






一:首先查看seatunnel提交任务到flink集群的时候的shell脚本start-seatunnel-flink-13-connector-v2.sh,查看最后会调用一个类FlinkStarter,如下图所示
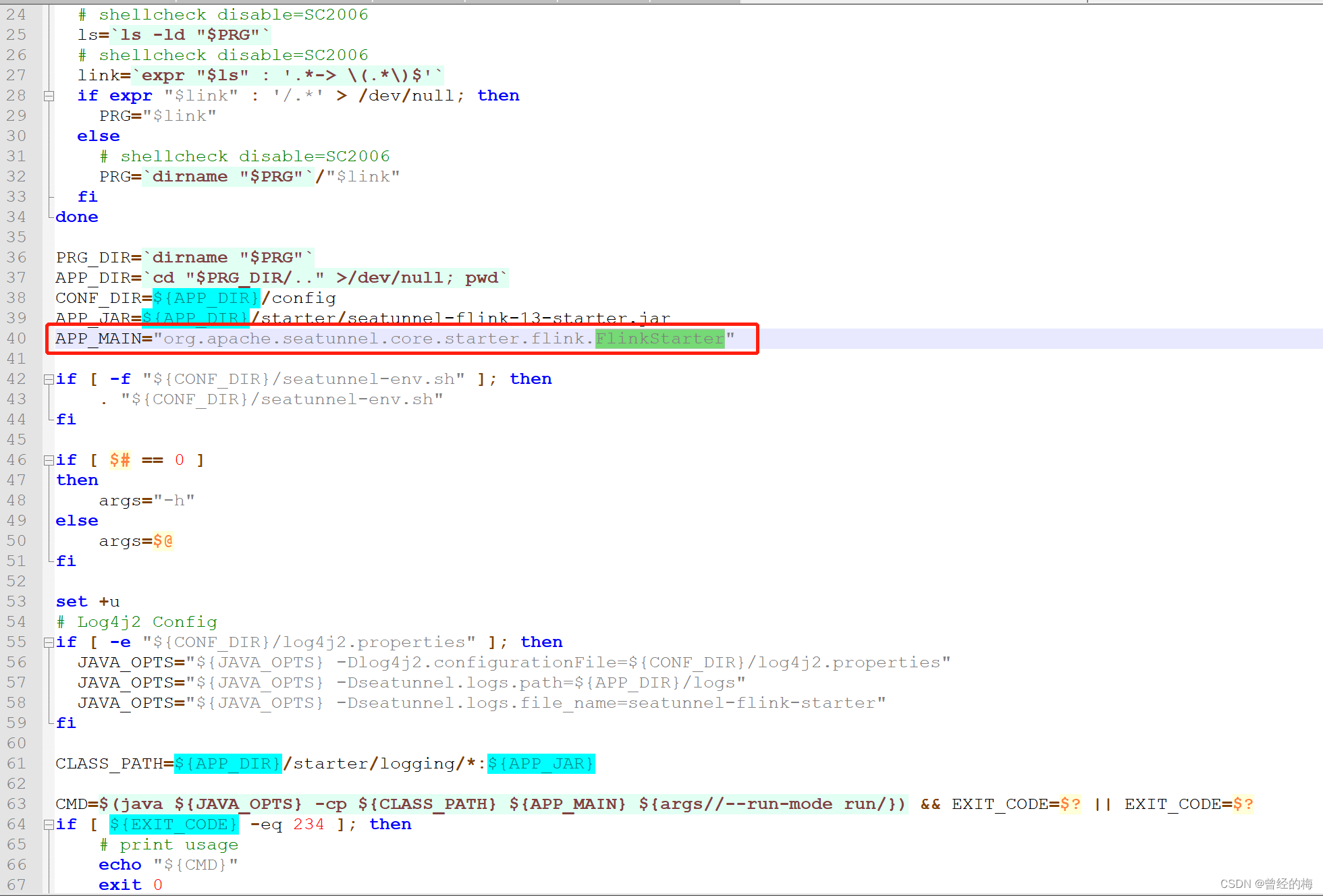
这个类主要调用SeaTunnelFlink这个类,并且生成相应的shell脚本
二:跟着相应的类走,最后会调用FlinkExecution,这个类的execute方法,其中这个方法里面会对flink的三大组件source,transform,以及sink进行相应的封装
public void execute() throws TaskExecuteException {
List<DataStream<Row>> dataStreams = new ArrayList<>();
dataStreams = sourcePluginExecuteProcessor.execute(dataStreams);
dataStreams = transformPluginExecuteProcessor.execute(dataStreams);
sinkPluginExecuteProcessor.execute(dataStreams);
log.info(
"Flink Execution Plan: {}",
flinkRuntimeEnvironment.getStreamExecutionEnvironment().getExecutionPlan());
log.info("Flink job name: {}", flinkRuntimeEnvironment.getJobName());
try {
flinkRuntimeEnvironment
.getStreamExecutionEnvironment()
.execute(flinkRuntimeEnvironment.getJobName());
} catch (Exception e) {
throw new TaskExecuteException("Execute Flink job error", e);
}
}接下来跟着我,逐步走进这三大组件
1:首先是组件sourcePluginExecuteProcessor,这个组件主要是用于生成source端,这个方法也是所有的封装当中最终要的一个类,接下来,我们仔细研究一下这个类,这个类里面主要调用这个方法,
@Override
public List<DataStream<Row>> execute(List<DataStream<Row>> upstreamDataStreams) {
StreamExecutionEnvironment executionEnvironment =
flinkRuntimeEnvironment.getStreamExecutionEnvironment();
List<DataStream<Row>> sources = new ArrayList<>();
for (int i = 0; i < plugins.size(); i++) {
SeaTunnelSource internalSource = plugins.get(i);
BaseSeaTunnelSourceFunction sourceFunction;
//通过这两种方式来判断是协同模式还是并行模式
