







文章目录
面向对象四特征:抽象、封装、继承、多态
1.抽象
UML类图:图像分三层:类名、成员变量、成员函数
定义一个类=定义成员变量+成员函数
类=结构体+行为
类只是一个描述,而对象是内存中真实存在的
类里面有两个特殊的成员函数:构造函数与析构函数
构造:this->n=n
析构:~A()
2.封装
public、protected、private
3.继承
同名函数就近原则
虚函数直接覆盖
4.多态
虚函数+指针实现多态。父类指针调用子类重写的虚函数即可
父类指定要做什么,子类实现具体做法
















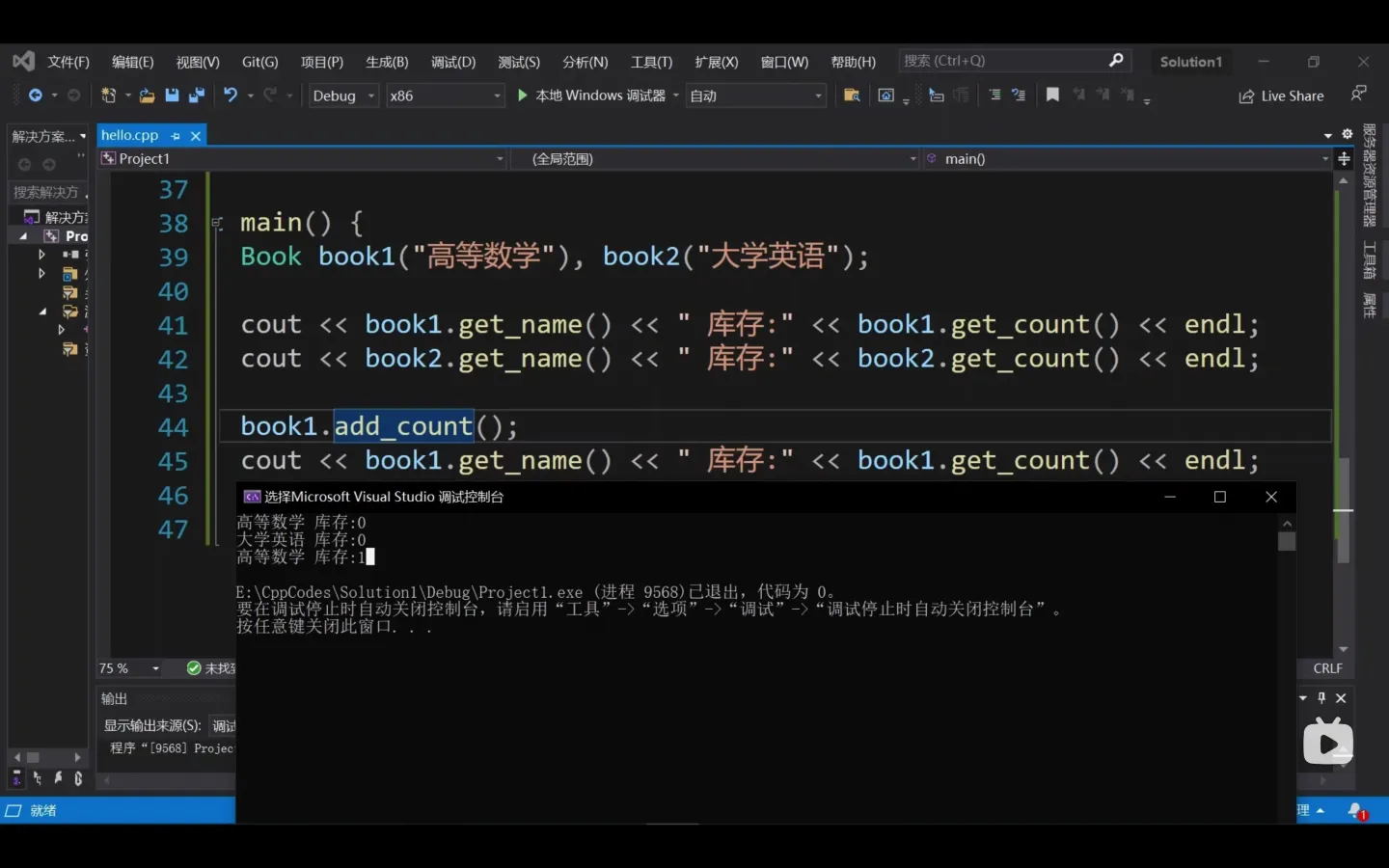


































1:命名空间、输入输出、常量、重载、模板
C是C++的子集,C++是既支持面向对象又支持现象过程的混合型语言
C++特色:抽象、封装、多态、继承
关于 #include
#include <...> // 尖括号写的是 C++ 自带的。编译器会去 include 目录进行搜索
#include "..." // 一般自己写的。编译器首先到当前工作目录中去查找,再去 include 目录寻找
namespace
- STL 中的东西都是在 std 中声明的,使用类等之前需要指明其所在的命名空间。
using namespace std; // 整个都用 std
using std::cout; // 有且只有 cout 可以直接写出来而不用带命名空间
using std::cin; // 同上
- 命名空间可防止重名冲突
命名空间的定义和使用
namespace ns1 { // declear
int inflag;
void g(int);
}
namespace ns2 {
int inflag;
}
//-------------------------
ns1::inflag = 2; // use
ns2::inflag = 1;
//-------------------------
using ns1::inflag;
inflag = 666; // in ns1
ns2::inflag = 123; // in ns2
ns1::g(123); // call. namespace required.
//-------------------------
using namespace ns1;
g(456); // call. without namespace, for having using above.
C++也可以用没名字的命名空间。
这样的空间中的内容无法在其他文件中进行访问,只能在本文件中使用——从声明处开始直到其所在源文件结束处。
int i = 666;
namespace {
int i = 123;
}
int main () {
cout << i;
}
// 会报错,【多重定义】
CPP 输入输出
cout<< 输出
cout 是一个输出流类的对象,“输出流”指的是从内存向输出设备流动的数据流。cout做的事情就是将要输出的数据插入到输出流对象中。也被称为“插入操作”。
cout<<exp1<<exp2<<...<<endl; // endl,换行。"<<"是“输出运算符”或“插入运算符”
cin>> 输入
cin 会识别空格作为结束标志
标准输入流对象。输入流是从输入设备流向内存的数据流。
cin是从输入流对象中提取数据,也称为“提取操作”。
cin>>var1>>var2>>...<<varn; // “>>”:“输入运算符”/“提取运算符”
使用 const 定义常量
C 中使用宏替换来定义常量。
定义使用 #define 进行,在预编译时进行字符置换,又称“宏替换”
#define PI 3.14
预编译是将C++代码转化为机器代码的第一个步骤。对于上面这行代码,这里的工作之一就是将代码中所有写作“PI”的字符全都换为 3.14,然后再进行后续的编译步骤
C++ 使用 const 定义常量
const <datatypeName> <constName> = <expression>; // 常量在定义时进行初始化
const int maxLine = 1000; // 初始化是常量赋值的唯一方式
// 下面这种在声明之后赋值的操作是错误的.
const int maxLine;
maxLine = 123;
#define VS const
-
#define 无类型,const 有;
-
一些 IDE 仅能检查、调试 const;
-
使用 #define 可能出现奇怪的错误,如:
#define pow a+b pow*pow; // 被换成 a+b*a+b,显然与设想不符
函数原型声明
若进行函数调用的位置在该函数定义位置之前,则须在调用前进行函数声明。
// 函数类型 函数名 (参数类型 [参数名称], ...)
函数重载
在同一作用域中使用同一函数名定义多个函数。这些函数的参数类型和个数(至少有一个)不同。只有返回值类型不同并不可以。
int add(int a, int b);
double add(double a, double b);
函数模板
引入 template 的目的在于:解决大量使用重载时,会产生大量类似的多余代码的问题。
适用于函数体相同、函数参数个数相同、类型不同的情况。
template<typename T 或 class T> // T 是类型名
template<typename T>
T max(T a, T b) {
return (a>b)?a:b;
}
函数模板不是确定的函数,编译器不会将模板本身变成指令。
编译器遇到与模板匹配的函数调用时,自动生成一个专用的重载函数,该函数的函数体与函数模板相同,但涉及类型的部分都被改变了。
例如:
int max(int a, int b) {
return (a>b)?a:b;
}
这是一个“模板函数”,意为"从模板产生的函数",是函数模板的一个实例,只能处理一种类型的数据。
函数模板是模板,模板函数是函数。
使用多个类型的参数
// template <class T1, class T2, class T3>
template<class T1, class T2>
T1 max(class T1, class T2) {
return (a>b)?a:(T1)b; // 返回时需要对 b 进行类型转换
}
2:引用、内联、动态分配内存
函数默认参数
如果想要给函数设定一个默认的参数,可以像下面这么写
int area(int a=6) {
...;
}
area(7); // 若调用中含参数,那参数传什么就是什么
area(); // 若调用中没写参数,就使用默认参数,这一行等效于 area(6)
实参与形参的结合是从左到右进行的,所以,指定默认值的参数必须在形参列表的最右端(以解决调用时省略参数的情况,防止参数串位)
int max(int a, int b=6, int c=123); // ok
int max(int a=1, int b, int c=123); // 这样布星
**推荐:在函数声明的时候就给出默认值,定义时不再给出。**不同编译器对默认值处理不同,可能由于声明、定义时都给出了默认值而报错,也可能支持声明和定义中使用不同的默认值(以先遇到的默认值为准)
重载函数和默认参数函数共同使用时可能出现二义性问题。
int max(int a, int b=6);
int max(int a);
引用(Reference)
基本用法
可以给变量起别名(alias),该别名就是变量的引用
