







声明:本文为个人在同步学习中国大学MOOC《数据结构(陈越、何钦铭)》(视频地址:https://www.icourse163.org/learn/ZJU-93001#/learn/content) 结合课件PPT所做的个人学习笔记,未经授权,禁止转载!但是您可以关注我的公众号“分享猿”,来获取此数据结构笔记(包括word版,pdf版,以及MarkDown版本),以及课件PPT,您需要关注后回复关键词“N01”获取资源!
获取此数据结构笔记(包括word版,pdf版,以及MarkDown版本),以及课件PPT,pdf书籍等资源,请关注本人公众号后回复关键词“N01”获取资源!
若要获取更多OpenCV,数字图像处理,python,深度学习,机器学习,计算机视觉等高清PDF以及 更多有意思、实用的分享,可搜一搜 微信公共号 “分享猿” 免费获取资源。也可扫描下面的二维码关注,期待你的到来~

本节思维导图
使用软件 :Xmind

快速导航
为了更好对线性和和非线性结构本质特征的理解,我们先介绍线性表的查找,再介绍非线性的树。
一、查找
分为静态查找和动态查找

两种静态查找方法
方法1:顺序查找
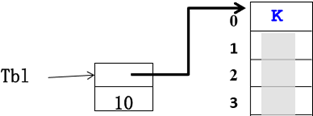
int SequentialSearch (StaticTable *Tbl, ElementType K)
{ /*在表Tbl[1]~Tbl[n]中查找关键字为K的数据元素*/
int i;
Tbl->Element[0] = K; /*建立哨兵*/
for(i = Tbl->Length; Tbl->Element[i]!= K; i--);
return i; /*查找成功返回所在单元下标;不成功返回0*/
}
顺序查找算法的时间复杂度为O(n)。
方法2:二分查找(Binary Search)
假设n个数据元素的关键字满足有序(比如:小到大)
k_1<k_2<…<k_n
并且是连续存放(数组),那么可以进行二分查找。
int BinarySearch ( StaticTable * Tbl, ElementType K)
{ /*在表Tbl中查找关键字为K的数据元素*/
int left, right, mid, NoFound=-1;
left = 1; /*初始左边界*/
right = Tbl->Length; /*初始右边界*/
while ( left <= right )
{
mid = (left+right)/2; /*计算中间元素坐标*/
if( K < Tbl->Element[mid]) right = mid-1; /*调整右边界*/
else if( K > Tbl->Element[mid]) left = mid+1; /*调整左边界*/
else return mid; /*查找成功,返回数据元素的下标*/
}
return NotFound; /*查找不成功,返回-1*/
}
二分查找算法具有对数的时间复杂度O(logN)
上述介绍的二分查找算法需要数据具备有序性,下面介绍的树则不需要这种有序性。
二、树
树是一种非常重要的非线性数据结构
2.1树的定义

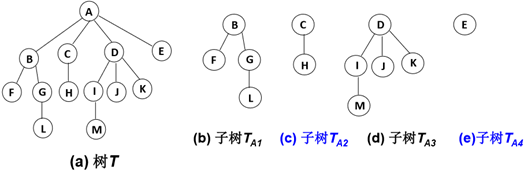
2.2树的特征
- 子树是不相交的;
- 除了根结点外,每个结点有且仅有一个父结点;
- 一棵N个结点的树有N-1条边。
下列不符合树的特征所以不是树

