






Scrapy介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,就是我们熟知的蜘蛛爬虫框架,我们用蜘蛛来获取互联网上的各种信息,然后再对这些信息进行数据分析处理。
Scrapy五大基本构成:
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。下面我们分别介绍各个组件的作用。
(1)、调度器(Scheduler):
调度器,说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
(2)、下载器(Downloader):
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
(3)、 爬虫(Spider):
爬虫,是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
(4)、 实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
(5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
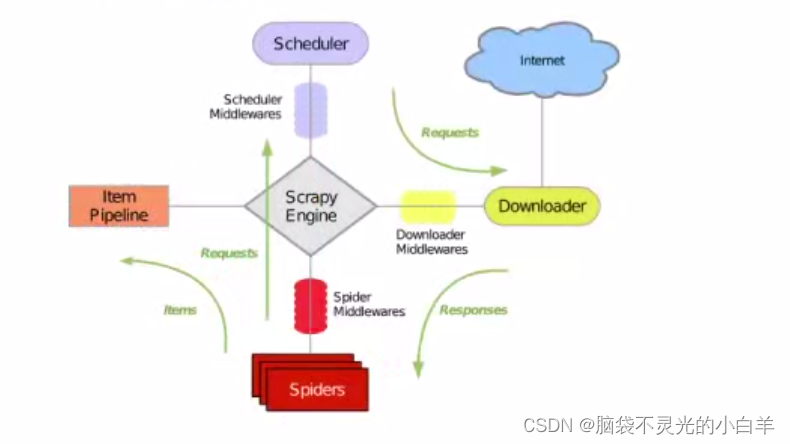
数据流是由执行流程的核心引擎来控制的,流程如下图所示:
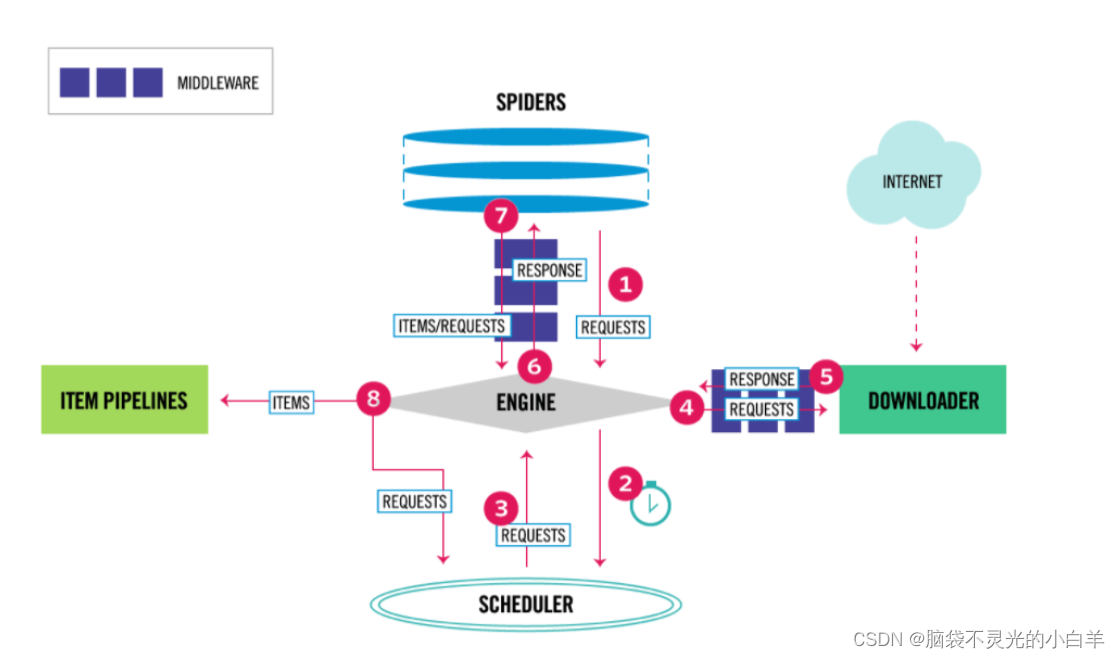
1、引擎打开网站,找到处理该网站的爬虫并向该爬虫请求第一个要爬取的URL。
2、引擎从爬虫中获取到第一个要爬取的URL,并在调度器中以请求调度。
3、引擎向调度器请求下一个要爬取的URL。
4、调度器返回下一个要爬取的URL给引擎,引擎通过下载中间件转给下载器。
5、一旦页面下载完毕,下载器便会生成一个该页面的响应,并通过下载器中间件将其发送给引擎。
6、引擎从下载器中接收到响应并通过爬虫中间件发送给爬虫处理。
7、爬虫处理响应,并返回爬取到的项目及新的请求给引擎。
8、引擎将爬虫爬取到的项目传给项目管道,将爬虫返回的请求传给调度器。
9、从第2步重复直到调度器中没有更多的请求,引擎便会关闭该网站。
Scrapy安装
pip install Scrapy
注:Windows平台需要依赖 pywin32
pip install pypiwin32
Scrapy框架使用
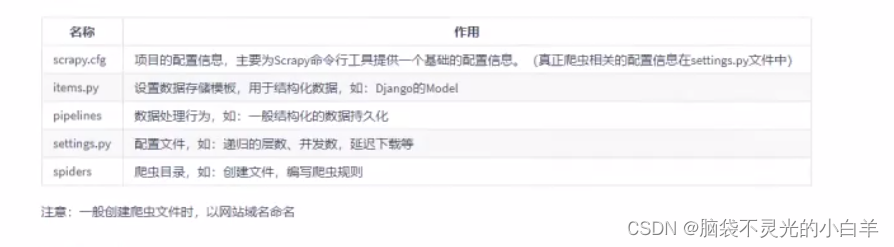
1 创建项目
运行命令:
# myProject(你创建的项目名称)
scrapy startproject myProject
2 切换到创建的scrapy项目文件夹下
cd myProject
3 创建要爬取网站的爬虫文件
scrapy genspider baidu baidu.com
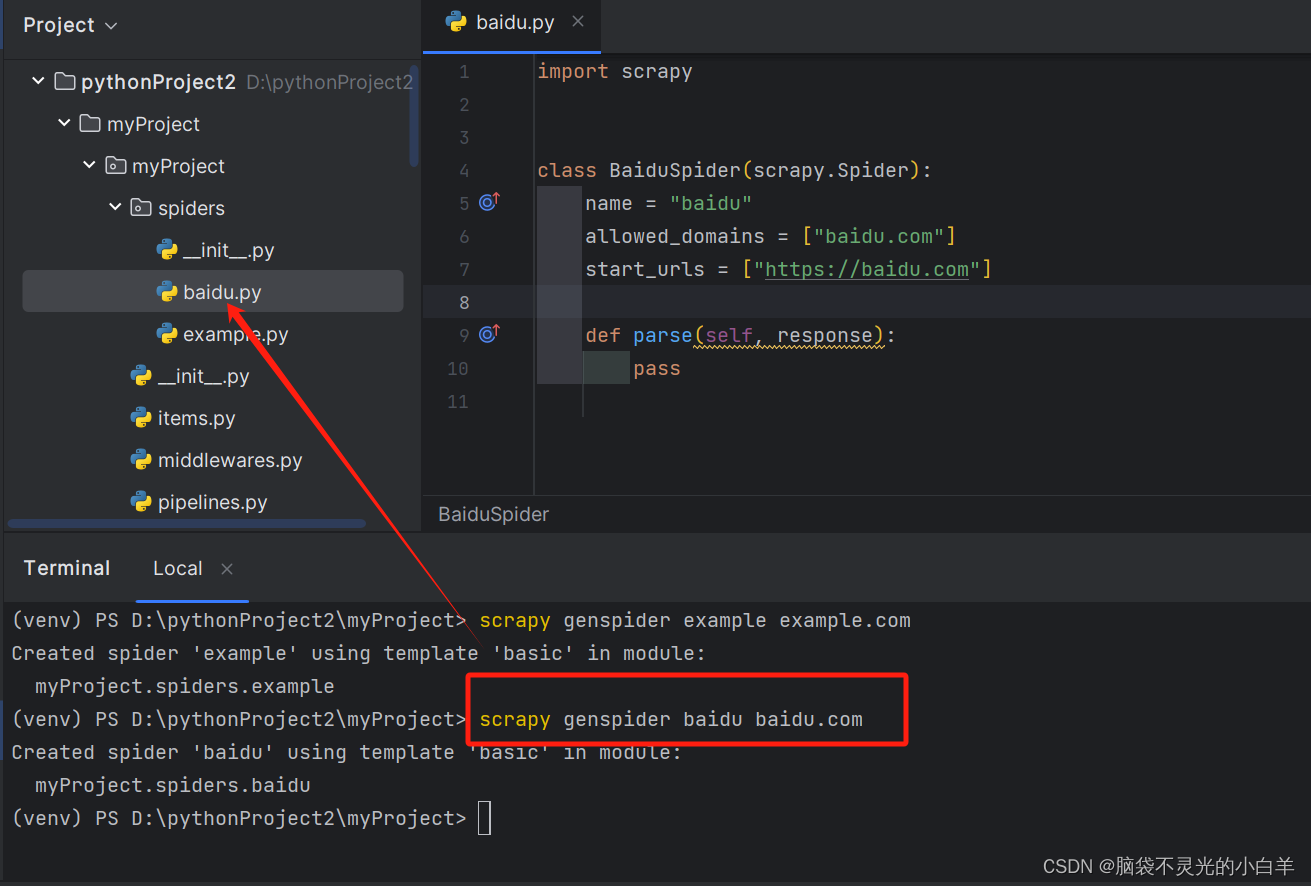
import scrapy
class BaiduSpider(scrapy.Spider):
name = "baidu" # 爬虫的名字,唯一,必须写的
allowed_domains = ["baidu.com"] # 允许爬取的域名,不是必须写的
start_urls = ["https://baidu.com"] # 从哪个URL地址开始获取数据
def parse(self, response): # 当请求访问成功以后,会有一个响应,这个parse就是默认处理响应的函数
print(response.text)
3 运行爬虫文件
scrapy crawl baidu
想要看获取的结果需要将 robots协议 关闭
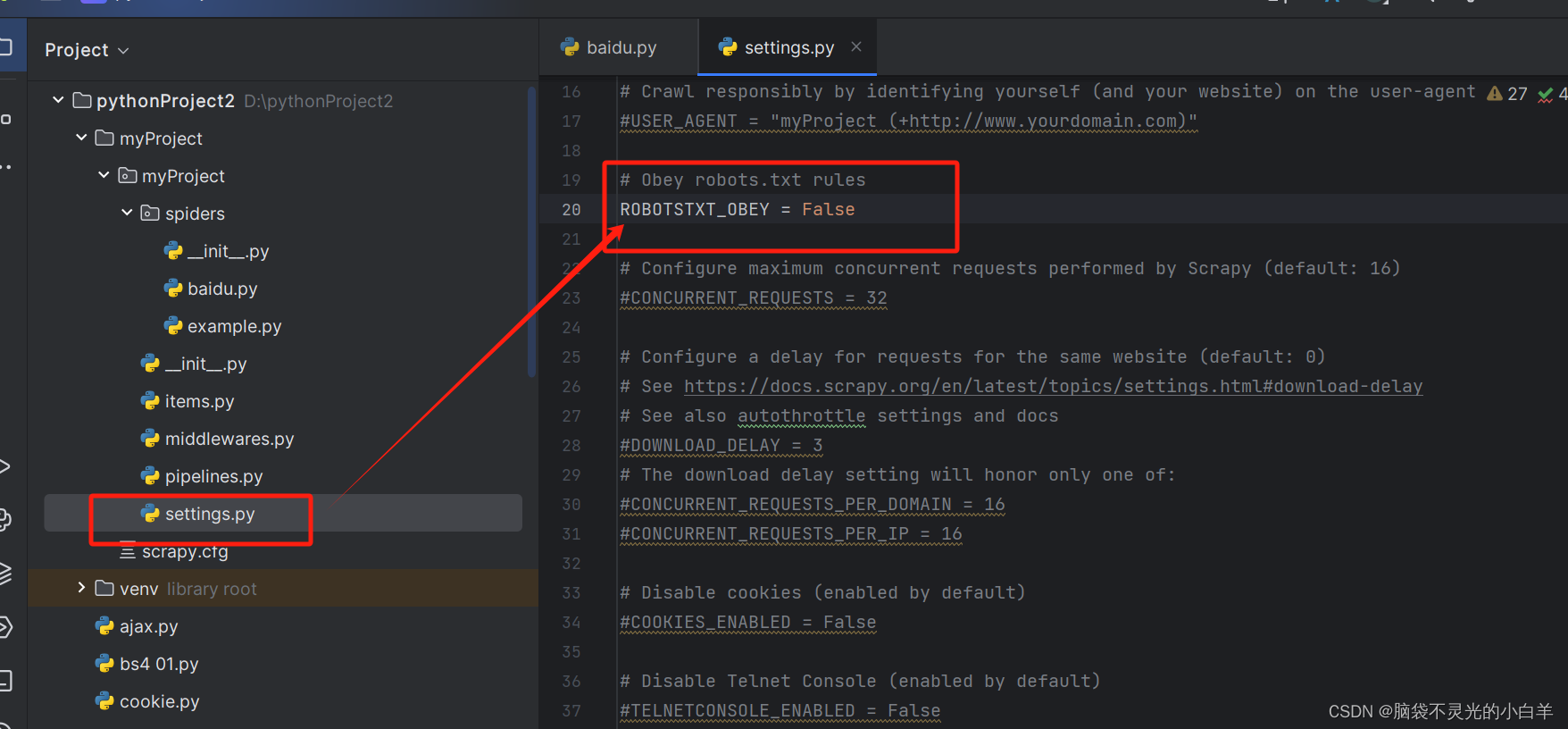
Scrapy数据的提取
从网页中提取数据,scrapy使用基于xpath和CSS表达式的技术叫做选择器
import scrapy
from scrapy.selector import Selector
class GetDataSpider(scrapy.Spider):
name = 'get_data'
allowed_domains = ['baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
# 获取title
# extract()、getall() 从选择器里面获取多条数据
# extract()、get() 从选择器里面获取一条数据
# 方式 1:xpath
title1 = response.xpath('//title/text()').extract()
print(title1)
title2 = response.xpath('//title/text()').getall()