<类型> &<引用变量名> = <原变量名> // &:引用声明符。表示后面的时引用变量名。原变量名需要是定义过的
例:
int max;
int &refMax = max; // refMax 就是 max 的别名。引用需要在定义时进行初始化
refMax = 123; // 用法和普通变量相同,也可以别名、原名混着用
max = 666;
int &refRefMax = refMax; // 可以进行引用的引用
refMax 和 max 在内存中处于同一地址。就只是两个名字指向了同一个地址。
引用声明后,不能再重新赋值、指向其他变量。
引用是有地址的,可以像使用普通变量一样用
int a, *p;
int &m = a; // &前面有类型就是引用的声明,没有的话就是取地址符
p = &a;
*p = 10; // a 的值就被修改为 10 了
对 const 的引用
int i=5;
const int &a = i; // a是一个引用,还是一个const。a称为【常引用】
a = 3; // 错误,a 是一个常量,其值不能被修改
i = 3; // 合法,因为 i 是个普通变量。这时再访问 a 得到的结果也是 3
几种非法声明
void &a // 引用需要引用一个已存在的变量,而并没有 void 类型的变量存在
int &a[6] = c; // c是一个数组名,本质是指向数组首元素的地址
int &*p = &a;
指针与引用的区别
- 指针是通过地址间接访问某变量,引用是通过别名直接访问某变量;
- 引用必须初始化,初始化后不能再称为其他变量的别名。
引用与函数
cpp 中很少使用独立变量的引用。引用主要用于 函数参数、函数返回值。
-
把变量的引用作为形参来调用函数
void swapint(int &a, int &b) { // a、b 就是实参 i、j 的引用了。初始化在调用时进行。 int tmp; tmp = a; a = b; b = tmp; } int main() { int i=3, j=5; swapint(i, j); // 执行完,i=5, j=3 return 0; }
引用形参 vs 指针形参:前者实参是变量,后者是地址,且后者需要单独创建空间用来保存指针
将引用类型作为函数的返回值
将函数的返回值定义为引用类型时,由于返回的是一个变量的别名,故这种情况下这样的函数可以作为左值。
int a = 4;
int &f(int x) {
a = a + x;
return a; // 返回的是 a 的引用
}
int main() {
int t = 5;
cout<<f(t)<<endl; // a=9.
f(t)=20; // 先调用,再赋值。 a=20.
return 0;
}
注意:返回引用类型的函数,必须返回某个类型的变量;返回的变量的引用,变量必须是全局变量 / 静态局部变量,即存储在静态区的变量
int &f(int &x) {
static int t=2; // 返回的变量的引用是局部静态变量
t=x++; // 先将 x 赋值给 t ,再 x++
return t;
}
int main() {
int a=3;
cout<<f(a)<<endl; // output:3, a=4, t=3
f(a)=20; // a=5, t=20
a+=5; // a=10
cout<<f(a)<<endl; // output:10, a=11, t=10
a=f(a); // a=11, t=11
cout<<f(a)<<endl; // output:11, a=12, t=11
return 0;
}
内联函数(inline)
被频繁调用的函数,可通过内联来提升性能(空间换时间)。
内联函数会在编译时被嵌入到函数调用处,以减少程序运行时频繁调用函数造成的资源开销(保护现场、断点地址入栈、跳转到被调用函数所在的内存地址执行,执行后从堆栈取断点地址跳回,继续执行)
直接在普通函数定义前加 inline 关键字即可
必须写在函数定义体前。声明前可加可不加,只在声明前加上是无效的。
调用内联函数时,编译器检查调用是否合法,然后将内联函数的代码直接替换掉函数调用代码,并用实参换形参。
内联需要慎重使用,函数体内出现循环、递归等复杂控制语句时不适合使用内联。另,编译器会根据函数的函数体来自动取消不值得的内联(内联,相当于对编译器的建议,而非绝对的指令)。
作用域运算符
float a = 1.23;
int main() {
int a = 111;
cout<<a<<" "<<::a<<endl; // 输出:111 1.23, ::a 是使用全局作用域中的变量 a
...
}
string
string2 = string1; // 赋值
string1 = string1 + string2; // 连接
string name[3] = {"...", "...", "..."}; // 字符串数组
动态分配/撤销内存(new/delete运算符)
new
new 从堆中分配一块空间,成功则将起始地址存入指针变量
<指针变量名> = new <类型>; // 想要啥样的类型就填啥。。
<指针变量名> = new <类型>(<初值>); // 要的变量的值
<指针变量名> = new <类型>[<元素个数>]; // 分配连续的空间,即数组
delete <指针变量名>
delete[] <指针变量名> // 释放连续的存储空间,即数组
动态整数存储空间
int *p = new int; // 用整型的指针指向这个空间
delete p;
int *p = new int(3); // 整数初始值为 3
delete p;
int *p; // 这里是没有办法动态确定数组长的
int pLength;
cin>>pLength; // 获取用户输入的数组长度
p = new int[pLength]; // 连续存储空间(数组空间),p 指向这个数组的首地址
delete[] p; // 这样就释放掉了,空中括号就是说明要释放的是数组空间
3:类、对象、构造函数、析构函数
软件开发与面向对象
好软件应该有的特点
可重用、可扩展(容易在现有基础上创建新的子系统)、可维护性(能适应需求的变化)
开发思想和方法
面向过程
-
按照功能划分软件结构——确定整个系统的输入输出,再把中间过程分为一个个小的子系统,每个子系统也都是有着输入输出的,把这些部分连接起来就是整个系统。
-
以函数作为主体,整个程序耦合程度高。
面向对象
- 将软件系统看作对象的集合;
- 系统结构相对稳定。“对象”相对于“功能/过程/函数”而言变化更少;
- 对象能够把函数的定义进行封装;
- 提高软件可重用性、可维护性、扩展性。
抽象
抽象的重点在于提取一个实体的本质,即对复杂的事物进行本质的提取和简化。
抽象过程抽象出的特征等,应该都是与系统相关的。一个抽象越简单,就越通用。
一个实体,会有许多可能的抽象的方式。需要注意根据实际需求进行针对性的抽象。
抽象所拥有的属性和行为,不应超出一开始定义的目的。
类的抽象和定义
对象,是具体事物的抽象。
对象是将状态(数据/属性)和行为(行为/操作/函数)捆绑在一起的软件结构或模块。也就是说,对象,是确定了属性值的,类的实例。
类,是对具有相同特征的对象的进一步抽象。
类是描述一组相似对象共有特征的抽象。类可以控制其中变量和函数在外部的可见性——即,可以设置某些变量/函数只有在该类对象内部可以访问——这样可以提升程序的安全性。
从类创建对象的过程被称为“实例化”。
从一个类实例化的不同对象具有相同的结构,但可以有不同的数据值。
类的 UML 表示法

