







参数有效性检验
2018-11-26天气凉,耗时三个周末完成这篇原创文章,记录下自己关于程序安全性方面的一些微薄见解。愿自己程序员之路越走越顺利,保持激情初心,不忘理想前行。
-
问题:
- 为什么要检验?
- 哪些情况判为参数失效?
- 有哪些参数需要检验?
- 怎么检测?
- 在哪里检验?
- 怎么处理?
-
为什么要检验?
保护程序免糟非法输入数据的破坏,尽可能将异常数据对程序造成的影响控制在有限的范围内。
防御式编程主要思想:子程序应该不因传入错误数据而被破坏,哪怕是由其他子程序产生的错误数据。更一般地说,其核心思想是承认程序都会有问题,都需要被修改,聪明的程序员应该根据这一点来编程。
不管进来什么,好的程序都不会生成垃圾,而是做到“垃圾进,什么都不出”、“进来垃圾,出去是错误提示”或“不许垃圾进来”。
——《代码大全2》第8章 防御式编程
-
哪些情况判为参数失效?
- 参数越界失效:参数值不在预期范围内。比如参数值超过上下限,数组下标越界。
- 符号异常失效:指正负号异常,应该尽可能使用无符号类型。
- 空指针失效:传递空指针。
- 数据过期失效:原本实时更新的数据长期未变化。
- 跳变失效:数据波动异常的大或小。
- 关联数据异常失效:指两个以上的数据值之间有依赖和关联,当值不符合依赖关联性时认为失效。
-
有哪些参数需要检验?
最佳的形式是在一开始就不引入错误。- 从数据来源讲:
- 检查来源于外部的数据的值。
- 检查子程序的输入参数的值。
应重点检查外部输入数据(网络通讯传入、上层或下层传入、硬件设备采集数据)外部传入的数据对本模块的程序员来说往往是模糊和不可操控的,内部数据也较多依赖于外部数据输入,因此中间检查外部数据。内部数据可以只检查较为复杂的算式或算结果。
- 从数据来源讲:
-
怎么检测?
对参数进行失效检验意味着需要存储有一些有关参数的信息,可以定义结构体化的参数。我们对参数进行分类如下:-
功能型参数。
用于表示某项功能开关的参数,我们可以定义为如下结构体:```c //Type redefinition------------------------------------------------------------------------ typedef unsigned char Byte; typedef Uint16 Word; //Function enum definition----------------------------------------------------------------- typedef enum Switch {DISABLE, ENABLE} ESwitch; //Switch variable //Functional parameter structure----------------------------------------------------------- typedef struct FunParameter { ESwitch eSwitch; //Value: ENABLE or DISABLE ESwitch ePrevious; //Previous value Word wCounter; //Enable or Disable time }TFunParameter, * pTFunParameter; //functional parameter initialization------------------------------------------------------ //Motor head temperature TFunParameter tfHeadTemp = {.eSwitch = ENABLE, .ePrevious = DISABLE, .wCounter = 0 }; ```note:定义历史值方便检测功能开关状态切换的跳变变化。功能有时需要记录开启或者关闭时间,因此直接将定时器封装进结构体使得参数关系紧密。
对功能型参数使用枚举类型因此不需要检测值越界失效和符号异常失效,重要的是检测关联数据异常失效。比如功能A和B为互斥关系,一次只能有一个功能打开或两个功能都关闭,再比如功能B开启前应该先打开功能A。功能开关较多,关联性强的情况下这样的检测变得重要。
对于功能型参数的关联性检测可以放到预处理时期由编译器检测,不用等到外出调试才发现错误。预处理指令不能检测变量,考虑到功能有效性一旦确当后不在修改,但又要满足调试时可能存在的对功能开关的修改,可以通过以下形式实现://General macro definition----------------------------------------------------------------- #define ENABLE 1 #define DISABLE 0 //The switch of Function------------------------------------------------------------------- #define FUN_HEAD_TEMP ENABLE #define FUN_OIL_PRESS DISABLE #define FUN_HEAD_TEMP_STOP ENABLE //Functional correlation detection--------------------------------------------------------- #if((FUN_HEAD_TEMP == FUN_OIL_PRESS) && (FUN_HEAD_TEMP == ENABLE)) #error 油压与油温为互斥功能,不能同时开启。 #endif #if((FUN_HEAD_TEMP_STOP == ENABLE) && (FUN_HEAD_TEMP == DISABLE)) #error 开启油温停机功能必须同时开启油温采样功能。 #endif //functional parameter initialization-------------------------------------------------------- TFunParameter tfHeadTemp = {.eSwitch = FUN_HEAD_TEMP, .ePrevious = DISABLE, .wCounter = 0}; //Motor head temperature TFunParameter tfOilPress = {.eSwitch = FUN_OIL_PRESS, .ePrevious = DISABLE, .wCounter = 0}; //Oile press Function TFunParameter tfHeadTempStop = {.eSwitch = FUN_HEAD_TEMP_STOP, .ePrevious = DISABLE, .wCounter = 0}; //Motor Closed Function -
状态型参数。
状态型参数用于表示当前运行下的某种状态,是实时的因此不像常量宏可以用预处理指令检验。比如电机的开关波状态,阀门的开关状态,气压状态等。我们可以定义为如下结构体://Status enum definition------------------------------------------------------------------- typedef enum MotorPwm{PWM_CLOSE, PWM_OPEN}EMotorPwm; //Motor Pwm Status typedef enum AirPressure{AP_LOW, AP_NORMAL, AP_HIGH}EAirPressure; //Air Pressure Status //Status parameter structure definition---------------------------------------------------- typedef struct StatusParameter { Byte byStatus; //Current Status Byte byPrevious; //Previous value Byte byFrequency; //Status frequency Word wCounter; //Status duration time }TStatusParameter, * pTStatusParameter; //Status parameter initialization---------------------------------------------------------- //Motor Pwm Status TStatusParameter tsMotorPwm = {.byStatus = PWM_OPEN, .byPrevious = PWM_CLOSE, .byFrequency = 0, .wCounter = 0 //Unit: s }; //Air Pressure Status TStatusParameter tsAirPressure = {.byStatus = AP_NORMAL, .byPrevious = AP_NORMAL, .byFrequency = 0, .wCounter = 0 //Unit: ms };
note:定义历史值方便检测状态转换的跳变变化。状态常常需要记录持续的时间,因此加入一个计数器可用于计时。在一段时间内有时还需要记录状态发生的次数,因此需要一个变量记录状态发生频度。
一种运行状态可能存在两种以上的状态值,且不同的状态值有不同的含义,因此无法用统一的枚举类型。对于一组状态值可以单独使用一组枚举表示,枚举的参数封装性更好,宏定义参数较“散”但省空间,综合多种因素在状态繁多的情况下我选择用封装性更好的枚举。
对于状态的检测,由于状态是随着程序运行实时变化的且不固定,因此无法在编译阶段对状态值的有效性检测。这就需要我们根据实际逻辑需要增加相应的检测代码。由于状态值都通过枚举定义好,因此不需要做参数越界失效和符号异常失效判断,状态值都是预知且固定的所以不需要跳变失效判断,其他失效根据实际情况添加检验代码。-
故障型参数。
故障型参数用于记录当前或历史的故障发生情况,并决定是否要发出报警信号或停机等操作。我们可以定义为如下结构体://Unusual enum definition------------------------------------------------------------------- typedef enum UnusualSymbol{ABNORMAL, NORMAL}EUnusualSymbol; //Unusual state //Unusual parameter structure definition---------------------------------------------------- typedef struct UnusualParameter { EUnusualSymbol eUnusualSymbol; //Unusual symbol EUnusualSymbol ePrevious; //Previous value EUnusualSymbol eWarningSymbol; //Unusual Warning symbol Byte