//如果需要配置成为协同模式的话,需要配置参数type = "coordinator"
if (internalSource instanceof SupportCoordinate) {
sourceFunction = new SeaTunnelCoordinatedSource(internalSource);
} else {
sourceFunction = new SeaTunnelParallelSource(internalSource);
}
DataStreamSource<Row> sourceStream =
addSource(
executionEnvironment,
//主要是这个类
sourceFunction,
"SeaTunnel " + internalSource.getClass().getSimpleName(),
internalSource.getBoundedness()
== org.apache.seatunnel.api.source.Boundedness.BOUNDED);
Config pluginConfig = pluginConfigs.get(i);
if (pluginConfig.hasPath(CommonOptions.PARALLELISM.key())) {
int parallelism = pluginConfig.getInt(CommonOptions.PARALLELISM.key());
sourceStream.setParallelism(parallelism);
}
//将数据源注册成为一张表,提供给transform端进行调用
registerResultTable(pluginConfig, sourceStream);
sources.add(sourceStream);
}
return sources;
}这个方法里面首先是生成了,一个sourceFunction,之后将sourceFunction传递给了Flink的程序,生成一个datastream
1)继续深究sourceFunction这个变量,这个变量,这次只是深究了SeaTunnelParallelSource这个类里面的东西,这个类继承了类BaseSeaTunnelSourceFunction,并且需要调用方法run(),其中run的源码如下所示
@SuppressWarnings("checkstyle:MagicNumber")
@Override
public void run(SourceFunction.SourceContext<Row> sourceContext) throws Exception {
internalSource.run(
new RowCollector(
//数据来源来自这个变量
sourceContext,
sourceContext.getCheckpointLock(),
source.getProducedType()));
// Wait for a checkpoint to complete:
// In the current version(version < 1.14.0), w hen the operator state of the source changes
// to FINISHED, jobs cannot be checkpoint executed.
