









1、关于锁的一些零碎知识,需要熟知
事务加锁方式:
两阶段锁:
整个事务分为两个阶段,前一个阶段加锁,后一个阶段为解锁。在加锁阶段,事务只能加锁,也可以操作数据,但是不能解锁,直到事务释放第一个锁,就进入了解锁阶段,此阶段事务只能解锁,也可以操作数据,不能再加锁。
两阶段协议使得事务具有比较高的并发度,因为解锁不必发生在事务结尾。
不过它没有解决死锁问题,因为它在加锁阶段没有顺序要求,如果两个事务分别申请了A,B锁,接着又申请对方的锁,此时进入死锁状态。
Innodb事务隔离
在MVCC并发控制中,读操作可以分为两类:快照读和当前读。
快照读读取的是记录的可见版本(有可能是历史版本),不用加锁。
当前读,读取的是记录的最新版本,并且当前读返回的记录都会加上锁,保证其他事务不再会并发修改这条记录。
- Read Uncommited:可以读未提交记录
- Read Committed(RC):当前读操作保证对独到的记录加锁,存在幻读现象。使用MVCC,但是读取数据时读取自身版本和最新版本,以最新为主,可以读已提交记录,存在不可重复
- Repeatable Read(RR):当前读操作保证对读到的记录加锁,同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入(间隙锁),不存在幻读现象。使用MVCC保存两个事务操作的数据互相隔离,不存在不可重复读现象。
- Serializable:MVCC并发控制退化为基于锁的并发控制。不区分快照读和当前读,所有读操作均为当前读,读加S锁,写加X锁。
MVCC多版本并发控制
MVCC是一种多版本并发控制机制。锁机制可以控制并发操作,但是其系统开销较大,而MVCC可以在大多数情况下替代行级锁,降低系统开销。
MVCC是通过保存数据在某个时间点的快照来实现的,典型的有乐观并发控制和悲观并发控制。
InnoDB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的,这两个列,分别保存这个行的创建时间和删除时间,这里存储的并不是实际的时间值,而是版本号,可以理解为事务的ID。每开始一个新的事务,这个版本号就会自动递增。
对于几种的操作:
- INSERT:为新插入的每一行保存当前版本号作为版本号
- UPDATE:新插入一行记录,并且保存其创建时间为当前事务ID,同时保存当前
- DELETE:为删除的每一行保存当前版本号作为版本号
- SELECT:
- InnoDB只会查找版本号小于等于事务系统版本号
- 行的删除版本要么未定义要么大于当前事务版本号,这样可以确保事务读取的行,在事务开始删除前未被删除
事实上,在读取满足上述两个条件的行时,InnoDB还会进行二次检查。
活跃事务列表:RC隔离级别下,在语句开始时从全局事务表中获取活跃(未提交)事务构造Read View,RR隔离级别下,事务开始时从全局事务表获取活跃事务构造Read View:
1、取当前行的修改事务ID,和Read View中的事务ID做比较,若小于最小的ID或小于最大ID但不在列表中,转2步骤。若是大于最大ID,转3
2、若进入此步骤,可说明,最后更新当前行的事务,在构造Read View时已经提交,返回当前行数据
3、若进入此步骤,可说明,最后更新当前行的事务,在构造Read View时还未创建或者还未提交,取undo log中记录的事务ID,重新进入步骤1.
