







1. 视觉角度
我们首先先通过一张图来直观的看看2D与3D卷积的区别:
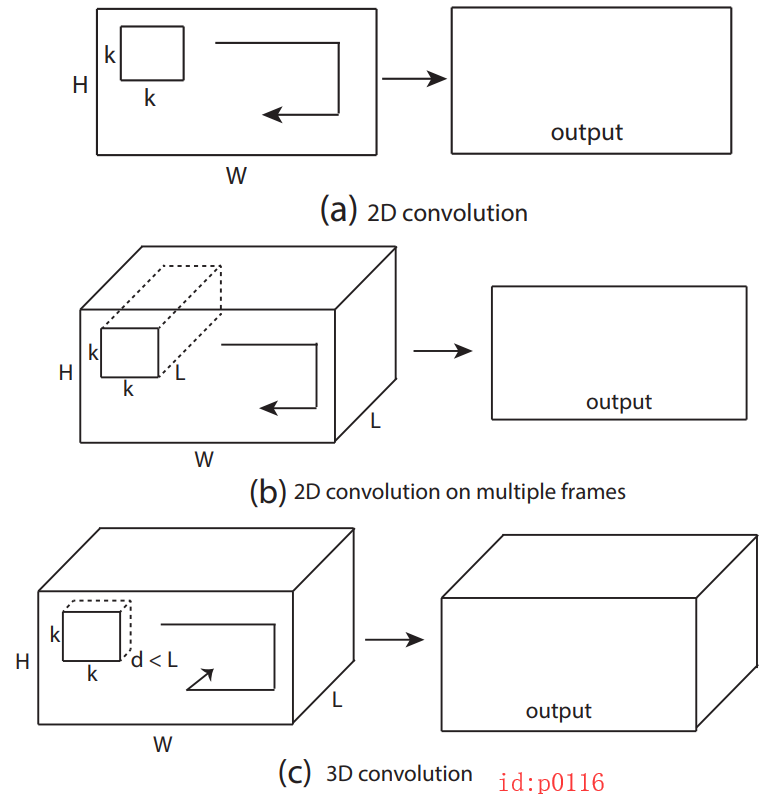
从图p0116中(只包含一个卷积核)我们可以看出,对于:
2D convolution: 使用场景一般是单通道的数据(例如MNIST),输出也是单通道,对整个通道同时执行卷积操作;
2D convolution on multiple frames: 使用场景一般是多通道的数据(例如cifar-10),输出也是单通道,对整个通道同时执行卷积操作;
2D卷积在执行时是在各自的通道中共享卷积核;
3D convolution: 使用场景一般是多帧(单/多通道)的frame-like数据(视频帧),且输出也是多帧,依次对连续k帧的整个通道同时执行卷积操作;
3D卷积在执行时不仅在各自的通道中共享卷积核,而且在各帧(连续k帧)之间也共享卷积核;
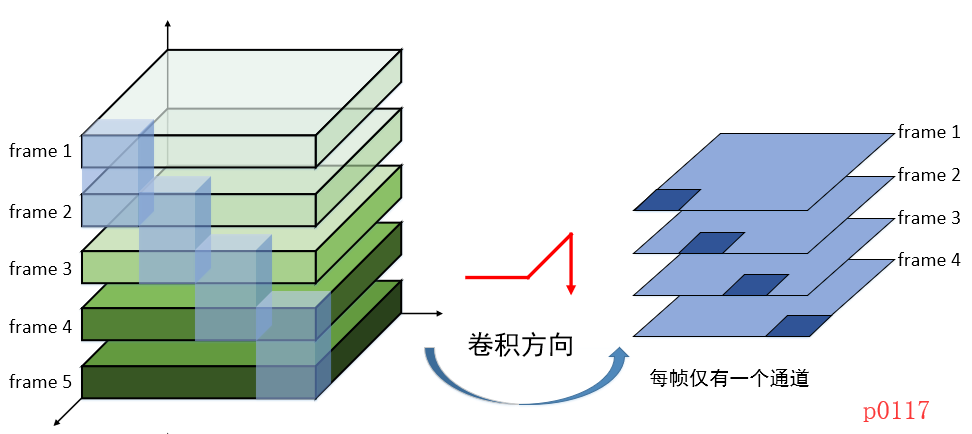
2. 计算角度
话说数无形时少直觉,形少数时难入微。在我们从视觉角度观察之后,我们再来从计算的角度看看3D卷积到底是怎么在工作。
假设现在有一个3帧的画面,且每一帧有2个通道,在时间维度的跨度为2帧,卷积核的宽度为3
- 我们首先再次从视觉的角度看看这个结果:
-
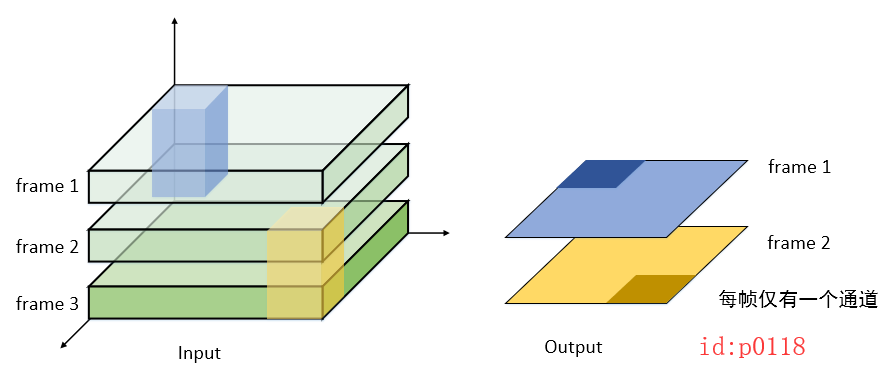
标题
计算结果:
由于在时间维度的跨度为2帧,且每帧有2个通道,所以从“矩阵”个数来看的话,我们的卷积核应该有4矩阵。