2.3树的一些基本术语
- 结点的度(Degree):结点的子树个数
- 树的度 :树的所有结点中最大的度数
- 叶结点(Leaf) :度为0的结点
- 父结点(Parent) :有子树的结点是其子树 的根结点的父结 点
- 子结点(Child) :若A结点是B结点的父结 点,则称B结点是A结点的子结点;子结点也 称孩子结点。
- 兄弟结点(Sibling) :具有同一父结点的各 结点彼此是兄弟结点。
- 路径和路径长度 :从结点n1到nk的路径为一 个结点序列n1 , n2 ,… , nk , ni是 ni+1的父结 点。路径所包含边的个数为路径的长度。
- 祖先结点(Ancestor) :沿树根到某一结点路 径上的所有结点都是这个结点的祖先结点。
- 子孙结点(Descendant) :某一结点的子树 中的所有结点是这个结点的子孙。
- 结点的层次(Level) :规定根结点在1层,其它任一结点的层数是其父结点的层数加1。
- 树的深度(Depth) :树中所有结点中的最 大层次是这棵树的深度。
2.4树的表示
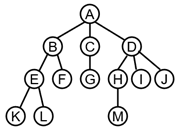
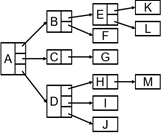
树的儿子-兄弟表示法


如此,任意一棵树都可以表示为二叉树了!
三、二叉树
3.1定义
二叉树T:一个有穷的结点集合。
这个集合可以为空
若不为空,则它是由根结点和称为其左子树TL和右子树TR的 两个不相交的二叉树组成。

3.2特殊二叉树
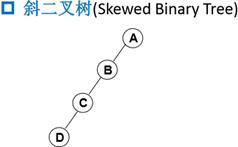
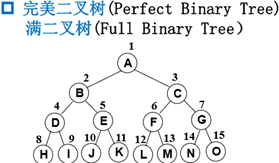

3.3 二叉树几个重要性质

3.4二叉树的存储结构
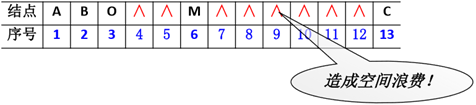
1. 顺序存储结构
✔ 完全二叉树:按从上至下、从左到右顺序存储
n个结点的完全二叉树的结点父子关系:


✔ 一般二叉树也可以采用这种结构,但会造成空间浪费……

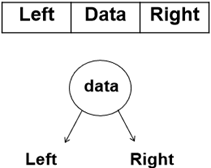
2. 链表存储结构
typedef struct TreeNode *BinTree;
typedef BinTree Position;
struct TreeNode{
ElementType Data;
BinTree Left;
BinTree Right;
}
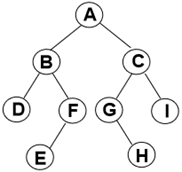
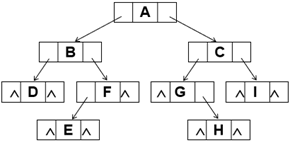
2.5二叉树的遍历
1.二叉树的递归遍历

void PreOrderTraversal ( BinTree BT )
{
if ( BT ) {
printf (“%d”, BT->Data);
PreOrderTraversal ( BT->Left );
PreOrderTraversal ( BT->Right );
}
}
- 中序遍历

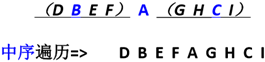
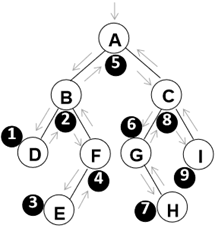
void InOrderTraversal ( BinTree BT )
{
if ( BT ) {
InOrderTraversal( BT->Left );
printf(“%d”, BT->Data);
InOrderTraversal( BT->Right );
}
}
- 后序遍历

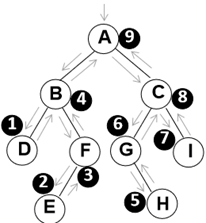
void PostOrderTraversal (BinTree BT)
{
if (BT) {
PostOrderTraversal ( BT->Left );
PostOrderTraversal ( BT->Right);
printf (“%d”, BT->Data);
}
}
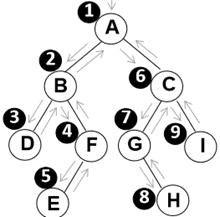
- 先序、中序和后序遍历过程:遍历过程中经过结点的路线一 样,只是访问各结点的时机不同。
- 图中在从入口到出口的曲线上用 ⊕、☆ 和 △三种符号分别标 记出了先序、中序和后序访问各结点的时刻