print(title2)
title3 = response.xpath('//title/text()').extract_first()
print(title3)
title4 = response.xpath('//title/text()').get()
print(title4)
# 方式 2:css
print("=====css======")
c1 = response.css('title::text').extract_first()
c2 = response.css('title').xpath('./text()').get() # 可以混合使用
print(c1)
print(c2)
# 方式 3:re
print('=======re=======')
r1 = response.selector.re('<title>(.+)</title>')
s1 = Selector(response = response) # 手动创建selector
r2 = s1.re('<title>(.+)</title>')
print(r1)
print(r2)
scrapy的调试方式
scrapy shell http://www.baidu.com
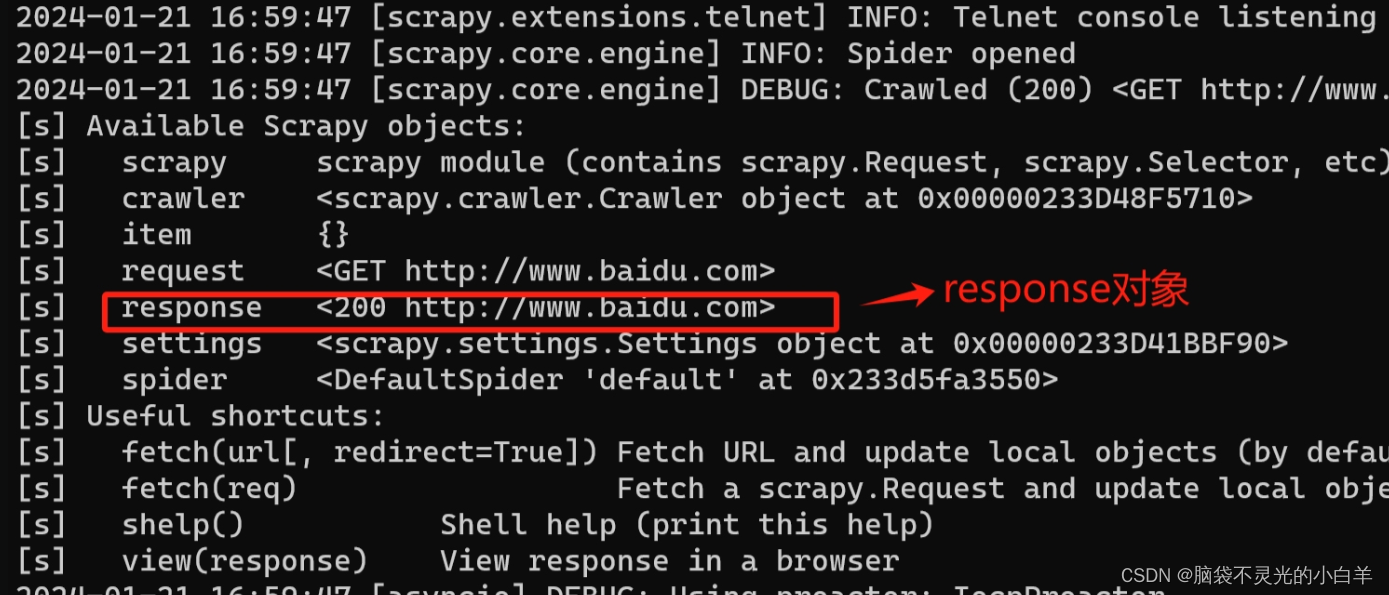
在不直接编写spider文件的情况下,去临时调试一个网页的爬虫逻辑。例如我们现在需要获取百度首页的“百度一下”:
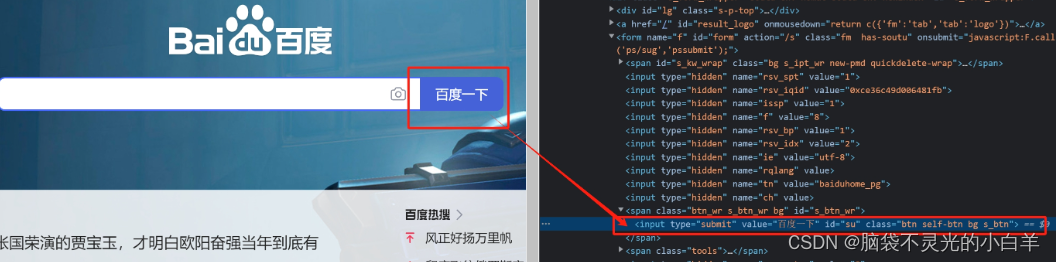
此时我们利用response对象,就可以直接执行xpath函数获取该元素对象的信息:

scrapy 的数据保存
import scrapy
class SaveDataSpider(scrapy.Spider):
name = 'save_data'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
titles = response.xpath('//a/span[@class="title"][1]/text()').getall()
stars = response.xpath('//span[@class="rating_num"]/text()').getall()
for t,s in zip(titles,stars):
print(f'{t},{s}')
注意:需要在setting文件中,修改 User_Agent
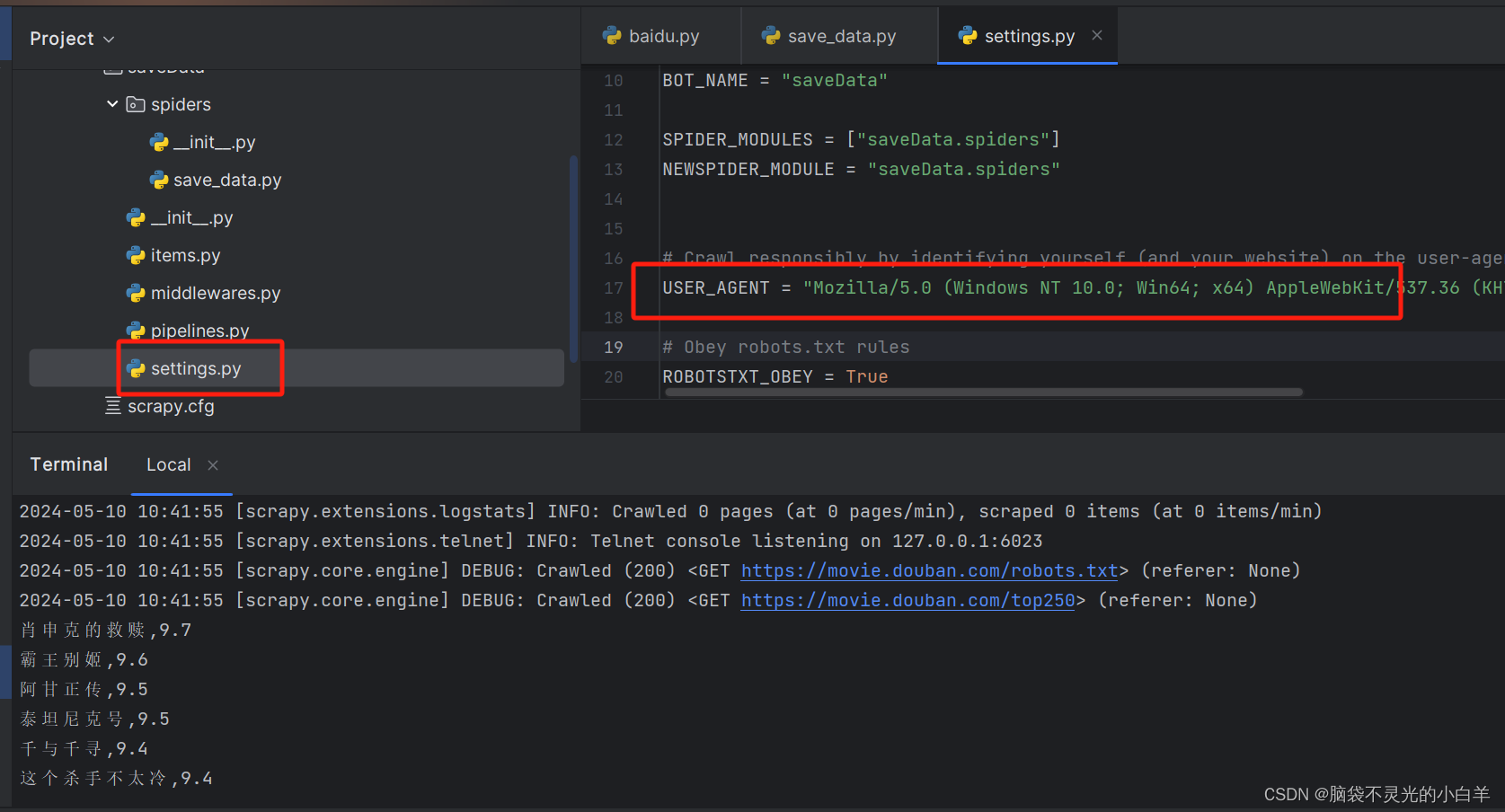
import scrapy
class SaveDataSpider(scrapy.Spider):
name = 'save_data'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
titles = response.xpath('//a/span[@class="title"][1]/text()').getall()
stars = response.xpath('//span[@class="rating_num"]/text()').getall()
# 输出到控制台
# for t,s in zip(titles,stars):
# print(f'{t},{s}')
# 保存到txt
# with open('movie.txt','w',encoding='utf-8') as f:
# for t,s in zip(titles,stars):
# f.write(f'{t},{s}\n')
# 使用yieid
for t, s in zip(titles, stars):
yield{
'title':t,
'star':s
}
# scrapy crawl spider_name -o filename.type
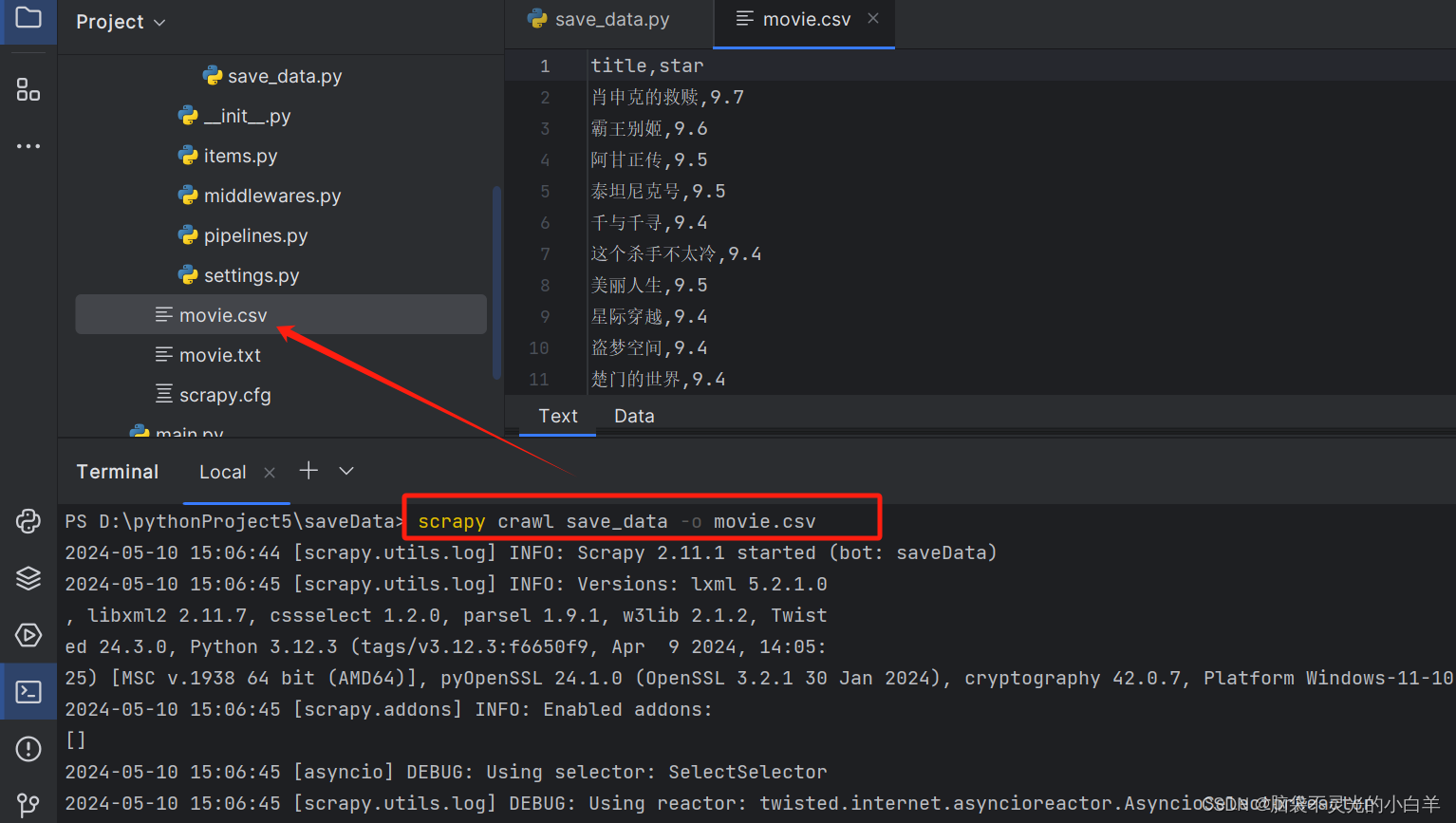
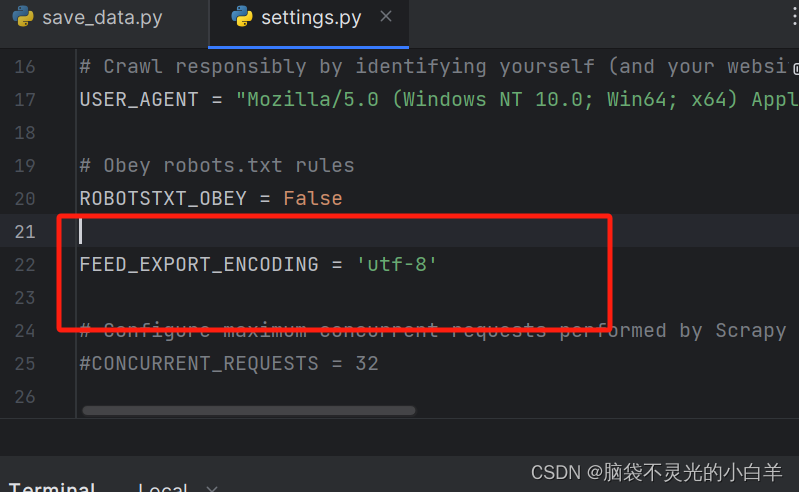
注意:如果输出的结果是json格式并且出现乱码可以直接在 setting 文件中配置:
FEED_EXPORT_ENCODING = 'utf-8'
scrapy中的pippeline的使用
必须要实现的函数
process_item(self,item,spider)
- 每个 item piple 组件是一个独立的python类,必须实现以 process_item(self,item,spider) 方法