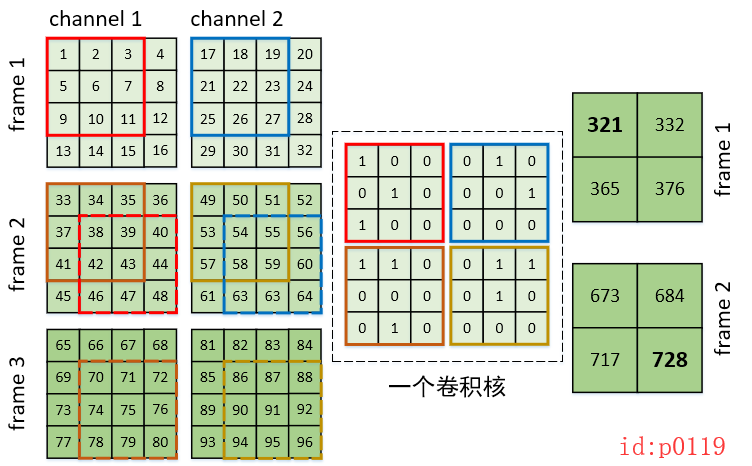
3. tensorflow示例
在知道3D CNN的原理之后,我们现在来看怎么用tensorflow提供的接口来实现上面的计算操作。首先根据上面的示例,我们有了下列参数:
输入数据:
- batch = 1;
- in_depth = 3; 序列长度
- in_channels = 2; 每一帧的通道数
- in_height = 4;
- in_width = 4;
卷积核:
- filter_depth = 2; 时间维度的连续跨度
- filter_height = 3;
- filter_width = 3;
- in_channels = 2; 输入时每帧的通道,必须核输入数据的通道一样
- out_channels = 1;卷积核的个数,对应的就是输出之后每帧的通道数
def conv3d(input, filter, strides, padding):
这是conv3d的接口,其主要接收4个参数:
input : 输入,其格式为[batch, in_depth, in_height, in_width, in_channels].
filter: 卷积核,其格式为[filter_depth, filter_height, filter_width, in_channels,out_channels]
strides: 移动步长[1,1,1,1,1]即可
padding: 是否padding
最后,其输出结果的格式同输入,也为[batch, in_depth, in_height, in_width, in_channels].