+ : public
- : private
# : protected
访问权限控制
public、private、protected,三者可以多次出现。一般来说前两者写在类的前面。
在一个类的外面,只能访问公有(public)的成员。
私有成员只能被本类中的函数访问和友元函数访问,在类外不可见。
保护成员,对该类的派生类(即,继承了该类的子类)而言,和public的一样,对其他的则和private一样。
成员
- 数据成员不能在类体内部进行显式初始化,比如 int number = 1。初始化通过构造函数(构造器)初始化。
- 成员函数的声明和原来一样。他们应该是对进行了封装的(private里面的)数据进行操作的唯一途径。成员函数可以在类内或类外进行定义。在类内定义的函数将自动成为内联函数。
多文件类的定义(构造、析构函数见本页尾)
//time.h
class Time {
public:
Time(int newH, int newM, int newS = 10);// 参数可有可无可默认,构造器可重载
// 默认值需要在声明时添加
~Time(); // 析构函数没有参数,不能被重载。
void setTime(int newH, int newM, int newS);
void showTime();
private:
int hour, min, second;
};
// time.cpp
#include "time.h" // 需要包含声明的文件
// 使用函数体进行初始化
Time::Time(int newH, int newM, int newS) {
hour = newH;
min = newM;
second = newS;
}
// 使用初始化列表进行初始化
Time::Time(int newH, int newM, int newS): hour(newH), min(newM), second:(newS) {}
Time::~Time(...) {
...
}
void Time::setTime(int newH, int newM, int newS) {
hour = newH;
min = newM;
second = newS;
}
void Time::showTime() {
...
}
// 实例化对象(会使用到无参构造器)时的写法:
Time myTime1;
// 实例化对象(有且仅有带参数构造器)时的写法:
Time myTime(...);
创建对象
<类名> <对象名表>;
在创建时才会分配存储空间,类仅仅是类型的定义。
对象名表,可以声明成为指针、引用名、对象数组。
对象的UML
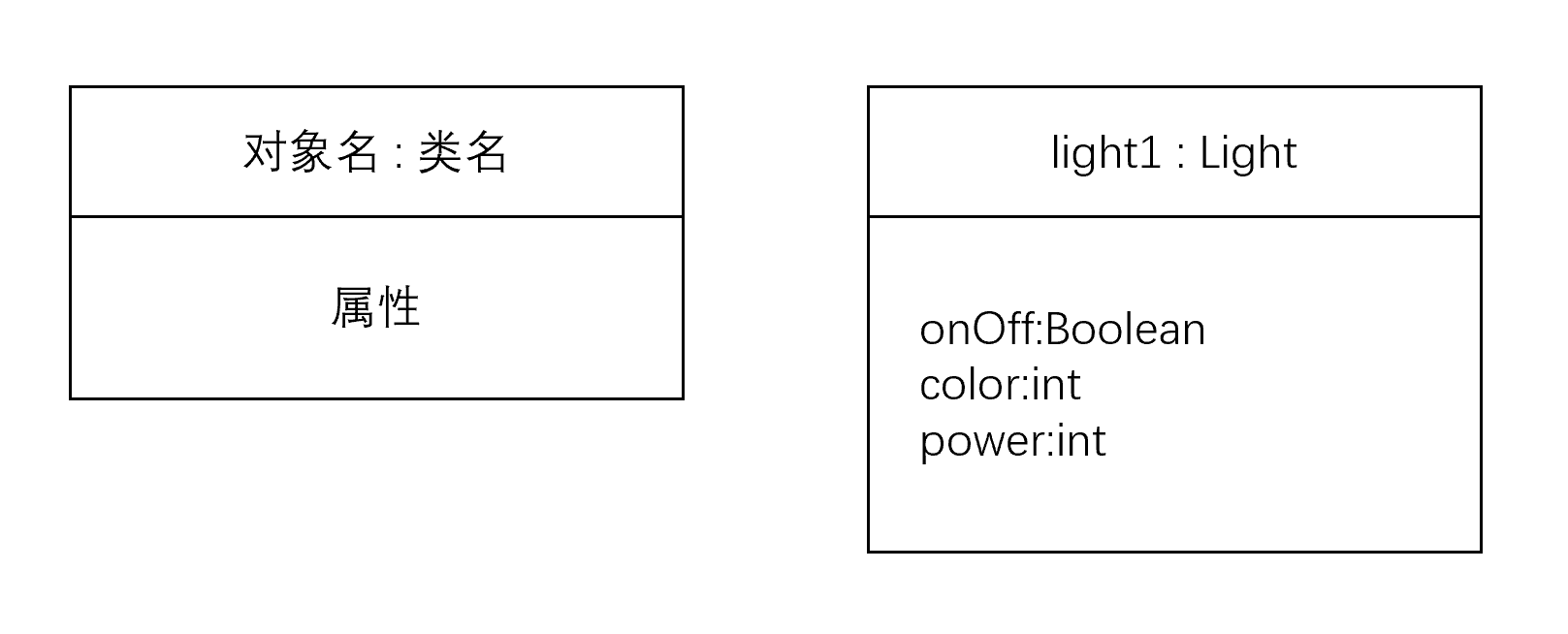
类成员的访问
- 可以通过对象来直接访问公有成员;
- 类中可以直接使用成员名来访问所有成员;
- 对象名和成员名访问:例:Time.showTime();
- 通过对象指针变量访问:例:TimePtr->showTime();
- 通过引用访问。
各个对象空间中只有数据成员。成员函数只存在一份,由所有对象共享。
构造函数、析构函数
构造函数、析构函数
构造函数在实例化时自动调用,按照我们定义的过程来自动进行初始化;析构函数在对象生命周期末端自动调用,按照我们定义的过程执行清除工作。在没有给变量初始化时,其中的值是随机的。
构造函数,在定义对象时,被编译系统自动调用,创建并初始化对象。
对于没有构造器的类,编译系统会准备一个默认的无参构造函数,该函数体为空,什么也不做。
对于显式定义了带参数构造函数的类,编译系统不会自动加上那个默认的无参构造函数。如果不调用这样的写法会报错。
- 析构函数只是在生命周期末端完成一些清理工作,并不会回收空间。这个空间应该是系统管理释放。析构函数不能有参数,因此也不能被重载;
- 一般,构造函数的调用顺序与声明对象的顺序相同,析构函数则相反;
构造、析构函数调用时机
全局对象的构造函数在所有函数(包括main)执行前调用,main执行结束或调用exit时调用析构函数;
局部自动对象:实例化时构造,函数调用结束、对象释放时先调用析构器;
函数中的静态局部对象:第一次调用其所在函数时调用构造器构造,调用结束不释放,直到main执行完或调用exit时才调用析构器。
复制(拷贝)构造函数
复制构造器的名字与类名相同,不指定类型,只有一个参数且是对同类对象的引用。
-
对象可以进行赋值和复制
-
赋值:两个同类的、已存在的对象,可以进行赋值。这样的赋值是整体进行的,与访问权限无关。
<对象1> = <对象2>; -
复制:建立一个新对象,并让它和原有对象一样
<类名> <对象2>(<对象1>); <类名> <对象2> = <对象1>;若未定义复制构造函数,这样就是“默认按成员初始化”。
<类名> (const <类名>& <对象名>); // 声明复制构造函数 // 这里的&表示引用,对后面的对象参数进行引用 // 总而言之,这是一个指向同类对象的常引用 <类名>::<类名> (const <类名>& <对象名>) { // 实现 ... }用例:
TAdd(const TAdd& p) { x = p.x; // 这里可以定义自己的复制逻辑 y = p.y; cout<<"复制构造器"<<endl; }系统默认的复制构造函数,就是做单纯的一对一拷贝。
-
-
使用复制构造器的情况
// 1. 直接的复制使用,略。 // 2. 函数用对象作为参数,在调用时需要把实参完整地传递给实参 void func(Box b) { ... } int main() { ... Box box1(1, 3, 5); func(box1); // 系统会进行从box1(实参)到b(形参)的复制,这里就自动调用复制构造器 ... } // 3. 函数的返回值是对象,函数调用结束要把返回值带回调用处 Box func2() { Box box1(1, 2, 3); return box1; } int main() { Box box2; box2=func2(); /* 其实在调用时,box1 先被复制到了一个临时对象中, 然后再被赋值给了box2。这里调用的都是复制构造器。 */ return 0; }
4:通过 static 实现对象间的数据共享;对象指针
静态成员
同一个类的不同对象,可以访问相同的静态成员变量、静态成员函数。
与静态成员相对的,非静态成员又被称为实例属性,它们的值是每个对象所特有的。
用static关键字声明的静态成员的属性则是被所有同类对象共有的类属性。
**静态成员不会在每个对象内部占用空间。**其空间在程序编译时进行分配,在整个程序中只存在唯一的地址(独立于任何对象),由所有对象共享访问。生命周期与程序本身相同。
静态成员可以在类不实例化的情况下进行访问。
static int a; // 这么声明就ok了
静态成员的初始化
静态成员只能在类体外初始化。
但是可以在类的函数中(包括构造器等)进行重新赋值等。
class Student {
...
static int stuNumber; // 某类东西的数量,这种东西值得各个对象共享
...
};
...
int Student::stuNumber = 0; // 需要指出类型,不能加 static
静态成员的使用
类的函数可以直接访问,无需指明使用哪一个(即无需作用域说明)
在类外访问,必须使用成员访问运算符(.)或作用域运算符(::)
cout<<Student::stuNumber; // 没有实例也可以用
cout<<stu1.stuNumber; // 这样也行
静态成员可以有权限限制
只有 public 的才可以在类外直接访问
静态成员函数
即,加了 static 声明出来的函数。其可以处理静态数据成员,但不能直接访问非静态成员。
如果想要访问非静态成员,需要通过参数传递方式得到对象名,然后通过对象名访问该对象的动态成员。
没有 this 指针。
// 访问非静态成员
class Student {
static void showInfo(Student stu) {
cout<<a<<stu.b; // 静态的直接引用,非静态的需要加上对象名
}
static int a;
int b;
};
int main() {
Student stu1;
...
Student::showInfo(stu1); // 这样把一个对象传过去就能访问了
...
}
对象指针
对象指针,指向对象所在内存的起始地址。
<类名> *<对象指针名> = &<对象名>; // 声明和初始化赋值。与普通指针相同
<指针名> -> <public成员名>; // 访问
(*<对象指针名>).<public成员名> // 访问
用对象指针作为参数
Student inputInfo(Student *stu) {
string name;
cin>>name;
stu->name = name;
return *stu; // 返回指针所指向的对象
}
5:动态对象、this指针、成员指针、对象引用、常对象、类模板
动态对象
new <类名>; // 申请成功会返回一个指向对象的指针
new <类名>(<参数列表>); // 自动调用带参构造器
delete <指向对象的指针名>; // 手动释放对应对象的内存空间
Student *stuPtr = new Student;
delete stuPtr;
this指针
该指针是一个隐含指针——隐含在每一个成员函数中(除静态的)——每一个成员函数都有一个。
其指向调用该函数的对象——即,值为当前函数所在对象的起始地址。
这里有个有趣的问题——既然同一个类的所有对象都共享同一份成员函数代码,那么为什么我们调用函数的时候,函数总会找到自己属于哪个对象从而访问其该访问的成员变量呢?这就问题就是通过 this 指针解决的。
对象调用成员函数时,编译系统先将对象地址赋值给 this ,然后再调用。每次成员函数访问成员变量时,本质上都使用了 this ,只不过是没有显式地使用而已(是编译器再编译的时候把对象地址加上去的)。
this 是 const,成员函数不能重新赋值之。
静态成员不能访问 this(显然,static成员 不属于任何的 that )
this 的显式使用
this 指针,返回的是指向当前对象自身的指针。对象用自己的函数返回自己的成员,可以:
this->memberVariable; // 是指针
(*this).memberVariable; // 是对象
// 用 this 来进行拷贝