- 每个 item piple 组件都需要调佣该方法,这个方法必须返回一个具有数据的 dict,或者item 对象,或者抛出DropItem异常,被丢弃的item 将不会被之后的 pippeline 组件所处理
可以选择实现
1、表示当 spider 被开启的时候调用这个方法
open_spider(self,spider)
2、当 spider 关闭的时候这个方法被调用
close_spider(self,spider)
Pipeline使用
首先要开启 Pipeline:
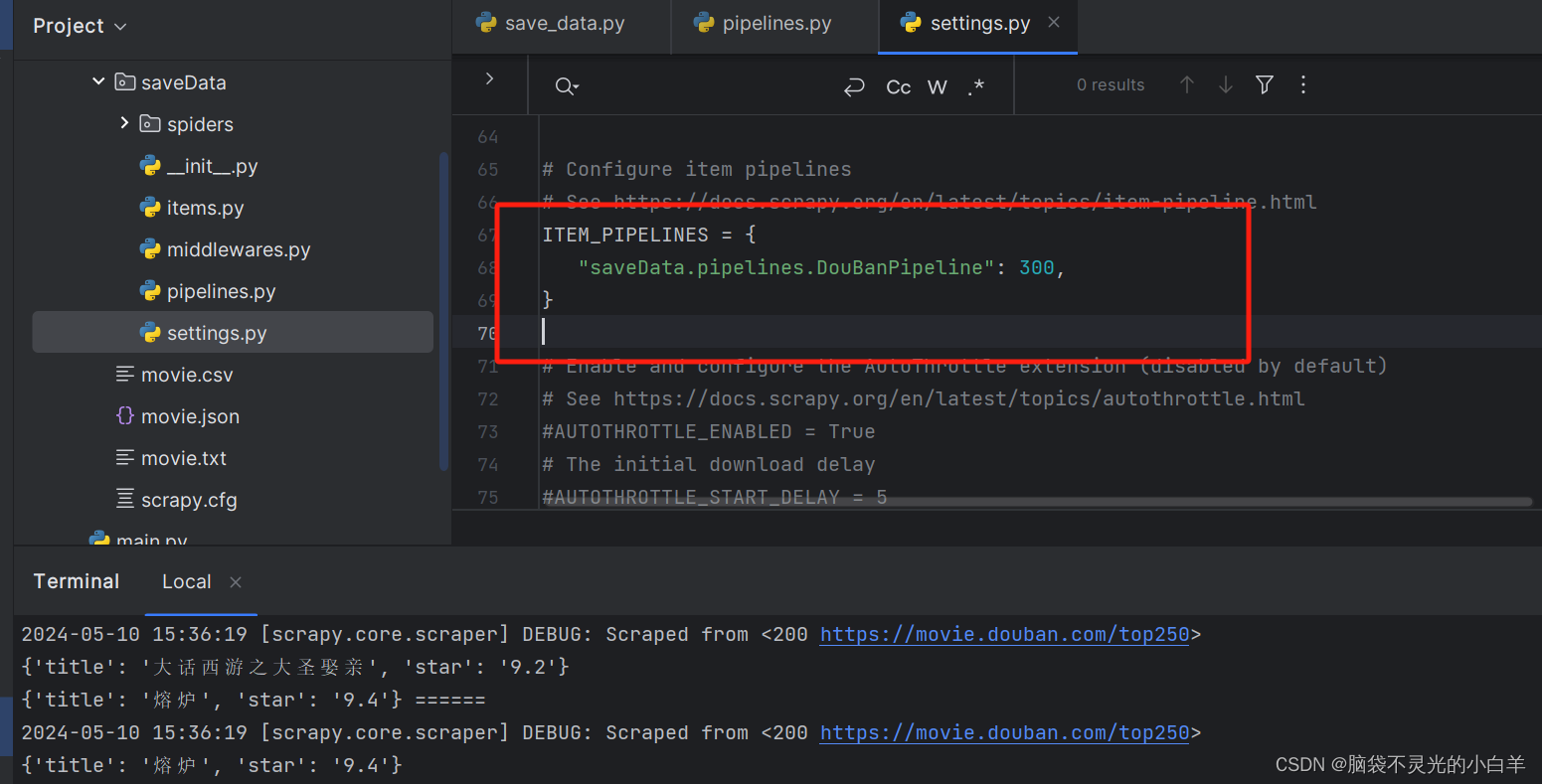
1、使用 dict 方式给Pipeline推送参数
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class DouBanPipeline:
def process_item(self, item, spider):
print(item,'======')
return item
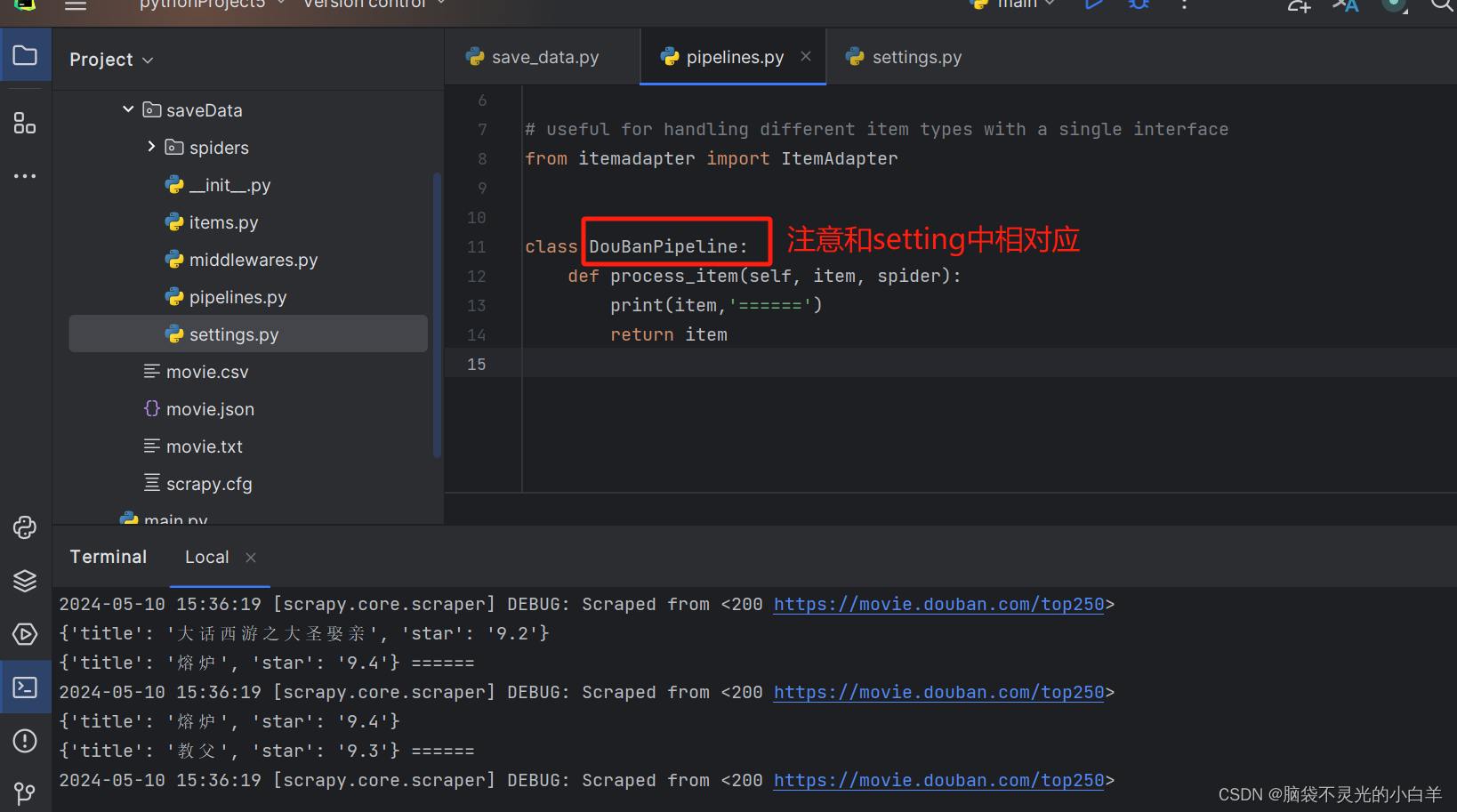
2、使用自定义的 item 方式给Pipeline推送参数(推荐使用)
编写 items文件
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MovieItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
star = scrapy.Field()
调整代码
import scrapy
from saveData.items import MovieItem
class SaveDataSpider(scrapy.Spider):
name = 'save_data'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
titles = response.xpath('//a/span[@class="title"][1]/text()').getall()
stars = response.xpath('//span[@class="rating_num"]/text()').getall()
# 使用yieid
# for t, s in zip(titles, stars):
# yield{
# 'title':t,
# 'star':s
# }
# 自定义item
for t, s in zip(titles, stars):
item = MovieItem()
item['title'] = t
item['star'] = s
yield item
Pipeline保存数据
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class DouBanPipeline:
def open_spider(self,spider):
self.file = open('movie2.txt','w',encoding='utf-8')
def process_item(self, item, spider):
info = f'{item.get("title")},{item.get("star")}\n'
self.file.write(info)
return item
def close_spider(self,spider):
self.file.close()
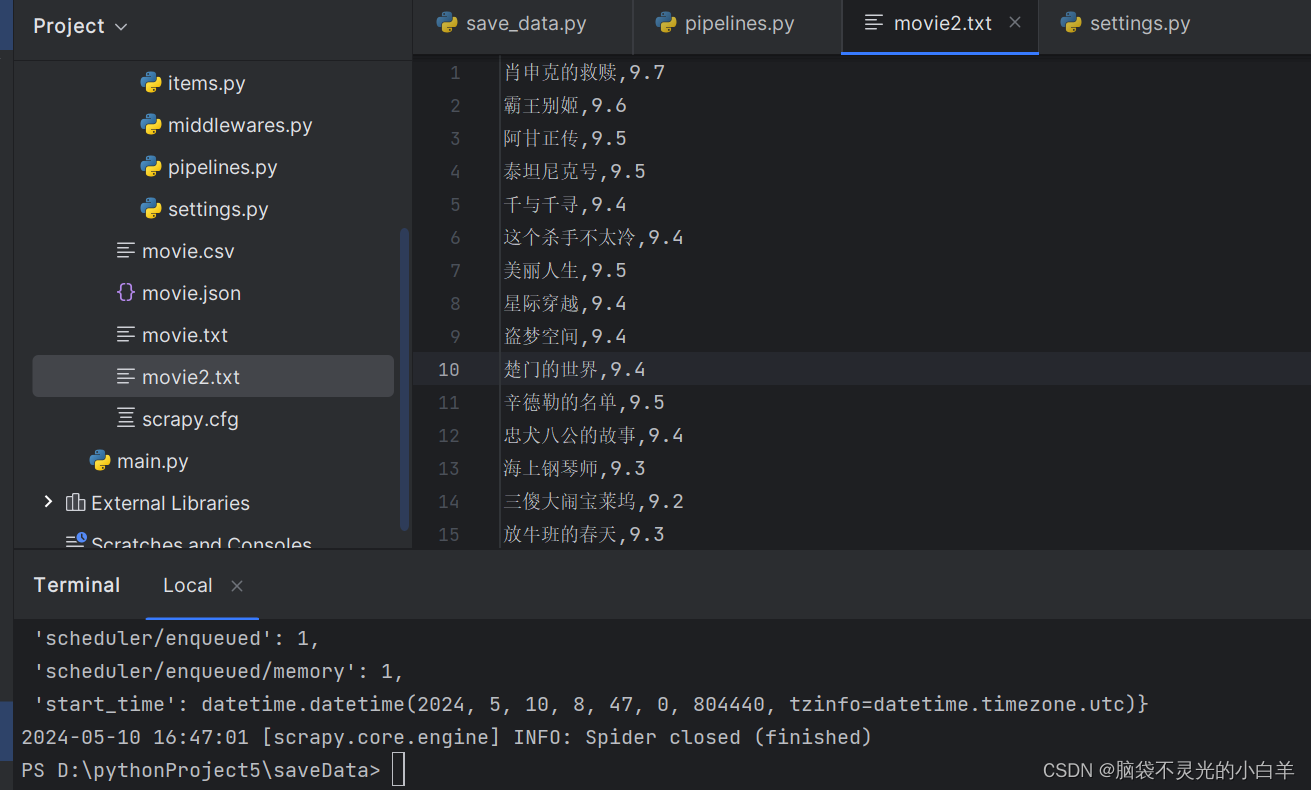
scrapy 中 ImgPipeline 的使用
scrapy提供了一个 item pipeline,来下载属于某个特定项目的图片,比如当你抓取产品时,也想把他们的图片下载到本地。
这条管道,被称作图片管道, 在 ImagesPipeline 类中实现,提供了一个方便并具有额外特性的方法,来下载并本地存储图片。
- 将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
- 避免重新下载最近已经下载过的图片
- 缩略图生成
- 检测图像的宽、高,确保它们满足最小限制
使用
1、关闭robots 协议

2、设置 User-Agent

3、开启 item pipeline
(1)安装 pillow
pip install pillow
(2)配置自定义 imagPipeline
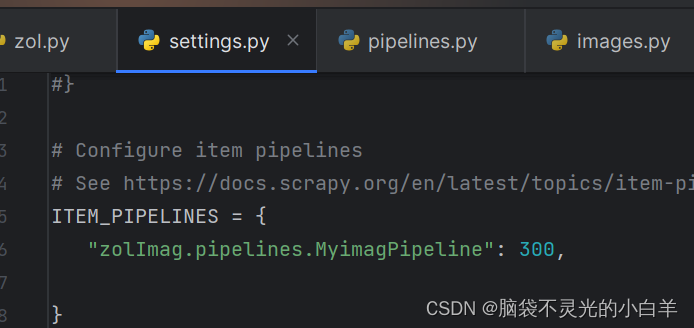
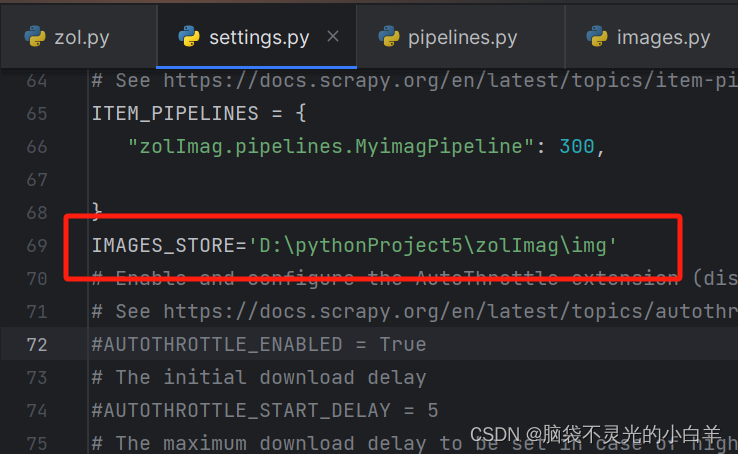
(3)指定图片保存路径
IMAGES_STORE='D:\pythonProject5\zolImag\img'
(4)编写爬取规则
import scrapy