byFrequency; //Unusual frequency Word wCounter; //Unusual duration time }TUnusualParameter, * pTUnusualParameter; //Unusual parameter initialization---------------------------------------------------------- //Head temperature over TUnusualParameter tuHeadTempOver = {.eUnusualSymbol = NORMAL, .ePrevious = NORMAL, .eWarningSymbol = NORMAL, .byFrequency = 0, .wCounter = 0 //Unit: ms };
note:定义历史值方便检测故障的发生和恢复变化。对于故障常常需要检测故障的持续时间和频度,因此定义相关成员变量。根据故障的持续时间和频度有时会引起其他动作,比如报警或停机,因此引入报警标志。
故障的状态只需要两种,即异常或正常,因此可以同意定义枚举类型。
对于故障的检测,由于故障是在程序运行中发生,因此对故障参数有效性的检测需要实时进行。由于故障参数有固定的枚举类型,因此不需要越界失效、符号异常、跳变失效判断,其他失效根据实际情况添加检验代码。-
普通值参数。
普通值参数是较为庞大的一类参数,这类参数的值类型不一,值之间的关联性可以很复杂,每种值各有特点,参数的有效性检验很难做统一的处理。我们可以定义为如下结构体://Sign enum definition------------------------------------------------------------------- typedef enum Sign{SIGN_MINUS = -1, SIGN_PLUS = 1}ESign; //Unusual state typedef enum Lock{LOCK_UNLOCK = 0, LOCK_LOCK = 1}ELock; //Resource lock //Value parameter structure definition---------------------------------------------------- typedef struct ValueParameter { ESign eSign; //Value: SIGN_PLUS of SIGN_MINUS Word wValue; //Current value Word wPrevious; //Previous value Word wDefault; //Default value Word wCounter; //duration time Word wUpperLimit; //Upper limit Word wLowerLimit; //Lower limit Word wJumpLimit; //Jump limit Word wOverdueLimit; //Overdue limit Byte wLock; //Resource lock }TValueParameter, * pTValueParameter; //Value parameter initialization---------------------------------------------------------- //Motor Rpm TValueParameter tvMotorActualRpm = {.eSign = SIGN_PLUS, .wValue = 0, //Unit: Rpm .wPrevious = 0, .wDefault = 1000, .wCounter = 0, //Unit: ms .wUpperLimit = 2000, .wLowerLimit = 0, .wJumpLimit = 1000, .wOverdueLimit = 0, //Unit: s .wLock = LOCK_UNLOCK }; //Speed TValueParameter tvSpeed = {.eSign = SIGN_PLUS, .wValue = 0, //Unit: 0.1K/M .wPrevious = 0, .wDefault = 400, .wCounter = 0, //Unit: ms .wUpperLimit = 200, .wLowerLimit = 0, .wJumpLimit = 1000, .wOverdueLimit = 0, //Unit: s .wLock = LOCK_UNLOCK };
-
-
怎么处理?
-
用断言检查永远不应该发生的错误
优点:错误定位,给代码调试带来极大的便利,创建更稳定、质量更好且不易于出错的代码。
缺点:频繁的调用会极大的影响程序的性能,增加额外的开销。
相比于函数,调用函数需要额外的队栈开销,宏函数节省开销但同一段代码存在多个副本。使用宏函数会引起很多副作用需要小心。断言使用形式如下:
//#define NDEBUG #ifndef NDEBUG #define _assert(bExpression) \ do{ \ if (!(bExpression)) \ { \ ErrorDeal(); /*Error deal*/ \ } \ }while(0) #else #define _assert(bExpression) ((void)0) #endif int main() { Byte byNumber1 = 10; Byte byNumber2 = 0; Byte byResult = 0; _assert(0 != byNumber2); //Cannot be 0 byResult = byNumber1 / byNumber2; printf("%d", byNumber2); system("pause"); return 0; }note:通过定义宏NDEBUG来控制断言的开启或关断。用于对较为严重的错误统一处理。另外,禁止把必须执行的代码放在断言中,断言关闭后功能将失效。
