







一.C++内存四区:
面向对象的三大特征:封装、继承、多态
封装:利用抽象数据类型将数据和基于数据的操作封装在一起,只保留一些对外接口。
继承:子类继承父类的所有内容,增加程序的可扩展性
多态:通过一个父类对象能够访问多个子类接口,动态绑定
1.代码区:存放二进制代码,操作系统进行管理,成员函数和非成员函数
2.全局区:存放全局变量、静态变量和常量
3.栈区:存放函数的参数值、局部变量,由编译器进行管理,声明的对象如果没有用new,则也是存放在栈中的
4.堆区:由程序员进行内存管理,否则程序结束时由操作系统回收
二.指针
1.指针必须初始化
2.指针变量和普通变量的区别
- 普通变量存放的是数据,指针变量存放的是地址
- 指针变量可以通过" * "操作符,操作指针变量指向的内存空间,这个过程称为解引用
3.当两个指针同时指向一块内存时,要释放这块内存的话,合法的操作应该是:先将一个指针置为NULL,再delete另一个指针(因为delete,就是告诉编译器这块内存已经没有被占用了,所以只能delete一次)
4.对基本数据类型,delete和delete[] 的结果是完全一样的,对于对象数组来说,必须用delete[] .单个对象用delete
三.模板的友元类
template <class Type> friend class 类名;
四.C语言的字符和字符串
在C语言中实际上是没有字符串的,只有char类型。
当用字符数组表示字符串时,会默认在末尾加上‘/0’,因此实际的字符数组空间要加一。
char str[100] = "hello world!";
char *p = (char *) malloc(sizeof(char) * n);
五、struct和class的区别
在C++中 struct和class唯一的区别就在于 默认的访问权限不同(其他没有什么太大区别)
区别:
- struct 默认权限为公共
- class 默认权限为私有
六、深拷贝和浅拷贝
浅拷贝:简单的赋值拷贝操作
深拷贝:在堆区重新申请空间,进行拷贝操作
对于基本数据类型,两个没有区别。但如果类中存在new出来的内存,也就是在堆内的内存,那么浅拷贝就相当于取别名,会导致释放时在堆内重复释放,而深拷贝就是在堆内申请内存,再将值复制到内存中。
#include<iostream>
#include<vector>
using namespace std;
class Animal {
public:
int* p = new int[10];
Animal(int a[10]){
for (int i = 0; i < 10; i++) {
p[i] = a[i];
}
}
virtual void doSpeak(){
cout << "动物在说话" << endl;
}
void change() {
p[0] = 100;
}
};
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
Animal animal(arr);
cout << animal.p[0] << endl;
Animal an2 = animal;
cout << an2.p[0] << endl;
animal.change();
cout << animal.p[0] << endl;
cout << an2.p[0] << endl;
return 0;
}
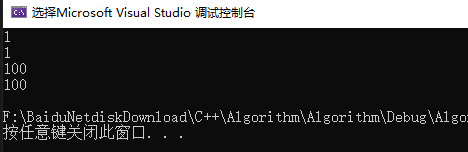
如上图,浅拷贝下,改变了animal中的值,an2里面的值也被改变了,证明两个指向了同一块内存。
#include<iostream>
#include<vector>
using namespace std;
class Animal {
public:
int* p ;
Animal(int a[10]){
p = new int[10];
for (int i = 0; i < 10; i++) {
p[i] = a[i];
}
}
Animal(const Animal& animal) {
p = new int[10];
for (int i = 0; i < 10; i++) {
p[i] = animal.p[i];
}
}
virtual void doSpeak(){
cout << "动物在说话" << endl;
}
void change() {
p[0] = 100;
}
};
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
Animal animal(arr);
cout << animal.p[0] << endl;
Animal an2 = animal;
cout << an2.p[0] << endl;
animal.change();
cout << animal.p[0] << endl;
cout << an2.p[0] << endl;
return 0;
}
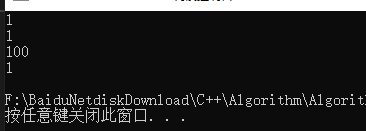
如上图,重写拷贝函数进行深拷贝就没有这个问题了。
七、类中内存问题
类所占内存的大小是由成员变量(静态变量除外)决定的,虚函数指针和虚基类指针也属于数据部分,成员函数是不计算在内的。因为在编译器处理后,成员变量和成员函数是分离的。成员函数还是以一般的函数一样的存在。a.fun()是通过fun(a.this)来调用的。所谓成员函数只是在名义上是类里的。
成员函数和非成员函数是放在代码区的
其实成员函数的大小不在类的对象里面,同一个类的多个对象共享函数代码。
无论有多少个虚函数,都只有一个虚函数表指针(vfptr)
而我们访问类的成员函数是通过类里面的一个指针实现,而这个指针指向的是一个table,table里面记录的各个成员函数的地址(当然不同的编译可能略有不同的实现)。所以我们访问成员函数是间接获得地址的。所以这样也就增加了一定的时间开销,这也就是为什么我们提倡把一些简短的,调用频率高的函数声明为inline形式(内联函数)
为什么空的什么都没有是1呢?