final long prevCheckpointId = latestTriggerCheckpointId.get();
// Ensured Checkpoint enabled
if (getRuntimeContext() instanceof StreamingRuntimeContext
&& ((StreamingRuntimeContext) getRuntimeContext()).isCheckpointingEnabled()) {
while (running && prevCheckpointId >= latestCompletedCheckpointId.get()) {
Thread.sleep(100);
}
}
}进入到RowCollector这个类里面去,里面最主要的一个方法就是collect,将数据进行收集,然后转换,最后封装
public void collect(SeaTunnelRow record) {
try {
//将数据转换成为row的格式,并且进行收集
internalCollector.collect(rowSerialization.convert(record));
} catch (IOException e) {
throw new RuntimeException(e);
}
}进入到internalSource这个变量的run方法里面去,其中实现的方法,主要是ParallelSource,这个类里面,主要是对读取数据进行了相应的封装,主要是采用了,多个reader的方式来读取表当中的数据的方式,来读取数据
public ParallelSource(
SeaTunnelSource<T, SplitT, StateT> source,
Map<Integer, List<byte[]>> restoredState,
int parallelism,
int subtaskId) {
this.source = source;
this.subtaskId = subtaskId;
this.parallelism = parallelism;
this.splitSerializer = source.getSplitSerializer();
this.enumeratorStateSerializer = source.getEnumeratorStateSerializer();
this.parallelEnumeratorContext =
new ParallelEnumeratorContext<>(this, parallelism, subtaskId);
this.readerContext = new ParallelReaderContext(this, source.getBoundedness(), subtaskId);
// Create or restore split enumerator & reader
//创建一个拆分的split和用于读取数据的reader,并且还需要进行查看到底是初始化还是从任务当中进行恢复的情况
try {
if (restoredState != null && restoredState.size() > 0) {
StateT restoredEnumeratorState = null;
if (restoredState.containsKey(-1)) {
//从检查点当中得到split的分发器,的当前状态
restoredEnumeratorState =
enumeratorStateSerializer.deserialize(restoredState.get(-1).get(0));
}
//恢复到任务停止前的每一个taskid的,可能设置了并行度,所以会有一个循环的存在
restoredSplitState = new ArrayList<>(restoredState.get(subtaskId).size());
for (byte[] splitBytes : restoredState.get(subtaskId)) {
restoredSplitState.add(splitSerializer.deserialize(splitBytes));
}
//从恢复的状态当中创建一个分发器
splitEnumerator =
source.restoreEnumerator(
parallelEnumeratorContext, restoredEnumeratorState);
} else {
//如果不是恢复状态的话,则需要直接进行相应的初始化
restoredSplitState = Collections.emptyList();
splitEnumerator = source.createEnumerator(parallelEnumeratorContext);
}
//创建读取器
reader = source.createReader(readerContext);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public void open() throws Exception {
executorService =
ThreadPoolExecutorFactory.createScheduledThreadPoolExecutor(
1, String.format("parallel-split-enumerator-executor-%s", subtaskId));
splitEnumerator.open();
if (restoredSplitState.size() > 0) {
splitEnumerator.addSplitsBack(restoredSplitState, subtaskId);
}
reader.open();
parallelEnumeratorContext.register();
//注册一个读取器
splitEnumerator.registerReader(subtaskId);
}
@Override
public void run(Collector<T> collector) throws Exception {
Future<?> future =
executorService.submit(
() -> {
//在线程池当中运行这个切分器,将表的数据切分成为多个,然后分给多个
//reader
try {
splitEnumerator.run();
} catch (Exception e) {
throw new RuntimeException("SourceSplitEnumerator run failed.", e);
}
});
while (running) {
if (future.isDone()) {
future.get();
}
//最后通过这个方式来读取所有的快照数据?
