







题目链接:判定链表是否有环
题目
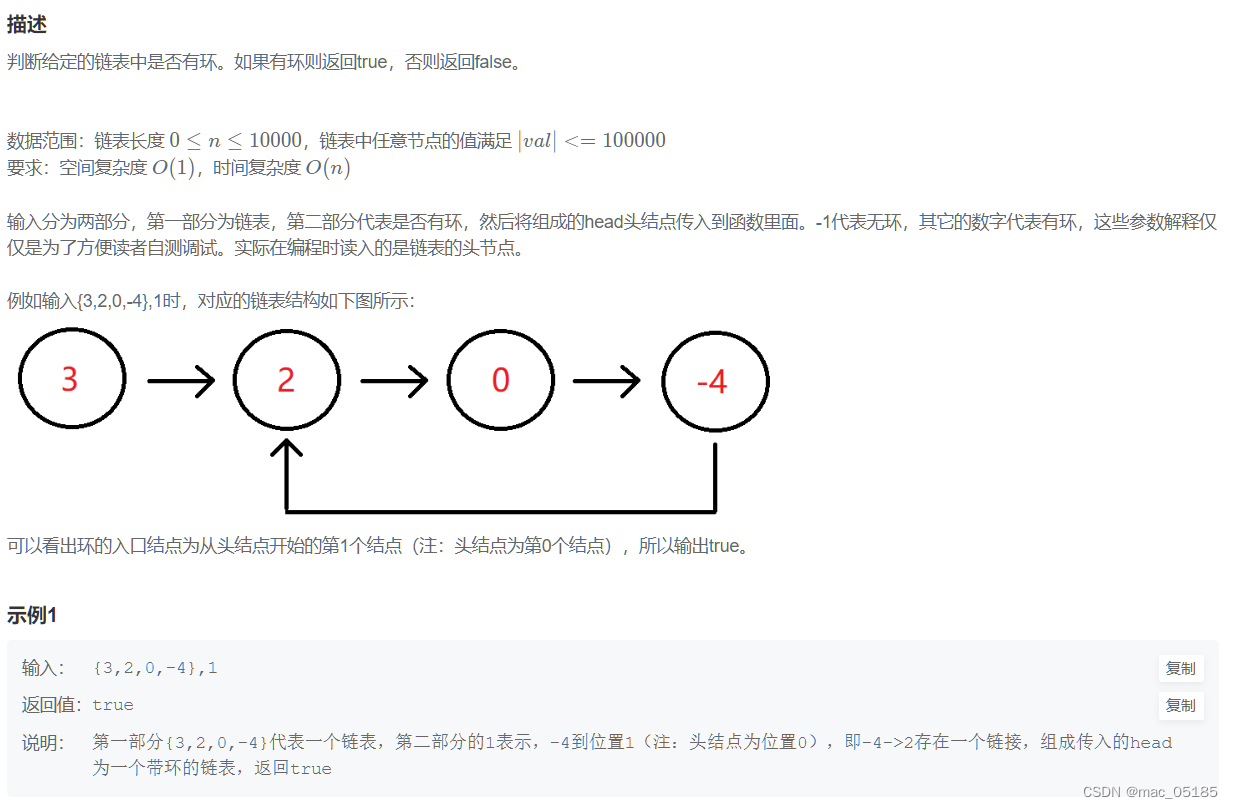
解决思路
遍历链表的每一个节点,记录下来,若再次遇到了遍历过的节点,就可以判定存在环。
- 遍历链表,把访问过的节点存储在哈希表中。
- 判定节点是否存在哈希表中,若存在则返回true。
- 遍历结束,则返回false。
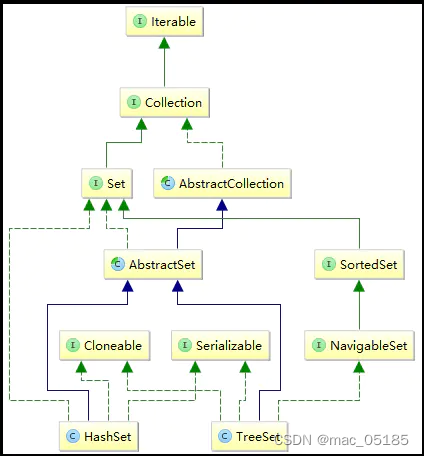
关于Java的Set集合
Set继承于Collection接口,是一个不允许出现重复元素,而且无需的集合,主要有HashSet和TreeSet两大类。
判定重复元素时候,Set集合会调用hashCode和equals方法实现。
HashSet是哈希表结构,主要利用HashMap的key来存储元素,计算插入元素的hashCode来获取元素在集合中的位置。
TreeSet是红黑树结构,每一个元素都是树中的一个节点,插入的元素都会进行排序。
Set常用方法
和List不同,Set提供了equals和hashCode方法,可以让子类重写,实现对集合插入重复元素的处理。
public interface Set<E> extends Collection<E> {
A:添加功能
boolean add(E e);
boolean addAll(Collection<? extends E> c);
B:删除功能
boolean remove(Object o);
boolean removeAll(Collection<?> c);
void clear();
C:长度功能
int size();
D:判断功能
boolean isEmpty();
boolean contains(Object o);
boolean containsAll(Collection<?> c);
boolean retainAll(Collection<?> c);
E:获取Set集合的迭代器:
Iterator<E> iterator();
F:把集合转换成数组
Object[] toArray();
<T> T[] toArray(T[] a);
//判断元素是否重复,为子类提高重写方法
boolean equals(Object o);
int hashCode();
}
HashSet
实现了Set接口,底层是HashMap实现,为哈希表结构,新增元素相当于HashMap的key,value默认是一个固定的Object,HashSet类似一个阉割的HashMap。
当有元素插入的时候,会计算元素的hashCode值,将元素插入到哈希表对应的位置中来。
它继承于AbstractSet,实现了Set, Cloneable, Serializable接口。
-
HashSet继承AbstractSet类,获得了Set接口大部分的实现,减少了实现此接口所需的工作,实际上是又继承了AbstractCollection类;
-
HashSet实现了Set接口,获取Set接口的方法,可以自定义具体实现,也可以继承AbstractSet类中的实现;
-
HashSet实现Cloneable,得到了clone()方法,可以实现克隆功能;
-
HashSet实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
因此具有如下特征:
- 不允许出现重复元素。
- 可以插入null数值。