根据上面策略,在读取数据的时候,InnoDB几乎不用获得任何锁,每个查询都能通过版本查询,只获得自己需要的数据版本,从而大大提高了系统并发度。
缺点是:每行记录都需要额外的存储空间,更多的行检查工作,额外的维护工作。
一般我们认为MVCC有几个特点:
- 每个数据都存在一个版本,每次数据更新时都更新该版本
- 修改时copy出当前版本修改,各个事务之间没有干扰
- 保存时比较版本号,如果成功,则覆盖原记录;失败则rollback
看上去保存是根据版本号决定是否成功,有点乐观锁意味,但是Innodb实现方式是:
- 事务以排他锁的形式修改原始数据
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功后啥都不做,失败则恢复undo log中的数据。
innodb没有实现MVCC核心的多版本共存,undo log内容只是串行化的结果,记录了多个事务的过程,不属于多版本共存。当事务影响到多行数据,理想的MVCC无能为力。
如:事务1执行理想MVCC,修改row1成功,修改row2失败,此时需要回滚row1,但是由于row1没有被锁定,其数据可能又被事务2修改,如果此时回滚row1内容,会破坏事务2的修改结果,导致事务2违反ACID。
理想的MVCC难以实现的根本原因在于企图通过乐观锁代替二阶段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统数据并无区别,而二阶段提交是目前这种场景保证一致性的唯一手段。二阶段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾。innodb只是借了MVCC名字,提供了读的非阻塞。
采用MVCC方式,读-写操作彼此并不冲突,性能更高;如果采用加锁方式,读-写操作彼此需要排队执行,从而影响性能。一般情况下,我们更愿意使用MVCC来解决读-写操作并发执行的问题,但是在一些特殊业务场景中,要求必须采用加锁的方式执行。
常用语句 与 锁的关系
对读取的记录加S锁:
select ... lock in share mode;
对读取的记录加X锁:
select ... for update;
delete:
对一条语句执行delete,先在B+树中定位到这条记录位置,然后获取这条记录的X锁,最后执行delete mark操作。
update:
- 如果未修改该记录键值并且被更新的列所占用的存储空间在修改前后未发生变化,则现在B+树定位到这条记录的位置,然后再获取记录的X锁,最后在原记录的位置进行修改操作。
- 如果为修改该记录的键值并且至少有一个被更新的列占用的存储空间在修改后发生变化,则先在B+树中定位到这条记录的位置,然后获取记录的X锁,然后将原记录删除,再重新插入一个新的记录。
- 如果修改了该记录的键值,则相当于在原记录上执行delete操作之后再来一次insert操作。
insert:
新插入的一条记录收到隐式锁保护,不需要在内存中为其生成对应的锁结构。
意向锁
为了允许行锁和表锁共存,实现多粒度锁机制。InnoDB还有两种内部使用的意向锁,两种意向锁都是表锁。
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁
意向排他锁(IX):事务打算给数据行加排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
意向锁仅仅用于表锁和行锁的共存使用。它们的提出仅仅是为了在之后加表级S锁或者X锁是可以快速判断表中的记录是否被上锁,以避免用遍历的方式来查看表中有没有上锁的记录。
需要注意的三点:
1、意向锁是表级锁,但是却表示事务正在读或写某一行记录
2、意向锁之间不会冲突,因为意向锁仅仅代表对某行记录进行操作,在加行锁的时候会判断是否冲突
3、意向锁是InnoDB自动加的,不需要用户干预。
行级锁
-
Record Lock:就是普通的行锁,官方名称:
LOCK_REC_NOT_GAP,用来锁住在聚集索引上的一条行记录 -
Gap Lock:用来在可重复读隔离级别下解决幻读现象。已知幻读还有一种方法解决:MVCC,还一种就是加锁。但是在使用加锁方案时有个问题,事务在第一次执行读取操作时,“幻影记录”还没有插入,所以我们无法给“幻影记录”加上Record Lock。InnoDB提出了Gap锁,官方名称:
LOCK_GAP,若一条记录的numberl列为8,前一行记录number列为3,我们在这个记录上加上gap锁,意味着不允许别的事务在number值为(3,8)区间插入记录。只有gap锁的事务提交后将gap锁释放掉后,其他事务才能继续插入。注意:gap锁只是用来防止插入幻影记录的,共享gap和独占gap起到作用相同。对一条记录加了gap锁不会限制其他事务对这条记录加Record Lock或者继续加gap锁。另外对于向限制记录后面的区间的话,可以使用Supremum表示该页面中最大记录。