c++要求每个实例在内存中都有独一无二的地址。空类也会被实例化,所以编译器会给空类隐含的添加一个字节,这样空类实例化之后就有了独一无二的地址了。所以空类的sizeof为1
八、静态成员
1、静态成员变量:所有对象共享同一份数据,类内声明,类外初始化
**2、静态成员函数:**所有对象共享同一个函数,静态成员函数只能访问静态成员变量
3、静态成员的访问方式:
(1)通过对象访问object.a或者object.fun(),
(2)通过类名访问:类名::a 或者 类名::fun().
4、 成员变量和成员函数分开存储
(1)非静态成员变量占空间
(2)静态变量不占空间
(3)静态成员函数不占对象空间
(4)非静态成员函数不占空间,所有函数共享一个函数实例
5、每一个非静态成员函数只会诞生一份函数实例,也就是说多个同类型的对象会共用一块代码
那么问题是:这一块代码是如何区分那个对象调用自己的呢?
this指针指向被调用的成员函数所属的对象
九、const的使用
1、成员函数用const修饰时:const func(); 这相当于修饰指针this: cnst this
则const修饰指针时,指针指向的对象不能改变,即不能改变成员变量的值。
2、常量指针 :Animal const p : p指向的值不能改变,即p
指针常量 :Animal * const p : p指向的地址不能改变
十、构造和析构的顺序
构造时:父类先构造,子类后构造
析构时:子类先析构,父类后析构
当子类和父类中出现同名函数,子类会隐藏父类的函数,如果要通过子类访问父类的函数,需要加作用域 son.father::func();
十一、函数重载
1、左移运算符重载
#pragma once
#include<iostream>
using namespace std;
//1.重载有两种方式:成员函数和全局函数
//左移运算符重载:用全局函数
class Person {
public:
int a;
int b;
//void operator<<(Person& p) { //成员函数重载:这么重载后的调用是 p1.operator<<(p2) 这个形式不对
//}
};
ostream& operator<<(ostream& cout, Person& p) { //全局函数重载:operator<<(cout,p),简写为cout<<p;
cout << p.a << " " << p.b; //注意:cout只能有一个,所以用引用的方式
return cout;
}
int main() {
Person p;
p.a = 1;
p.b = 2;
cout << p <<endl; //但是如果要实现cout<<p1<<p2<<...,必须将重载函数的返回置为cout的类型ostream,将返回值再次进行调用
}
十二、文件操作

Person p = {“张三”,24}; //自己创建的对象还可以这么赋值
#include<iostream>
#include<vector>
#include <string> //为了使用getline函数
#include <fstream> //头文件
using namespace std;
//读文件用ifstream
//写文件ofstream
//读写文件用fstream
class Person {
public:
char name[64]; //这里使用c++的string会出问题
int age;
};
int main()
{
//ofstream ofs;
//ofs.open("123.txt",ios::out); //路径地址限制在23个字符内
也可以 ofstream ofs("123.txt",ios::out | ios::binary);
//if (!ofs.is_open()) {
// cout << "文件打开失败!" << endl;
//}
//ofs << "hello world" << endl; //写出到文件中
//ofs << "我是你爸爸" << endl;
//ofs.close(); //关闭文件流
//ifstream ifs;
//ifs.open("123.txt",ios::in);
//if (!ifs.is_open()) {
// cout << "文件打开失败!" << endl;
//}
//读取方式1
//string buf;
//while (getline(ifs, buf)) { //getline是头文件string中的方法
// cout << buf << endl;
//}
//读取方式2
//char arr[1024];
//while (ifs.getline(arr,sizeof(arr))) { //整行读取