class ZolSpider(scrapy.Spider):
name = "zol"
allowed_domains = ["www.k.sina.com.cn"]
start_urls = ["https://k.sina.com.cn/article_2879147004_ab9c4bfc00100lzv5.html"]
def parse(self, response):
img_url = response.xpath('//div[@id="article"]/p[last()-20]/img/@src').get()
yield {
'img_url':img_url
}
(5)编写Pipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from scrapy.pipelines.images import ImagesPipeline
from scrapy.http import Request
class MyimagPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
print(item)
return Request(item.get('img_url'))
# 修改图片名称
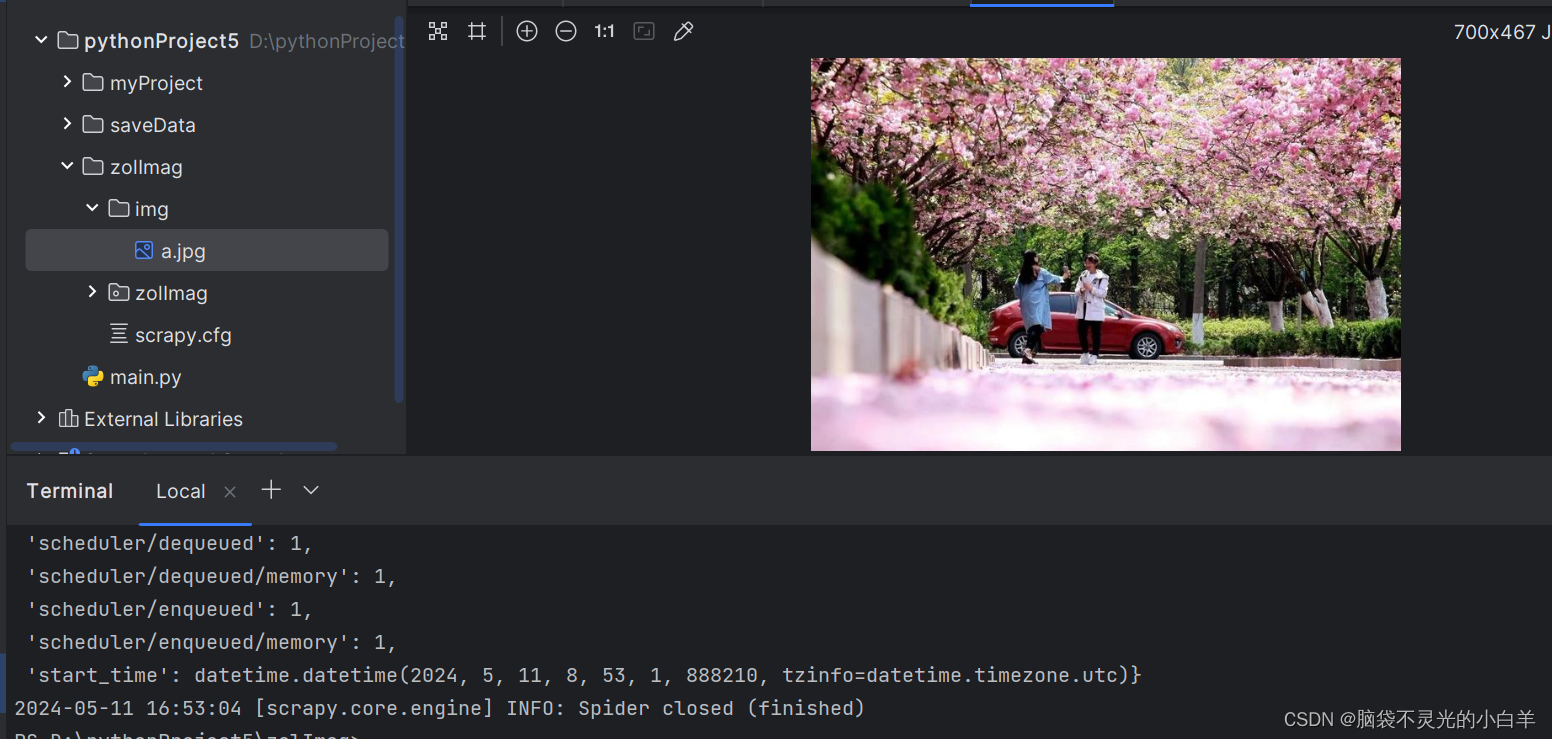
def file_path(self, request, response=None, info=None, *, item=None):
return f"a.jpg"
获取多张图片
编写爬取规则
import scrapy
class ZolSpider(scrapy.Spider):
name = "zol"
allowed_domains = ["www.zol.com.cn"]
start_urls = ["https://desk.zol.com.cn/bizhi/9630_116592_2.html"]
def parse(self, response):
img_url = response.xpath('//img[@id="bigImg"]/@src').get()
img_name = response.xpath('string(//h3)').get().strip().replace('\r\n\t\t','')
yield {
'img_url':img_url,
'img_name': img_name
}
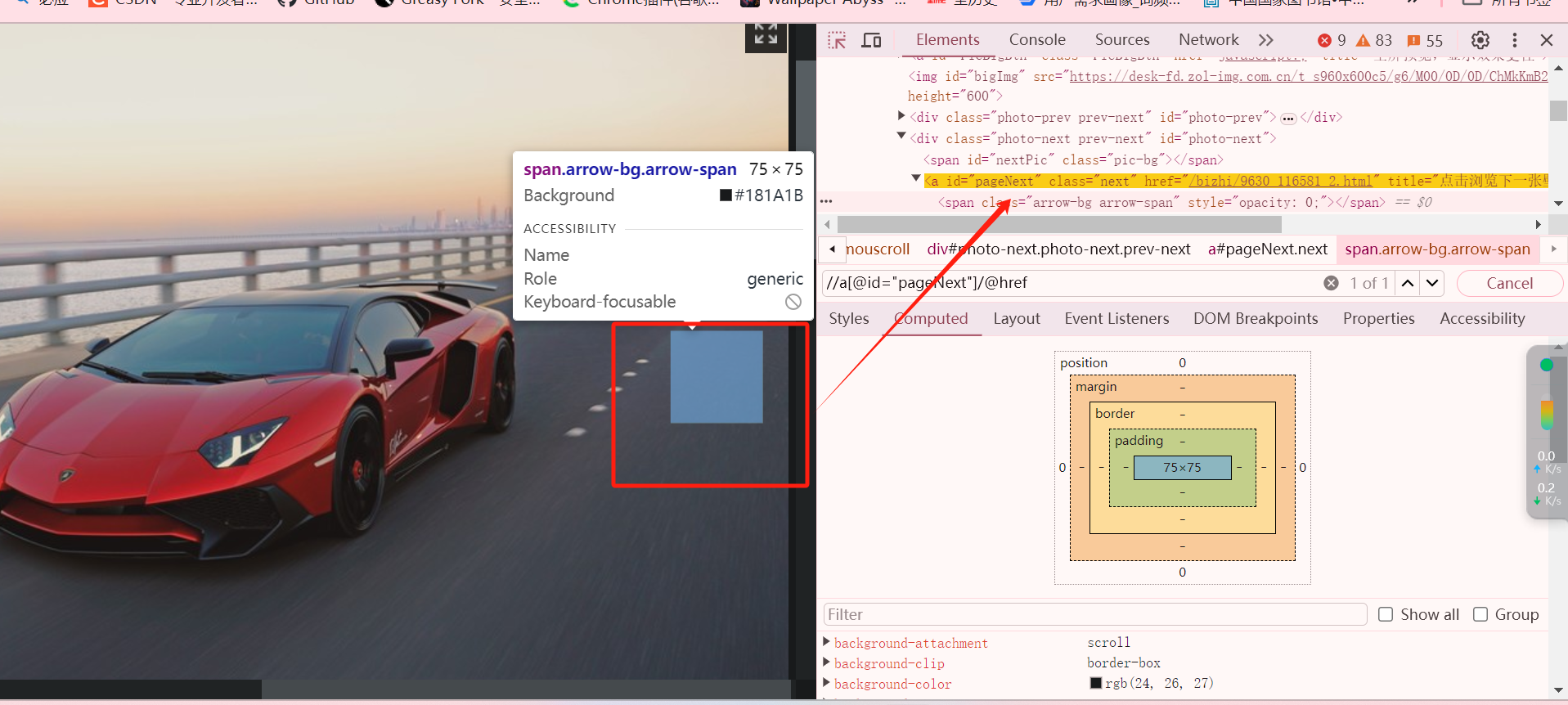
# 下一页选择器
next_url = response.xpath('//a[@id="pageNext"]/@href').get()
# 最后一页不做拼接
if next_url.find('javascript') == -1:
full_url = response.urljoin(next_url)
yield scrapy.Request(full_url)
修改 Pipelines 文件
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from scrapy.pipelines.images import ImagesPipeline
from scrapy.http import Request
class MyimagPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
name = item.get('img_name')
return Request(item.get('img_url'),meta={'name':name})
# 修改图片名称
def file_path(self, request, response=None, info=None, *, item=None):
name = request.meta.get('name')
# 处理异常字符
name = name.replace('/','_')
return f"{name}.jpg"

scrapy中的setting的使用
# Scrapy settings for ScrapyDemo project
# 自动生成的配置,无需关注,不用修改
BOT_NAME = 'ScrapyDemo'
SPIDER_MODULES = ['ScrapyDemo.spiders']
NEWSPIDER_MODULE = 'ScrapyDemo.spiders'
# 设置UA,但不常用,一般都是在MiddleWare中添加
USER_AGENT = 'ScrapyDemo (+http://www.yourdomain.com)'
