







目录
1.1 解决循环依赖过程
- 一级缓存:存储单例Bean的Map对象。
- 二级缓存:为了将成熟Bean和纯净Bean分离开来,职责更明确,代码更容易维护,避免由于多线程的环境下读取到不完整的Bean。二级缓存不能存储原生对象。
- 三级缓存:解决因为AOP,创建动态代理导致的问题。存储函数式接口,钩子函数。
- 如果没有出现循环依赖,则会在初始化之后通过BeanPostProcessor创建动态代理。
- 如果出现了循环依赖,则会在实例化之后通过BeanPostProcessor创建动态代理。(提前了)怎么判断当前是否出现了循环依赖呢?可以判断在二级缓存中是否有对应Bean。可以添加一个循环依赖的标识。比如标识为正在创建的Bean。singletonCurrentlyInCreation。
动态代理放入到二级缓存中会有什么问题:
更多的是单一职责原则,其实问题不大。将钩子函数通过函数式接口传递到getSinleton)()方法,判断二级缓存中是否包含对应Bean,并且创建对应的动态代理对象,实现AOP。代码解耦,代码看起来更好看,更易于维护。
1.1.1 三级缓存的作用
循环依赖在我们日常开发中属于比较常见的问题,spring对循环依赖做了优化,使得我们在无感知的情况下帮助我们解决了循环依赖的问题。
最简单的循环依赖就是,A依赖B,B依赖C,C依赖A,如果不解决循环依赖的问题最终会导致OOM,但是也不是所有的循环依赖都可以解决,spring只可以解决通过属性或者setter注入的单例bean,而通过构造器注入或非单例模式的bean都是不可解决的。
通过上文创建bean的过程中我们知道,在获取bean的时候,首先会尝试从缓存中获取,如果从缓存中获取不到才会去创建bean,而三层的缓存正是解决循环依赖的关键:
三级缓存的作用:
-
singletonObjects:用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用
-
earlySingletonObjects:提前曝光的单例对象的cache,存放原始的 bean 对象(尚未填充属性),用于解决循环依赖
-
singletonFactories:单例对象工厂的cache,存放 bean 工厂对象,用于解决循环依赖
1.1.2 解决循环依赖的流程
根据上文,我们都知道创建bean的流程主要包括以下三步:
-
实例化bean
-
装配bean属性
-
初始化bean
例如我们现在有 A依赖B,B依赖A,那么spring是如何解决三层循环的呢?
-
首先尝试从缓存中加载A,发现A不存在
-
实例化A(没有属性,半成品)
-
将实例化完成的A放入第三级缓存中
-
装配属性B(没有属性,半成品)
-
尝试从缓存中加载B,发现B不存在
-
实例化B
-
将实例化完成的B放入第三级缓存中
-
装配属性A
-
尝试从缓存中加载A,发现A存在于缓存中(第3步),将A从第三级缓存中移除,放入第二级缓存中,并将其赋值给B,B装配属性完成
-
此时B的装配属性完毕,初始化B,并将B从三级缓存中移除,放入一级缓存
-
返回第四步,此时A的属性也装配完成
-
初始化A,并将A放入一级缓存
自此,实例A于B都分别完成了创建的流程。
用一张图来描述:
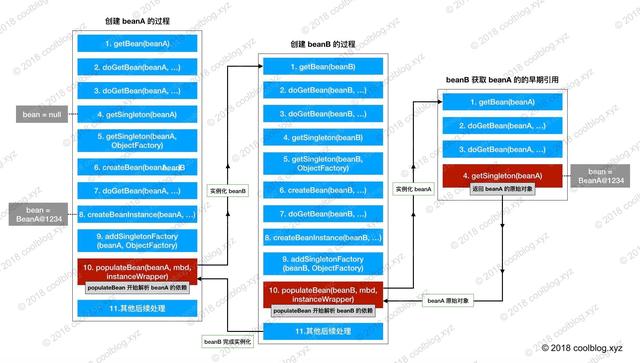
那么此时有一个问题,在第9步中B拥有的A是只实例化完成的对象,并没有属性装配以及初始化,A的初始化是在11步以后,那么在最后全部创建完成此时B中的的属性A是半成品还是已经可以正常工作的成品呢?答案是成品,因为B对A可以理解为引用传递,也就是说B中的属性A于第11步之前的A为同一个A,那么A在第11步完成了属性装配,自然B中的属性也会完成属性装配。
例如我们在一个方法中传入一个实例化对象,如果在方法中对实例化对象做了修改,那么在方法结束后该实例化对象也会做出修改,需要注意的是实例化对象,而不是java中的几种基本对象,基本对象是属于值传递(其实实例化对象也是值传递,不过传入的是对象的引用,可以理解为引用传递)。
2.2 为什么是三层缓存
2.2.1 三级缓存在循环依赖中的作用
有的小伙伴可能已经注意到了,为什么需要三层缓存,两层缓存好像就可以解决问题了,然而如果不考虑代理的情况下确实两层缓存就能解决问题,但是如果要引用的对象不是普通bean而是被代理的对象就会出现问题。
大家需要知道的是,spring在创建代理对象时,首先会实例化源对象,然后在源对象初始化完成之后才会获取代理对象。
我们先不考虑为什么是三级缓存,先看一下在刚才的流程中代理对象存在什么问题
回到我们刚刚举的例子,加入现在我们需要代理对象A,其中A依赖于B,而B也是代理对象,如果不进行特殊处理的话会出现问题:
首先尝试从缓存中加载A,发现A不存在
实例化A(没有属性,半成品)
将实例化完成的A放入第三级缓存中
装配属性B(没有属性,半成品)
尝试从缓存中加载B,发现B不存在
实例化B
将实例化完成的B放入第三级缓存中
装配属性A
尝试从缓存中加载A,发现A存在于缓存中(第3步),将A从第三级缓存中移除,放入第二级缓存中,并将其赋值给B,B装配属性完成
此时B的装配属性完毕,初始化B,并将B从三级缓存中移除,放入一级缓存
返回第四步,此时A的属性也装配完成
初始化A,并将A放入一级缓存
跟之前一样的流程,那么此时B拥有的对象是A的普通对象,而不是代理对象,这就有问题了。
可能有同学会问,不是存在引用传递吗?A被代理完成不是还是会被B所拥有吗?