- 元素无序,添加顺序和遍历顺序不一样。
- 线程不安全,若多个线程同时操作HashSet,则必须利用代码实现同步。
HashSet基本操作
底层是HashMap实现,插入元素当作是key和value。提供hashCode来确定集合中的位置,由于Set集合没有下标的概念,因此没有像List一样提供get方法。若要获取HashSet某个元素,只能够通过遍历形式进行equals方式比较。
public class HashSetTest {
public static void main(String[] agrs){
//创建HashSet集合:
Set<String> hashSet = new HashSet<String>();
System.out.println("HashSet初始容量大小:"+hashSet.size());
//元素添加:
hashSet.add("my");
hashSet.add("name");
hashSet.add("is");
hashSet.add("jiaboyan");
hashSet.add(",");
hashSet.add("hello");
hashSet.add("world");
hashSet.add("!");
System.out.println("HashSet容量大小:"+hashSet.size());
//迭代器遍历:
Iterator<String> iterator = hashSet.iterator();
while (iterator.hasNext()){
String str = iterator.next();
System.out.println(str);
}
//增强for循环
for(String str:hashSet){
if("jiaboyan".equals(str)){
System.out.println("你就是我想要的元素:"+str);
}
System.out.println(str);
}
//元素删除:
hashSet.remove("jiaboyan");
System.out.println("HashSet元素大小:" + hashSet.size());
hashSet.clear();
System.out.println("HashSet元素大小:" + hashSet.size());
//集合判断:
boolean isEmpty = hashSet.isEmpty();
System.out.println("HashSet是否为空:" + isEmpty);
boolean isContains = hashSet.contains("hello");
System.out.println("HashSet是否为空:" + isContains);
}
}
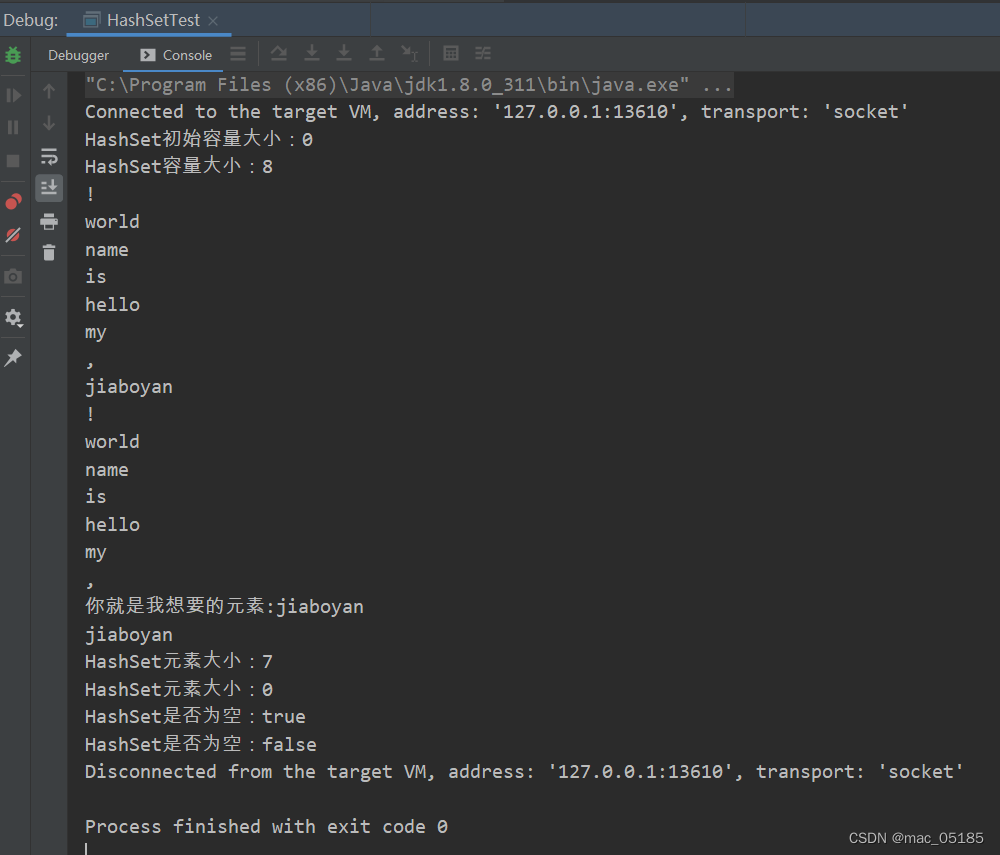
HashSet添加元素
Set集合不允许添加重复元素,请看如下代码:
public class HashSetTest2 {
public static void main(String[] agrs){
//hashCode() 和 equals()测试:
hashCodeAndEquals();
}
public static void hashCodeAndEquals(){
//第一个 Set集合:
Set<String> set1 = new HashSet<String>();