-
Next-Key Lock:当我们既想锁住某条记录,又想阻止其他事务在该记录前面的间隙插入新记录,使用该锁。官方名称:
LOCK_ORDINARY,本质上就是上面两种锁的结合。 -
Insert Intention Lock:一个事务在插入一条你记录时需要判断该区间点上是否存在gap锁或Next-Key Lock,如果有的话,插入就需要阻塞。设计者规定,事务在等待时也需要在内存中生成一个锁结构,表明有个事务想在某个间隙中插入记录,但是处于等待状态。这种状态锁称为Insert Intention Lock,官方名称:
LOCK_INSERT_INTENTION,也可以称为插入意向锁。
2、锁的内存结构以及一些解释
一个事务对多条记录加锁时不一定就要创建多个锁结构。如果符合下面条件的记录的锁可以放到一个锁结构中:
- 在同一个事务中进行加锁操作
- 被加锁的记录在同一个页面中
- 加锁的类型是一样的
- 等待状态是一样的
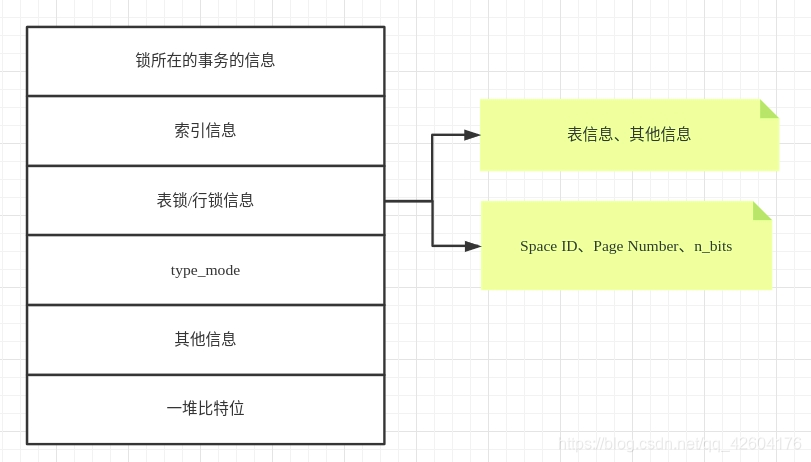
type_mode是一个32位比特的数,被分为lock_mode、lock_type、rec_lock_type三个部分。
低4位表示:lock_mode,锁的模式
0:表示IS锁
1:表示IX锁
2:表示S锁
3:表示X锁
4:表示AI锁,就是auto-inc,自增锁
第5~8位表示:lock_type,锁的类型
LOCK_TABLE:第5位为1,表示表级锁
LOCK_REC:第6位为1,表示行级锁
其余高位表示:rec_lock_type,表示行锁的具体类型,只有lock_type的值为LOCK_REC时,才会出现细分
LOCK_ORDINARY:为0,表示next-key锁
LOCK_GAP:为512,即当第10位设置为1时,表示gap锁
LOCK_REC_NOT_GAP:为1024,当第11位设置为1,表示正常记录锁
LOCK_INSERT_INTENTION:为2048,当第12位设置为1时,表示插入意向锁
LOCK_WAIT:为256,当第9位设置为1时,表示is_waiting为false,表明当前事务获取锁成功。
一堆比特位
其他信息:涉及了一些哈希表和链表
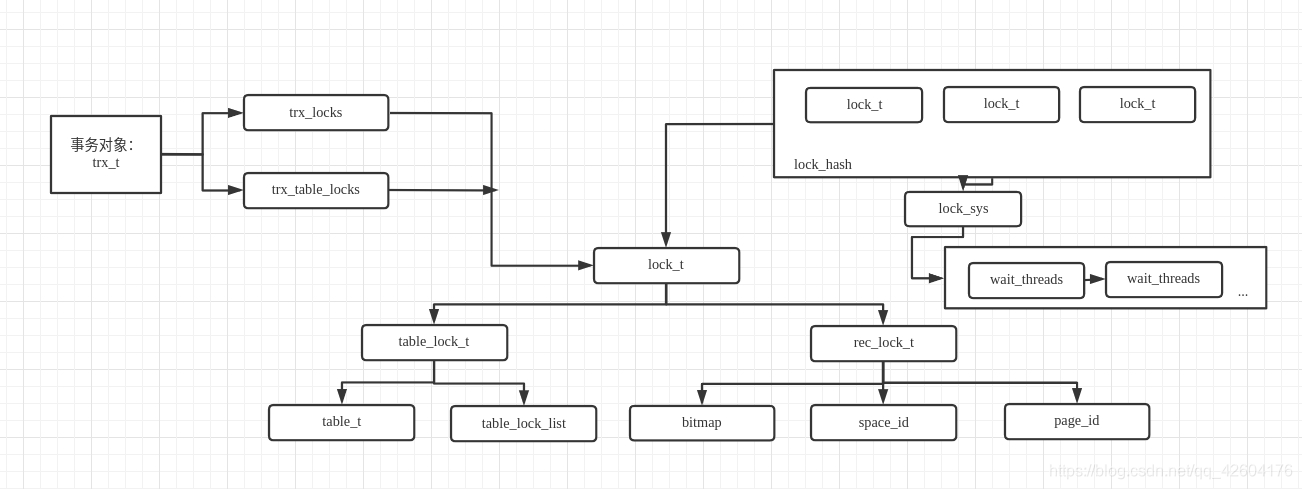
更加细节的结构可以看这一张图:
3、InnoDB的锁代码实现
锁系统结构lock_sys_t
详细讲解见:https://dev.mysql.com/doc/dev/mysql-server/latest/structlock__sys__t.html#details
锁系统结构,在innodb启动的时候初始化,在innodb结束时释放。保存锁的hash表,相关事务、线程的一些信息
/** The lock system struct */
struct lock_sys_t {
/** The latches protecting queues of record and table locks */
locksys::Latches latches;
/** The hash table of the record (LOCK_REC) locks, except for predicate
(LOCK_PREDICATE) and predicate page (LOCK_PRDT_PAGE) locks */
hash_table_t *rec_hash;
/** The hash table of predicate (LOCK_PREDICATE) locks */
hash_table_t *prdt_hash;
/** The hash table of the predicate page (LOCK_PRD_PAGE) locks */
hash_table_t *prdt_page_hash;
/** Padding to avoid false sharing of wait_mutex field */
char pad2[ut::INNODB_CACHE_LINE_SIZE];
/** The mutex protecting the next two fields */
Lock_mutex wait_mutex;
/** Array of user threads suspended while waiting for locks within InnoDB.
