







多线程和多进程的格式
多线程
#target=func 不加括号是对函数的调用;target=func()加括号是对结果的调用
t = Thread(target=func) # 创建一个多线程对象
t.start() #多线程为可以开始工作状态
方式二:
t = MyThread() #定义一个对象
t.start() #开启线程
class MyThread(Thread): #子类继承了Thread
def run(self): #这里的方法必须是run()
多进程
#target=func 表示是对函数的调用;target=func()表示是对结果的调用
p = Process(target=func)
p.start() # 开启多进程
传参格式
p1 = Process(target=func, args=("周杰伦",)) #传递参数必须是元组
p1.start() # 开启多进程
一、多线程
1、demo1
#多线程
from threading import Thread
def func():
for i in range(100):
print("func", i)
if __name__ == '__main__':
#target=func 不加括号是对函数的调用;target=func()加括号是对结果的调用
t = Thread(target=func) # 创建一个多线程对象
t.start() #多线程为可以开始工作状态
for i in range(100):
print("main", i)
2、demo2
from threading import Thread
class MyThread(Thread): #子类继承了Thread
def run(self): #这里的方法必须是run()
for i in range(1000):
print("子线程", i)
if __name__ == '__main__':
t = MyThread() #定义一个对象
t.start() #开启线程
for i in range(1000):
print("主线程", i)
二、多进程
1、demo1
from multiprocessing import Process
def func():
for i in range(10000):
print("子进程", i)
if __name__ == '__main__':
#target=func 表示是对函数的调用;target=func()表示是对结果的调用
p = Process(target=func)
p.start() # 开启多进程
for i in range(10000):
print("主进程", i)
2、demo2
from multiprocessing import Process
def func(name):
for i in range(10000):
print(name, i)
if __name__ == '__main__':
#target=func 表示是对函数的调用;target=func()表示是对结果的调用
p1 = Process(target=func, args=("周杰伦",)) #传递参数必须是元组
p1.start() # 开启多进程
p2 = Process(target=func, args=("王力宏",)) # 传递参数必须是元组
p2.start() # 开启多进程
三、线程池和进程池
1、demo
#导入线程池和进程池
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def fn(name):
for i in range(10):
print(name, i)
if __name__ == '__main__':
#创建线程池
with ThreadPoolExecutor(50) as t:
for i in range(10):
t.submit(fn, name=f"线程{i}") #调度任务
#等待线程池中的任务全部执行完毕,才继续执行(守护)
print("完成")
2、xpath+爬取菜价
数据在页面源代码中
爬取地址 https://www.construdip.com/marketanalysis/0/list/1.shtml
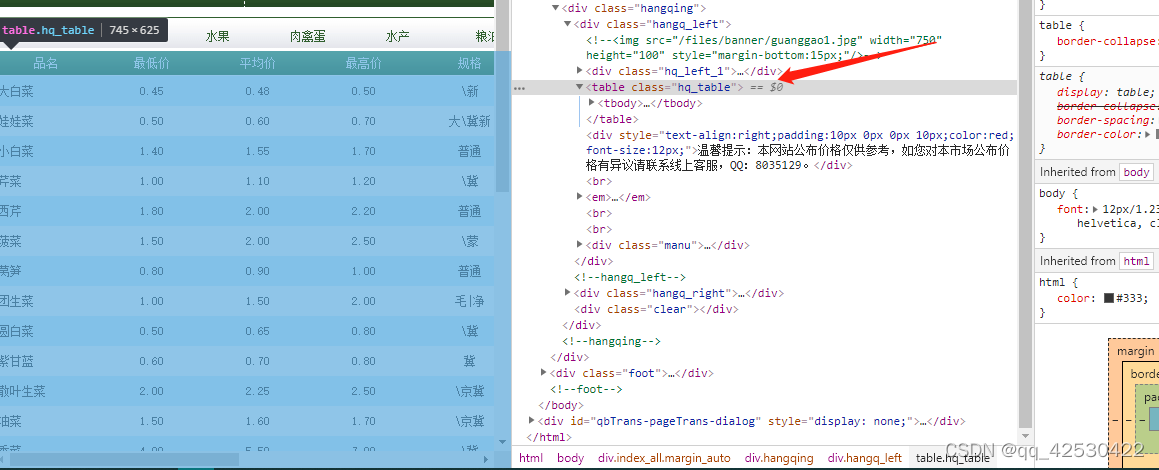
定位到数据的位置
def download_one_page(url):
resp = requests.get(url)
# print(resp.text)
html = etree.HTML(resp.text)
#下面要是不加[0]就是一个列表,且只有一个元素,索引为0
table = html.xpath("/html/body/div[2]/div[4]/div[1]/table")[0]
# print(table)
去除第一行的标签