void Student::copy(const Student & stu) {
if( this != &stu ) { // 检查一下当前在哪个对象里,避免自己拷自己
...
}
}
成员指针
可以使用一个指针绕过对象本身,直接访问该对象的成员。
实现这样功能的指针就叫做成员指针。
指向非静态数据成员的指针
定义方法与普通指针完全相同。
int *p = &time.hour;
指向非静态数据成员函数的指针
普通的指向普通函数的指针:
void (*p)(); // 普通的指向 void 型函数的指针变量
p = func; // func 是一个定义好的函数,这一行用指针指向它
(*p)(); // 通过指针变量调用,等效于 func();
指向public函数的指针:
函数类型名 (类名::*指针变量名)(参数表); // 要表明指针指向哪个类中的成员函数
指针变量名 = &类名::成员函数名; // 指向类中的函数
int (Point::*pGetX)(int a); // 比较一般的写法
void (*p)();
p = &Time::showTime;
(t.*p)(); // 新的调用方法,等效于 t.showTime();
指向静态成员的指针
class Point {
...
static int count;
...
static void GetC() {
...
}
};
int Point::count = 123; // 静态数据成员,类外初始化
int *countPtr = &Point::count; // 指上静态数据成员
void (*gc)() = Point::GetC; // 指上静态成员函数
gc(); // 调用就这样
对象引用
Reference,是某个变量的别名 alias
引用,是直接访问对象。指针,是间接访问
Time myTime;
Time &refTime = myTime;
refTIme.func();
myTime.func(); // 完全等效
引用调用
Student returnS(Student s) {return s;}
Student stu1;
stu1.returnS(stu1); // 到这一行,首先会调用 Student 类的复制构造器。
// 复制构造器将形参 s 初始化为实参 stu1
// 然后,第二次构造复制构造器,以将 return s 的这个返回值对象初始化为 s
// 接下来 returnS 的返回值对象调用析构器,将返回值对象析构。
// 然后形参 s 对象的析构器也要被调用。
// 就这样,啥都没干就调用了两次构造器、调用了两次析构器。成本过高。
而,参数的引用传递可以有效避免值传递带来的高额开销。
Student& returnS(const Student& s) {
return s;
}
这样会直接将引用传递过去,没有任何产生副本造成的额外的开销。
共享数据的保护——常对象
对于需要被共享,且值不能被改变的量,可以设置为常量。
const <数据类型名> <常量名>=<表达式>;
常对象:其数据成员值在该对象生命周期内不能被改变
const <类名> <对象名>(<初始化值>); // 常用这种
<类名> const <对象名>(<初始化值>); // 两种效果相同
const Time t(1, 1, 1); // 其所有的数据都是常量,因此必须被初始化
常对象不能调用普通的成员函数——防止在成员函数中尝试修改常对象数据的值
编译时,编译以一个源程序文件作为单位来进行编译。如果函数的定义和声明、调用不在一起,那么编译器就无法对函数内部结构进行检查,导致错误遗留到链接、运行阶段。因此,编译器干脆就不对函数内部进行检查。
mutable
常对象中, 用 mutable 声明的变量,可以被声明为 const 的成员函数修改。
类的常成员
加 const 声明的变量和函数。
const 变量 只能 通过构造器的参数初始化列表来对常成员进行初始化。
const int Hour;
Time::Time(int h): Hour(h) {}
常成员函数
可以通过常成员函数访问数据成员,但不能够修改值,也不能调用该类的非 const 函数
<数据类型> <函数名> (<参数表>) const; // 这个 const 要写在最后。声明和定义时候都要加
常对象只能调用常成员函数
常对象中的函数 不等于 常成员函数!只有带 const 的才是常函数!
const 还可以用于对重载函数的区分。
class R {
R(int i, int j) {
R1 = i;
R2 = j;
}
void print();
void print() const;
int R1, R2;
};
...
R a(5, 4);
a.print(); // 普通对象,调重载的普通函数
const R b(1, 2); // 声明一个常对象
b.print(); // 常量对象,调重载的常函数
const 指针
指向对象的常指针
这样的指针指向不能再改变,但其所指的对象可以改变。
类名* const 指针变量名 = 对象地址;
指向常对象的指针
常对象只能用 const 型的指针指向。
const 类型名* 指针变量名;
这样声明的指针可以指向常对象,也可以指向普通对象。不能通过指针改变对象的值,但是指针本身的值可以改变(也就是重新指向其他对象)。
这也就是说,可以实现【有保护的使用】
例:
Time t1, t2;
const Time* p=&t1;
(*p).hour=18; // 错,不能通过常指针修改变量
t1.hour = 18; // 对,t1 不是常对象
p = &t2; // 对,指向常对象的指针仍然是指针,可以被重新赋值
常引用
声明引用时使用 const 修饰的引用
常引用所引用的对象不能被更新。
const 数据类型 &引用名
常引用参数:函数中不能改变实参对象的值
void fun(const Time &t);
对象数组
<类名> <数组名>[<下标表达式>];
// 数组建立时,每个元素都是一个独立的对象,也就是说有多少个元素就要创建多少次对象
Student stud[3] = [11, 22, 33]; // 这样填写构造器实参
Student exStud[2] = {Student(11, 'abc'), Student(22, 'def')};
// 构造器有多个参数,需要这样调用构造器
Student exStud[2] = {Student(11, 'abc')};
// 如果构造器有默认参数值,则第二个直接通过默认参数构造
访问:
<数组名>[<下标>].<成员名>
动态对象数组
CPoint* ptr = new CPoint[5]; // 声明并分配空间
...
delete[] ptr; // 释放上面动态申请的内存
对象成员(子对象)
class A {
...
};
class B {
B(const A &a):m_a(a) { // 在这里调用了复制构造器,把 a 复制给 m_a
...
}
/* 或
B(const A &a):m_a(a) {
m_a = a;
...
}
*/
A m_a; // 对象成员。A需要在B前面进行声明
};
有子对象的类在进行初始化时,先调用子对象的构造器,再调用本类的构造器。析构相反:即先析构自己,再析构各个子对象。
如果类没有写自定义构造器,则子对象构造时使用的也是默认构造器。
与对象成员类似,还有一种叫做对象成员数组的东西
类模板
类模板是类的抽象,类是类模板的实例。
类模板,是对一批【仅有数据成员类型不同的】类的抽象。
因为在这个类中,数据类型也成为了参数,故又称“参数化的类”。
类模板实例化出来的类:“模板类”(从模板来的类)
template <class 类型参数> // 类型参数数量不限
class <类模板名> {
...
};
// 例1:
template <class T>
class Compare {
public:
Compare() {
x=0;
y=0;
}
Compare(T a, T b) {
x=a;
y=b;
}
T max() {
return (x>y)?x:y;
}
private:
T x, y;
};
// 例2:
template <class T1, class T2> // 多个类型的参数
class A {
...
};
A<int, double> obj; // 实例化对象。先实例化出对应类型的类,再实例化对象
template <class T=int> // 使用默认参数的类模板
class Array {
...
};
Array<> intArray; // 可以留空
6:运算符重载,友元
运算符重载:重新定义运算符
本质是函数的重载,我们需要为每个重载的运算符定义一个【运算符重载函数】,运算符该做的事情实际上会交给这个函数来做。这样的函数可以是类的成员函数或友元函数。
运算符的重载不会改变其本来的优先级和结合性
重载为类的成员函数
<函数类型> operator <运算符>(<参数表>) { // 参数表中是要运算的对象,最多只有一个参数
// 一个(右)操作数是参数,另一个(左操作数)则是调用该函数的对象
函数体
}
单目运算符的重载
一般只有++和–
但注意,这俩运算符的 先自加 / 后自加 的效果是不同的,也就是说重载运算符函数的返回值不同,重载时需要区分。
<类型> operator ++() // 前置
<类型> operator ++(int) // 后置. 写个 int 仅仅用于区分,无实际用途
以定义复数的计算等进行说明
复数类
包含普通双目运算符的重载
class Complex {
public:
Complex(double r=0.0, double i=0.0) {
real = r;
imag = i;
}
const double Real() {return real; }
const double Imag() {return imag; }
Complex operator+(Complex &c); // 重载加减
Complex operator+(double &c);
Complex operator-(Complex &c);
Complex operator-(double &c);
private:
double real, imag;
};
Complex Complex::operator+(Complex &c) {
Complex tmp;
tmp.real = real + c.real;