但是答案也很简单,并不是,A跟A的代理对象肯定时两个对象,在内存中肯定也是两个地址,因此需要解决这种情况。
2.2.2 解决代理对象的问题
我们来看看spring是如何解决这个问题的:
根据bean创建的过程我们知道,bean会首先被实例化
首先会判断是否需要提前曝光,判断结果由三部分组成,分别是:
-
是否是单例模式,默认情况下都是单例模式,spring也只能解决这种情况下的循环依赖
-
是否允许提前曝光,默认是true,也可以更改
-
是否正在创建,正常来说一个bean在创建开始该值为true,创建结束该值为false
回到之前的逻辑,例如此时实例B需要装填属性A,会从缓存中查询A是否存咋,查询到A已经存在,则调用A的getObject()方法,如果A是需要被代理的对象则返回被代理过得对象,否则返回普通bean。
此外还需要注意的是:先创建对象,再创建代理类,再初始化原对象,和初始化之后再创建代理类,是一样的,这也是可以提前暴露代理对象的基础。
2.2.3 二级缓存的作用
那么二级缓存是干什么用的呢?
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean))可以在源代码中看出每调用一次getObject()然后调用getEarlyBeanReference()中 createProxy()都会产生一个新的代理对象,并不不符合单例模式。
(网上有很多文章说是因为调用lamda表达式所以会产生新的对象,其实如果非代理bean并不会产生新的对象,因为objectFactory所持有的是有原始对象的,即时多次调用也会返回相同的结果。但是对于代理对象则会每次新create一个,所以其实会产生新的代理对象而不会是新产生普通对象。所以就其本质为什么使用二级缓存的原因是因为创建代理对象是使用createProxy()的方法,每次调用都会产生新的代理对象,那么其实只要有一个地方能根据beanName返回同一个代理对象,也就不需要二级缓存了,这也是二级缓存的本质意义。其实也可以在getObject()方法中去缓存创建完成的代理对象,只不过这样做就太不优雅,不太符合spring的编码规范。 )
例如A依赖于B,B依赖与A、C、D,而C、D又依赖于A,如果不进行处理的话,A实例化完成之后,在B创建过程中获取A的代理对象A1,然后C、D获取的代理对象就是A2、A3,显然不符合单例模式。
以上有两个需要注意的地方:
-
因为在之前在B装配属性A的时候,即从三级缓存中查找A的时候,如果查到了会将A的bean(有可能是代理对象)放入二级缓存,然后删除三级缓存,那么此时
getSingleton()返回的就是二级缓存中的bean。 -
这里判断经过后置处理器的bean是否被改变,一般是不会改变的,除非实现
BeanPostProcessor接口手工改变。如果没有改变的话则将缓存中的数据取出返回,也就是说如果此时二级缓存中的是代理beanA2,此时会返回A2而不是原始对象A1,如果是普通bean的话则都一样。而如果对象已经被改变则走下面的判断有没有可能报错的逻辑。
3.1循环依赖总结
在学习代理在循环依赖的,发现其实并不太需要二级缓存,可以在bean实例化完成之后就选择要不要生成代理对象,如果要生成的话就往三级缓存中放入代理对象,否则的话就放入普通bean,这样别人过来拿的时候就不用判断是否需要返回代理对象了。
后面发现在网络上有很多跟我想得一样的人,目前参考别人的想法以及自己进行了总结大概是这样子的:
无论是实例化完成之后就进行对象代理还是选择返回一个factory在使用的时候进行代理其实效率上都没有什么区别,只不过一个是提前做一个是滞后做,那么为什么spring选择滞后做的这件事呢?我自己的思考是:
道理也很简单,既然效率没有什么提升的话,为什么要破坏普通bean的创建流程,本来循环依赖就是一件非常小概率的事,没必要因为小概率事情并且滞后也可以解决,从而选择需要修改普通bean的创建逻辑,这无异于是本末倒置,而这也是二级缓存或者说三级缓存中存放的是factory的意义。

















 4341
4341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