Protected by the lock_sys->wait_mutex. */
srv_slot_t *waiting_threads;
/** The highest slot ever used in the waiting_threads array.
Protected by lock_sys->wait_mutex. */
srv_slot_t *last_slot;
/** TRUE if rollback of all recovered transactions is complete.
Protected by exclusive global lock_sys latch. */
bool rollback_complete;
/** Max lock wait time observed, for innodb_row_lock_time_max reporting. */
ulint n_lock_max_wait_time;
/** Set to the event that is created in the lock wait monitor thread. A value
of 0 means the thread is not active */
os_event_t timeout_event;
#ifdef UNIV_DEBUG
/** Lock timestamp counter, used to assign lock->m_seq on creation. */
std::atomic<uint64_t> m_seq;
#endif /* UNIV_DEBUG */
};
lock_t 、lock_rec_t 、lock_table_t
无论是行锁还是表锁都使用lock_t结构保存,其中用一个union来分别保存行锁和表锁不同的数据,分别为lock_table_t和lock_rec_t
/** Lock struct; protected by lock_sys latches */
struct lock_t {
/** transaction owning the lock */
trx_t *trx;
/** list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/** Index for a record lock */
dict_index_t *index;
/** Hash chain node for a record lock. The link node in a singly
linked list, used by the hash table. */
lock_t *hash;
union {
/** Table lock */
lock_table_t tab_lock;
/** Record lock */
lock_rec_t rec_lock;
};
/** Record lock for a page */
struct lock_rec_t {
/** The id of the page on which records referenced by this lock's bitmap are
located. */
page_id_t page_id;
/** number of bits in the lock bitmap;
NOTE: the lock bitmap is placed immediately after the lock struct */
uint32_t n_bits;
/** Print the record lock into the given output stream
@param[in,out] out the output stream
@return the given output stream. */
std::ostream &print(std::ostream &out) const;
};
struct lock_table_t {
dict_table_t *table; /*!< database table in dictionary
cache */
UT_LIST_NODE_T(lock_t)
locks; /*!< list of locks on the same
table */
/** Print the table lock into the given output stream
@param[in,out] out the output stream
@return the given output stream. */
std::ostream &print(std::ostream &out) const;
};
bitmap
Innodb 使用位图来表示锁具体锁住了那几行,在函数 lock_rec_create 中为 lock_t 分配内存空间的时候,会在对象地址后分配一段内存空间(当前行数 + 64)用来保存位图。n_bits 表示位图大小。
锁的基本模式的兼容关系和强弱关系
/* LOCK COMPATIBILITY MATRIX
* IS IX S X AI
* IS + + + - +
* IX + + - - +
* S + - + - -
* X - - - - -
* AI + + - - -
*
* Note that for rows, InnoDB only acquires S or X locks.
* For tables, InnoDB normally acquires IS or IX locks.
* S or X table locks are only acquired for LOCK TABLES.
* Auto-increment (AI) locks are needed because of
* statement-level MySQL binlog.
* See also lock_mode_compatible().
