






一. Python中的多线程模块
Python中的线程模块是 threading ,创建线程的步骤如下:
1. 导入线程模块
import threading
2. 通过线程类创建线程对象
线程对象 = threading.Thread(target=任务名)
3. 启动线程执行任务
线程对象.start()
二. 多线程的执行顺序
1. 线程间的执行是无序的
线程之间执行是无序的,当前执行哪个线程是由CPU决定的。因为线程是CPU调度资源的基本单位,所以,当前CPU调度哪个线程,哪个线程就执行,未被调度的线程是无法执行的。
下面的代码用于演示线程执行的无序性:
# 1. 导包
import threading, time
# 2. 创建子线程
def print_info():
time.sleep(0.5)
# 获取当前线程
cur_thread = threading.current_thread()
print(cur_thread)
if __name__ == '__main__':
# 循环多次执行子线程
for i in range(10):
t1 = threading.Thread(target=print_info)
t1.start()
if threading.current_thread().name == 'MainThread':
print("主线程开始!")上面的代码涉及到thread模块中一种常用方法:
threading.current_thread()
该方法用于当前的线程对象。即,在哪个线程中调用threading.current_thread方法就返回哪个线程。进一步的,threading.current_thread().name属性可以返回当前线程对象的属性名。
运行结果:
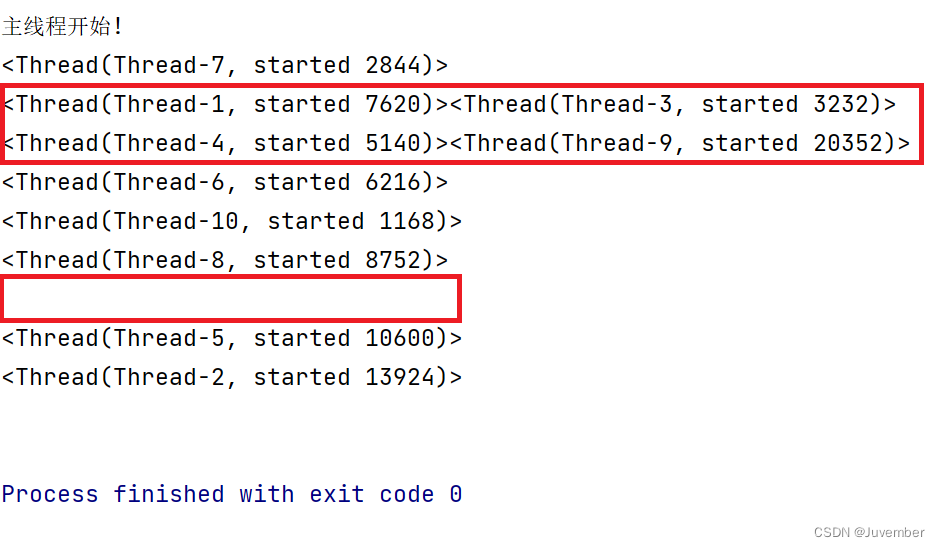
可以看到,在主线程开启子线程后,10个子线程并没有按顺序依次执行,甚至还出现了抢占资源的情况。
三. 主线程会等所有子线程执行结束后再结束
我们都知道,线程是CPU调度的基本单位,每个进程至少都有一个线程,而这个线程就是我们通常说的主线程。那么在多线程的情况下,主线程和子线程的关闭顺序如何呢?
import threading, time
# 定义子线程任务
def thread1():
for i in range(10):
print(f"子线程进行中...{i}")
time.sleep(0.3)
if __name__ == '__main__':
# 创建线程对象
t1 = threading.Thread(target=thread1)
# 开启子线程
t1.start()
time.sleep(1)
print("主线程结束!")在上面的代码中,子线程每执行1次,会休眠0.3s,循环执行10次的时间为3s;我们设定让主线程在开启后休眠1s就结束。然后代码的运行结果如下:
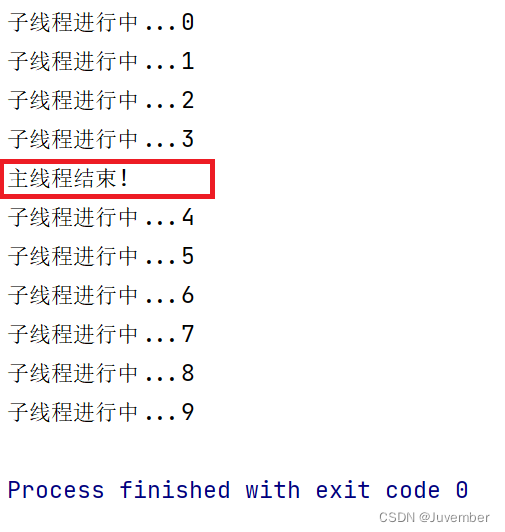
可以看出在主线程结束后,整个程序并没有马上结束,而是在子进程执行10次结束后,整个程序才结束。
四. 守护线程的用法
实际工作中,我们会有这样的需求:当主线程结束后,需要所有的子线程随之立即结束,而不是让主线程等待子线程结束后再结束,这个时候,就可以设置守护线程(daemon)来完成。
Python中设置守护线程的方法有3种:
1. 在创建子线程时设置
线程对象 = threading.Thread(target=任务名,daemon=True)
2. 在创建子线程完成后,开启子线程前 设置
线程对象.setdaemon(True)
3. 同样在创建子线程完成后,开启子线程前 设置
线程对象.daemon = True
import threading, time
# 定义子线程任务
def thread1():
for i in range(10):
print(f"子线程进行中...{i}")
time.sleep(0.3)
if __name__ == '__main__':
# 如果要实现主线程结束时,子线程立即结束,则使用守护线程写法:
# 写法1:在定义线程时就指定daemon属性
t1 = threading.Thread(target=thread1, daemon=True)
# t1 = threading.Thread(target=thread1)
# 写法2:单独设置
# t1.setDaemon(True)
# 写法3:设置线程的属性
# t1.daemon = True
t1.start()
time.sleep(1)
print("主线程结束!")
上述三种方法的效果相同,运行结果如下:

五. 线程同步/子线程插队
如果我们既想实现主线程等待子线程,但又不想让主线程打断子线程的执行顺序,那我们可以用多线程的 join()方法。
1. 使用方法
线程对象.join()
2. 使用场景
join() 方法的主要作用是让一个线程等待另一个线程的结束。当一个线程调用另一个线程的 join() 方法时,它会被阻塞,直到被调用的线程执行完毕才会继续执行。
简单点来说,正常情况下,主线程会等待子线程的结束再结束;而在主线程中中,使用了子线程.join()方法后,实现的效果是,主线程会等待子线程结束后再继续进行。
import threading, time
# 定义子线程任务
def thread1():
for i in range(10):
print(f"子线程进行中...{i}")
time.sleep(0.3)
if __name__ == '__main__':
# 创建线程
t1 = threading.Thread(target=thread1)
t1.start()
# 如果存在join()方法,主线程会等待t1结束后再继续执行
t1.join()
time.sleep(1)
print("主线程结束!")在主线程中加上 t1.join()方法后,结果如下:

3. join()方法与daemon属性的优先级
进行到这里,我们不免有个疑问:守护线程的作用是让主线程结束的时候立即结束子线程,而我们又可以通过 join()方法让主线程等子线程结束后再继续,这两个会不会起冲突呢?
import threading, time
# 定义子线程任务
def thread1():
for i in range(10):
print(f"子线程进行中...{i}")
time.sleep(0.3)
if __name__ == '__main__':
# 如果要实现主线程结束时,子线程立即结束,则使用守护线程写法:
# 在定义线程时设置daemon属性
t1 = threading.Thread(target=thread1, daemon=True)
t1.start()
# 如果存在join()方法,主线程还是会等待t1结束后再进行
t1.join()
time.sleep(1)
print("主线程结束!")
经测试,表现出来的结果仍然是:
个人的理解是:join() 方法优先级高于守护线程的属性,所以让守护线程失效了。当然实际开发中,并不会出现这样“多次一举”的操作。其中深层次的原理,有知道的大佬麻烦在评论里指点一下,非常感谢(抱拳)!














 1670
1670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