# 遵循robots.txt中的爬虫规则,很多人喜欢False,当然我也喜欢....
ROBOTSTXT_OBEY = True
# 对网站并发请求总数,默认16
CONCURRENT_REQUESTS = 32
# 相同网站两个请求之间的间隔时间,默认是0s。相当于time.sleep()
DOWNLOAD_DELAY = 3
# 下面两个配置二选一,但其值不能大于CONCURRENT_REQUESTS,默认启用PER_DOMAIN
# 对网站每个域名的最大并发请求,默认8
CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 默认0,对网站每个IP的最大并发请求,会覆盖上面PER_DOMAIN配置,
# 同时DOWNLOAD_DELAY也成了相同IP两个请求间的间隔了
CONCURRENT_REQUESTS_PER_IP = 16
# 禁用cookie,默认是True,启用
COOKIES_ENABLED = False
# 请求头设置,这里基本上不用
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# 配置启用Spider MiddleWares,Key是class,Value是优先级
SPIDER_MIDDLEWARES = {
'ScrapyDemo.middlewares.ScrapydemoSpiderMiddleware': 543,
}
# 配置启用Downloader MiddleWares
DOWNLOADER_MIDDLEWARES = {
'ScrapyDemo.middlewares.ScrapydemoDownloaderMiddleware': 543,
}
# 配置并启用扩展,主要是一些状态监控
EXTENSIONS = {
'scrapy.extensions.telnet.TelnetConsole': None,
}
# 配置启用Pipeline用来持久化数据
ITEM_PIPELINES = {
'ScrapyDemo.pipelines.ScrapydemoPipeline': 300,
}
# 禁止控制台使用telnet连接scrapy获取状态,默认是启用。我们使用默认值即可
TELNETCONSOLE_ENABLED = False
# Telnet终端使用的端口范围。默认: [6023, 6073],如果设置为 None 或 0 , 则使用动态分配的端口
# TELNETCONSOLE_PORT
# telnet账号,默认:scrapy
TELNETCONSOLE_USERNAME = None
# telnet密码:默认会自动生成一个密码
TELNETCONSOLE_PASSWORD
# Telnet终端监听的接口(interface)。默认: '127.0.0.1'
TELNETCONSOLE_HOST = '127.0.0.1'
# AutoThrottle是限速节流算法
# 让爬虫程序自适应download_delay和concurrent并发
AUTOTHROTTLE_ENABLED = True
# 爬虫程序启动时,开始对网站发起请求的延迟
AUTOTHROTTLE_START_DELAY = 5
# 请求到响应的最大允许的延迟时间,必须大于download_delay
AUTOTHROTTLE_MAX_DELAY = 60
# 并行发送到每个远程服务器的平均请求数,小于CONCURRENT_REQUESTS_PER_DOMAIN和CONCURRENT_REQUESTS_PER_IP
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# 为每个响应启用显示限制统计信息
AUTOTHROTTLE_DEBUG = False
# HttpCache主要是将每次的请求和响应缓存到本地,可以离线进行处理
# 配置启用HTTP Cache,默认不启用
HTTPCACHE_ENABLED = True
# 缓存的过期时间,0为永不过期
HTTPCACHE_EXPIRATION_SECS = 0
# 缓存目录名称
HTTPCACHE_DIR = 'httpcache'
# 设置不需要缓存的状态码请求
HTTPCACHE_IGNORE_HTTP_CODES = []
# 此类将缓存保存到本地文件系统,还可以使用其他类保存到数据库
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
scrapy 获取小说信息
1、关闭 robots协议
2、配置 USER_AGENT
3、编写爬取规则
方式一:直接从第一章开始爬取
import scrapy
class XisSpider(scrapy.Spider):
name = "xis"
allowed_domains = ["www.xbiquge.to"]
# 第一章
start_urls = ["https://www.xbiquge.to/article/169482/64775516.html"]
def parse(self, response):
title = response.xpath('//h1/text()').get()
content = response.xpath('string(//div[@id="htmlContent"])').get().strip().replace(u'\xa0', '')
# 返回数据
yield {
'title':title,
'content':content
}
# 下一章
next_url = response.xpath('//div[@class="yd_linebot"]/span[4]/a/@href').get()
yield scrapy.Request(response.urljoin(next_url))
4、开启 Pipeline
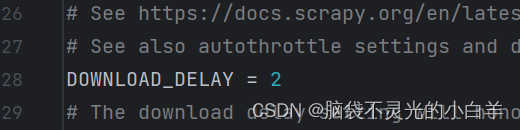
5、设置间隔时间
6、编写 pipelines文件
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class BookPipeline:
def open_spider(self, spider):
self.file = open('xs.txt','w',encoding='utf-8')
def process_item(self, item, spider):
self.file.write(item.get('title'))
self.file.write('\n')
self.file.write(item.get('content'))
self.file.write('\n')
return item
def close_spider(self, spider):
self.file.close()
方式二:从目录开始爬取
import scrapy
