










目录
在当前人工智能的快速发展时代,🤗 Transformers库成为了众多开发者和数据科学爱好者的宝贵工具。它不仅简化了使用预训练模型的过程,还提供了一个易于使用的接口来进行复杂的自然语言处理、计算机视觉和音频处理任务。无论你是一名开发人员还是日常用户,只要对机器学习有所涉猎,本文将带你快速了解如何启动并运行🤗 Transformers。
准备工作:安装必要的库
在深入探索Transformers之前,首先需要确保你的工作环境中安装了所有必要的库。这一步骤对于接下来顺利运行示例代码至关重要。安装这些库的过程极其简单,只需在你的Python环境中执行以下命令:
pip install transformers datasets
这条命令将会安装Transformers库及其依赖的datasets库,后者是一个轻量级、易于使用、以及高度优化的库,用于处理和加载数据集。
选择你的机器学习框架
Transformers库设计之初就考虑到了灵活性,支持两大流行的机器学习框架:PyTorch和TensorFlow。因此,根据个人偏好或项目需求,你还需要安装相应的机器学习框架。如果你倾向于使用PyTorch,可以通过以下命令安装(这里建议使用pytorch,因为后续我发布的文档都是使用pytorch框架去做测试):
pip install torch
安装这些库不仅是开始使用Transformers的前提,也将为你日后的机器学习项目奠定基础。这一步完成后,你就可以愉快地开始探索Transformers提供的强大功能了。
Transformers库中的pipeline()功能是使用预训练模型进行推理任务的最简单快捷方式。这一功能的设计目的是为了让用户能够轻松地应用多种不同模态的预训练模型,以完成各种自然语言处理(NLP)、计算机视觉和音频处理任务,而无需深入了解模型的内部工作原理。下面,我们将围绕pipeline()的使用场景,对其功能和应用领域进行详细的介绍。
不同任务的Pipeline
pipeline()能够处理的任务范围广泛,涵盖了文本、图像、音频和多模态等不同的数据类型。以下是一些常见任务及其对应的pipeline标识符:
- 文本分类(Text classification): 给定文本序列,为其分配一个标签。例如,情感分析(
sentiment-analysis),可用于判断文本的情绪倾向。 - 文本生成(Text generation): 给定一个提示(prompt),生成文本。这可以用于自动创作故事、文章或者对话生成(
text-generation)。 - 摘要生成(Summarization): 为一段文本或文档生成摘要(
summarization),这对于快速理解长文章的主要内容非常有用。 - 图像分类(Image classification): 为图像分配一个标签(
