







如何查找重复行
首先,我们新建一个测试表,然后插入一些重复数据,一些不重复数据
create table test
(
id int not null primary key,
day date not null
);
insert into test(id, day)
value (1, '2006-10-08'),
(2, '2006-10-08'),
(3, '2006-10-09');
insert into test(id, day)
values (4, '2006-10-08');
查询结果:
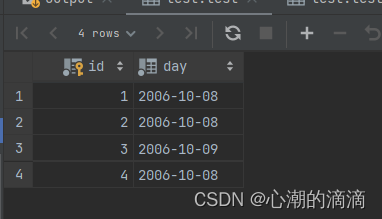
我们发现,id为1,2,4为重复行。现在我们将具有相同day字段值的行归为一组,然后计算组的大小。
select day, count(*)
from test
group by day
having count(*);
运行结果:
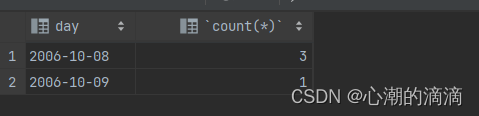
然后,如果我们希望只显示重复行,必须使用having子句
select day, count(*)
from test
group by day
having count(*) > 1;
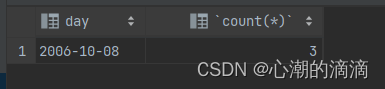
为什么不能使用where子句?
因为where子句过滤的是分组之后的行,having子句过滤的是分组之后的行
如何删除重复行
这里,我们的任务是:删除所有重复行,除了分组id字段具有最小值的行。因此,需要找出大小大于1的分组,以及希望保留的行。你可以使用min()函数,这里的语句是创建临时表,以及查找需要用DELETE删除的行
create temporary table to_delete
(
day date not null,
min_id int not null
);
insert into to_delete(day, min_id)
SELECT day, min(id)
from test
group by day
having count(*) > 1;
select *
from to_delete;

有了这些数据,你可以开始删除“脏数据”行了。
delete
from test
where exists(
select *
from to_delete
where to_delete.day = test.day
and to_delete.min_id <> test.id
);
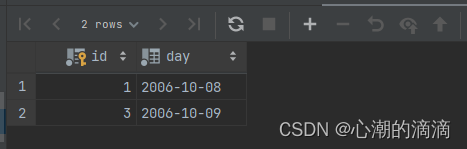
然后再查看具有脏数据的表格,预期结果只剩1和3
select *
from test;
查询结果:















 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