2.二叉树的非递归遍历
✔ 中序遍历非递归遍历算法
非递归算法实现的基本思路:使用堆栈
- 遇到一个结点,就把它压栈,并去遍历它的左子树;
- 当左子树遍历结束后,从栈顶弹出这个结点并访问它;
- 然后按其右指针再去中序遍历该结点的右子树。
void InOrderTraversal ( BinTree BT )
{ BinTree T=BT;
Stack S = CreatStack ( MaxSize ); /*创建并初始化堆栈S*/
while ( T || ! IsEmpty(S) ) {
while (T) { /*一直向左并将沿途结点压入堆栈*/
Push(S,T);
T = T->Left;
}
if (!IsEmpty(S)) {
T = Pop(S); /*结点弹出堆栈*/
printf (“%5d”, T->Data); /*(访问)打印结点*/
T = T->Right; /*转向右子树*/
}
}
}
✔ 先序遍历的非递归遍历算法?
将printf调至第二个while后
3.层次遍历
二叉树遍历的核心问题:二维结构的线性化
✔ 从结点访问其左、右儿子结点
✔ 访问左儿子后,右儿子结点怎么办?
需要一个存储结构保存暂时不访问的结点
存储结构:堆栈、队列
☆队列实现
遍历从根结点开始,首先将根结点入队,然后开始执行循环:结点出队、访问该结点、其左右儿子入队
层序基本过程 :先根结点入队,然后:
①从队列中取出一个元素;
②访问该元素所指结点;
③若该元素所指结点的左、右孩子结点非空,则将其左、右孩子的指针顺序入队。
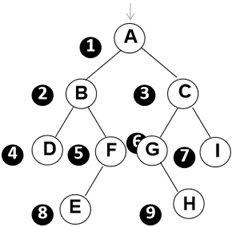
void LevelOrderTraversal ( BinTree BT )
{ Queue Q; BinTree T;
if ( !BT ) return; /* 若是空树则直接返回 */
Q = CreatQueue( MaxSize ); /*创建并初始化队列Q*/
AddQ( Q, BT );
while ( !IsEmptyQ( Q ) ) {
T = DeleteQ( Q );
printf(“%d\n”, T->Data); /*访问取出队列的结点*/
if ( T->Left ) AddQ( Q, T->Left );
if ( T->Right ) AddQ( Q, T->Right );
}
}
- 先序和中序遍历序列来确定一棵二叉树;
类似地,后序和中序遍历序列也可以确定一棵二叉树。
四、二叉搜索树
4.1 定义
二叉搜索树(BST,Binary Search Tree):也称二叉排序树或二叉查找树 ,一棵二叉树,可以为空;如果不为空,满足以下性质:
- 非空左子树的所有键值小于其根结点的键值。
- 非空右子树的所有键值大于其根结点的键值。
- 左、右子树都是二叉搜索树。
4.2 查找
✔ 查找从根结点开始,如果树为空,返回NULL
✔ 若搜索树非空,则根结点关键字和X进行比较,并进行不同处理:
- 若X小于根结点键值,只需在左子树中继续搜索;
- 如果X大于根结点的键值,在右子树中进行继续搜索;
- 若两者比较结果是相等,搜索完成,返回指向此结点的指针。
Position Find( ElementType X, BinTree BST )
{
if( !BST ) return NULL; /*查找失败*/
if( X > BST->Data )
return Find( X, BST->Right ); /*在右子树中继续查找*/
Else if( X < BST->Data )
return Find( X, BST->Left ); /*在左子树中继续查找*/
else /* X == BST->Data */
return BST; /*查找成功,返回结点的找到结点的地址*/
}
由于非递归函数的执行效率高,可将“尾递归”函数改为迭代函数
Position IterFind( ElementType X, BinTree BST )
{
while( BST ) {
if( X > BST->Data )
BST = BST->Right; /*向右子树中移动,继续查找*/