tmp.imag = imag + c.imag;
return tmp;
}
// 用法如下
Complex c1(...);
Complex c2(...);
Complex c3;
c3 = c1 + c2; // 实际上是:c3 = c1.operator+(c2);
// 左操作数必须是对象,左操作数用右操作数为参数调用运算符
双目运算符重载为成员函数时,仅能有一个显示指出的参数,另外还会隐含一个 this 指针,用以指向调用它的那个对象(比如上面的 c3 = c1.operator+(c2)),隐含的就是指向c1的。
因此,这种重载的算符是无法进行 c3 = 12 + c1 这样的计算的。如果想要进行这样的计算,则可将该双目算符重载为全局的友元函数,让参与运算的两个数都变成参数即可。
单目运算符重载
例:
class A {
float x, y;
...
A operator++() {
A t;
t.x = ++x;
t.y = ++y;
return t;
}
A operator++(int) {
A t;
t.x = x++;
t.y = y++;
return t;
}
/* 简便写法。如下例中,调用这个函数的就是 a,this指向的也是这个a本身。也就是把自己返回了
A operator++() {
++x;
++y;
return *this;
}
*/
};
A a(2, 3), b;
b = ++a; // b = a.operator++(); 重载的运算符内没有参数
运算符重载为友元函数
运算符重载,本质上是一个全局函数。
这样的情况下,参数中必须有一个自定义对象(因为重载运算符的意义就在于可以使用“常见的”运算符来对自定义的类型进行运算),但并不再必须是左值——参与运算的对象全部成为函数的参数。
例如,一个双目运算符的两边全都是参数。因为这样重载算符的友元函数一般是全局函数,不存在普遍意义上的“属于谁”的概念。
A a, b, c;
c = a + b; // c = operator+(a, b)
c = ++a; // c = operator++(a)
c += a; // operator+=(c, a)
过去要求左操作数一定是对象,主要是因为重载的运算符函数属于左操作数所属类的成员函数,故要依赖于左操作数用右操作数为参数调用运算符。但现在,左操作数是什么都可以了。因为全局函数不需要依赖类的实例来进行调用。
算符重载为类的友元函数
最多只能有两个参数
friend <函数值类型> operator <运算符>(<参数表>) {
...
}
如果重载的是双目运算符,则第一个参数是左操作数,第二个是右操作数
例:
class A {
private:
int i;
public:
...
friend A operator+(A &, A &); // 虽然声明写在 A 里面,但并不是 A 的成员函数
// 这么写仅仅是说:有这么一个函数,它是A的友元函数
};
A operator+(A &a, A &b) { // 并不属于 A ,所以不用加作用域算符
A t;
t.i = a.i + b.i; // 计算示例
return t;
}
// 用法
A a1, a2, a3;
a3 = a1 + a2; // a3 = operator+(a1, a2);
友元单目例:
// A operator++(A &a) ++为前置运算符
// A operator++(A &a, int) ++为后置运算符
class A {
private:
int i;
public:
friend A operator++(A &a) { // 定义放在类定义中,仍然可以保证自己是个全局函数
a.i++;
return a;
}
friend A operator++(A &a, int) {
A t;
t.i = a.i;
a.i++;
return t;
}
};
A a1, a2, a3;
a2 = ++a1; // a2 = operator++(a1)
a3 = a1++; // a3 = operator++(a1, 3) 这后边这个 3 其实没啥影响的样子
友元
友元——private 的东西可以给和自己关系好的看,友元关系是单向的,而且不能传递。
被声明为友元的函数 / 类可以直接访问当前类的 private 成员。
友元,可以是一个全局函数、另一个类的成员函数(友元函数)、或者是整个类(友元类),友元类的所有函数都是友元函数。
实际应用中应该尽量避免使用友元。
友元函数
谨慎使用:友元函数常用于取数据成员值而不进行修改
// 友元的声明只能出现在被访问类的定义中——我自己来决定谁是我的友
friend <函数类型> <函数名>(<参数表>);
friend class <类名>;
例:
class A {
private:
float x, y;
public:
float Sum() {return x+y;}
friend float Sum(A &a) { return a.x + a.y; } //全局友元函数,需要指明对谁进行操作
};
A t1(3, 4), t2(10, 20);
t1.Sum(); // 成员函数调用
Sum(t2); // 全局友元函数调用。它不属于任何类所以不用指明属于谁,但需要指明操作谁
友元函数无 this 指针,因此需要指明被操作的对象作为参数
访问权限关键字(public private protect)对友元函数没有影响,也就是说声明在哪里都一样用
多数情况下,一个类的友元函数是某个类的成员函数,这样就能够实现类和类的通信
class A {
public:
void fun(B &);
private:
float x, y;
};
class B {
public:
friend void A::fun(B &);
private:
float m, n;
};
void A::fun(B &b) { // 这样,A 类的函数就可以随便访问 B 了
x = b.m + b.n;
}
友元类
两个类紧密耦合,一个类中的好多函数都需要访问另一个类中的成员
class A { // 被访问类
...
friend class B;
};
class B { // 可以对 A 的实例为所欲为
...
void showA(A &a) { // 一定要在参数中指明实例才能操作——总不能操作一个概念吧
...
}
};
A a1;
B b1;
b1.showA(a1); // 使用
输入输出运算符的重载
此处将说明如何实现对于对象的输入和输出
注意,只能重载为友元函数——原因如下:
对于 cin>>a, cout<<a,这里的 >> 、<< 其实都是双目运算符。我们要做的其实是 cin.operator>>(a),然而 cin 并不是 A 类的对象,自然不可能调用 A 类的函数。重载为全局的友元函数,则运算符两端的值都将作为参数填入运算符重载函数。即如: operator>>(cin, a)
// 友元重载算符一般格式
friend istream& operator>>(istream &, MyClassName &)
// 返回值是一个 istream&, 也就是对输入流的对象的引用
// 两个参数,右操作数是我们要进行输入操作的对象的引用
istream& operator>>(istream &is, MyClassName &f) {...}
cin>>a; // 本质:operator>>(cin, a)
cin>>a>>b; // 可以连续使用,这样就是调用两次,cin>>a 的返回值就是相对于 b 的第一个参数
// 输出重载
friend ostream& operator<<(ostream &, MyClassName &)
cout<<a; // operator<<(cout, a);
class A {
float x, y;
public:
...
friend istream& operator>>(istream &, A &);
friend ostream& operator<<(ostream &, A &);
};
istream& operator>>(istream &is, A &a) {
cout<<"input a: "<<endl;
is>>a.x>>a.y; // 系统定义的输入运算符。a.x、a.y都是基本数据类型
return is; // 把引用返回回去
}
ostream& operator<<(ostream &os, A &a) {
cout<<"Object is: "<<endl;
os<<a.x<<"\t"<<a.y<<endl; // \t是 tab
return is;
}
类型转换运算符重载
基本类型到类
直接将基本类型数据赋值给类时,会对这个基本类型进行强制类型转换——通过构造函数进行此操作。
进行此任务的构造函数,应该是一个仅有一个参数的构造函数,被称为【转换构造函数】。这个参数的类型就是被转换的类型。
比如,将一个单一的实数赋值给一个复数,在复数类中就需要有这样的一个构造器:
Complex(double r) {
cout<<"调用构造器"<<endl;
real = r;
imag = 0;
}
~Complex() {
cout<<"调用析构器"<<endl;
}
// 使用
Complex c1(1.1);
Complex a(2.2);
a = 3.3; // 如果有只有一个参数的构造器,可以用等号强制赋值
// 这一句话会先进行 Complex(3.3),生成一个临时对象,
// 该临时对象将被赋给 a,然后临时对象调用析构器解构
类到基本类型
有一种叫做【类型转换函数】的东西,可以实现这样的转换。这个函数本质上是一个类型转换运算符重载函数,专门用于将类转换为基本类型。
由于是对特定的类进行操作,故这种函数只能被重载为某个类的成员函数。
operator <返回的基本类型名> () { // 最前面不加返回值类型。调用属于隐含调用,故不能加参数。
...
return <基本类型值>;
}
class A {
int i;
public:
A(int a=0) {
i=a;
}
operator int();
};
A::operator int() {
return i;
}
...
A a(10);
cout<<a; // 就可以直接印出一个10。这里进行了对类型转换函数的隐含调用
7:类的继承、多继承与虚基类
继承
继承关系图。向上的箭头指向直接父类。

