






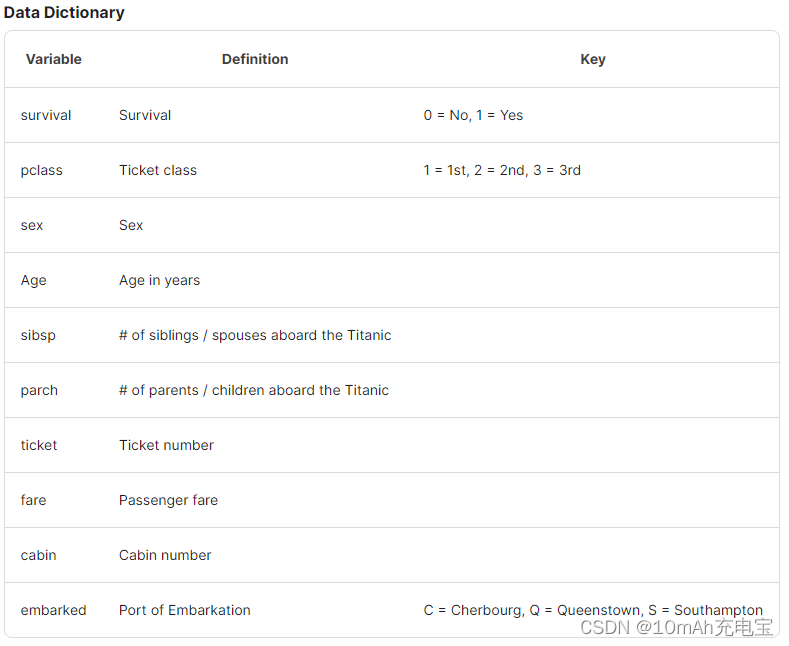
最近在学习pytorch深度学习实践,记录一下处理这个数据集以及利用其训练网络的过程。
数据集位置:泰坦尼克号数据集
1. 数据集处理
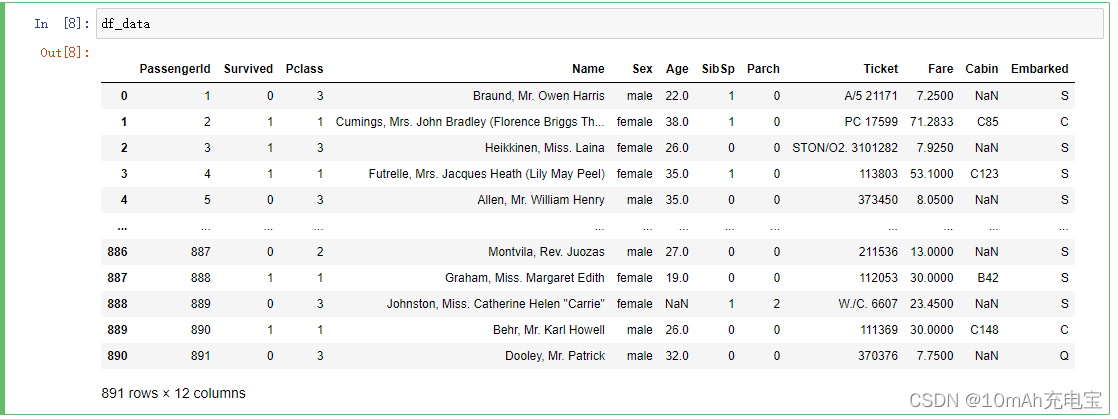
可以在jupyter notebook上先跑一跑,看看数据集的样子
import numpy
import pandas as pd
from sklearn import preprocessing
data_path = "D:\WorkSpace\python_work\Deep_Learn\le-pytorch\dataset\\titanic\\train.csv"
df_data = pd.read_csv(data_path)
对数据集的处理,借鉴了博客:泰坦尼克号数据集处理 的方法
筛选字段:
很明显,在数据中,有些字段我们并不需要,我们要筛选出可以作为特征值的字段。
train_selected_cols = ['Survived', 'Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
train_data = train_data[train_selected_cols]
填补有NaN值(空值)的字段
在数据中若存在空值,网络无法正确完成处理,需要我们在数据预处理的过程中将空值填补。
Pandas判断缺失值采用 isnull(),会生成所有数据的True/False矩阵,这是元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True, 否则就是False。
在数据量大的情况下,采用列级别的处理会更一目了然,可以马上看出需要填补的字段。
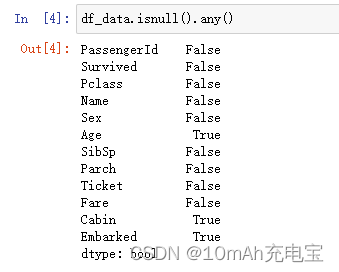
可以看到,在我们需要的数据列中,‘Age’ 列和 ‘Embarked’ 列有空值,需要我们去填补。这里我们采用平均值去填补
age_mean = select_data['Age'].mean()
select_data['Age'] = select_data['Age'].fillna(age_mean)
编码转换
我们需要将Sex列的 ‘male’ 和 ‘female’ 和embarked列的C、Q、S转换为数值
select_data['Sex'] = select_data['Sex'].map({'male': 0, 'female': '1'}).astype(int)
select_data['Embarked'] = select_data['Embarked'].map({'C': 0, 'S': 1, 'Q': 2}).astype(int)
取特征值和标签值
features = select_data.values[:, 1:]
label = select_data.values[:, 0]
数据归一化
因为每列数据取值范围不一样,所以我们要将数据归一化,避免数值大的列对整体损失影响过大
norm_features = preprocessing.minmax_scale(features, feature_range=(0, 1))
norm_features = norm_features.astype(numpy.float32)
label = label.astype(numpy.float32)
这里采用了preprocessing的minmax_scale函数。另外要注意,归一化之后,特征的数据类型是float64类型(也就是double),我本人做的时候在网络输入端需要的是float32类型,因此进行了类型的转换。
数据预处理函数
def prepare_train_data(df_data):
select_data = df_data.drop(['Name'], axis=1)
age_mean = select_data['Age'].mean()
select_data['Age'] = select_data['Age'].fillna(age_mean)
select_data['Embarked'] = select_data['Embarked'].fillna('S')
select_data['Sex'] = select_data['Sex'].map({'male': 0, 'female': '1'}).astype(int)
select_data['Embarked'] = select_data['Embarked'].map({'C': 0, 'S': 1, 'Q': 2}).astype(int)
features = select_data.values[:, 1:]
label = select_data.values[:, 0]
norm_features = preprocessing.minmax_scale(features, feature_range=(0, 1))
norm_features = norm_features.astype(numpy.float32)
label = label.astype(numpy.float32)
return norm_features, label
2. 数据集定义
class TitanicDataset(Dataset):
def __init__(self, data_path):
train_selected_cols = ['Survived', 'Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
train_data = pd.read_csv(data_path)
self.len = train_data.shape[0]
self.train_data_x, self.train_data_y = prepare_train_data(train_data[train_selected_cols])
def __getitem__(self, index):
return self.train_data_x[index], self.train_data_y[index]
def __len__(self):
return self.len
dataset = TitanicDataset("D:\WorkSpace\python_work\Deep_Learn\le-pytorch\dataset\\titanic\\train.csv")
train_loader = DataLoader(
dataset=dataset,
batch_size=8,
shuffle=True,
num_workers=4
)
3. 网络结构、损失函数、优化器定义
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(7,4)
self.linear2 = torch.nn.Linear(4,2)
self.linear3 = torch.nn.Linear(2,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
4. 训练
if __name__ == '__main__':
# 训练
for epoch in range(100):
print("epoch:", epoch)
for i, (inputs, labels) in enumerate(train_loader, 0):
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print("batch:",i,"loss:",loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