else if( X < BST->Data )
BST = BST->Left; /*向左子树中移动,继续查找*/
else /* X == BST->Data */
return BST; /*查找成功,返回结点的找到结点的地址*/
}
return NULL; /*查找失败*/
}
4.3 查找最大和最小元素
✔ 最大元素一定是在树的最右分枝的端结点上
✔ 最小元素一定是在树的最左分枝的端结点上
- 查找最小元素的递归函数
Position FindMin( BinTree BST )
{
if( !BST ) return NULL; /*空的二叉搜索树,返回NULL*/
else if( !BST->Left )
return BST; /*找到最左叶结点并返回*/
else
return FindMin( BST->Left ); /*沿左分支继续查找*/
}
- 查找最大元素的迭代函数
Position FindMax( BinTree BST )
{
if(BST )
while( BST->Right ) BST = BST->Right; /*沿右分支继续查找,直到最右叶结点*/
return BST;
}
4.4 插入
BinTree Insert( ElementType X, BinTree BST )
{
if( !BST ){
/*若原树为空,生成并返回一个结点的二叉搜索树*/
BST = malloc(sizeof(struct TreeNode));
BST->Data = X;
BST->Left = BST->Right = NULL;
}else /*开始找要插入元素的位置*/
if( X < BST->Data )
BST->Left = Insert( X, BST->Left); /*递归插入左子树*/
else if( X > BST->Data )
BST->Right = Insert( X, BST->Right); /*递归插入右子树*/
/* else X已经存在,什么都不做 */
return BST;
}
4.5 删除
三种情况
- 要删除的是叶结点:直接删除,并再修改其父结点指针—置为NULL
- 要删除的结点只有一个孩子结点:将其父结点的指针指向要删除结点的孩子结点
- 要删除的结点有左、右两棵子树: 用另一结点替代被删除结点:右子树的最小元素 或者 左子树的最大元素
BinTree Delete( ElementType X, BinTree BST )
{ Position Tmp;
if( !BST ) printf("要删除的元素未找到");
else if( X < BST->Data )
BST->Left = Delete( X, BST->Left); /* 左子树递归删除 */
else if( X > BST->Data )
BST->Right = Delete( X, BST->Right); /* 右子树递归删除 */
else /*找到要删除的结点 */
if( BST->Left && BST->Right ) { /*被删除结点有左右两个子结点 */
Tmp = FindMin( BST->Right ); /*在右子树中找最小的元素填充删除结点*/
BST->Data = Tmp->Data;
BST->Right = Delete( BST->Data, BST->Right); /*在删除结点的右子树中删除最小元素*/
} else { /*被删除结点有一个或无子结点*/
Tmp = BST;
if( !BST->Left ) /* 有右孩子或无子结点*/
BST = BST->Right;
else if( !BST->Right ) /*有左孩子或无子结点*/
BST = BST->Left;
free( Tmp );
}
return BST;
}
五、平衡二叉树
5.1定义
- ASL - 平均查找长度
- 平衡因子(BF) - 左右子树高度差,即 BF(T)=hL-hR
- 平衡二叉树 - 空树或者任一结点左、右子树高度差的绝对值不超过1,即 |BF(T)| ≤ 1