class XisSpider(scrapy.Spider):
name = "xis2"
allowed_domains = ["www.xbiquge.to"]
# start_urls = ["https://www.xbiquge.to/article/169482/"]
# start_urls的另一种写法:当携带参数时用
def start_requests(self):
yield scrapy.Request('https://www.xbiquge.to/article/169482/')
# 从目录获取
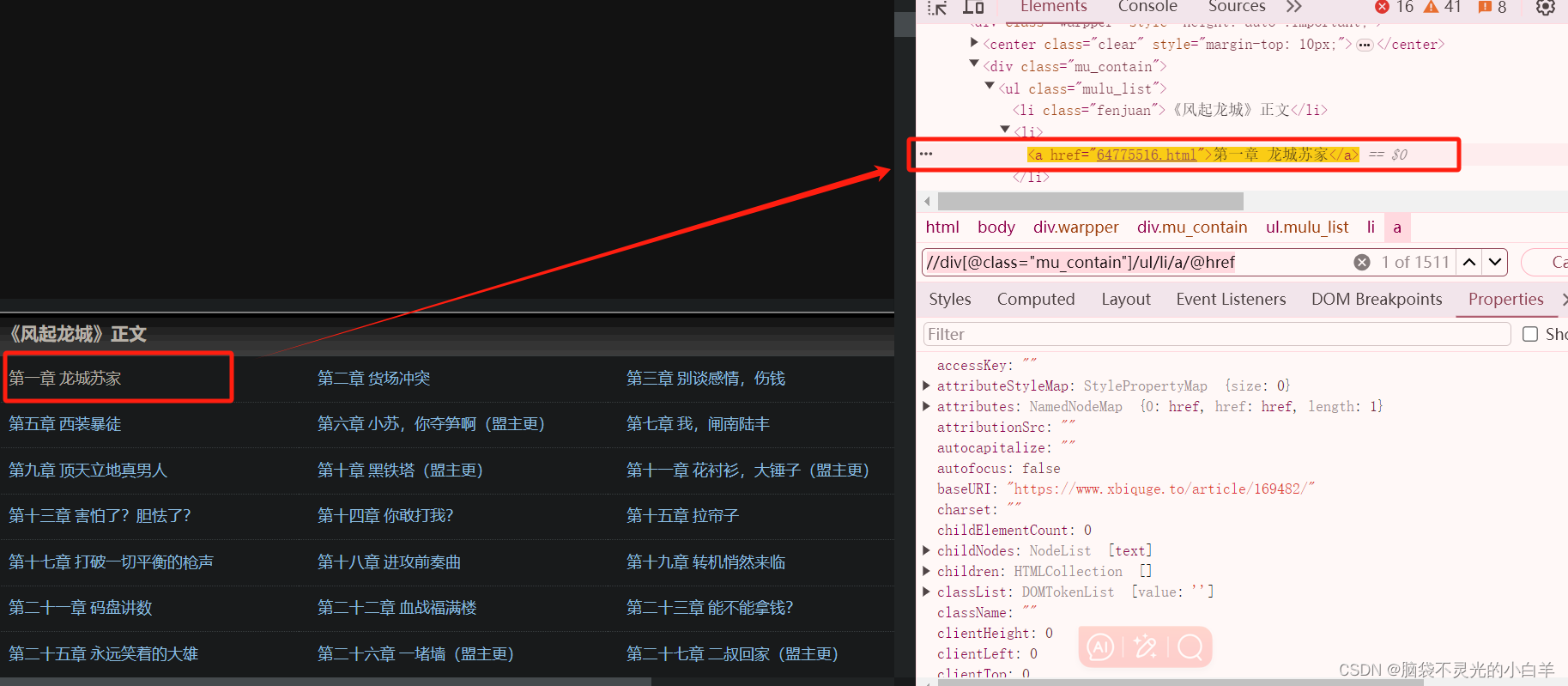
def parse(self, response):
next_url = response.xpath('//div[@class="mu_contain"]/ul/li/a/@href').get()
yield scrapy.Request(response.urljoin(next_url),callback=self.parse_info)
def parse_info(self, response):
title = response.xpath('//h1/text()').get()
content = response.xpath('string(//div[@id="htmlContent"])').get().strip().replace(u'\xa0', '')
# 返回数据
yield {
'title':title,
'content':content
}
# 下一章
next_url = response.xpath('//div[@class="yd_linebot"]/span[4]/a/@href').get()
yield scrapy.Request(response.urljoin(next_url),callback=self.parse_info)
scrapy中 crawlspider 的使用
创建 crawlspider 模版
scrapy genspider -t crawl 文件名 (allowed_url)
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Xis3Spider(CrawlSpider):
name = "xis3"
allowed_domains = ["xbiquge.to"]
start_urls = ["https://www.xbiquge.to/article/169482/"]
rules = (
# 从目录中获取第一章
Rule(LinkExtractor(restrict_xpaths=r'//div[@class="mu_contain"]/ul/li/a'),
callback="parse_item", follow=True),
# 下一章
Rule(LinkExtractor(restrict_xpaths=r'//div[@class="yd_linebot"]/span[4]/a'),
callback="parse_item", follow=True),
)
def parse_item(self, response):
title = response.xpath('//h1/text()').get()
content = response.xpath('string(//div[@id="htmlContent"])').get().strip().replace(u'\xa0', '')
# 返回数据
yield {
'title': title,
'content': content
}
scrapy中 Reuqest 对象的使用
一、利用 meta 传递参数
import scrapy
class BqgSpider(scrapy.Spider):
name = "bqg"
allowed_domains = ["xbiquge.to"]
start_urls = ["https://www.xbiquge.to/article/169482/"]
def parse(self, response):
title = response.xpath('//div[@class="mu_contain"]/ul/li[2]/a/text()').get()
next_url = response.xpath('//div[@class="mu_contain"]/ul/li[2]/a/@href').get()
yield scrapy.Request(response.urljoin(next_url),meta={'title':title},callback=self.parse_info)
def parse_info(self, response):
title = response.request.meta.get('title')
print(title,"======")
二、url 去重
import scrapy
class BaiduSpider(scrapy.Spider):
name = "baidu"
allowed_domains = ["baidu.com"]
start_urls = ["https://www.baidu.com/"]
def parse(self, response):
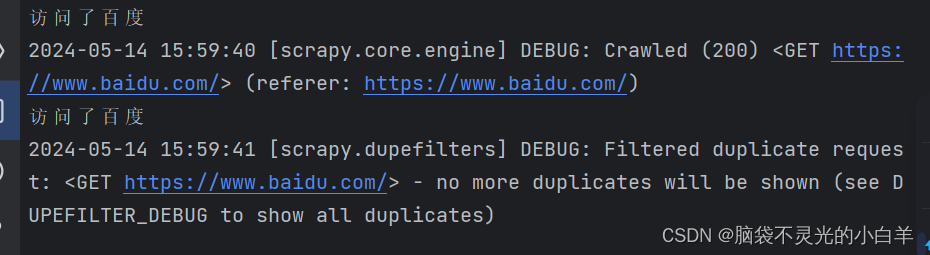
print('访问了百度')
# Request 默认是去重的
# start_urls 是去重的
yield scrapy.Request('https://www.baidu.com/')
解开去重效果
import scrapy
class BaiduSpider(scrapy.Spider):
name = "baidu"
allowed_domains = ["baidu.com"]
start_urls = ["https://www.baidu.com/"]
def parse(self, response):
print('访问了百度')
yield scrapy.Request('https://www.baidu.com/',dont_filter=True)
三、cookie
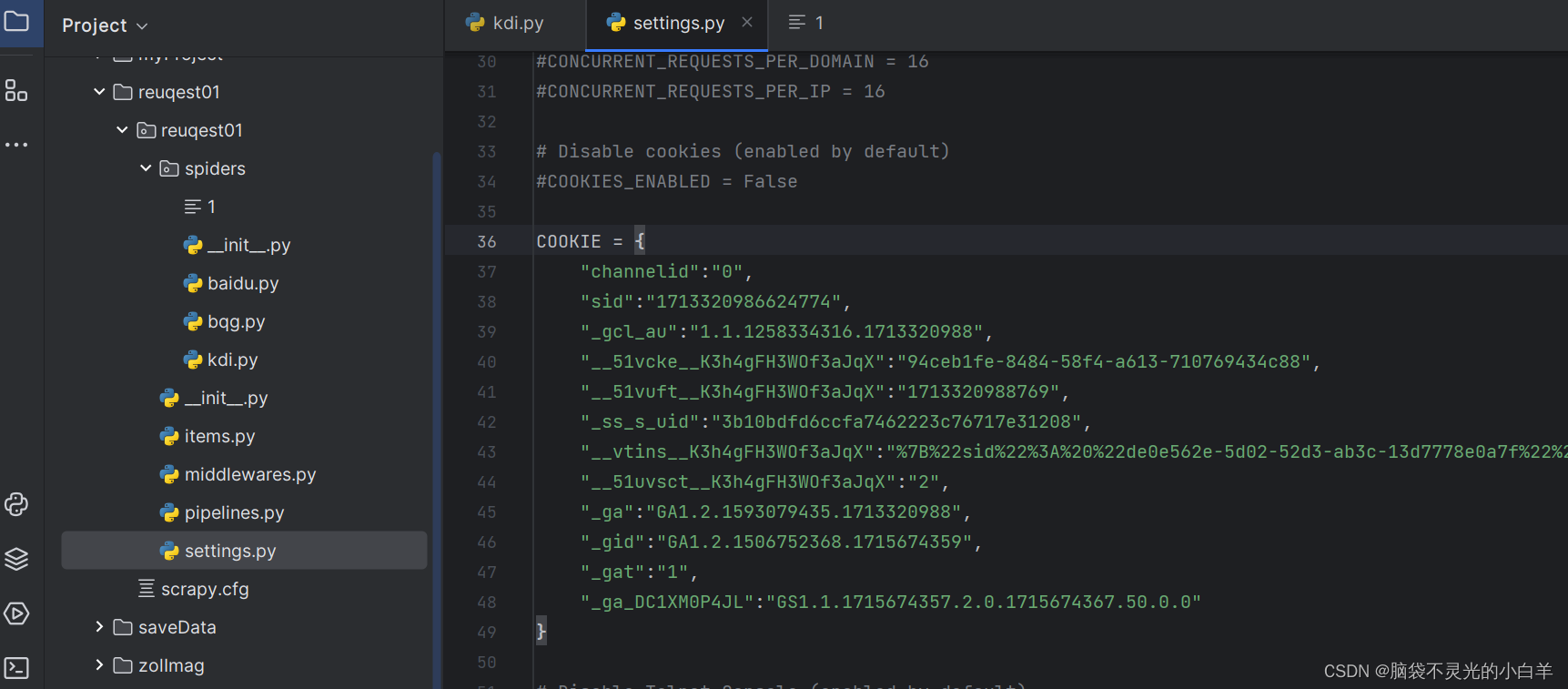
在settings文件中配置
import scrapy
from request01.settings import COOKIE
class KdiSpider(scrapy.Spider):
name = "kdi"
allowed_domains = ["kuaidaili.com"]
start_urls = ["https://www.kuaidaili.com/usercenter/"]
def start_requests(self):
yield scrapy.Request(
self.start_urls[0],