# [1:]每页获取的菜价还有一个 “菜名” “价格” 之类的东西,[1:]就是用来去除列表第一行元素的
# trs = table.xpath("./tr")[1:]
trs = table.xpath("./tr[position()>1]") #方法二,舍弃第一行的数据
# print(len(trs))

#拿到每个tr
for tr in trs:
txt = tr.xpath("./td/text()")
print(txt)
输出结果为
['大白菜', '0.45', '0.48', '0.50', '\\新', '斤', '2021-07-16']
['娃娃菜', '0.50', '0.60', '0.70', '大\\冀新', '斤', '2021-07-16']
['小白菜', '1.40', '1.55', '1.70', '普通', '斤', '2021-07-16']
['芹菜', '1.00', '1.10', '1.20', '\\冀', '斤', '2021-07-16']
....
#对数据做简单的处理:\\ /去掉
txt = (item.replace("\\","").replace("/", "") for item in txt)
print(list(txt))
输出结果
['大白菜', '0.45', '0.48', '0.50', '新', '斤', '2021-07-16']
['娃娃菜', '0.50', '0.60', '0.70', '大冀新', '斤', '2021-07-16']
['小白菜', '1.40', '1.55', '1.70', '普通', '斤', '2021-07-16']
。。。。
程序代码
import requests
from lxml import etree
import csv
from concurrent.futures import ThreadPoolExecutor
f = open("线程池_菜价.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
def download_one_page(url):
resp = requests.get(url)
# print(resp.text)
html = etree.HTML(resp.text)
#下面要是不加[0]就是一个列表,且只有一个元素,索引为0
table = html.xpath("/html/body/div[2]/div[4]/div[1]/table")[0]
# print(table)
# [1:]每页获取的菜价还有一个 “菜名” “价格” 之类的东西,[1:]就是用来去除列表第一行元素的
# trs = table.xpath("./tr")[1:]
trs = table.xpath("./tr[position()>1]") #方法二,舍弃第一行的数据
# print(len(trs))
#拿到每个tr
for tr in trs:
txt = tr.xpath("./td/text()")
# print(txt)
#对数据做简单的处理:\\ /去掉
txt = (item.replace("\\","").replace("/", "") for item in txt)
# print(list(txt))
csvwriter.writerow(txt)
print(url, "提取完毕")
if __name__ == '__main__':
# download_one_page("https://www.construdip.com/marketanalysis/0/list/1.shtml")
#单线程的下载方式
# for i in range(1, 100):
# download_one_page(f"https://www.construdip.com/marketanalysis/0/list/{i}.shtml")
with ThreadPoolExecutor(50) as t:
for i in range(1, 200):
#把下载任务提交给线程池
t.submit(download_one_page, f"https://www.construdip.com/marketanalysis/0/list/{i}.shtml")
四、协程
方法一:
async def func1():
print("程序1")
# time.sleep(3) #当程序出现了同步操作的时候,异步就中断了
await asyncio.sleep(3) #异步操作的代码;await表示挂起,cpu执行下一个程序
print("程序1")
f1 = func1()
f2 = func2()
f3 = func3()
#把任务放到列表里面去
tasks = [f1, f2, f3]
#一次性启动多个任务(协程)
asyncio.run(asyncio.wait(tasks))
方法二:
async def main():
#第一种写法
# f1 = func1()
# await f1 #一般await挂起操作放在协程对象前面
#第二种写法
tasks = [asyncio.create_task(func1()), asyncio.create_task(func2()), asyncio.create_task(func3())]
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
1、aiohttp模块应用下载图片
import asyncio
import aiohttp
urls = [
"http://kr.shanghai-jiuxin.com/file/2020/1031/small774218be86d832f359637ab120eba52d.jpg",
"http://kr.shanghai-jiuxin.com/file/2020/1031/small563337d07af599a9ea64e620729f367e.jpg",
"http://kr.shanghai-jiuxin.com/file/2020/1031/small26b7e178e987be6d914bf8d1af120890.jpg"
]
async def aiodownload(url):
name = url.rsplit("/", 1)[1] #创建文件名为最后一个
#这里加了with就相当于开文件时的一样,执行完这里之后就不用手动进行释放了
#aiohttp.ClientSession() <==> 相当于 requests模块
async with aiohttp.ClientSession() as session: #async表示异步
async with session.get(url) as resp:
# resp.content.read() #<==>等价于requests模块中的 resp.content
#请求回来了,写入文件
with open(name, mode="wb") as f:
f.write(await resp.content.read()) #读取内容是异步的,需要await挂起
print(name, "搞定")
async def main():
tasks = []
for url in urls:
tasks.append(asyncio.create_task(aiodownload(url)))
# tasks.append(aiodownload(url))
await asyncio.wait(tasks)
if __name__ == '__main__':
# asyncio.run(main()) #这里的会报错
asyncio.get_event_loop().run_until_complete(main())
2、用协程爬取一部小说
爬取网站: http://dushu.baidu.com/pc/detail?gid=4306063500

