





1. 导言
在机器学习领域,有许多技术术语包含“学习”一词。其中一些是深度学习、强化学习、有监督或无监督学习、主动学习、元学习和迁移学习。尽管“学习”这个词很常见,但这些术语却截然不同。它们之间唯一的共同点都出现在机器学习中。
对于那些没有了解过机器学习的人或刚开始研究这一领域的人来说,所有这些术语听起来可能非常相似,并会造成混乱。为了稍微区分一下,我们将用一些例子解释元学习和迁移学习这两个术语。
2. Transfer learning 迁移学习
迁移学习是深度学习中一种非常流行的技术,现有的预训练模型被用于新任务。基本上,我们的想法是将我们为一项特定任务训练的一个神经网络作为另一项任务的起点。有时,当我们需要使用现有的神经网络来执行不同的任务时,例如,将三个类别分类,而不是两个类别,可以只更改网络的最后几层,并将其余保持原样。
如今,在计算机视觉和自然语言处理领域,研究人员和工程师使用巨大的神经网络,这需要大量的计算和时间资源来学习。得益于迁移学习,我们可以将这些模型作为我们任务的起点,并根据我们的目的对其进行微调,而不是每次都对这些模型进行重新训练。当然,原始训练数据与我们的数据集越相似,我们需要做的微调就越少。
2.1 为什么迁移学习有效
迁移学习是可能的,因为神经网络倾向于学习数据中的不同模式。例如,在计算机视觉中,初始层学习线、点和曲线等低级特征。顶层学习建立在低级功能之上的高级功能。大多数模式,尤其是低级模式,对于许多不同的计算机图像数据集是常见的。我们可以使用网络的现有部分,并通过一些调整来重用它们,而不是每次都从头开始学习。
3. Meta-learning 元学习
“元”一词通常表示更全面或更抽象的东西。例如,元宇宙是一个虚拟世界或我们世界中的世界,元数据是提供有关其他数据的信息的数据,等等。
同样,在这种情况下,元学习指的是关于学习的学习。元学习包括从其他机器学习算法的输出中学习的机器学习算法。
通常,在机器学习中,我们试图找出哪些算法最适合我们的数据。这些算法从历史数据中学习来生成模型,这些模型可以稍后用于预测我们任务的输出。元学习算法不直接使用这种历史数据,而是从机器学习模型的输出中学习。这意味着元学习算法需要存在已经在数据上训练过的其他模型。
例如,如果目标是对图像进行分类,则机器学习模型将图像作为输入并预测类,而元学习模型将这些机器学习模型的预测作为输入并基于此预测图像的类。从这个意义上说,元学习比机器学习高出一个层次。
为了更直观地解释元学习的概念,我们将在下面提到几个例子。
3.1 元学习示例
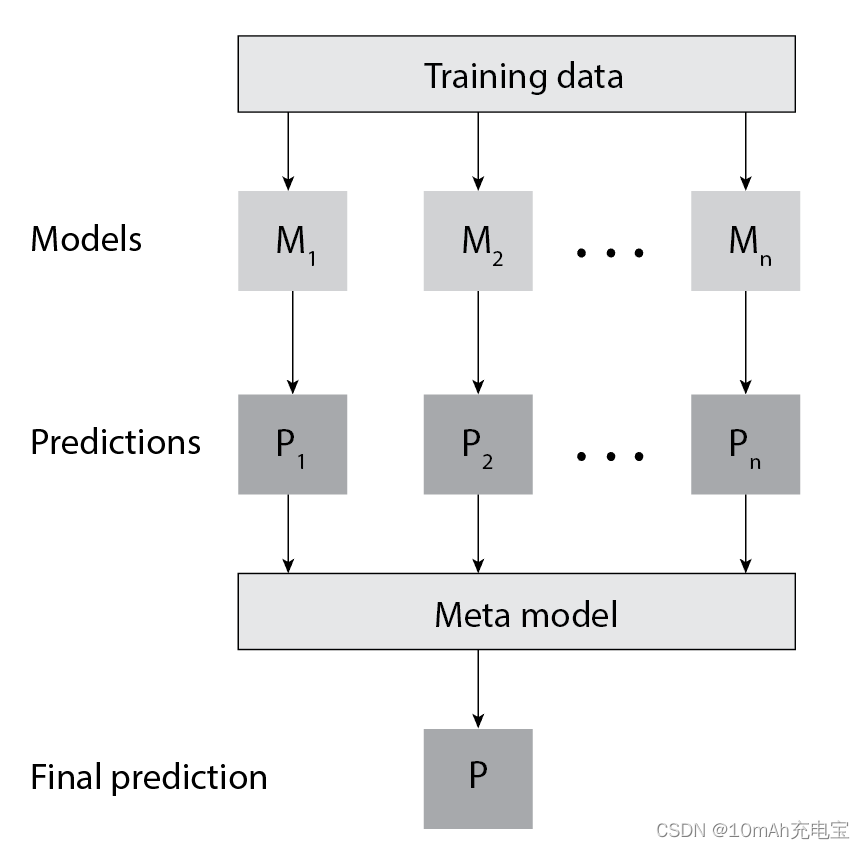
也许,最流行的元学习技术是Stacking(堆叠)。堆叠是一种集成学习算法,它将两个或多个机器学习模型的结果组合在一起。它学习如何最好地将多个预测组合成一个预测。
其想法是使用训练数据来训练作为集成模型一部分的单个模型。然后,这些模型的预测被用作元模型的输入。在这种情况下,这些预测成为元模型的元特征。对于堆叠模型,重要的是使用交叉验证技术(cross-validation)来防止过拟合:
除此之外,还有许多其他类型的元学习算法。其中一些是:
- Meta-learning optimizers:优化现有的神经网络,以便利用新数据更快地学习。
- Metric meta-learning:目的是学习神经网络的嵌入,其中相似输入样本之间的距离变得更近,对于不相似的样本,反之亦然。
4. 总结
在本文中,我们对迁移学习和元学习的概念进行了简要的解释。在一句话中,迁移学习是一种重用现有神经网络的技术,另一方面,元学习是一个关于学习的学习理念。

















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