// cout << arr << endl;
//}
//读取方式3
//char ar[1024];
//while (ifs >> ar) { //这种方式是以空格为间断符
// cout << ar << endl;
//}
//ifs.close();
//二进制方式读写文件
ofstream ofs1("124.txt",ios::binary | ios::out); //如果没有该文件,会直接创建一个文件
if (!ofs1.is_open()) {
cout << "文件打开失败" << endl;
}
Person p = {"张三",24}; //自己创建的对象还可以这么赋值
ofs1.write((const char*)&p, sizeof(p)); //二进制写入的数据会乱码,但读取出来不会出问题
ofs1.close();
ifstream ifs1("124.txt",ios::binary | ios :: in);
if (!ifs1.is_open()) {
cout << "文件打开失败" << endl;
}
Person p1;
ifs1.read((char *)&p1,sizeof(p1)); //存放数据的地址
cout << p1.name << " " << p1.age << endl;
ifs1.close();
return 0;
}
十三、C++之STL
1、STL包含六个组件:容器、算法、迭代器、仿函数、适配器、空间配置器
容器:各种数据结构,如vector、stack等
算法:各种算法实现,如find、sort等
**迭代器:算法和容器之间的桥梁,提供一种方法,使之能够访问某个容器中的所有数据,**而不会暴露容器的内部表示方式
仿函数:重载了运算时调用的运算符,,仿函数是一个类,在类中进行operator小括号的重载
2、
vector容器是单端动态数组:不是链表,内存是连续的,在头部插入时,后面所有数据都要移动
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
void myPrint(int x) {
cout << x << endl;
}
int main()
{
vector<int> a(10); //10代表存放数据的个数,通过a.resize()可以改变
//存放数据1
for (int i = 0; i < 10; i++) {
a[i] = i;
}
//存放数据2
a.push_back(12); //存放数据,每次都会重新分配内存
//a.resize(15); //重新分配内存大小
cout << a.front() << endl;
cout << a.back() << endl;
a.erase(a.begin()+3); //删除某个元素或某段元素 ,除了begin、end还有rbegin、rend
cout << a.empty() << endl;
遍历方式1
//for_each(a.begin(),a.end(),myPrint); //for_each方法是头文件algorithm中的,调用myPrint函数
遍历方式2
//for (vector<int>::iterator it = a.begin(); it != a.end(); it++) {
// cout << *it << endl;
//}
遍历方式3
//for (int i = 0; i < a.size(); i++) {
// cout << a[i] << endl;
//}
遍历方式4
for (auto i : a) {
cout << i << endl;
}
return 0;
}
deque是双端数组:头部的插入删除也快,类似双向链表,内存不连续
#include<iostream>
#include<algorithm>
#include <set>
#include<list>
#include <deque>
#include <vector>
#include <queue>
using namespace std;
//大部分容器操作相似,只有赋值和取值可能有差异
//删除:erase(begin,(end)) ,查找: find(key); 返回迭代器的位置
//swap()交换两个set的数据
int main()
{
list<int> l; //list只能通过push_back()赋值
l.push_back(56);
l.push_back(23);
l.push_back(12);
for (auto it : l) {
cout << it << " ";
}
cout << "list" << endl;
queue<int> q; //队列,没有迭代器?