关于这样的继承关系的三种表述方法:(即,同义词)
父类、子类;基类、派生类;超类、次类。
从上向下被称为“特化”,向上则被称为“概化”。在继承中,派生类可以覆盖基类方法、添加新的属性和方法。
例
// 每次自增1,无限增长
class Counter {
private:
int value;
public:
Counter(int initValue);
Counter();
void show();
void next(); // 自增
void reset();
int revalue();
};
// 每次自增1,有循环
class CycleCounter {
private:
int value;
int base; // 循环基数
public:
CycleCounter(int initValue);
CycleCounter();
void show();
void next(); // 自增
void reset();
int revalue();
};
上面这两个类,其实可以往上再抽取出来一层。
下面的类,自动就有了上面的类的成员。在下面各个类中增加比较特殊的东西就可以了。

DisplayableNumber 就是一个下面两个计数器共同的基类。
类是可以不断横向、纵向进行扩展的。

派生类的定义
class <派生类名>: <继承方式> <基类名> { // 继承方式:public, private, protected
// 默认 private
<派生类新定义的成员> // 和基类重复的就不需要再进行定义了
};
// 例:
class A {
int i;
};
class B: public A { // 派生类将自动继承基类所有成员,但不包含构造、析构器
int j;
};
不同继承方式的访问权限
表格内容是派生类中基类成员的访问控制权限。
| public 继承 | private 继承 | protected 继承 | |
|---|---|---|---|
| 基类公有成员 | 公有 | 私有 | 保护 |
| 基类私有 | 派生类成员不可访问 | 派生类成员不可访问 | 派生类成员不可访问 |
| 基类保护 | 保护 | 私有 | 保护 |
也就是说,基类的 private 就是 private 的,即使是派生出来的子类也是【其他的类】,故同样不能访问。派生类可以直接在本类内访问基类的保护成员。
如果非要在派生类中访问基类的私有成员,可以把派生类声明为基类的友元。
public 继承
派生类中的基类公有成员、保护成员在被继承后分别成为派生类的公有、保护成员。派生类的新成员可以直接访问这些成员,但是不能直接访问基类私有成员。
在类外,派生类的实例只能访问继承的基类的公有成员,保护的不行。。因为本来在一个类的外面(其他类、本类的实例)都只能访问这个类的 public 成员。
例:从 Point 类派生 Rectangle 类(矩形)

protected 继承
派生类中,基类的公有、保护成员全都是派生类的保护成员。
在派生类内可以访问这些成员,但类的实例则啥基类内成员都不能访问了。。。
保护继承模式下,为了保证一些从基类继承来的对外接口仍能正常使用,就需要在派生类中重新声明同名的成员函数
class A {
public:
int getA() {
return a;
}
protected:
int a;
};
class B: protected A {
public:
int getA() { // 为了起到和基类一样的效果,需要搞一个完全重名的函数
// 否则在外面,也即是B的实例中是访问不到A::getA()的
// 只能通过 B::getA() 间接取到
return A::getA() // 显式访问基类成员
};
protected:
...
};
private 继承
派生类中,基类的公有、保护成员全都是基类所私有的。
派生类的新成员可以直接访问原来基类中的公有、保护成员(但依旧不能直接访问基类的私有成员)。类外,派生类的对象不能访问基类的所有成员
关于继承中的构造器
构造器简例
class Point {
public:
Point(float xx=0, float yy=0) {
X=xx;
Y=yy;
}
float GetX() {return X;}
float GetY() {return Y;}
private:
float X, Y;
};
class Rectangle: public Point {
public:
Rectangle(float x, float y, float w, float h) { // 派生类构造器
Point(x, y);// 错!不能在派生类构造器中显式调用基类构造器!这样创建了一个无名对象!
W=w;
H=h;
}
float GetH() {return H;}
float GetW() {return W;}
private:
float W, H;
};
// 由于派生类不会继承基类的构造器、析构器,故派生类对于自身包含的基类成员初始化必须由派生类构造器完成
// 正确的通过基类构造器初始化基类成员的方法:
// 使用成员初始化列表。这里面可以显式调用基类构造器,完成基类成员初始化
<派生类名>(<总参数表>): <基类名>(<参数表1>), <对象成员名>(<参数表2>) {
<派生类数据成员初始化>
};
// 上面的例:(派生类自己的对象也可以使用:成员名(值) 的写法来初始化)
Rectangle(float x, float y, float w, float h): Point(x, y), W(w), H(h) {}
构造器、析构器调用顺序

构造器
比如要实例化 Sub11。从Sub11开始上溯找到根节点(即Base),从这里开始,逐步向下调用各类构造器,直到调用 Sub11 自己的构造器。
基类构造器 -> 基类成员的构造器 -> 派生类自己的构造器
当基类中没有自定义构造器,或者只有无参构造器时,派生类构造器里面就不用再写基类的构造器了,这里将进行“隐含调用”。
当基类只有有着大于等于一个参数的构造器时,派生类必须定义构造器,将参数传递给基类构造器。
如果基类中同时有【有参数的构造器】和【没有参数的构造器】,则派生类可调可不调,不调就隐性调了。
析构器
与构造器相反,先调用 Base 的。
派生类是基类的友元
class A {
friend class B; // B 是 A 的友元,B 可以直接访问 A 里面的私有成员
public:
private:
int getA() {
return a;
}
int a;
};
class B: public A {
public:
int callGetA() {
return getA(); // 直接读取 A 的私有成员
}
int directlyGetA() {
return a; // 直接读取 A 的私有成员
}
private:
int b;
};
// 但是下面这样就不行了
A aObj;
aObj.callGetA(); // 正确
aObj.getA(); // 错误。不能直接在类外调私有成员
作为基类的友元,在友元派生类中,访问基类的成员不再需要像之前的“跨类”访问一样,指明要访问哪个实例才能进行对友元的访问。因为那个的本质还是俩类,但这个却已经是类套着类,变成了类之套娃,实质上是一个了。