*/
static const byte lock_compatibility_matrix[5][5] = {
/** IS IX S X AI */
/* IS */ { TRUE, TRUE, TRUE, FALSE, TRUE},
/* IX */ { TRUE, TRUE, FALSE, FALSE, TRUE},
/* S */ { TRUE, FALSE, TRUE, FALSE, FALSE},
/* X */ { FALSE, FALSE, FALSE, FALSE, FALSE},
/* AI */ { TRUE, TRUE, FALSE, FALSE, FALSE}type_mode
};
/* STRONGER-OR-EQUAL RELATION (mode1=row, mode2=column)
* IS IX S X AI
* IS + - - - -
* IX + + - - -
* S + - + - -
* X + + + + +
* AI - - - - +
* See lock_mode_stronger_or_eq().
*/
static const byte lock_strength_matrix[5][5] = {
/** IS IX S X AI */
/* IS */ { TRUE, FALSE, FALSE, FALSE, FALSE},
/* IX */ { TRUE, TRUE, FALSE, FALSE, FALSE},
/* S */ { TRUE, FALSE, TRUE, FALSE, FALSE},
/* X */ { TRUE, TRUE, TRUE, TRUE, TRUE},
/* AI */ { FALSE, FALSE, FALSE, FALSE, TRUE}
};
行锁类别代码
#define LOCK_WAIT \
256 /*!< Waiting lock flag; when set, it \
means that the lock has not yet been \
granted, it is just waiting for its \
turn in the wait queue */
/* Precise modes */
#define LOCK_ORDINARY \
0 /*!< this flag denotes an ordinary \
next-key lock in contrast to LOCK_GAP \
or LOCK_REC_NOT_GAP */
#define LOCK_GAP \
512 /*!< when this bit is set, it means that the \
lock holds only on the gap before the record; \
for instance, an x-lock on the gap does not \
give permission to modify the record on which \
the bit is set; locks of this type are created \
when records are removed from the index chain \
of records */
#define LOCK_REC_NOT_GAP \
1024 /*!< this bit means that the lock is only on \
the index record and does NOT block inserts \
to the gap before the index record; this is \
used in the case when we retrieve a record \
with a unique key, and is also used in \
locking plain SELECTs (not part of UPDATE \
or DELETE) when the user has set the READ \
COMMITTED isolation level */
#define LOCK_INSERT_INTENTION \
2048 /*!< this bit is set when we place a waiting \
gap type record lock request in order to let \
an insert of an index record to wait until \
there are no conflicting locks by other \
transactions on the gap; note that this flag \
remains set when the waiting lock is granted, \
or if the lock is inherited to a neighboring \
record */
#define LOCK_PREDICATE 8192 /*!< Predicate lock */
#define LOCK_PRDT_PAGE 16384 /*!< Page lock */
记录锁的alloc函数
Create the lock instance,创建一个lock实例,在create函数中被调用。主要就是分配一些内存,还有设置事务请求记录锁、锁的索引号、锁的模式、行锁的pageid、n_bits。
/**
Create the lock instance
@param[in, out] trx The transaction requesting the lock
@param[in, out] index Index on which record lock is required
@param[in] mode The lock mode desired
@param[in] rec_id The record id
@param[in] size Size of the lock + bitmap requested
@return a record lock instance */
lock_t *RecLock::lock_alloc(trx_t *trx, dict_index_t *index, ulint mode,
const RecID &rec_id, ulint size) {
ut_ad(locksys::owns_page_shard(rec_id.get_page_id()));
/* We are about to modify structures in trx->lock which needs trx->mutex */
ut_ad(trx_mutex_own(trx));
lock_t *lock;
if (trx->lock.rec_cached >= trx->lock.rec_pool.size() ||
sizeof(*lock) + size > REC_LOCK_SIZE) {
ulint n_bytes = size + sizeof(*lock);
mem_heap_t *heap = trx->lock.lock_heap;
lock = reinterpret_cast<lock_t *>(mem_heap_alloc(heap, n_bytes));
} else {
lock = trx->lock.rec_pool[trx->lock.rec_cached];
++trx->lock.rec_cached;
}
lock->trx = trx;
lock->index = index;
/* Note the creation timestamp */
ut_d(lock->m_seq = lock_sys->m_seq.fetch_add(1));