q.push(12);
q.push(5);
//q.swap(); swap交换两个队列的数据
vector<int> v(10); // 只有声明时确定了大小,才能这种方式赋值,后面通过resize()重置大小
deque<int> d(10);
for (int i = 0; i < 5; i++) { //只有声明确定了大小,才能这种方式赋值
d[i] = i;
}
d.push_front(18); //与vector的使用区别,vector没有这个方法,因此deque叫双端队列
for (auto it : d) {
cout << it << " ";
}
cout << "deque" << endl;
//pair: 对组,不需要头文件
pair<char, int> p('a', 1);
pair<char, int> p1 = make_pair('b',2); //两种创建方式
cout << p.first << p.second <<"pair" <<endl;
cout << p1.first << p1.second <<"pair" <<endl;
return 0;
}
queue:队列,先进先出
list: 双向循环链表
前四个类型用法相似
set /multiset:所有元素在插入时自动排序,底层用二叉树实现。set不允许有重复元素出现,multiset允许。注意当数据类型是自定义时,自动排序可能出现问题,通过仿函数解决
class Person {
public:
char name[64];
int age;
};
class comparePerson {
public:
bool operator()(const Person& p1, const Person& p2) const{
return p1.age > p2.age; //按年龄从大到小排序
}
};
int main(){
set<int> s; //set只能用insert赋值,set不记录重复值,multiset支持,都是自动排序,自定义类型需要自己指定排序规则
s.insert(56); //只能通过insert()插入
s.insert(56);
s.insert(2);
s.insert(8);
multiset<int> ms;
ms.insert(56);
ms.insert(56);
ms.insert(2);
ms.insert(8);
cout << "set size:" << s.size() << endl;
for (set<int>::iterator it = s.begin(); it != s.end(); it++) {
cout << *it << " ";
}
cout << "set" << endl;
for (multiset<int>::iterator it = ms.begin(); it != ms.end(); it++) {
cout << *it << " ";
}
cout << "multiset" << endl;
Person person1 = {"张三",23}; //当自定义数据类型时,编译器不知道该以哪个为标准进行排序,所以报错
Person person2 = { "李四",22 }; //通过仿函数解决这个问题
Person person3 = { "王五",26 };
Person person4 = { "张龙",15 };
set<Person,comparePerson> sp; //自定义数据类型通过仿函数解决自动排序问题comparePerson类
sp.insert(person1);
sp.insert(person2);
sp.insert(person3);
sp.insert(person4);
for (set<Person, comparePerson>::iterator it = sp.begin(); it != sp.end(); it++) {
cout << (*it).name << " " << (*it).age << "set自定义排序" << endl;
}
return 0;
}
pair : 对组
map/multimap : 键值对,有key和value两个值,元素按照key自动排序,底层用二叉树。 优点是通过key可以直接映射到对应的value。
map不允许出现重复key,multimap允许出现.
#include<iostream>
#include<algorithm>
#include <map>
#include<queue>
using namespace std;
class Person {
public:
string name;
int age;
};
class compareMap {
public: //这里加&是防止拷贝构造一个新的副本,减少内存消耗
bool operator() (const Person& p1, const Person& p2) const{
return p1.age < p2.age;
}
};
int main()
{
map<char, int> m; //map里面存放的是pair类型的数据 pair<key,value>(k,v);
m.insert(pair<char,int>('a',1)); //pair<char,int>()的匿名对象传递
m.insert(pair<char, int>('c', 3));
m.insert(pair<char, int>('b', 2));
for (map<char, int>::iterator it = m.begin(); it != m.end(); it++) {
cout << (*it).first <<" " <<it->second<< endl; //两种表现形式:(*it).first it->second
}
map<char, int> m2(m); //拷贝构造
//两个map容器的交换 swap()函数
//删除元素:erase() 1.根据迭代器进行删除m.erase(begin,end),end可省略 2.根据键key进行元素删除
//查找 : find() 返回迭代器位置 count 返回key的元素个数
//改变排序算法
Person p1 = {"张三",56};
Person p2 = { "李四",12 };
Person p3 = { "王五",43 };
map<Person, int,compareMap> mp;
mp.insert(pair<Person,int>(p1,1));
mp.insert(pair<Person, int>(p2, 1));
mp.insert(pair<Person, int>(p3, 1));
for (map<Person, int, compareMap>::iterator it = mp.begin(); it != mp.end(); it++) {
cout << (*it).first.name<<" " <<(*it).first.age << " " << it->second << endl; //两种表现形式:(*it).first it->second
}
return 0;
}














 5893
5893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