- 搜索树结点不同插入次序,将导致不同的 深度 和平均查找长度 ASL

ASL越小,结构越好,与完全二叉树越接近,查找时间复杂度越接近 O(logN)
5.2平衡二叉树的调整
①单旋调整
- RR型不平衡 - 右单旋

因为BF={-1,0,1},AVL树才是平衡的。当Nov插入之后,Mar的平衡因子为-2,标识树的不平衡。此时Nov是不平衡的“ 发现者”,Mar是不平衡的“ troublemaker(麻烦结点)”,其在发现者右子树的右边,因而叫做 RR插入,需要 RR单旋(即右单旋)。

调整策略:逆时针旋转相关结点(以BF为1/-1的结点为轴)
- LL型不平衡 - 左单旋

“发现者”是Mar,“麻烦结点”Apr 在发现者左子树的左边, 因而叫 LL插入,需要 LL旋转(左单旋)

调整策略:顺时针旋转
②双旋调整
- LR型不平衡 - “左-右单旋”

“发现者”是May,“麻烦结点”Jan在左子树的右边, 因而叫 LR插入,需要 LR旋转

之所以称为“左-右双旋”,是因为调整过程中相当于先对以B为根结点的子树做了一次右单旋,再对以A根结点的子树做了一次做单旋,是两次单旋的合成结果。
六、树的应用
6.1 堆heap - 优先队列
1.堆的两个特性
- 结构性:用数组表示的完全二叉树;
- 有序性:任一结点的关键字是其子树所有结点的最大值(或最小值)
“最大堆(MaxHeap)”,也称“大顶堆”:最大值
“最小堆(MinHeap)”,也称“小顶堆” :最小值

2.最大堆的操作
① 最大堆的创建
typedef struct HeapStruct *MaxHeap;
struct HeapStruct {
ElementType *Elements; /* 存储堆元素的数组 */
int Size; /* 堆的当前元素个数 */
int Capacity; /* 堆的最大容量 */
};
MaxHeap Create( int MaxSize ) { /* 创建容量为MaxSize的空的最大堆 */
MaxHeap H = malloc( sizeof( struct HeapStruct ) );
H->Elements = malloc( (MaxSize+1) * sizeof(ElementType));
H->Size = 0;
H->Capacity = MaxSize;
H->Elements[0] = MaxData; /*定义“哨兵”为大于堆中所有可能元素的值,便于以后更快操作 */
return H;
}
② 最大堆的插入
算法:将新增结点插入从其父结点到子结点的有序序列中

void Insert( MaxHeap H, ElementType item )
{ /* 将元素item 插入最大堆H,其中H->Elements[0]已经定义为哨兵 */
int i;
if ( IsFull(H) ) {
printf("最大堆已满");
return;
}
i = ++H->Size; /* i指向插入后堆中的最后一个元素的位置 */
for ( ; H->Elements[i/2] < item; i/=2 )
H->Elements[i] = H->Elements[i/2]; /* 向下过滤结点 */
H->Elements[i] = item; /* 将item 插入 */
}
③ 最大堆的删除
- 取出很结点(最大值)元素,同时删除堆的一个结点
- 为了使删除操作后,最大堆仍然要是完全二叉树:删除的结点应该是数组的最后一个单元,将删除结点(数组中最后一个元素单元)的元素作为假设的根结点,依次与其下层的子结点进行比较。

ElementType DeleteMax( MaxHeap H )
{ /* 从最大堆H中取出键值为最大的元素,并删除一个结点 */
int Parent, Child;
ElementType MaxItem, temp;
if ( IsEmpty(H) ) {
printf("最大堆已为空");
return;
}
MaxItem = H->Elements[1]; /* 取出根结点最大值 */
/* 用最大堆中最后一个元素从根结点开始向上过滤下层结点 */
temp = H->Elements[H->Size--];
for( Parent=1; Parent*2<=H->Size; Parent=Child ) {
Child = Parent * 2;
if( (Child!= H->Size) &&
(H->Elements[Child] < H->Elements[Child+1]) )
Child++; /* Child指向左右子结点的较大者 */
if( temp >= H->Elements[Child] ) break;
else /* 移动temp元素到下一层 */
H->Elements[Parent] = H->Elements[Child];
}
H->Elements[Parent] = temp;
return MaxItem;
}
④ 最大堆的建立
建立最大堆:将已经存在的N个元素按最大堆的要求存放在一个一维数组中
- 方法1:通过插入操作,将N个元素一个个相继插入到一个初 始为空的堆中去,其时间代价最大为O(N·logN)。
- 方法2:在线性时间复杂度下建立最大堆。
- 将N个元素按输入顺序存入,先满足完全二叉树的结构特性,
- 调整各结点位置,以满足最大堆的有序特性。
void PercDown( MaxHeap H, int p )
{ /* 下滤:将H中以H->Data[p]为根的子堆调整为最大堆 */
int Parent, Child;
ElementType X;
X = H->Data[p]; /* 取出根结点存放的值 */
for( Parent=p; Parent*2<=H->Size; Parent=Child ) {
Child = Parent * 2;
if( (Child!=H->Size) && (H->Data[Child]<H->Data[Child+1]) )
Child++; /* Child指向左右子结点的较大者 */
if( X >= H->Data[Child] ) break; /* 找到了合适位置 */
else /* 下滤X */
H->Data[Parent] = H->Data[Child];
}
H->Data[Parent] = X;
}
void BuildHeap( MaxHeap H )
{ /* 调整H->Data[]中的元素,使满足最大堆的有序性 */
/* 这里假设所有H->Size个元素已经存在H->Data[]中 */
int i;
/* 从最后一个结点的父节点开始,到根结点1 */
for( i = H->Size/2; i>0; i-- )
PercDown( H, i );
}