用断言的两种形式:
1、断言一直开启。不论是调试版还是发行版都将断言函数开启。
2、可以在测试时启用断言,而在部署时禁用断言。同样,程序投入运行后,最终用户在遇到问题时可以重新起用断言。它可以快速发现并定位软件问题,同时对系统错误进行自动报警。断言可以对在系统中隐藏很深,用其它手段极难发现的问题可以用断言来进行定位,从而缩短软件问题定位时间,提高系统的可测性。实际应用时,可根据具体情况灵活地设计断言。前置条件断言:代码执行之前必须具备的特性
后置条件断言:代码执行之后必须具备的特性
前后不变断言:代码执行前后不能变化的特性
-
错误处理代码
用错误处理代码来处理预期会发生的状况,用断言来处理绝不应该发生的状况。通常用错误处理来检查有害的输入数据。断言检查代码中的bug。根据情形的不同,你可以返回中立值、换用下一个正确数据、返回与前次相同的值、换用最接近的有效值、在日志文件中记录警告信息、返回一个错误吗、调用错误处理子程序或对象、显示出错信息或者关闭程序——或把这些技术结合起来使用。
1、返回中立值
对于一些“危害”并不严重的错误,最佳的做法就是继续执行操作并简单的返回一个没有危害的数值,比如数值0或空指针。2、给出一个修正的数据
对于can网络中不断更新但实时性要求并不高的数据,比如电机温度,短时间内数据丢失可是使用历史值。3、换用最接近的合法值
有些情况下可以换用最接近的合法值,当值大于上限或者小于下限值时,可以直接去上下限边界值。4、把警告信息记录到日志文件中
在检测到错误数据的时候,你可以选择在日志文件中记录一条警告信息,然后继续执行。这种方法可以同其他的错误处理技术结合使用。5、返回一个错误码
你可以决定只让系统的某些部分处理错误。其他部分则不在本地(局部)处理错误,而只是简单地报告有错误发生和发生的是何种错误,并信任调用链上游的某个子程序会处理该错误。通知系统其余部分已经发生错误可以采用下列方法:- 设置一个状态变量的值
- 用状态值作为函数的返回值
- 用语言内建的异常机制抛出一个异常
需要决定系统里哪部分应该直接处理错误,哪部分只是报告所发生的错误。对于安全性很重要的部分请确认调用的子程序总会检查返回的错误码。
6、调用错误处理子程序或对象
这种方法需要把错误处理都集中在一个全局的错误处理子程序或对象中,使得调试工作更为简单。而代价是整个程序都要知道这个集中点并与之紧密耦合。如果你想在其他系统中重用其中的某些代码,那就得把错误处理代码一并带过去。7、错误发生时发出错误信息
在调试模式下,当错误发生时为了帮助调试者尽快定位问题所在位置,可以通过打印显示或者报文将错误信息较为详细的发出。8、在局部处理错误
针对一些设计方案可能更适合在局部立即解决所有遇到的问题,具体的错误处理方法需要由该模块的设计者根据问题特点自行决定。这种方法给力模块程序员很大的灵活度,但这样做会导致错误记录和发出错误信息等代码散布到整个系统中,从而使得设计者还得考虑错误记录和错误发送相关的故障问题。能在局部立即解决的问题最好在内部立即解决。9、关闭或复位程序
程序发生较为严重的错误时,比如堆栈溢出导致运行环境被破坏,所依附的操作系统严重故障,甚至收到恶意攻击时可能需要关闭和复位程序。确定一种通用的处理错误参数的方法,是架构层次(或称高层次)的设计决策。如果在高层次处理错误,低层次只是汇报错误,那么就要确保高层次真的处理有错误!千万不要忽略错误信息,在函数的返回值返回故障信息,记得检查函数的返回值,即使你对某个函数有足够的自信。当有错误产生时,请记录并反馈对应的故障码和它描述的信息。
-
异常
如果一个子程序在运行过程中遇到了预料之外的情况,但这个情况又必须处理否则会影响功能的使用或程序的运行,这个时候需要子程序将异常抛出,把“问题”交给能解释并处理好它的代码。这属于一种错误处理机制。
能在局部处理的错误优选在局部处理,不能立即处理或局部无法处理的问题可抛出异常。不能用异常来推卸责任。异常处理函数需要了解大量子程序可能抛出何种错误并给出处理办法,弱化了程序的封装性,增加了程序的复杂程度。
每种异常都对应一种特殊情况,因此要确保异常信息中含有为理解异常抛出原因所需的充分信息,这对于读取异常信息的人来说是很有价值的。比如当发生数据越界时,除了抛出对应的故障码标识数据越界外,还应该给出上下界和非法的数据值。
总结:断言、错误处理代码、异常都需要有完备的故障捕获处理,以及故障信息的记录反馈。因此有必要考虑一种方法以确保异常处理的一致性,即创建一个集中的异常报告机制。这个机制需要能对异常信息进行一个集中的格式化和存储。c语言不像c++和java自带异常机制,但c语言可以借助setjmp和longjmp实现异常处理机制。实现代码如下:
typedef unsigned char Byte; typedef Uint16 Word; #define String char * //Don't use typedef //Exception information structure----------------------------------------------------------- typedef struct Exception { char * description; }TException, * pTException; //Exception stack structure------------------------------------------------------------ typedef struct ExceptionFrame { struct ExceptionFrame * prev; jmp_buf env; //Use in setjmp() //Exception information const TException * ptException; //About Exception const String strFileName; //File name const String strFunctionName; //Function name Word wLineNumber; //Line number }TExceptionFrame, * pTExceptionFrame; //Exception status---------------------------------------------------------------------- typedef enum ExceptionStatus{ EXCEPT_ENTERED = 0, EXCEPT_RAISED, EXCEPT_HANDLED, EXCEPT_FINALIZED }EExceptionStatus; /************************************************************ * try-catch-finally definition * *************************************************************/ //try deal-------------------------------------------------------------------------------- #define _try \ { \ Byte byExceptFlg; /*Return by setjmp()*/ \ TExceptionFrame tExceptionNode; \ \ /*Push stack*/ \ tExceptionNode.prev = ptExceptionStackTop; \ ptExceptionStackTop = &tExceptionNode; \ \ byExceptFlg = setjmp(tExceptionNode.env); /*Set jump point*/ \ if(EXCEPT_ENTERED == byExceptFlg) \ { /*Here check and throw your exception*/ //... //catch deal------------------------------------------------------------------------------- #define _catch(tException) \ if(EXCEPT_ENTERED == byExceptFlg) /*No Exception*/ \ { \ ptExceptionStackTop = ptExceptionStackTop -> prev; /*Pop stack*/ \ } \ } \ else if(&(tException) == tExceptionNode.ptException) \ { \ byExceptFlg = EXCEPT_HANDLED; /*Here deal your exception*/ //... //finally deal------------------------------------------------------------------------------ #define _finally \ if(EXCEPT_ENTERED == byExceptFlg) /*No Exception*/ \ { \ ptExceptionStackTop = ptExceptionStackTop -> prev; /*Pop stack*/ \ } \ } \ { \ if(EXCEPT_ENTERED == byExceptFlg) \ { \ byExceptFlg = EXCEPT_FINALIZED; \ } /*Here must deal*/ //... //end try deal------------------------------------------------------------------------------- #define _end_try \ if(EXCEPT_ENTERED == byExceptFlg) /*No Exception*/ \ { \ ptExceptionStackTop = ptExceptionStackTop -> prev; /*Pop stack*/ \ } \ } \ if(EXCEPT_RAISED == byExceptFlg) \ { \ \ } \ }while(0) //_throw() deal------------------------------------------------------------------------------ #define _throw(tException) ExceptRaise(&(tException), __FILE__, __FUNCTION__, __LINE__) /************************************************************ * Exception deal function * *************************************************************/ pTExceptionFrame ptExceptionStackTop = NULL; //Stack top void ExceptRaise(const TException * const ptException, const String const strFileName, const String const strFunctionN ame, const wLineNumber) { pTExceptionFrame pStackTop = ptExceptionStackTop; if(NULL == ptException) //Check NULL exception { //Do Something //... } else { if(NULL == pStackTop) //Check stack empty { //Do Something //... } else { //Record some information pStackTop -> ptException = ptException; pStackTop -> strFileName = strFileName; pStackTop -> strFunctionName = strFunctionName; pStackTop -> wLineNumber = wLineNumber; ptExceptionStackTop = ptExceptionStackTop -> prev; //Pop stack longjmp(pStackTop -> env, EXCEPT_RAISED); } } } int main() { TException A = {"A exception"}; _try { _throw(A); } _catch(A) { printf("A exception\n"); }_end_try; system("pause"); return 0; }预料之外的错误处理。
异常中没有捕获到的异常情况,我们认为是意外异常,发生意外异常时的一种常见做法是终止程序运行。-
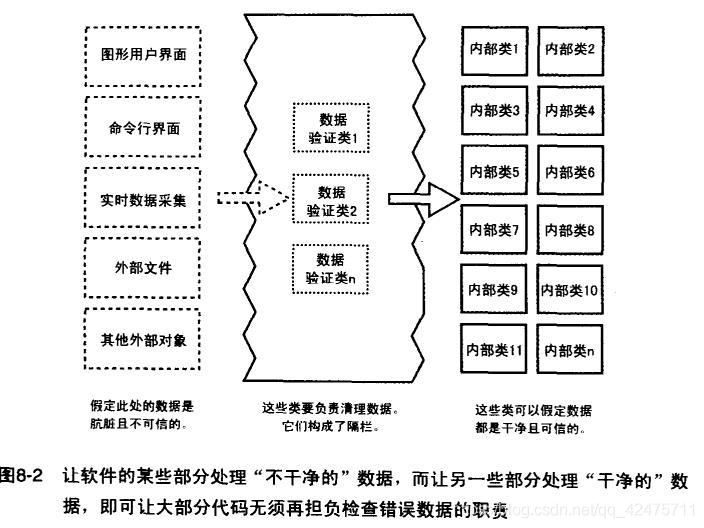
隔栏。
数据源有两类,一类是外部传入一类是内部运算产生。由于外部数据的处理过程和存储环境对本模块设计者来说是模糊或不可见的,而内部数据处理直接或间接依赖于外部数据。因此我们假定外部数据是肮脏且不可信的,内部数据假定为干净(仅对少量安全性高数据检测)。不可信的外部数据传入内部需要一个统一数据清理的环节,这就是隔栏的作用。隔栏与断言的关系:
隔栏的使用使断言和错误处理有了清晰的区分。隔栏外部的数据应该使用错误处理技术,在那里对数据做到任何假定都是不安全的。而隔栏内部的程序里就应该使用断言技术,因为传进来的数据都已在通过隔栏时被清理过了。如果隔栏内部的某个子程序检测到了错误的数据,那么应该是程序李的错误而不是数据里的错误。
——《代码大全2》
 -
错误日志处理。
随着项目规模的不断扩大,日志的应用对于维护程序的正常运行具有重要的意义。当一个程序崩溃时如果没有抛出异常信息,对于维护人员来说无法快速定位问题,更别谈去解决问题了。
日志时程序员解决问题的第一手资料。异常发生时,从别人口述的情况往往存在不准确或模糊,为了更好的解决问题我们需要当时发生了什么,用户当时做了什么操作,运行环境有无异常,数据有哪些变化,异常时否反复发生,是偶发还是有必然起因。若日志做了详细记录对于问题的定位和解决起到举足轻重的作用。-
日志的作用
- 记录用户操作的审计日志,甚至就是监管部门的要求。
- 记录程序运行的流程。
- 记录数据的变化。
- 记录异常信息,快速定位问题根源。
- 数据统计和性能分析(程序性能或设备性能)。
-
如何做好程序日志
-
日志的可读性
看日志的是程序员,但并不一定是接触过相关模块或看过这部分源码的程序员。日志应该一路了然,信息详细但又不重复冗余。日志信息应该准确可靠,避免含糊不清的日志。 -
日志的资源消耗
日志的记录毫无疑问需要消耗资源,占用程序运行的时间资源、占用io口写入文件或数据库,占用磁盘或EE存储。日志信息应该简明扼要,避免打印无意义的日志,减少重复日志。日志应该做成滚动式,记录一段时间内的日志和错误等级高的日志,防止日志文件写满存储空间。 -
日志应该分等级
日志的等级可以分为FATAL、ERROR、INFO、DEBUG、TRACE。-
FALTAL(致命)
FALTAL是错误等级最高的重大错误,它的出现程序无法自我恢复,必须通过复位程序才能运行。该类错误应该记录错误码。 -
ERROR(错误)
这类错误虽然发生,但可以通过程序来弥补或忽略来保证程序正常运行。该类错误需要记录错误码。 -
WARN(警告)
表示会出现潜在错误的情形,比如参数未传入,使用默认了参数,参数持续时长一直未变化,这类错误虽异常但在程序员预期之内,并且程序做了充分的弥补措施。也建议记录错误码。 -
INFO(信息)
用于记录程序的运行过程,打印一些程序运行中的重要信息,但要避免滥用。 -
DEBUG(调试)
用于开发调试过程中,由程序员自由控制,具有较高灵活度。 -
TRACE(跟踪)
一般不使用。用于跟踪函数的调用,不含变量只反应函数调用关系。
-
-
代码示例:
//Log Level definition----------------------------------------------------------------- typedef enum LogLevel {LOG_LEVEL_TRACE, LOG_LEVEL_DEBUG, LOG_LEVEL_INFO, LOG_LEVEL_WARN, LOG_LEVEL_ERROR, LOG_LEVEL_FATAL} ELogLevel; // 定义FATAL级别输出宏 #define LOG_FATAL(wFaultCode, strFormat, ...) LogPrint(LOG_LEVEL_FATAL, "[%s <%d>](%s) " "[%#08X]" strFormat "\n", __FILE__, __LINE__, __FUNCTION__, wFaultCode, ##__VA_ARGS__) // 定义ERROR级别输出宏 #define LOG_ERROR(wFaultCode, strFormat, ...) LogPrint(LOG_LEVEL_ERROR, "[%s <%d>](%s) " "[%#08X]" strFormat "\n", __FILE__, __LINE__, __FUNCTION__, wFaultCode, ##__VA_ARGS__) // 定义WARN级别输出宏 #define LOG_WARN(wFaultCode, strFormat, ...) LogPrint(LOG_LEVEL_WARN, "[%s <%d>](%s) " "[%#08X]" strFormat "\n", __FILE__, __LINE__, __FUNCTION__, wFaultCode, ##__VA_ARGS__) // 定义INFO级别输出宏 #define LOG_INFO(strFormat, ...) LogPrint(LOG_LEVEL_INFO, "[%s <%d>](%s) " strFormat "\n", __FILE__, __LINE__, __FUNCTION__, ##__VA_ARGS__) // 定义DEBUG级别输出宏 #define LOG_DEBUG(strFormat, ...) LogPrint(LOG_LEVEL_DEBUG, "[%s <%d>](%s) " strFormat "\n", __FILE__, __LINE__, __FUNCTION__, ##__VA_ARGS__) // 定义TRACE级别输出宏 #define LOG_TRACE(strFormat, ...) LogPrint(LOG_LEVEL_TRACE, "[%s <%d>)](%s) " strFormat "\n", __FILE__, __LINE__, __FUNCTION__, ##__VA_ARGS__)输出结果展示:
 -
-
错误码。
软件运行中由于错误类型众多,为了对错误进行区分,系统设定了错误码(error code),软件通过内部的自检机制超出错误并抛出给开发人员,开发人员通过错误码快速分析错误原因。//Error description---------------------------------------------------------------------------------- //Belongs to #define AIR_COMPRESSOR (0X01 << 24) #define STEERING_MOTOR (0X02 << 24) //... //Error level #define ERROR_LEVEL_1 (0X01 << 16) #define ERROR_LEVEL_2 (0X02 << 16) #define ERROR_LEVEL_3 (0X03 << 16) #define ERROR_LEVEL_4 (0X04 << 16) #define ERROR_LEVEL_5 (0X05 << 16) #define ERROR_LEVEL_6 (0X06 << 16) //Error categories #define CATEGORIES_FUNCTION (0X01 << 8) #define CATEGORIES_VALUE (0X02 << 8) //... //About function #define DOMAIN_ERROR (AIR_COMPRESSOR | ERROR_LEVEL_4 | CATEGORIES_FUNCTION | 0X01) #define RANGE_ERROR (AIR_COMPRESSOR | ERROR_LEVEL_4 | CATEGORIES_FUNCTION | 0X02) #define INVALID_ARGUMENT (AIR_COMPRESSOR | ERROR_LEVEL_4 | CATEGORIES_FUNCTION | 0X03) //... //About value #define OVERFLOW_ERROR (AIR_COMPRESSOR | ERROR_LEVEL_4 | CATEGORIES_VALUE | 0X01) #define UNDERFLOW_ERROR (AIR_COMPRESSOR | ERROR_LEVEL_4 | CATEGORIES_VALUE | 0X02) #define OUT_OF_BOUNDS (AIR_COMPRESSOR | ERROR_LEVEL_4 | CATEGORIES_VALUE | 0X03) #define LENGTH_ERROR (AIR_COMPRESSOR | ERROR_LEVEL_4 | CATEGORIES_VALUE | 0X04) //... //... -
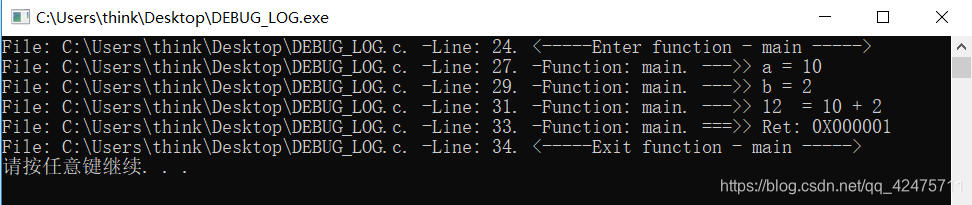
调试log。