String str1 = new String("jiaboyan");
String str2 = new String("jiaboyan");
set1.add(str1);
set1.add(str2);
System.out.println("长度:"+set1.size()+",内容为:"+set1);
//第二个 Set集合:
Set<App> set2 = new HashSet<App>();
App app1 = new App();
app1.setName("jiaboyan");
App app2 = new App();
app2.setName("jiaboyan");
set2.add(app1);
set2.add(app2);
System.out.println("长度:"+set2.size()+",内容为:"+set2);
//第三个 Set集合:
Set<App> set3 = new HashSet<App>();
App app3 = new App();
app3.setName("jiaboyan");
set3.add(app3);
set3.add(app3);
System.out.println("长度:"+set3.size()+",内容为:"+set3);
}
}
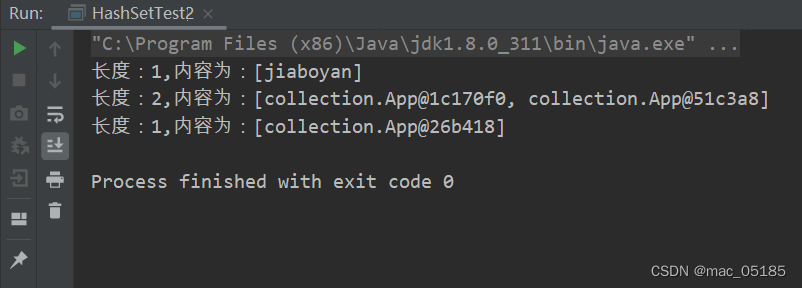
查看HashSet的add方法:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
在底层HashSet调用了HashMap的put(key,value)方法:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
int hash = hash(key)对传入的key计算哈希数值;
int i = indexFor(hash, table.length)对哈希数值转换,转换为数组的索引index,这是因为HashMap底层存储使用了Entry<K ,V>[]数组。
for (Entry<K,V> e = table[i]; e != null; e = e.next) 判断对应index下是否存在元素;
如果存在,则if(e.hash == hash && ((k = e.key) == key || key.equals(k)))判断;
如果不存在,则addEntry(hash, key, value, i)直接添加。
解题代码
import java.util.*;
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode pos = head;
//哈希表记录访问过的结点
Set<ListNode> visited = new HashSet<>();
while (pos != null) {
//判定节点是否被访问过
if (visited.contains(pos)) {
return true;
} else {
//节点记录到哈希表中
visited.add(pos);
}
//遍历哈希表
pos = pos.next;
}
return false;
}
}
运行结果















 1716
1716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









