_doc/1
{
"nick_name":"wcc 1 鹅鹅"
}
搜索语句
GET user/_search
{
"query": {
"match_phrase": {
"nick_name": {
"query": "1 鹅",
"slop": 0
}
}
}
}
1、query 用户输入的关键字
2、slop 是为了控制 搜素的模糊度
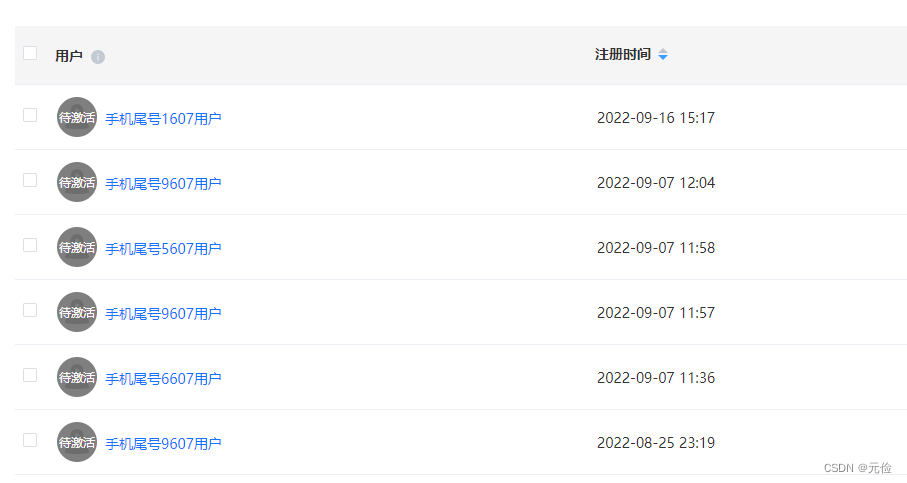
实践结果
输入关键字:

结果:
希望见到此文章的伙伴能点点赞!!!















 5777
5777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