如上图,套娃。
下面,回忆一下之前的普通友元类。。。
class A { // 被访问类
...
friend class B;
};
class B { // 可以对 A 的实例为所欲为
...
void showA(A &a) { // 一定要在参数中指明实例才能操作——总不能操作一个概念吧
...
}
};
A a1;
B b1;
b1.showA(a1); // 使用
友元不能继承
比如,B 是 A 的友元,C 是 B 的派生类,则 C 和 A 并不是友元。
(王叔叔是你爹的朋友,但并不是你的朋友,所以你当然不能访问王叔叔的 private ,除非你也和王叔叔成为朋友)
多继承
一个派生类有多个基类,就叫多继承。单继承是多继承的特殊情况。
class <派生类名>: <继承方式> <基类名1>, ..., <继承方式> <基类名n> {
<派生类新定义成员>
};
// 多继承派生类构造器。总参数表 中必须!包含所有基类初始化所需的参数
<派生类名>(<总参数表>): <基类名1>(<参数表1>), ..., <基类名n>(<参数表n>) {
...
}
// 基类初始化所需的参数是根据某些参数算出来的也行,比如
C(int k): A(k+2), B(k-2) {}
多继承派生类构造器调用顺序:所有基类构造器 -> 对象成员类构造器 -> 派生类构造器。
处于同一层次的各基类构造器的调用顺序取决于定义派生类时指定的基类顺序(从前往后),与初始化列表中的顺序无关。
若有多个成员类对象,则他们构造器的调用顺序是他们在本类中被声明的顺序,同样与初始化列表中的顺序无关。
多继承引起的二义性问题
两个基类有同名成员
class A {
public:
int a;
void display();
};
class B {
public:
int a;
void display();
};
class C: public A, public B { // 这样的C中有两套 a、display()
public:
int b;
void show();
};
// 解决方案
C c1;
c1.A::a=3;
c1.A::display();
两个基类和派生类都有同名成员
// A、B 类还和上面那个例子相同
class C: public A, public B { // 这样的C中有三套 a、display
public:
int a;
void display();
};
C c1;
c1.a=3;
c1.display(); // 这样直接访问是可以的,但只直接访问派生类中的成员
// 即,基类成员在派生类中被派生类的同名成员【屏蔽】了
c1.A::a=3; // 但仍可通过指出作用域来访问
c1.A::display();
某个类继承了从同一个基类派生出的两个类

这样的 C 类中,将有两份 N 类成员。C面临着【选择哪条继承路径所继承下来的A】的问题
// N中有a
c.A::a; // 这样是 ok 的
这种情况,其实在某些场景下是必要的——A、B各有一种对N的初始化方式,而C同时需要这两种共同存在的情况。
虚基类
多数情况下,我们并不想让上面的情况出现。
将直接基类(上面的A、B)的共同基类(上面的N)设置为【虚基类】,将使共同基类(N)在内存中只有一个副本存在,从而解决对基类成员访问的二义性问题。
虚基类定义
class <派生类名>: virtual <继承方式><共同基类名>; // <共同基类名> 就是虚基类
虚基类的派生类对象中,将只存在一个虚基类成员的副本。
为保证虚基类在派生类中只继承一次,应在该基类的所有直接派生类中都声明为虚基类。

这样将会导致最终的 C 中有两份N的成员。其中一份 A、D 公用,另一份通过 C 产生。
class A {
public:
A() {a=10; }
protected:
int a;
};
class A1: virtual public A {
public:
A1() {cout<<a<<endl; } // 调用一次A的构造器。输出10
};
class A2: virtual public A {
public:
A2() {cout<<a<<endl; } // 不再调用A的构造器。输出10
};
class B: A1, A2 {
public:
B() {cout<<a<<endl; } // 10
};
B obj;
return 0;
虚基类构造器调用顺序
先调用虚基类的构造器,再调用非虚基类的构造器。
若同一层次中有多个虚基类,则调用顺序是定义的顺序。
如果虚基类由普通类派生而来,则仍按原顺序执行:即先调用基类构造器,再调用派生类的构造器。
例:
class Base1 {
public:
Base1() {cout<<"Base1"<<endl; }
};
class Base2 {
public:
Base2() {cout<<"Base2"<<endl; }
};
class Level1: public Base2, virtual public Base1 {
public:
Level1() {cout<<"Level1"<<endl; }
};
class Level2: public Base2, virtual public Base1 {
public:
Level2() {cout<<"Level2"<<endl; }
};
class TopLevel: public Level1, virtual public Level2 {
public:
TopLevel() {cout<<"TopLevel"<<endl; }
};
TopLevel obj;
/* 输出:
Base1 # TopLevel 先构造虚基类 Level2( Level2 先构造虚基类 Base1 )
Base2 # Level2 再调用基类 Base2
Level2 # 调用 Level2 构造器
# Level2 一侧构造完成,开始构造 Level1 一侧
Base2 # Base1在TopLevel1中也是虚基类,虚基类只需要被构造一次,故本次只构造Base2
Level1 # Level1 构造
TopLevel # 终于轮到自己了
*/
虚基类的初始化
如果虚基类只有带参构造器,则其所有派生类中(包括直接、间接的)都要通过构造器初始化列表对虚基类进行初始化(因为原本就需要参数。。)
class A {
A(int i) {...}
};
class B: virtual public A {
B(int n): A(n) {...}
};
class C: virtual public A {
C(int n): A(n) {...}
};
class D: public B, public C {
D(int n): A(n), B(n), C(n) {...} // 间接基类构造也要调用。
// 因,如果让B、C自己调用A,那么可能会导致
// B、C使用不同的值初始化A,而A又只有一个,产生矛盾
// 该情况下,将忽略B、C对A的调用,只用D的参数调A
};
如果多继承不牵涉对同一基类的派生,则没必要定义虚基类
多继承经常出现二义性问题,使用要非常小心
能用单一继承解决的问题就不要用多继承
类的层次结构设计
分析所有的类,对属性分组,然后不断调整,一次次往上概化
- 找出所有可能的候选类
- 对这些候选类往上概化一步
- 进行迭代分类(也就是进一步寻找共同点,分出必要的层次)
8:多态性与虚函数
类型兼容规则
在需要基类对象的任何地方,都可以使用公有的派生类的对象来替代
因为公有派生类继承了基类的所有东西,相当于整个包含了基类
-
派生类的对象可以赋值给基类的对象——用派生类从基类继承来的成员赋值给基类对象成员;
-
派生类的对象可以初始化基类的引用
class A {...}; class B: public A {...}; A a, *pa; B b; A &a1 = b; // a1 和 b 不共享存储空间,而是和 B 中与 A 相同的那部分共享! -
派生类的对象的地址可以赋值给基类的指针变量
pa = &b; // 指向 b 中从 A 继承的那一部分,而不是 b 的全部 // 如果 B 中有与A中同名的函数,那么通过pa->func()调用的将是A的
替代后,派生类对象就可以当作基类的对象用了。但是只能访问从基类继承的成员,也只能调用基类中包含的函数
多态(Polymorphism)
具有相似功能的不同函数使用同一个名称,从而可以使用相同的调用方式来调用这些有不同功能的同名函数。
即:调用同一个函数名,可以根据需要来实现不同的功能
重载就是一种多态,但重载是【静态的多态】。
多态分类
- 静态多态(编译时多态):编译时系统就能决定调用的是哪个函数。通过重载实现;
- 动态多态(运行时多态):程序运行时才能动态确定操作所针对的对象(即,调用的时哪一个函数)。运行时,不同类的对象调用各自的虚函数。
联编
将标识符名称和存储地址关联起来的过程。比如调用一个函数,函数名和函数的地址就是联系在一起的。多态实现过程中,确定调用哪个同名函数的过程就是联编(又名绑定)。
联编分类
- 静态联编:编译时确定调用哪个函数的代码。常在重载时使用。
- 动态联编:只能在程序执行过程中,通过具体的执行情况动态确定。通过继承和虚函数实现。
如果想要用指向基类的指针指向派生类并调用派生类中的函数,就需要利用动态多态,将基类中的函数声明为虚函数。这样的,同一类族中不同类的对象,对同一函数调用做出不同响应,叫做【由虚函数实现的动态多态】。
比如,演员、发型师、外科医生都是人类的实例,并且都有名为 cut() 的函数,可是做的事情截然不同。
虚函数的使用
- 类之间满足类型兼容规则(也就是有继承关系、有同名函数替代的情况);
- 同名声明虚函数:在基类和派生类中都同名声明虚函数——派生类中要有与基类中完全同名的函数的定义——函数名、参数表、返回值都完全相同;
- 通过基类对象指针或对象引用来调用虚函数。如果使用对象调用则仍是静态联编。
虚函数
在基类中被 virtual 说明、在一个或多个派生类中被重新定义的成员函数(也就是说只剩名字参数返回值一样,别的全都要在子类重写)
virtual <返回值类型> <函数名>(<参数表>);
要访问派生类中的同名函数,必须将基类中的同名函数定义为虚函数。
如此一来,就可以声明一个指向基类的指针,然后将这个指针重新指向不同的派生类对象——每次重新指向一个对象,就可以调用其特有的与虚函数重名的函数(需要通过调用指针/引用所指向的虚函数才能实现动态的多态性,不能通过对象来调用)。