image-classification),用于识别图像中的对象或场景。 - 图像分割(Image segmentation): 对图像中的每个像素分配一个标签,支持语义、全景和实例分割(
image-segmentation),常用于医学图像处理和自动驾驶等领域。 - 对象检测(Object detection): 预测图像中对象的边界框和类别(
object-detection),在视频监控和零售分析中有广泛应用。 - 音频分类(Audio classification): 为音频数据分配一个标签(
audio-classification),可用于声音场景识别或音乐类型分类。 - 自动语音识别(Automatic speech recognition): 将语音转换为文本(
automatic-speech-recognition),这是虚拟助手和语音用户界面的基础。 - 视觉问题回答(Visual question answering): 给定一幅图像和一个问题,返回关于该图像的答案(
vqa),是多模态交互的一个例子。 - 文档问题回答(Document question answering): 针对给定的文档和问题,提供答案(
document-question-answering),用于自动化客户支持和信息检索。 - 图像标题生成(Image captioning): 为给定图像生成一个描述性文字(
image-to-text),增强图像内容的可访问性和理解。
使用Pipeline
使用pipeline()非常直观,你只需指定任务类型,它就会自动下载并加载相应的预训练模型和预处理器。例如,若要进行情感分析,只需几行代码:
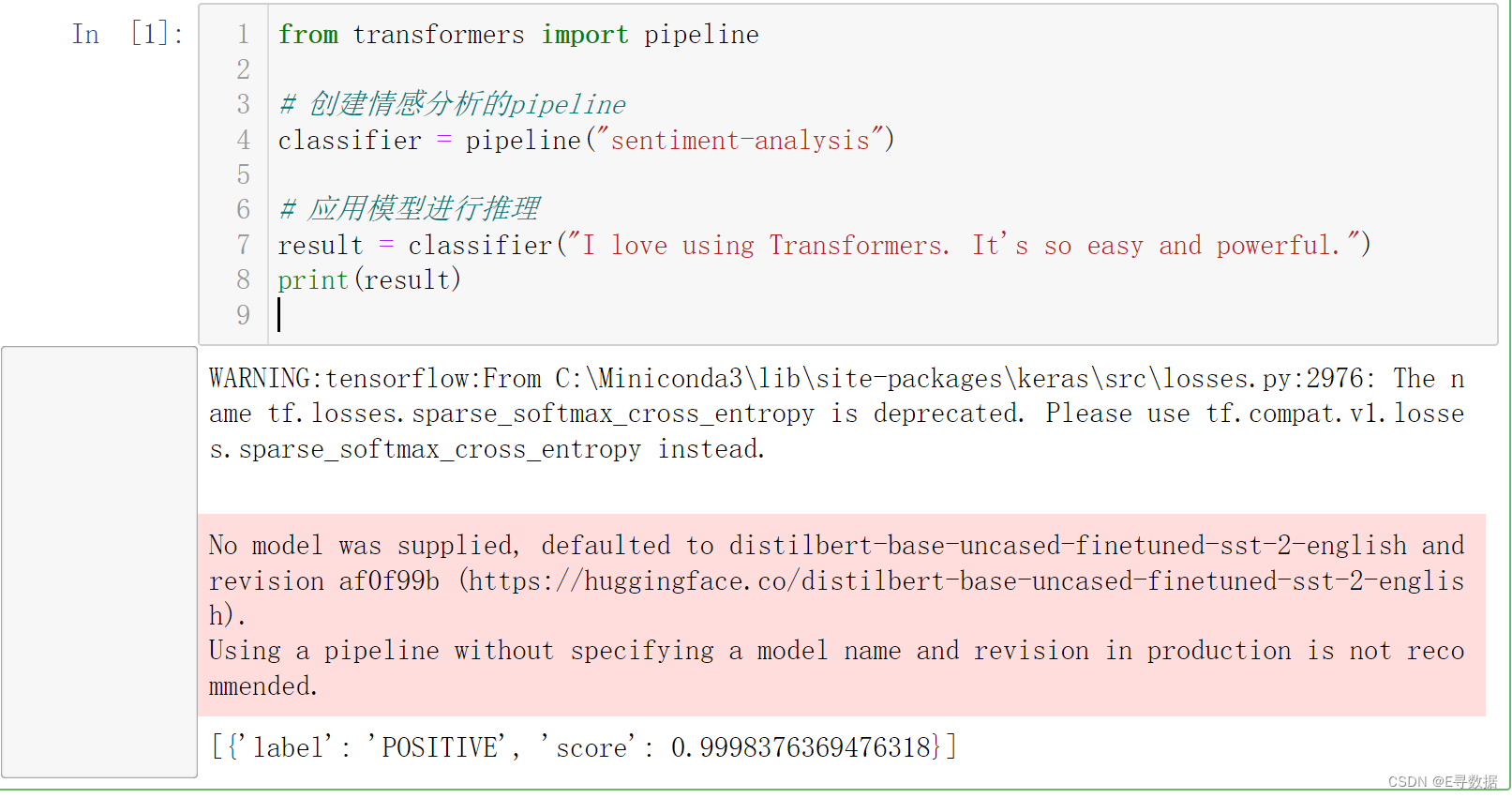
from transformers import pipeline
# 创建情感分析的pipeline
classifier = pipeline("sentiment-analysis")
# 应用模型进行推理
result = classifier("I love using Transformers. It's so easy and powerful.")
print(result)
这将输出文本的情绪倾向及其置信度,如[{'label': 'POSITIVE', 'score': 0.9999}]。
这样我们就能很快的部署一个文本分类任务,根据上面的提示换成指定的字符。就可以快速的做出很多高水平的任务。想想就激动。输出效果如下:



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