跟踪代码运行轨迹,担当开发环境中的调试利器,提高开发效率,增强查错能力。
区别出产品代码与开发代码。产品级软件要求运行快速、节约资源、较高安全性,而开发中的软件可以运行缓慢、资源利用奢侈、提供一些额外的辅助调试的不安全操作。开发期间牺牲一些速度和资源换取使开发顺畅的内置工具,比如调试log,用于监视程序运行流程和数据。#include <stdio.h> #include <stdlib.h> typedef unsigned int Uint16; typedef unsigned char Byte; typedef Uint16 Word; //Function enum definition----------------------------------------------------------------- typedef enum Switch {DISABLE, ENABLE} ESwitch; //Switch variable #define DEBUG_LOG #ifdef DEBUG_LOG //Global variable----------------------------------------------------------------- ESwitch bDebugSwtich = DISABLE; //Switch function #define DEBUG_SWITCH(bSwitch) bDebugSwtich = (bSwitch) //Basic function #define DEBUG_ENTER_FUN() (DISABLE == bDebugSwtich) ? ((void)0) : printf("File: %s. -Line: %d. <-----Enter function - %s ----->\n", __FILE__, __LINE__, __FUNCTION__) #define DEBUG_EXIT_FUN() (DISABLE == bDebugSwtich) ? ((void)0) : printf("File: %s. -Line: %d. <-----Exit function - %s ----->\n", __FILE__, __LINE__, __FUNCTION__) #define DEBUG_PRINT(strFormat, ...) (DISABLE == bDebugSwtich) ? ((void)0) : printf("File: %s. -Line: %d. -Function: %s. --->> " strFormat "\n", __FILE__, __LINE__, __FUNCTION__, ##__VA_ARGS__) #define DEBUG_RETURN(Ret) (DISABLE == bDebugSwtich) ? ((void)0) : printf("File: %s. -Line: %d. -Function: %s. ===>> Ret: %#08X\n", __FILE__, __LINE__, __FUNCTION__, Ret); //Extension function #define DEBUG_NUMBER(Number) (DISABLE == bDebugSwtich) ? ((void)0) : printf("File: %s. -Line: %d. -Function: %s. --->> " #Number " = %d\n", __FILE__, __LINE__, __FUNCTION__, Number) #else //Switch function #define DEBUG_SWITCH(bSwitch) ((void)0) //Basic function #define DEBUG_ENTER_FUN() ((void)0) #define DEBUG_EXIT_FUN() ((void)0) #define DEBUG_PRINT(strFormat, ...) ((void)0) #define DEBUG_RETURN(Ret) ((void)0) //Extension function #define DEBUG_NUMBER(Number) ((void)0) #endif int main() { int a = 0; int b = 0; int sum = 0; int Return = 0x00000001; DEBUG_SWITCH(ENABLE); DEBUG_ENTER_FUN(); a = 10; DEBUG_NUMBER(a); b = 2; DEBUG_NUMBER(b); sum = a + b; DEBUG_PRINT("%d = %d + %d", sum, a, b); DEBUG_RETURN(Return); DEBUG_EXIT_FUN(); DEBUG_SWITCH(DISABLE); system("pause"); return Return; }输出结果展示:
 -
正确性与健壮性抉择。
- 正确性意味着结果永远是正确的,如果出错,宁愿不给出结果也不要给定一个不准确的值。
- 健壮性意味着通过一些措施,保证软件能正常运行下去,即使有时候会有一些不准确的值出现。
-
进攻式编程。
它的思想主要是提倡在开发阶段让问题尽可能显现出来,并且将问题扩大使得问题难以被忽视,这样才有助于问题不被忽视得到解决。而在产品运行时解决问题或让它能够自我纠正恢复。
-















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









