







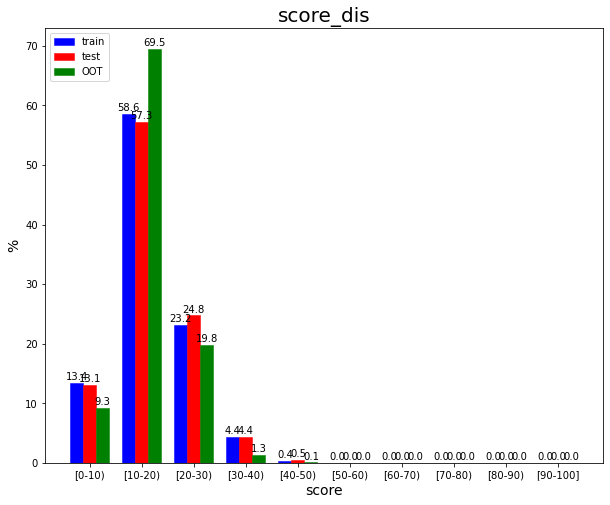
建模样本分数分布matplotlib,结合psi判断模型拟合程度
画此图的目的是除了ks和auc指数,结合建模样本和OOT样本的psi,利用分数分布图进行比较,判断模型拟合程度。
psi计算
def multi_psi_for_continue_var(expected_frame, actual_frame, bins=10, bucket_type='bins', detail=False,
save_file_path=None):
col_list = expected_frame.columns.tolist()
if detail == True:
psi_value = []
for i in col_list:
expected_array = expected_frame[i]
actual_array = actual_frame[i]
_psi = psi_for_continue_var(expected_array, actual_array, bins=bins, bucket_type=bucket_type, detail=detail,
save_file_path=save_file_path)
if not isinstance(_psi, int):
_psi['col_name'] = str(i)
print(i)
psi_value.append(_psi)
else:
print(i)
psi_all = pd.concat(psi_value, sort=False)
elif detail == False:
psi_value = {}
for i in col_list:
expected_array = expected_frame[i]
actual_array = actual_frame[i]
_psi = psi_for_continue_var(expected_array, actual_array, bins=bins, bucket_type=bucket_type, detail=detail,
save_file_path=save_file_path)
psi_value[i] = _psi
psi_all = pd.DataFrame(psi_value, sort=False)
return psi_all
分数分布图
def score_distribution_plot(data,title,label=None,perc=False):
'''
----------------------------------------------------------------------
功能: 画出单个项目分数分布图
----------------------------------------------------------------------
:param data: numpy array of score by model,模型分数
:param title: str of title,图标题
:param perc: bool,取值为True时分数为百分制,False时为1分制
----------------------------------------------------------------------
'''
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
def score(x):
if x >=0 and x<10:
return '[0-10)'
elif x>=10 and x<20:
return '[10-20)'
elif x>=20 and x<30:
return '[20-30)'
elif x>=30 and x<40:
return '[30-40)'
elif x>=40 and x<50:
return '[40-50)'
elif x>=50 and x<60:
return '[50-60)'
elif x>=60 and x<70:
return '[60-70)'
elif x>=70 and x<80:
return '[70-80)'
elif x>=80 and x<90:
return '[80-90)'
elif x>=90 and x<100:
return '[90-100]'
x_laybel = ['[0-10)','[10-20)','[20-30)','[30-40)','[40-50)','[50-60)','[60-70)','[70-80)','[80-90)','[90-100]']
data = pd.DataFrame(data)
#判断分数是否为*100形式,默认否
if perc == False:
data = data*100
dt1 = []
for i in data.index.values.tolist():
dt1.append(score(data.iloc[i][0]))
dt1 = pd.DataFrame(dt1)
dt2 = pd.DataFrame(columns=['[0-10)','[10-20)','[20-30)','[30-40)','[40-50)','[50-60)','[60-70)','[70-80)','[80-90)','[90-100]'],data=[[np.sum(dt1[0].values=='[0-10)'),np.sum(dt1[0].values=='[10-20)'),np.sum(dt1[0].values=='[20-30)'),np.sum(dt1[0].values=='[30-40)'),np.sum(dt1[0].values=='[40-50)'),np.sum(dt1[0].values=='[50-60)'),np.sum(dt1[0].values=='[60-70)'),np.sum(dt1[0].values=='[70-80)'),np.sum(dt1[0].values=='[80-90)'),np.sum(dt1[0].values=='[90-100)')]])
#计算各分段占比
dt3 = pd.DataFrame(dt2.apply(lambda x:x*100/len(dt1)))
plt.figure(figsize=(10,8))#设置画布的尺寸
plt.title(title,fontsize=20)#标题,并设定字号大小
plt.xlabel(u'score',fontsize=14)#设置x轴,并设定字号大小
plt.ylabel(u'%',fontsize=14)#设置y轴,并设定字号大小
width_val = 0.7 #若显示 n 个柱状图,则width_val的值需小于1/n ,否则柱形图会有重合
#alpha:透明度;width:柱子的宽度;facecolor:柱子填充色;edgecolor:柱子轮廓色;lw:柱子轮廓的宽度;label:图例;
plt.bar(dt3.columns.values,dt3.iloc[0,:], alpha=1,width = width_val, facecolor = 'blue', edgecolor = 'blue', lw=0.5, label=label)
#标注数据
for x,y in enumerate(dt3.loc[0,:]):
plt.text(x, y+0.5, '%s' %round(y,1), ha='center')
plt.legend(loc=2)#图例展示位置,数字代表第几象限















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