点击页面的查看更多后出现

此时,http://dushu.baidu.com/api/pc/getCatalog?data={“book_id”:“4306063500”}
第一章的小说在这里


http://dushu.baidu.com/api/pc/getChapterContent?data={%22book_id%22:%224306063500%22,%22cid%22:%224306063500|1569782244%22,%22need_bookinfo%22:1}
其中的%22为符号""号,所以,修改后的地址为
http://dushu.baidu.com/api/pc/getChapterContent?data={“book_id”:“4306063500”,“cid”:“4306063500|1569782244”,“need_bookinfo”:1}

# url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":f"{b_id}"}' 这样写就会报错,只能用下面的
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}'

代码:
import requests
import asyncio
import aiohttp
import json
import aiofiles
#1、同步操作:访问getCatalog ,拿到所有章节的cid和名称
#2、异步操作:访问 getChapterContent,下载所有的文章内容
#
# "http://dushu.baidu.com/pc/detail?gid=4306063500"
#
# 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}'
async def aiodownload(cid, b_id, title):
data = {
"book_id": f"{b_id}",
"cid": f"{b_id}|{cid}",
"need_bookinfo": 1
}
data = json.dumps(data) #将data转换为字符串
url = f"http://dushu.baidu.com/api/pc/getChapterContent?data={data}"
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
dic = await resp.json()
async with aiofiles.open("西游记小说/"+title, mode="w", encoding="utf-8") as f:
await f.write(dic['data']['novel']['content'])
async def getCatalog(url):
resp = requests.get(url)
# print(resp.text)
# print(resp.json())
dic = resp.json()
tasks = []
# 在data里面找到novel,再在novel中找到items;
for item in dic['data']['novel']['items']:
title = item['title'] #在items中找到title
cid = item['cid']
#准备异步任务
tasks.append(asyncio.create_task(aiodownload(cid, b_id, title)))
# print(title, cid)
await asyncio.wait(tasks)
if __name__ == '__main__':
b_id = "4306063500"
# url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":f"{b_id}"}' 这样写就会报错,只能用下面的
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}'
asyncio.run(getCatalog(url))















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