3.2 生成数据和实现
在介绍完接口后,只需要给定数据即可了。为了验证第二节中实验,我们下面先生成数据,然后再进行卷积。
生成数据:
image_in_man = np.linspace(1, 96, 96).reshape(1, 3, 2, 4, 4)
# [batch, in_depth, in_channels, in_height, in_width]
image_in_tf = image_in_man.transpose(0, 1, 3, 4, 2)
# [batch, in_depth, in_height, in_width, in_channels].
值得注意的是,为了查看我们生成的数据,我们将inchannels这个维度放在了第2个(从0开始)维度,因为这样看才直观(详见tf.nn.conv2d 你真的会用么),但在喂给conv3d是要转成其接收的格式
卷积核:
weight_in_man = np.array(
[1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0]).reshape(1, 2, 2, 3, 3)
# [out_channels,filter_depth, in_channels,filter_height, filter_width, ]
weight_in_tf = weight_in_man.transpose(1, 3, 4, 2,0)
# [filter_depth, filter_height, filter_width, in_channels,out_channels]
计算:
import tensorflow as tf
import numpy as np
image_in_man = np.linspace(1, 96, 96).reshape(1, 3, 2, 4, 4)
# [batch, in_depth, in_channels, in_height, in_width]
image_in_tf = image_in_man.transpose(0, 1, 3, 4, 2)
# [batch, in_depth, in_height, in_width, in_channels].
# shape:[1,2,4,4,2]
weight_in_man = np.array(
[1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0]).reshape(1, 2, 2, 3, 3) # 1,3,4,2,0
weight_in_tf = weight_in_man.transpose(1, 3, 4, 2, 0)
# [filter_depth, filter_height, filter_width, in_channels,out_channels]
# shape: [2,3,3,2,1]
print(image_in_man)
print(weight_in_man)
x = tf.placeholder(dtype=tf.float32, shape=[1, 3, 4, 4, 2], name='x')
w = tf.placeholder(dtype=tf.float32, shape=[2, 3, 3, 2, 1], name='w')
conv = tf.nn.conv3d(x, w, strides=[1, 1, 1, 1, 1], padding='VALID')
with tf.Session() as sess:
r_in_tf = sess.run(conv, feed_dict={x: image_in_tf, w: weight_in_tf})
# [batch, in_depth, in_height, in_width, in_channels].
print(r_in_tf.shape)
r_in_man = r_in_tf.transpose(0, 1, 4, 2, 3)
# [batch, in_depth,in_channels,in_height, in_width].
print(r_in_man)
结果:
[[[[[ 1. 2. 3. 4.]
[ 5. 6. 7. 8.]
[ 9. 10. 11. 12.]
[13. 14. 15. 16.]]
[[17. 18. 19. 20.]
[21. 22. 23. 24.]
[25. 26. 27. 28.]
[29. 30. 31. 32.]]]
[[[33. 34. 35. 36.]
[37. 38. 39. 40.]
[41. 42. 43. 44.]
[45. 46. 47. 48.]]
[[49. 50. 51. 52.]
[53. 54. 55. 56.]
[57. 58. 59. 60.]
[61. 62. 63. 64.]]]
[[[65. 66. 67. 68.]
[69. 70. 71. 72.]
[73. 74. 75. 76.]
[77. 78. 79. 80.]]
[[81. 82. 83. 84.]
[85. 86. 87. 88.]
[89. 90. 91. 92.]
[93. 94. 95. 96.]]]]]
[[[[[1 0 0]
[0 1 0]
[1 0 0]]
[[0 1 0]
[0 0 1]
[0 0 0]]]
[[[1 1 0]
[0 0 0]
[0 1 0]]
[[0 1 1]
[0 1 0]
[0 0 0]]]]]
(1, 2, 2, 2, 1)
[[[[[321. 332.]
[365. 376.]]]
[[[673. 684.]
[717. 728.]]]]]















 1592
1592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