cookies=COOKIE
)
def parse(self, response):
print(response.text)
scrapy 中 FormRequest 对象
import scrapy
class LoginSpider(scrapy.Spider):
name = "login"
allowed_domains = ["kuaidaili.com"]
def start_requests(self):
url = 'https://www.kudaili.com/login/'
data = {
'login_type':'1',
'username':'ls',
'passwd':'123abc',
}
yield scrapy.FormRequest(url,formdata=data)
def parse(self, response):
yield scrapy.Request('https://www.kudaili.com/usercenter/overview/',callback=self.parse_info)
def parse_info(self,response):
print(response.text)
# cookie 默认是开启的,如果需要不再保存cookie,可以去settings中关闭【COOKIES_ENABLED = False】
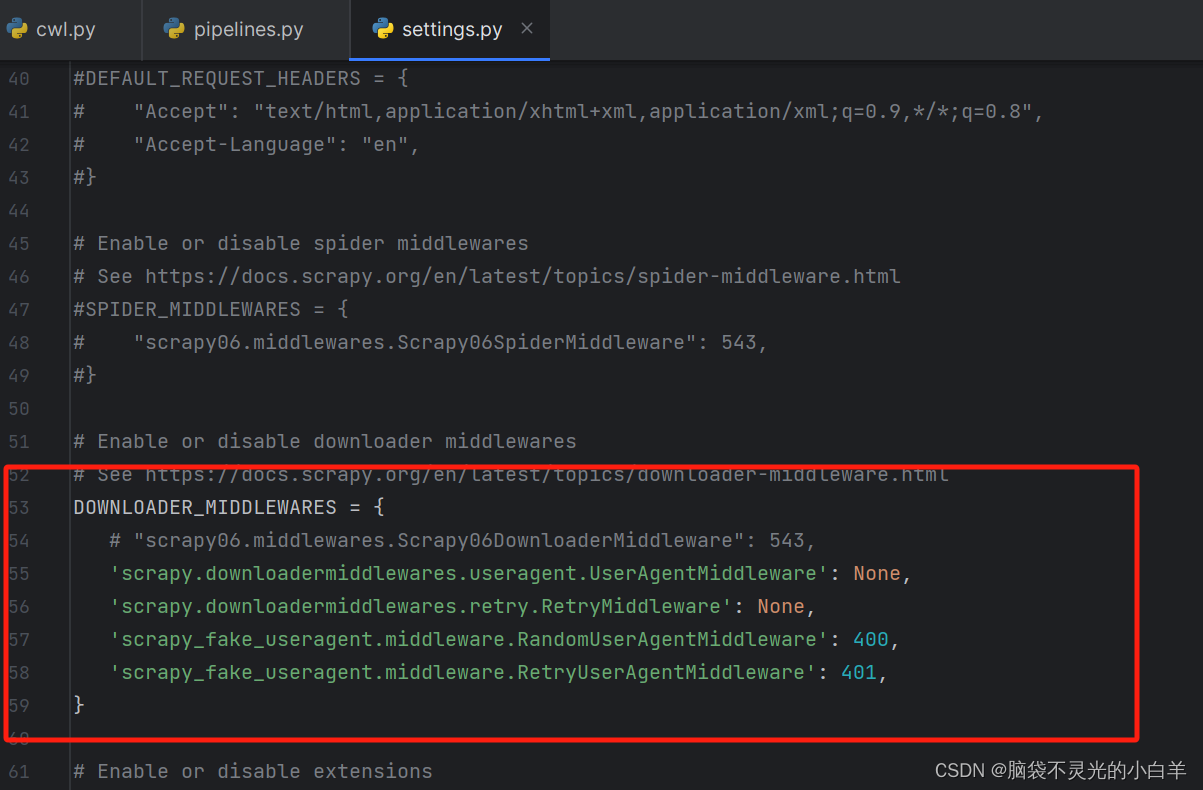
scrapy中下载中间件修改UA
方法一:安装 scrapy 动态ua模块
pip install scrapy-fake-useragent
直接在setting 中修改:
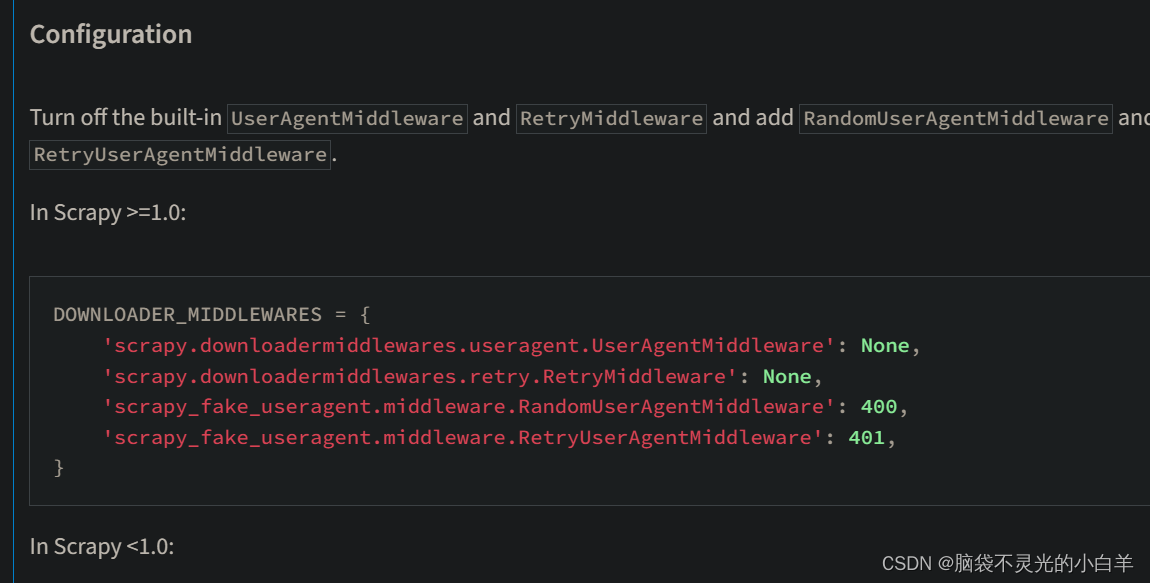
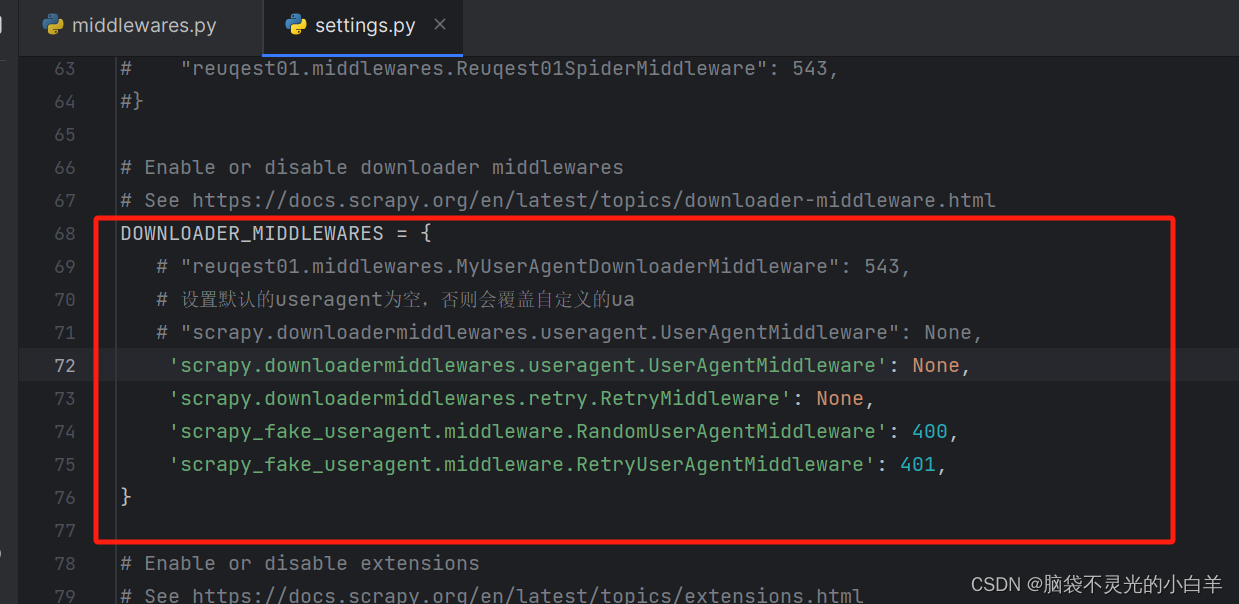
方法二:也可以 自定义 动态ua
第一步:配置 DOWNLOADER_MIDDLEWARES
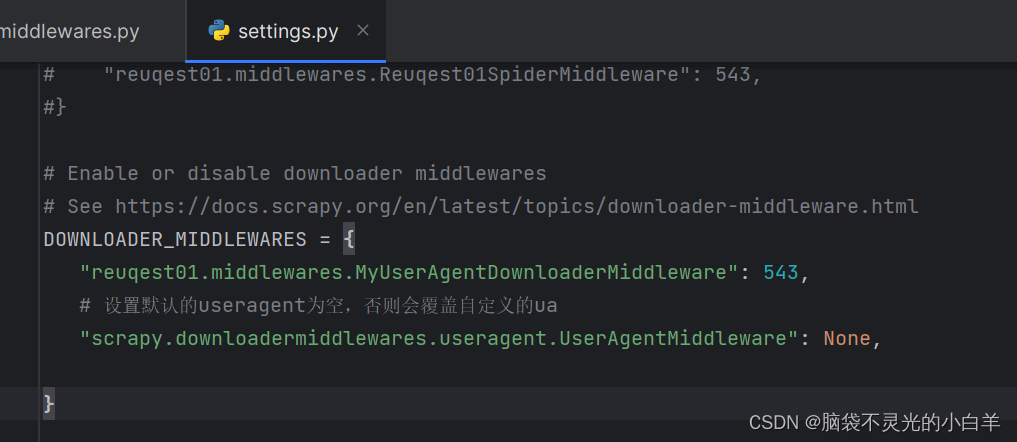
第二步:修改 middlewares文件
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from fake_useragent import UserAgent
class MyUserAgentDownloaderMiddleware:
def process_request(self, request, spider):
ua = UserAgent()
request.headers.setdefault(b"User-Agent", ua.Chrome)
scrapy中下载中间件设置代理
设置setting文件
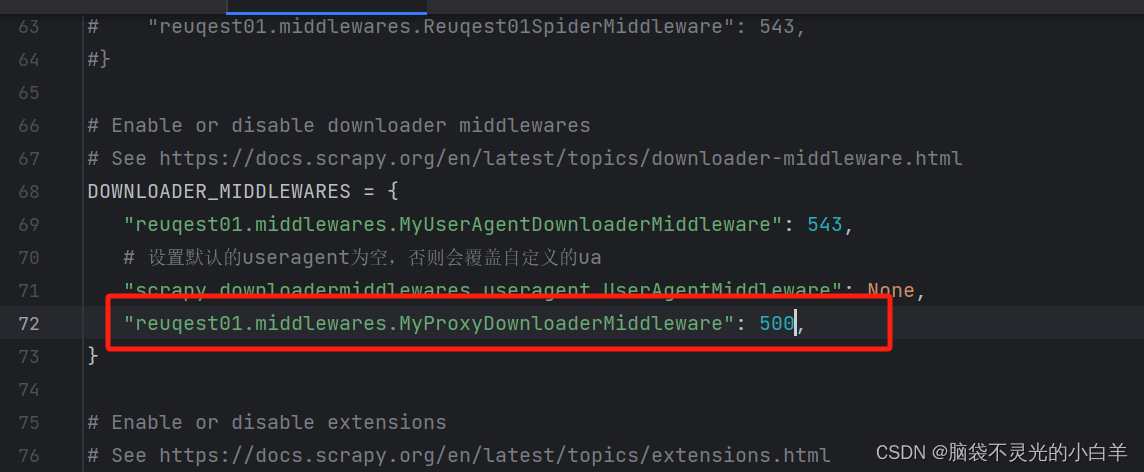
编写 middlewares文件
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from fake_useragent import UserAgent
# 设置动态代理
class MyProxyDownloaderMiddleware:
def process_request(self, request, spider):
request.meta['proxy'] = 'http://ip:prot'
scrapy 与 selenium 结合
1、下载驱动
chrome驱动的exe执行文件,放到你项目的根目录即可。下载地址:驱动
2、在创建好的项目中 编写 爬取规则
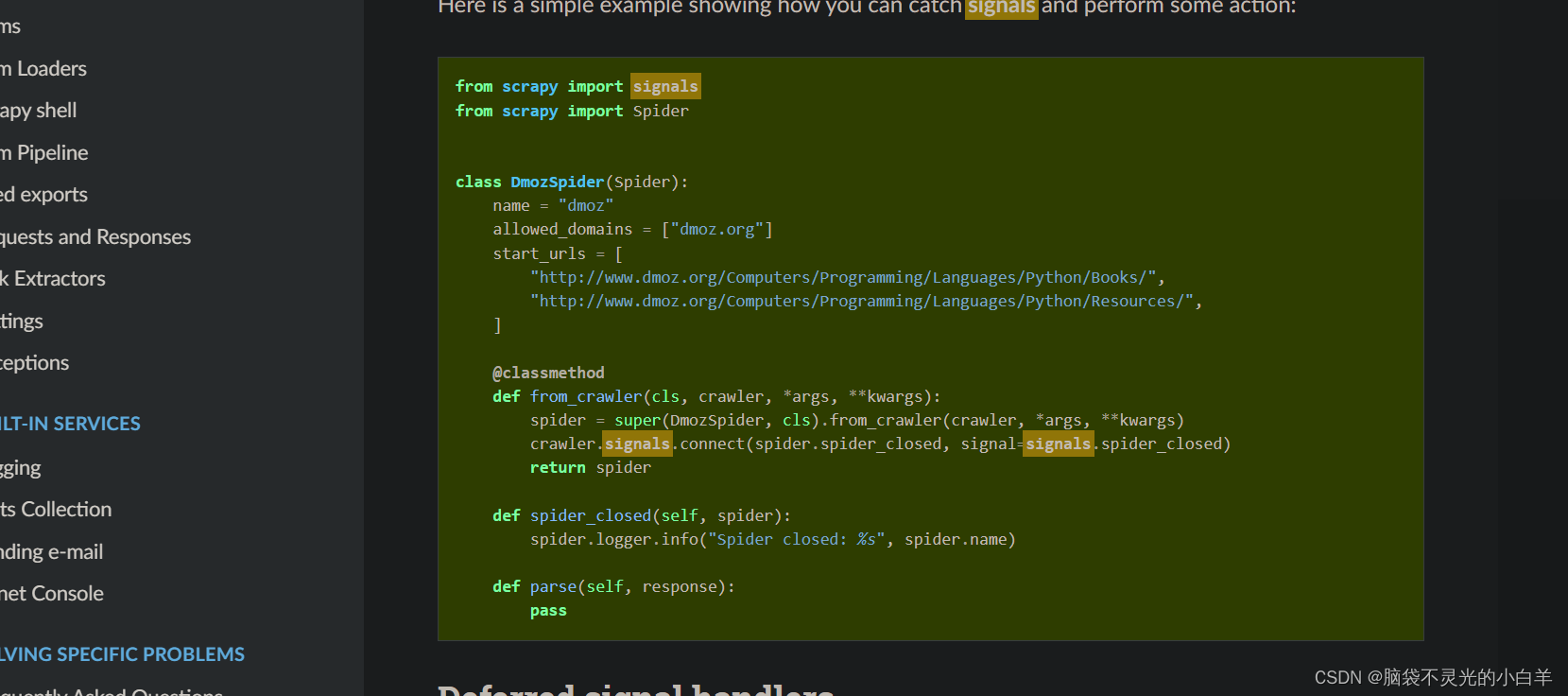
import scrapy
from selenium import webdriver
from scrapy import signals
class BaiduSpider(scrapy.Spider):
name = "baidu"
allowed_domains = ["baidu.com"]
start_urls = ["https://www.baidu.com/"]
# 抓取关闭信号
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super(DmozSpider, cls).from_crawler(crawler, *args, **kwargs)
self.chrome = webdriver.Chrome(executable_path='../tools/chromedriver.exe')
crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed)
return spider
def spider_closed(self, spider):
spider.logger.info("爬虫关闭了!")
self.chrome.close()
def parse(self, response):
print(response.text)
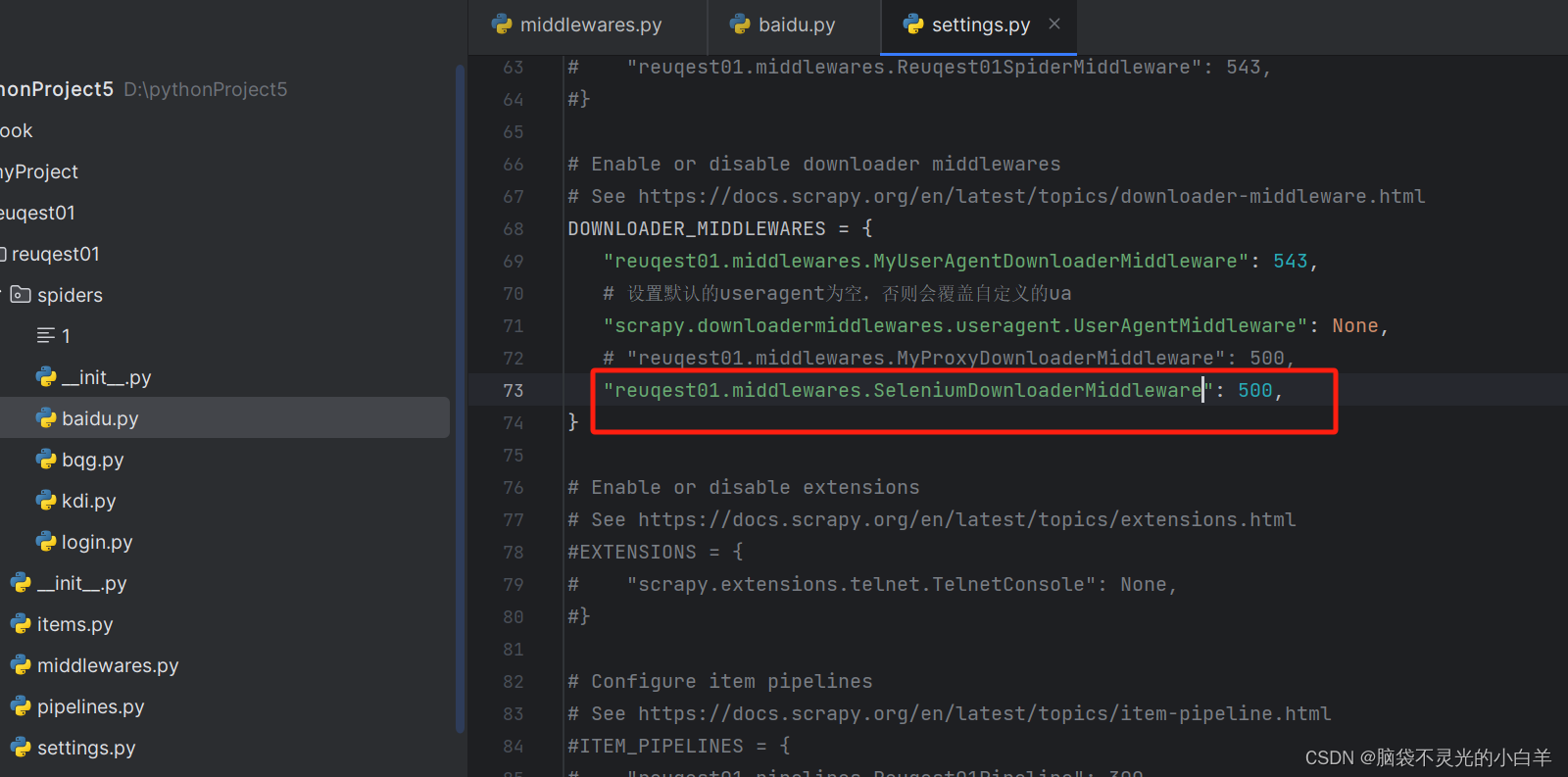
3、编写 middleware规则
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from fake_useragent import UserAgent
from scrapy.http.response.html import HtmlResponse
from selenium import webdriver
# Selenium
class SeleniumDownloaderMiddleware
def process_requests(self, request, spider):
scrapy.chrome.get(request.url)
html = scrapy.chrome.page_source
return HtmlResponse(url = request.url,body=html,encoding='utf-8')
4、开启 SeleniumDownloaderMiddleware:
scrapy 数据保存 MongoDB
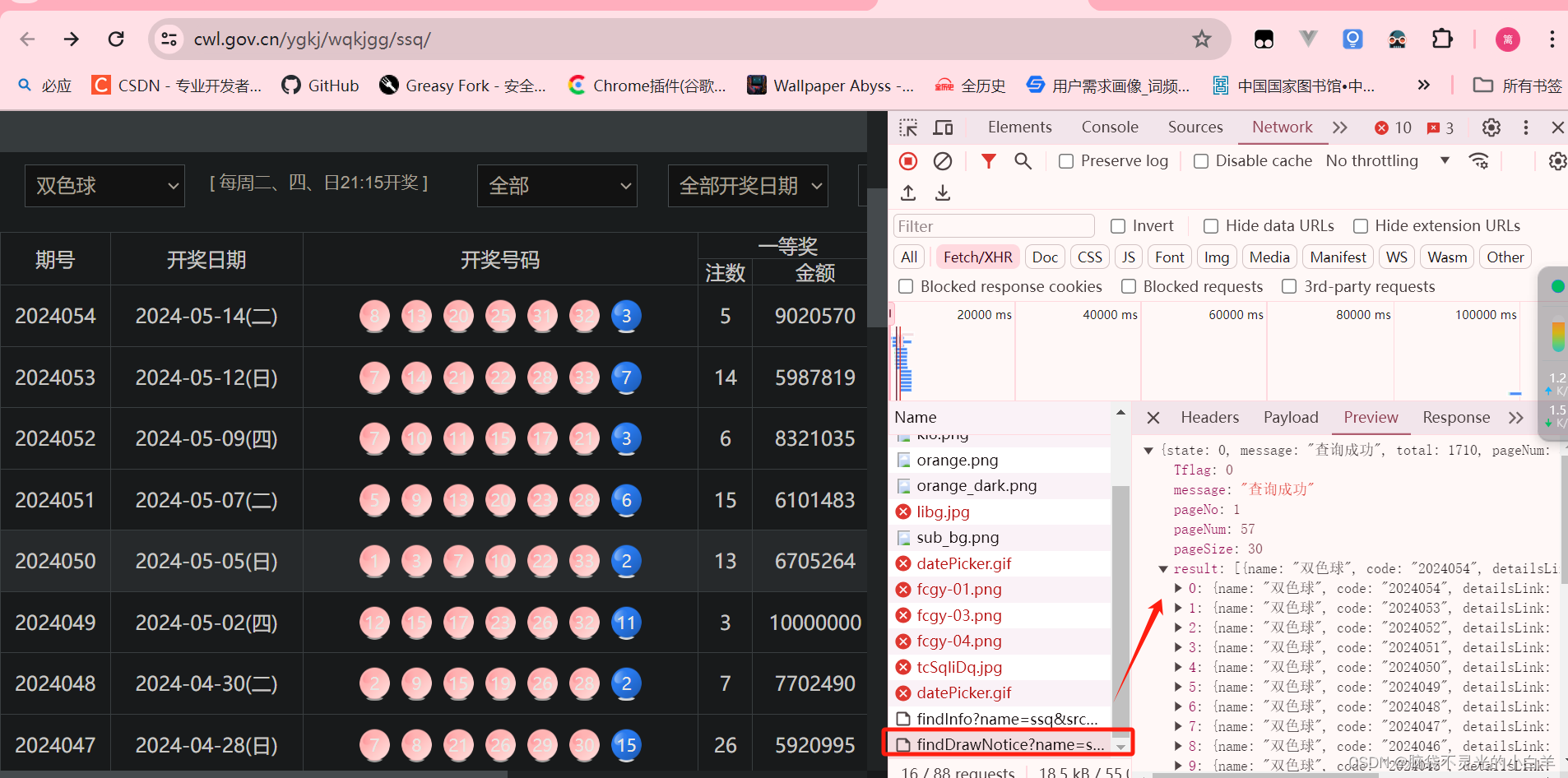
确定要爬取的接口
安装pymongo
pip install pymongo
关闭 robot 协议

配置 动态UA
编写爬取规则
import scrapy
from json import loads
class CwlSpider(scrapy.Spider):
name = "cwl"
allowed_domains = ["cwl.gov.cn"]
# start_urls = ["https://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice?name=ssq&issueCount=&issueStart=&issueEnd=&dayStart=&dayEnd=&pageNo=1&pageSize=30&week=&systemType=PC"]
def start_requests(self):