reader.pollNext(collector);
Thread.sleep(SLEEP_TIME_INTERVAL);
}
LOG.debug("Parallel source runs complete.");
}
@Override
public void close() throws IOException {
// set ourselves as not running;
// this would let the main discovery loop escape as soon as possible
running = false;
if (executorService != null) {
LOG.debug("Close the thread pool resource.");
executorService.shutdown();
}
if (splitEnumerator != null) {
LOG.debug("Close the split enumerator for the Apache SeaTunnel source.");
splitEnumerator.close();
}
if (reader != null) {
LOG.debug("Close the data reader for the Apache SeaTunnel source.");
reader.close();
}
}OK,上述就是source端的读数据方式
2:第二个大的组件是transform,在transform这个组件里面,可以发现,这个代码里面,首先是
DataStream<Row> stream = fromSourceTable(pluginConfig).orElse(input);通过这个方式来获取到一条流,至于为啥这样操作呢,是因为在source端,有一行这样的代码registerResultTable(pluginConfig, sourceStream);,所以才会优先得到这条流注册的表,没有得到这个表,才会得到这条流,最后通过调用方法flinkTransform来进行相应的转换,由于走的引擎是flink,所以转换操作,是跟flink框架一样的
public List<DataStream<Row>> execute(List<DataStream<Row>> upstreamDataStreams)
throws TaskExecuteException {
if (plugins.isEmpty()) {
return upstreamDataStreams;
}
DataStream<Row> input = upstreamDataStreams.get(0);
List<DataStream<Row>> result = new ArrayList<>();
for (int i = 0; i < plugins.size(); i++) {
try {
SeaTunnelTransform<SeaTunnelRow> transform = plugins.get(i);
Config pluginConfig = pluginConfigs.get(i);
DataStream<Row> stream = fromSourceTable(pluginConfig).orElse(input);
input = flinkTransform(transform, stream);
registerResultTable(pluginConfig, input);
result.add(input);
} catch (Exception e) {
throw new TaskExecuteException(
String.format(
"SeaTunnel transform task: %s execute error",
plugins.get(i).getPluginName()),
e);
}
}
return result;
}
protected DataStream<Row> flinkTransform(SeaTunnelTransform transform, DataStream<Row> stream) {
SeaTunnelDataType seaTunnelDataType = TypeConverterUtils.convert(stream.getType());
transform.setTypeInfo(seaTunnelDataType);
TypeInformation rowTypeInfo = TypeConverterUtils.convert(transform.getProducedType());
FlinkRowConverter transformInputRowConverter = new FlinkRowConverter(seaTunnelDataType);
FlinkRowConverter transformOutputRowConverter =
new FlinkRowConverter(transform.getProducedType());
DataStream<Row> output =
stream.flatMap(
new FlatMapFunction<Row, Row>() {
@Override
public void flatMap(Row value, Collector<Row> out) throws Exception {
SeaTunnelRow seaTunnelRow =
transformInputRowConverter.reconvert(value);
SeaTunnelRow dataRow = (SeaTunnelRow) transform.map(seaTunnelRow);
if (dataRow != null) {
Row copy = transformOutputRowConverter.convert(dataRow);
out.collect(copy);
}
}
},
rowTypeInfo);
return output;
}3:第二个大的组件是sink端,
sink端的代码如下所示,也是比较简单,一个简单的flink算子sinkto就可以将数据写入到目的端了
@Override
public List<DataStream<Row>> execute(List<DataStream<Row>> upstreamDataStreams)
throws TaskExecuteException {
DataStream<Row> input = upstreamDataStreams.get(0);
for (int i = 0; i < plugins.size(); i++) {
Config sinkConfig = pluginConfigs.get(i);
SeaTunnelSink<SeaTunnelRow, Serializable, Serializable, Serializable> seaTunnelSink =
plugins.get(i);
DataStream<Row> stream = fromSourceTable(sinkConfig).orElse(input);
seaTunnelSink.setTypeInfo(
(SeaTunnelRowType) TypeConverterUtils.convert(stream.getType()));
if (SupportDataSaveMode.class.isAssignableFrom(seaTunnelSink.getClass())) {
SupportDataSaveMode saveModeSink = (SupportDataSaveMode) seaTunnelSink;
DataSaveMode dataSaveMode = saveModeSink.getDataSaveMode();
saveModeSink.handleSaveMode(dataSaveMode);
}
//通过flink的stream流的方法sinkto方式写入到目的端
DataStreamSink<Row> dataStreamSink =
stream.sinkTo(new FlinkSink<>(seaTunnelSink))
.name(seaTunnelSink.getPluginName());
if (sinkConfig.hasPath(CommonOptions.PARALLELISM.key())) {
int parallelism = sinkConfig.getInt(CommonOptions.PARALLELISM.key());
dataStreamSink.setParallelism(parallelism);
}
}
// the sink is the last stream
return null;
}OK上述就是seatunnel提交任务到FLink集群当中的源码解析。















 2877
2877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









