







一、实验目的
通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的类型码及单词符号的自身值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示)
二、实验要求
用C或C++或其他程序设计语言写一个简单的词法分析程序,程序可以满足下列要求:
1、能分析如下几种简单的语言词法
(1) 标识符: ID=letter(letter|digit)*
(2) 关键字(全部小写)
main int float double char if then else switch case break continue while do for
(3)整型常量:NUM=digit digit*
(4)运算符
= + - * / < <= == != > >= ; ( )? :
(5)空格由空白、制表符和换行符组成,用以分隔ID、NUM、运算符等,字符分析时被忽略。
2、单词符号和相应的类别码
假定单词符号和相应的类别码如下:
| 单词符号 | 种别码 |
|---------|--------|
| int | 1 |
| = | 17 |
| float | 2 |
| < | 20 |
| if | 3 |
| <= | 21 |
| switch | 4 |
| == | 22 |
| while | 5 |
| != | 23 |
| do | 6 |
| > | 24 |
| 标识符 | 10 |
| >= | 25 |
| 整型常量| 11 |
| ; | 26 |
| + | 13 |
| ( | 27 |
| - | 14 |
| ) | 28 |
| * | 15 |
| ? | 29 |
| / | 16 |
| : | 30 |
3、词法分析程序实现的功能
输入:单词序列(以文件形式提供),输出识别的单词的二元组序列到文件和屏幕
输出:二元组构成: (syn,token或sum)
其中: syn 为单词的种别码
token 为存放的单词自身符号串
sum 为整型常数
例:
源程序: int ab; float ef=20;
ab=10+ef;
输出:
(保留字--1,int)
(标识符--10,ab)
(分号--26,;)
(保留字--2,float)
(标识符--10,ef)
(等号--17,=)
(整数--11,20)
(分号--26,;)
(标识符--10,ab)
(等号--17,=)
(整数--11,10)
(加号--13,+)
(标识符--10,ef)
(分号--26,;)
三、实验过程:
- 算法分析:
- 读取输入文件中的单词序列。
- 根据给定的词法规则,识别并分类单词符号。
- 输出识别的单词的二元组序列到文件和屏幕。
- 程序流程图:

- 程序代码:
#include <iostream>
#include <fstream>
#include <string>
#include <map>
using namespace std;
// Token codes
#define RESERVED 1
#define FLOAT_TYPE 2
#define IF_KEYWORD 3
#define LESS_THAN 20
#define LESS_THAN_OR_EQUAL 21
#define SWITCH_KEYWORD 4
#define EQUAL_EQUAL 22
#define WHILE_KEYWORD 5
#define NOT_EQUAL 23
#define DO_KEYWORD 6
#define GREATER_THAN 24
#define GREATER_THAN_OR_EQUAL 25
#define IDENTIFIER 10
#define INTEGER_CONSTANT 11
#define SEMICOLON 26
#define PLUS 13
#define LEFT_PAREN 27
#define MINUS 14
#define RIGHT_PAREN 28
#define MULTIPLY 15
#define QUESTION_MARK 29
#define DIVIDE 16
#define COLON 30
#define ASSIGNMENT 17
// Token map
map<string, int> tokenMap = {
{"int", RESERVED},
{"float", FLOAT_TYPE},
{"double", RESERVED},
{"char", RESERVED},
{"if", IF_KEYWORD},
{"then", RESERVED},
{"else", RESERVED},
{"switch", SWITCH_KEYWORD},
{"case", RESERVED},
{"break", RESERVED},
{"continue", RESERVED},
{"while", WHILE_KEYWORD},
{"do", DO_KEYWORD},
{"for", RESERVED}
};
bool isLetter(char c) {
return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z');
}
bool isDigit(char c) {
return c >= '0' && c <= '9';
}
void analyzeToken(const string &word, ofstream &outFile) {
if (tokenMap.find(word) != tokenMap.end()) {
outFile << "(保留字--" << tokenMap[word] << "," << word << ")" << endl;
} else if (word == ";") {
outFile << "(分号--26," << word << ")" << endl;
} else if (word == "=") {
outFile << "(等号--17," << word << ")" << endl;
} else if (word == "+") {
outFile << "(加号--13," << word << ")" << endl;
} else if (word == "-") {
outFile << "(减号--14," << word << ")" << endl;
} else if (word == "*") {
outFile << "(乘号--15," << word << ")" << endl;
} else if (word == "/") {
outFile << "(除号--16," << word << ")" << endl;
} else if (word == "<") {
outFile << "(小于--20," << word << ")" << endl;
} else if (word == ">") {
outFile << "(大于--24," << word << ")" << endl;
} else if (word == "==") {
outFile << "(等于--22," << word << ")" << endl;
} else if (word == "!=") {
outFile << "(不等于--23," << word << ")" << endl;
} else if (word == "<=") {
outFile << "(小于等于--21," << word << ")" << endl;
} else if (word == ">=") {
outFile << "(大于等于--25," << word << ")" << endl;
} else if (isdigit(word[0])) {
outFile << "(整数--11," << word << ")" << endl;
} else {
bool isID = true;
for (char c : word.substr(1)) {
if (!isalnum(c)) {
isID = false;
break;
}
}
if (isID && isalpha(word[0])) {
outFile << "(标识符--10," << word << ")" << endl;
}
}
}
int main() {
ifstream inFile("TestData.txt");
ofstream outFile("Result.txt");
if (!inFile.is_open()) {
cout << "Error opening input file!" << endl;
return 1;
}
if (!outFile.is_open()) {
cout << "Error opening output file!" << endl;
return 1;
}
string line, word;
while (inFile >> word) {
size_t pos = word.find_first_of(";=+-*/<>"); // Find operator symbols in the word
if (pos != string::npos) {
if (pos != 0) {
analyzeToken(word.substr(0, pos), outFile);
}
string op = string(1, word[pos]); // Get operator symbol
analyzeToken(op, outFile);
if (pos < word.size() - 1) {
analyzeToken(word.substr(pos + 1), outFile);
}
} else {
analyzeToken(word, outFile);
}
}
inFile.close();
outFile.close();
return 0;
}- 程序运行结果截图:
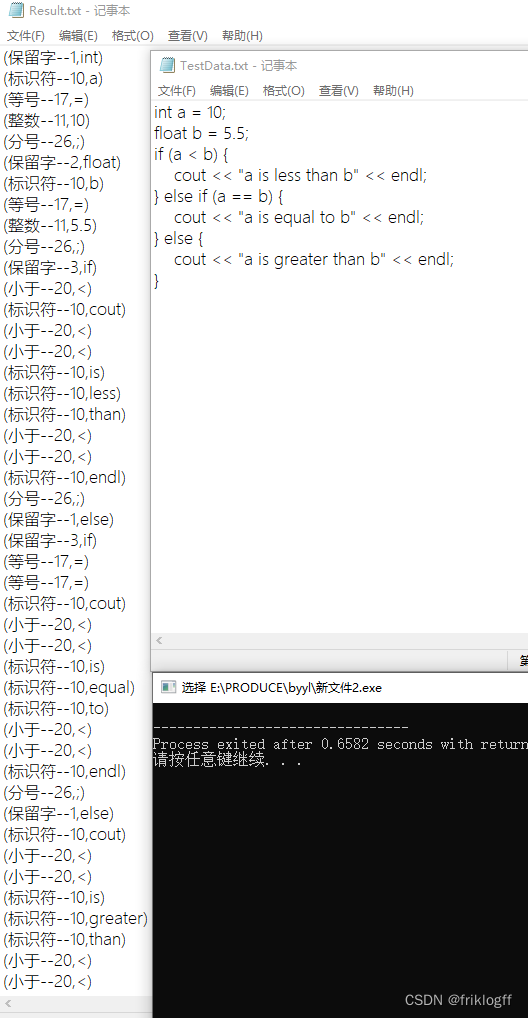
4、自己准备测试数据存放于TestData.txt文件中,测试数据中应覆盖有以上5种数据,测试结果要求以原数据与结果对照的形式输出并保存在Result.txt中,同时要把结果输出到屏幕。
5、提前准备
① 实验前,先编制好程序,上机时输入并调试程序。
- 准备好多组测试数据(存放于文件TestData.txt中)。
四、思考题:
词法分析中如何识别单词?请具体描述识别过程。
在词法分析中,识别单词通常需要遵循以下步骤:
- 读取字符序列: 从输入源(如文件或输入流)中逐个读取字符,构成一个字符序列。
- 判断字符类型: 对于每个读取到的字符,判断其类型,比如是字母、数字、特殊符号等。
- 构建单词: 在字符序列中,如果连续的字符满足某种规则形成的序列能够被认定为一个单词,就将这些字符组合成一个单词。这可能包括关键字、标识符、数字、运算符等。
- 识别单词类型: 将构建好的单词与预先定义的词法规则进行匹配,确定该单词的类型。
- 输出结果: 根据单词的类型,生成相应的输出,通常是一个标识符和其对应的类型。
- 处理下一个单词: 继续以上步骤,直到完成所有字符的扫描。
具体描述识别过程时,识别单词的算法一般会根据编程语言的词法规则进行设计,通过状态机、正则表达式等方式来实现各种单词的识别。例如,针对不同类型的单词可能会有不同的识别逻辑和判断条件。在实现中,需要考虑边界情况、错误处理、特殊字符处理等方面,以确保正确地识别并分类单词。
五、实验小结:
通过本次实验,我学会了设计和实现一个简单的词法分析器。这为我理解编程语言中单词和符号的识别提供了良好的基础。扩展词法分析器的功能可以通过添加更多的词法规则和相应的分类逻辑来实现,从而适应更复杂的编程语言要求。
以上是对本次实验的总结和反思。词法分析是编译原理中的重要内容,通过实践可以更深入地理解编程语言的内部机制。

















 9123
9123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