url = 'https://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice?name=ssq&pageNo=1&pageSize=30&systemType=PC'
yield scrapy.Request(url,dont_filter=True)
def parse(self, response):
print(response.text)
data = loads(response.text)
for d in data.get('result'):
red = d.get('red')
blue = d.get('blue')
code = d.get('code')
yield {
'code': code,
'red':red,
'blue':blue
}
编写Pipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from pymongo import MongoClient
class MongoPipeline:
def open_spider(self, spider):
# 连接Mongo
self.client = MongoClient()
# 创建彩票实例
self.ssq = self.client.caipiao.ssq
def process_item(self, item, spider):
# 插入数据
self.ssq.insert_one(item)
return item
def close_spider(self, spider):
self.client.close()
开启 Pipeline
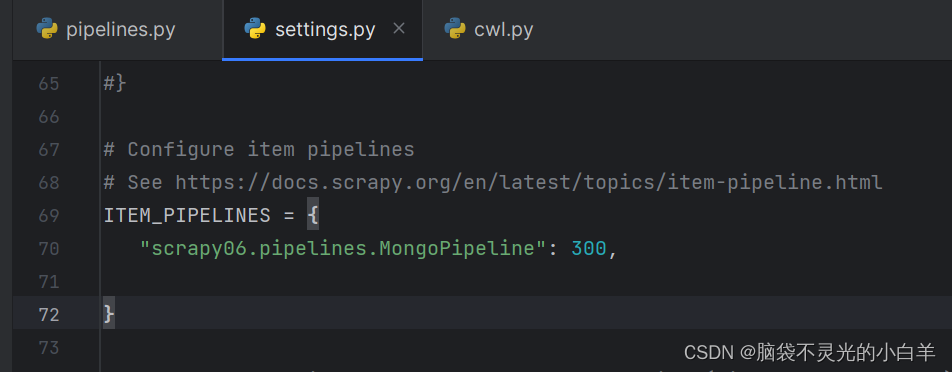
scrapy 数据保存MySQL
准备好数据库和对应的表格
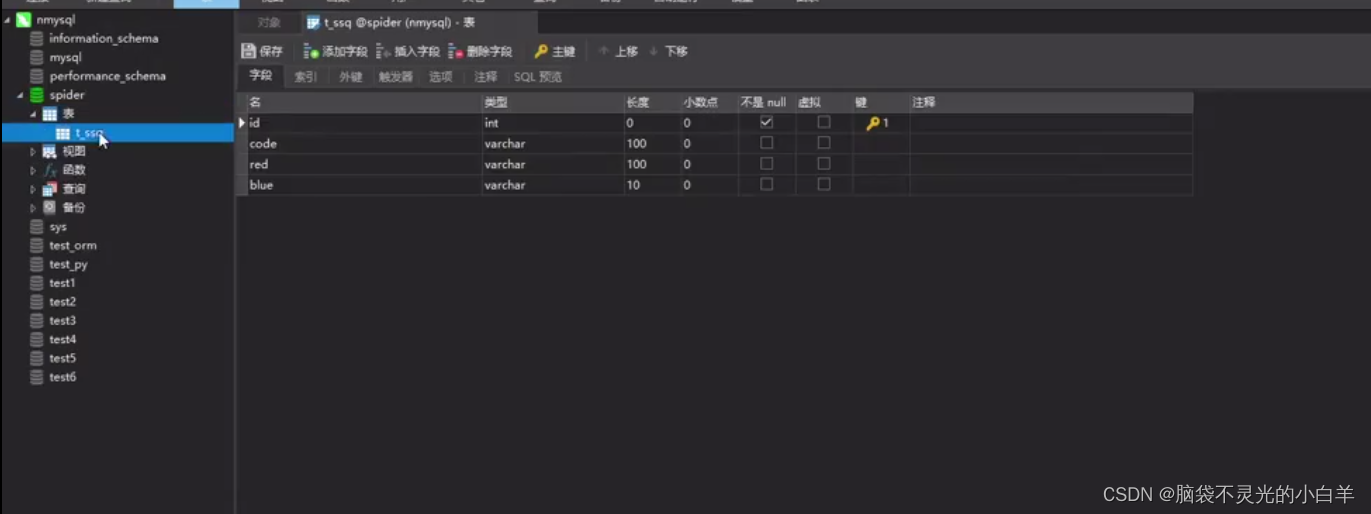
安装 pymysql
pip install pymysql
编写 Pipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from pymongo import MongoClient
import pymysql
class MysqlPipeline:
def open_spider(self, spider):
# 连接mysql
self.client = pymysql.connect(host='localhost',port=3306,user='root',passwd='123456',db='spider',charset='utf8')
self.cousor = self.client.cousor()
def process_item(self, item, spider):
# 插入数据
args = [
item.get('red'),
item.get('blue'),
item.get('code')
]
sql = 'insert into t_ssq values (0,%s,%s,%s)'
self.cousor.execute(sql,args)
self.client.commit()
return item
def close_spider(self, spider):
self.cousor.close()
self.client.close()
开启 Pipeline
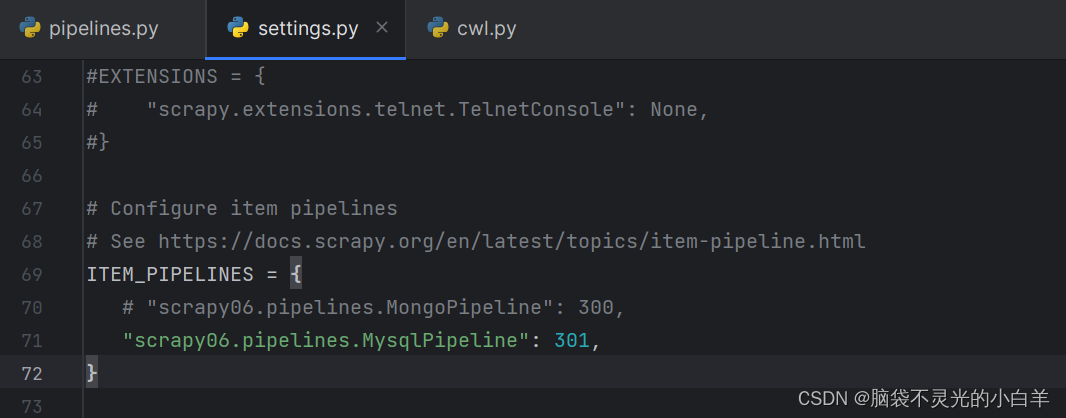
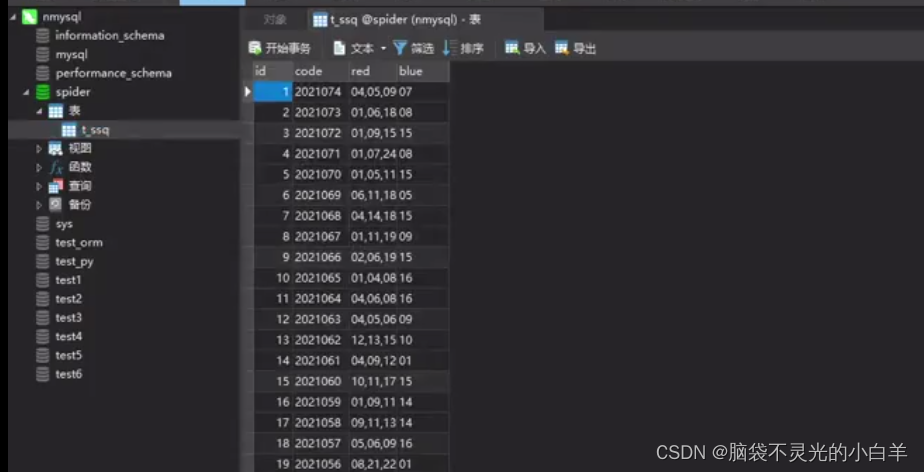
scrapy 多数据库保存处理
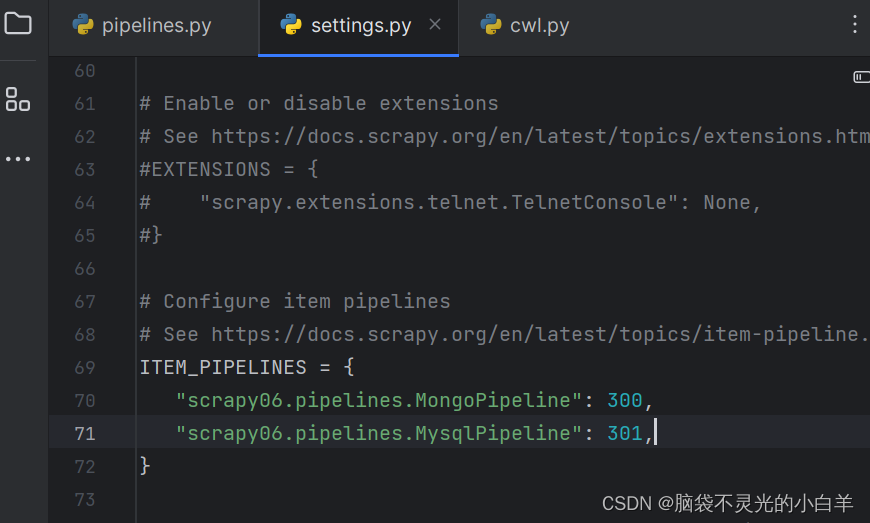
开启多个 Pipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from pymongo import MongoClient
import pymysql
from scrpay.exceptions import DropItem
'''
1、一个scrapy可以开启多个 Pipeline
1.1 一个 pipe保存一个网站的数据
可以通过 spider 来判断是否是当前网站的数据
1.2 一个pipe 保存一类数据
2、多个Pipeline开启,数据传递需要写 return item
3、当数据不想保存时,可以通过 DropItem 进行丢弃,丢弃后,后面的Pipeline也不会再处理,并且记录日志
'''
class MongoPipeline:
def open_spider(self, spider):
# 连接Mongo
self.client = MongoClient()
# 创建彩票实例
self.ssq = self.client.caipiao.ssq
def process_item(self, item, spider):
if item.get('code') == '2021074':
raise DropItem('这个数据已经存在!')
if spider.name == 'cwl':
return item
else:
# 插入数据
self.ssq.insert_one(item)
def close_spider(self, spider):
self.client.close()
class MysqlPipeline:
def open_spider(self, spider):
# 连接mysql
self.client = pymysql.connect(host='localhost',port=3306,user='root',passwd='123456',db='spider',charset='utf8')
self.cousor = self.client.cousor()
def process_item(self, item, spider):
# 插入数据
args = [
item.get('red'),
item.get('blue'),
item.get('code')
]
sql = 'insert into t_ssq values (0,%s,%s,%s)'
self.cousor.execute(sql,args)
self.client.commit()
return item
def close_spider(self, spider):
self.cousor.close()
self.client.close()















 60万+
60万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