6.2 哈夫曼树 - 最优二叉树
1.定义
带权路径长度(WPL):设二叉树有n个叶子结点,每个叶子结点带有权值 Wi,从根结点到每个叶子结点的长度为 Li,则每个叶子结 点的带权路径长度之和就是: W = ∑ Wi·Li
最优二叉树或哈夫曼树: WPL最小的二叉树
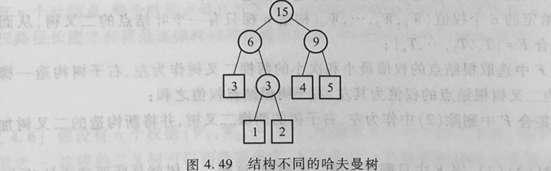
〖例〗有五个叶子结点,它们的权值为{1,2,3,4,5},用此权值序列 可以构造出形状不同的多个二叉树。

2.哈夫曼树的构造
每次把权值最小的两棵二叉树合并

typedef struct TreeNode *HuffmanTree;
struct TreeNode{
int Weight;
HuffmanTree Left, Right;
}
HuffmanTree Huffman( MinHeap H )
{ /* 假设H->Size个权值已经存在H->Elements[]->Weight里 */
int i; HuffmanTree T;
BuildMinHeap(H); /*将H->Elements[]按权值调整为最小堆*/
for (i = 1; i < H->Size; i++) { /*做H->Size-1次合并*/
T = malloc( sizeof( struct TreeNode) ); /*建立新结点*/
T->Left = DeleteMin(H); /*从最小堆中删除一个结点,作为新T的左子结点*/
T->Right = DeleteMin(H); /*从最小堆中删除一个结点,作为新T的右子结点*/
T->Weight = T->Left->Weight+T->Right->Weight; /*计算新权值*/
Insert( H, T ); /*将新T插入最小堆*/
}
T = DeleteMin(H);
return T;
}
需要指出的是,对于同一组给定权值叶结点所构造的哈夫曼树,树的形状可能不同,但是带权路径的长度一定相同。
3.哈夫曼树的特点
- 没有度为1的结点;
- 哈夫曼树的任意非叶节点的左右子树交换后仍是哈夫曼树;
- n个叶子结点的哈夫曼树共有2n-1个结点;
- 对同一组权值{w1 ,w2 , …… , wn},存在不同构的两棵哈夫曼树
4.哈夫曼编码
-
设计编码时需要遵守两个原则:
① 无二义性,即唯一性;
② 编码尽可能地短。 -
两种编码方式
① 等长编码
简单且具有唯一性,但编码长度并不是最短的。
② 不等长编码
能节约一些空间,但译码不唯一因此,为了设计长短不等的编码,以便减少电文的总长,还必须考虑编码的唯一性,即在建立不等长编码时必须使任何一个字符的编码都不是另一个字符的前缀,这种编码称为前缀编码(prefix code)。
-
哈夫曼树的前缀编码
① 利用字符集中每个字符的使用频率作为权值构造一个哈夫曼树;
② 从根结点开始,为到每个叶子结点路径上的左分支赋予0,右分支赋予1,并从根到叶子方向形成该叶子结点的编码
一篇关于哈夫曼树的csdn文章:https://blog.csdn.net/upHailin/article/details/77829803















 3800
3800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









