







系统稳定通常指某项指标波动小(低方差),指标曲线几乎是一条水平的直线。此时系统运行正常稳定。
在数学上可用变异系数(Coefficient of Variation,CV)来衡量这种数据波动水平。变异系数越小,代表波动越小,稳定性越好。
变异系数的计算公式为:变异系数 C·V =( 标准偏差 SD / 平均值Mean )× 100%
在机器学习建模时假设“历史样本分布等于未来样本分布”。因此认为:
模型或变量稳定 <=> 未来样本分布与历史样本分布之间的偏差小。
实际中受到客群变化(互金市场用户群体变化快)、数据源采集变化(比如爬虫接口被风控了)等等因素影响,实际样本分布将会发生偏移,就会导致模型不稳定。
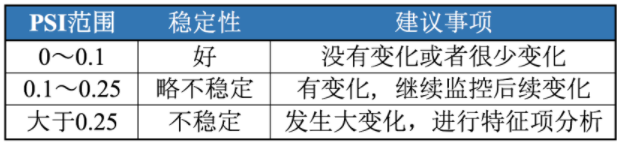
PSI反映了验证样本在各分数段的分布与建模样本分布的稳定性。
在建模中常用来筛选特征变量、评估模型稳定性。
稳定性是有参照的,因此需要有两个分布——实际分布(actual)和预期分布(expected)。
在建模时通常以训练样本(In the Sample, INS)作为预期分布,而验证样本通常作为实际分布。

与IV值计算公式很类似。
PSI数值越小,两个分布之间的差异就越小,代表越稳定。
当两个随机分布完全一样时,PSI = 0;反之,差异越大,PSI越大。
相对熵(relative entropy)又称Kullback-Leibler散度(Kullback-Leibler divergence)或信息散度(information divergence),
是两个概率分布间差异的非对称性度量——KL散度不满足对称性。

在信息理论中,相对熵等价于两个概率分布的信息熵(Shannon entropy)的差值;
KL散度是单向描述信息熵差异;KL散度不是距离,其不满足对称性和三角不等式。

PSI本质上是实际分布(A)与预期分布(E)的KL散度的一个对称化操作。
x 代表 X 的每一个取值,则
由公式可知,K-L散度其实是数据的分布 P 和分布 Q 之间的对数差值的期望,也表示 P 和 Q 间信息损失的二进制位数。
由上式变换:

前一部分就是 P(x)的熵,后一部分就是交叉熵![]()
在深度学习中,需要使用K-L散度评估 labels 和 predicts 间的差距 ;

前一部分 -H(ylabels) 不变,故在优化过程中只需要关注交叉熵 CE 即可。一般在深度学习中直接用交叉熵做Loss,评估模型。也可以直接把交叉熵理解为判断两个分布相似性的依据,本文则进一步解释了交叉熵的由来,即交叉熵是由相对熵(K-L散度)衍生出来的。















 1889
1889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