例:
class Student {
public:
virtual void print() {
cout<<...;
}
};
class GStudent: public Student {
public:
virtual void print() { // 这里的 virtual 可省略
cout<<...;
}
};
int main() {
Student s1, *ps;
GStudent s2;
ps = &s2;
ps->print(); // 调用的是 GStudent 中的print
}
virtual 函数无论派生了多少层,都会一直保持 virtual(这被称为“继承虚特性”,从【开始虚的地方】开始沿着继承关系向下传),派生类中进行重新定义时可以省略 virtual 关键字。只需要基类中有就可以了。
实际使用中不同操心类的继承路径之类,直接把虚函数瞎击毙写上调用就能通过动态联编得到正确的结果。
使用对象引用调用虚函数
class Student {
public:
virtual void print() {
cout<<"student"<<endl;
}
};
class GStudent: public Student {
public:
virtual void print() {
cout<<"graduated student"<<endl;
}
};
void fun(Student &s) { // 对象的引用作参数
s.print(); // 通过对象引用调用虚函数
}
GStudent s1;
fun(s1); // 这样调用的就是派生类的虚函数,打印graduate..
动态多态的力量:可以简单组织复杂的调用

静态成员函数、友元函数(因二者不属于任何一个对象,没有多态特征),内联成员函数(编译时代码已明确确定并替换,而多态是要在运行时才能确定要调用哪一段的代码)不能为虚函数。
(但,加了 virtual 且在类内被定义的函数并不再算做是内联函数)
构造器不能是虚函数,析构器可以是。
virtual ~<类名>();
例:
class Base {
public:
Base() {}
~Base() { // 不定义为虚函数
cout<<"Base destructor"<<endl;
}
};
class Deriverd: public Base {
public:
Deriverd() {}
~Deriverd() { // 不定义为虚函数
cout<<"Deriverd destructor"<<endl;
}
};
int main() {
Base *b = new Deriverd;
delete b; // 这样算静态联编,b被关联到基类对象,只会调用基类的析构器
// 输出只有:Base destructor
// 这样就会跳过派生类析构器中的内存释放逻辑,导致内存泄漏
return 0;
}
//==============================
class Base {
public:
Base() {}
virtual ~Base() { // 虚函数
cout<<"Base destructor"<<endl;
}
};
class Deriverd: public Base {
public:
Deriverd() {}
~Deriverd() { // 虚函数
cout<<"Deriverd destructor ";
}
};
int main() {
Base *b = new Deriverd;
delete b; // 动态联编,b被关联到派生类对象,会先调派生类析构器,再调基类析构器
// 输出:Deriverd destructor Base destructor
// 会执行派生类的析构器,能够避免内存泄漏
return 0;
}
虚函数为一个类簇中所有派生类的同一行为提供了统一的接口。调用类簇时只需要记住一个接口即可。
稍微实际一点的用法示例:
const double PI = 3.14159;
class Point {
private:
int x, y;
public:
Point(int X=0, int Y=0) {
this->x = X;
this->y = Y;
}
virtual double area() {
return 0.0;
}
};
class Circle: public Point {
private:
double radius;
public:
Circle(int X, int Y, double R): Point(X, Y) {
radius = R;
}
virtual double area() {
return PI*radius*radius;
}
};
Circle C1(10, 10, 20);
Point *Pp;
Pp = &C1; // 基类对象指针
cout<<Pp->area(); // 正确。打印圆的面积
Point & Rp = C1; // 基类对象引用
cout<<Rp->area(); // 正确。打印圆的面积
若派生类中定义了虚函数的重载函数,且没有定义虚函数,则重载函数将覆盖派生类中的虚函数。尝试使用虚函数将产生错误。(但仍可用基类中定义好的虚函数)
如果派生类中不重新定义虚函数,则不会动态联编,派生类对象将使用基类的虚函数代码
纯虚函数
用 virtual 声明,没有任何实现,必须由派生类重新定义并进行实现
virtual <返回值类型> <函数名>(<参数表>) = 0;
// 基类中的纯虚函数直接赋值为 0 即可,永远不会被直接用到
// 其存在的意义只是为了提供一个多态的接口,
// 必须在派生类中被重新定义
注意,纯虚函数和【函数体为空】的虚函数不同,前者没有函数体且不能被实例化,后者有函数体只不过是空的,可以被实例化
virtual void func() {} // 函数体为空的虚函数
virtual void func() = 0; // 纯虚函数
抽象类
抽象类:包含一个 / 多个纯虚函数的类,其无法被实例化。其只能作为派生类的基类,而不能直接生成对象
如果派生类没有实现所有的纯虚函数,那该派生类也是抽象类。必须在将所有纯虚函数都实现后,该类才能进行实例化。
抽象类不能用作参数类型、函数值类型、显式转换类型。但是可以声明指向抽象类的指针或引用,通过指针或引用指向其派生类的对象,实现动态多态。

例:
const double PI=3.14159;
class Shapes {
public:
void setValue(int d, int w=0) {
x=d;
y=w;
}
virtual void area() = 0; // 纯虚
protected:
int x, y;
};
class Square: public Shapes {
public:
void area() { // 实现虚函数
cout<<x*y<<endl;
}
};
class Circle: public Shapes {
public:
void area() { // 实现虚函数
cout<<PI*x*x<<endl;
}
};
int main() {
Shapes *ptr[2]; // 指向抽象类类型的指针
Square s1;
Circle c1;
ptr[0]=&s1; // 抽象类指针指向派生类对象
ptr[0]->setValue(10, 5);
ptr[0]->area(); // 抽象类指针调用派生类成员函数
ptr[0]=&c1;
ptr[1]->setValue(10);
ptr[1]->area();
return 0;
}
例:
class B0 {
public: // 留给外部的接口
virtual void display() = 0; // 纯虚函数
};
class B1: public B0 {
public:
void display() { // 实现虚函数
cout<<"B1::display()"<<endl;
}
};
class D1: public B1 {
void display() { // 重新定义
cout<<"D1::display()"<<endl;
}
};
void f1(B0* ptr) { // 将一个抽象基类的指针,通过这个指针访问不同的函数
ptr->display();
}
int main() {
B0 *p;
B1 b1;
D1 d1;
p = &b1;
f1(p); // 基类指针指向派生类对象,输出:B1::display()
p = &d1;
f1(p); // 基类指针指向派生类对象,输出:D1::display()
// 中间的多少层继承直接穿透,拿到最终的实现
}
9:输入输出流
printf、scanf的缺点
- 非类型安全。可以输入/输出各种类型的数据。如果scanf的地址写错,可能会让程序硬写内存导致一些危险的后果
- 不可扩充性。没办法输出复杂的东西
C++使用类型安全的 I/O 流操作,不同类型的 I/O 流操作都是重载的,没定义过 I/O 功能的类型不具备 I/O 操作的能力。通过重载,可以对 I/O 进行自定义的修改和扩充。
C++ 使用输入输出流进行 I/O
流 Stream
流,是字节的序列。从一个位置流向另一个位置。输入输出,就是字符序列在内存和外设之间的流动。
从流中获取数据:提取操作(输入操作)
向流中添加数据:插入操作(输出操作)
输入流:从外设到内存;
输出流:从内存到外设。
C++ I/O流类库的层次结构
I/O 流类库有两个平行基类:streambuf、ios
常用 ios,ios 有 istream(输入流类)、ostream(输出流类)、fstreambase(文件流类基类)、strstreambase(字符串流类基类)
















 6296
6296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