5. 完整代码
import numpy
import pandas as pd
import torch
from sklearn import preprocessing
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
#数据预处理
def prepare_train_data(df_data):
select_data = df_data.drop(['Name'], axis=1)
age_mean = select_data['Age'].mean()
select_data['Age'] = select_data['Age'].fillna(age_mean)
select_data['Embarked'] = select_data['Embarked'].fillna('S')
select_data['Sex'] = select_data['Sex'].map({'male': 0, 'female': '1'}).astype(int)
select_data['Embarked'] = select_data['Embarked'].map({'C': 0, 'S': 1, 'Q': 2}).astype(int)
features = select_data.values[:, 1:]
label = select_data.values[:, 0]
norm_features = preprocessing.minmax_scale(features, feature_range=(0, 1))
norm_features = norm_features.astype(numpy.float32)
label = label.astype(numpy.float32)
return norm_features, label
def prepare_test_data(df_data):
select_data = df_data.drop(['Name'], axis=1)
age_mean = select_data['Age'].mean()
select_data['Age'] = select_data['Age'].fillna(age_mean)
select_data['Embarked'] = select_data['Embarked'].fillna('S')
select_data['Sex'] = select_data['Sex'].map({'male': 0, 'female': '1'}).astype(int)
select_data['Embarked'] = select_data['Embarked'].map({'C': 0, 'S': 1, 'Q': 2}).astype(int)
features = select_data.values[:, :]
norm_features = preprocessing.minmax_scale(features, feature_range=(0, 1))
norm_features = norm_features.astype(numpy.float32)
return norm_features
class TitanicDataset(Dataset):
def __init__(self, data_path):
train_selected_cols = ['Survived', 'Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
train_data = pd.read_csv(data_path)
self.len = train_data.shape[0]
self.train_data_x, self.train_data_y = prepare_train_data(train_data[train_selected_cols])
def __getitem__(self, index):
return self.train_data_x[index], self.train_data_y[index]
def __len__(self):
return self.len
dataset = TitanicDataset("D:\WorkSpace\python_work\Deep_Learn\le-pytorch\dataset\\titanic\\train.csv")
train_loader = DataLoader(
dataset=dataset,
batch_size=8,
shuffle=True,
num_workers=4
)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(7,4)
self.linear2 = torch.nn.Linear(4,2)
self.linear3 = torch.nn.Linear(2,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
if __name__ == '__main__':
# 训练
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader, 0):
y_pred = model(inputs)
loss = criterion(y_pred.squeeze(), labels.squeeze())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%10 == 0:
mask = y_pred.ge(0.5).float().squeeze()
correct = (mask == labels).sum()
acc = correct.item()/labels.shape[0]
print("epoch: ", epoch, "loss: ",loss.item(),"accurate: ",acc)
# 加载测试数据
test_data_path = "D:\WorkSpace\python_work\Deep_Learn\le-pytorch\dataset\\titanic\\test.csv"
test_selected_cols = ['Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
test_data = pd.read_csv(test_data_path)
test_data_x = prepare_test_data(test_data[test_selected_cols])
test_data_x = torch.from_numpy(test_data_x)
test_data_y = model(test_data_x)
test_data_y = test_data_y.ge(0.5).int().squeeze()
test_data_y = test_data_y.detach().numpy()
test_data_Id = test_data['PassengerId']
test_df = pd.DataFrame({'PassengerId': test_data_Id, 'Survived': test_data_y})
test_df.to_csv('D:\WorkSpace\python_work\Deep_Learn\le-pytorch\dataset\\titanic\submission.csv',index=False)
这个网络表现一般,最后提交准确率只有77%
















 1114
1114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