/* Setup the lock attributes */
lock->type_mode = LOCK_REC | (mode & ~LOCK_TYPE_MASK);
lock_rec_t &rec_lock = lock->rec_lock;
/* Predicate lock always on INFIMUM (0) */
if (is_predicate_lock(mode)) {
rec_lock.n_bits = 8;
memset(&lock[1], 0x0, 1);
} else {
ut_ad(8 * size < UINT32_MAX);
rec_lock.n_bits = static_cast<uint32_t>(8 * size);
memset(&lock[1], 0x0, size);
}
rec_lock.page_id = rec_id.get_page_id();
/* Set the bit corresponding to rec */
lock_rec_set_nth_bit(lock, rec_id.m_heap_no);
MONITOR_INC(MONITOR_NUM_RECLOCK);
MONITOR_INC(MONITOR_RECLOCK_CREATED);
return (lock);
}
记录锁的add函数
将锁添加到记录锁哈希和事务的锁列表中。
void RecLock::lock_add(lock_t *lock) {
ut_ad((lock->type_mode | LOCK_REC) == (m_mode | LOCK_REC));
ut_ad(m_rec_id.matches(lock));
ut_ad(locksys::owns_page_shard(m_rec_id.get_page_id()));
ut_ad(locksys::owns_page_shard(lock->rec_lock.page_id));
ut_ad(trx_mutex_own(lock->trx));
bool wait = m_mode & LOCK_WAIT;
hash_table_t *lock_hash = lock_hash_get(m_mode);
lock->index->table->n_rec_locks.fetch_add(1, std::memory_order_relaxed);
if (!wait) {
lock_rec_insert_to_granted(lock_hash, lock, m_rec_id);
} else {
lock_rec_insert_to_waiting(lock_hash, lock, m_rec_id);
}
#ifdef HAVE_PSI_THREAD_INTERFACE
#ifdef HAVE_PSI_DATA_LOCK_INTERFACE
/* The performance schema THREAD_ID and EVENT_ID are used only
when DATA_LOCKS are exposed. */
PSI_THREAD_CALL(get_current_thread_event_id)
(&lock->m_psi_internal_thread_id, &lock->m_psi_event_id);
#endif /* HAVE_PSI_DATA_LOCK_INTERFACE */
#endif /* HAVE_PSI_THREAD_INTERFACE */
locksys::add_to_trx_locks(lock);
if (wait) {
lock_set_lock_and_trx_wait(lock);
}
}
记录锁的create函数
就是调用alloc,然后add加锁,
Create a lock for a transaction and initialise it.
@param[in, out] trx Transaction requesting the new lock
@param[in] prdt Predicate lock (optional)
@return new lock instance */
lock_t *RecLock::create(trx_t *trx, const lock_prdt_t *prdt) {
ut_ad(locksys::owns_page_shard(m_rec_id.get_page_id()));
/* Ensure that another transaction doesn't access the trx
lock state and lock data structures while we are adding the
lock and changing the transaction state to LOCK_WAIT.
In particular it protects the lock_alloc which uses trx's private pool of
lock structures.
It might be the case that we already hold trx->mutex because we got here from:
- lock_rec_convert_impl_to_expl_for_trx
- add_to_waitq
*/
ut_ad(trx_mutex_own(trx));
/* Create the explicit lock instance and initialise it. */
lock_t *lock = lock_alloc(trx, m_index, m_mode, m_rec_id, m_size);
#ifdef UNIV_DEBUG
/* GAP lock shouldn't be taken on DD tables with some exceptions */
if (m_index->table->is_dd_table &&
strstr(m_index->table->name.m_name,
"mysql/st_spatial_reference_systems") == nullptr &&
strstr(m_index->table->name.m_name, "mysql/innodb_table_stats") ==
nullptr &&
strstr(m_index->table->name.m_name, "mysql/innodb_index_stats") ==
nullptr &&
strstr(m_index->table->name.m_name, "mysql/table_stats") == nullptr &&
strstr(m_index->table->name.m_name, "mysql/index_stats") == nullptr) {
ut_ad(lock_rec_get_rec_not_gap(lock));
}
#endif /* UNIV_DEBUG */
if (prdt != nullptr && (m_mode & LOCK_PREDICATE)) {
lock_prdt_set_prdt(lock, prdt);
}
lock_add(lock);
return (lock);
}
4、锁的流程
lock system 开始启动 申请lock_sys_t结构,初始化结构体
lock system 结束关闭 释放lock_sys_t结构的元素,释放结构体
表锁加锁流程
1、检查当前事务是否拥有更强的表锁,如果有的话直接返回成功,否则继续往下走
2、遍历表的锁列表,判断是否有冲突的锁,没有转3,有转4
3、直接创建一个表锁,放入事务的lock list中,放入table 的lock list中,加锁成功
4、创建等待的表锁,然后进行死锁检测和死锁解决,回滚当前事务或者挂起当前事务
行锁加锁流程
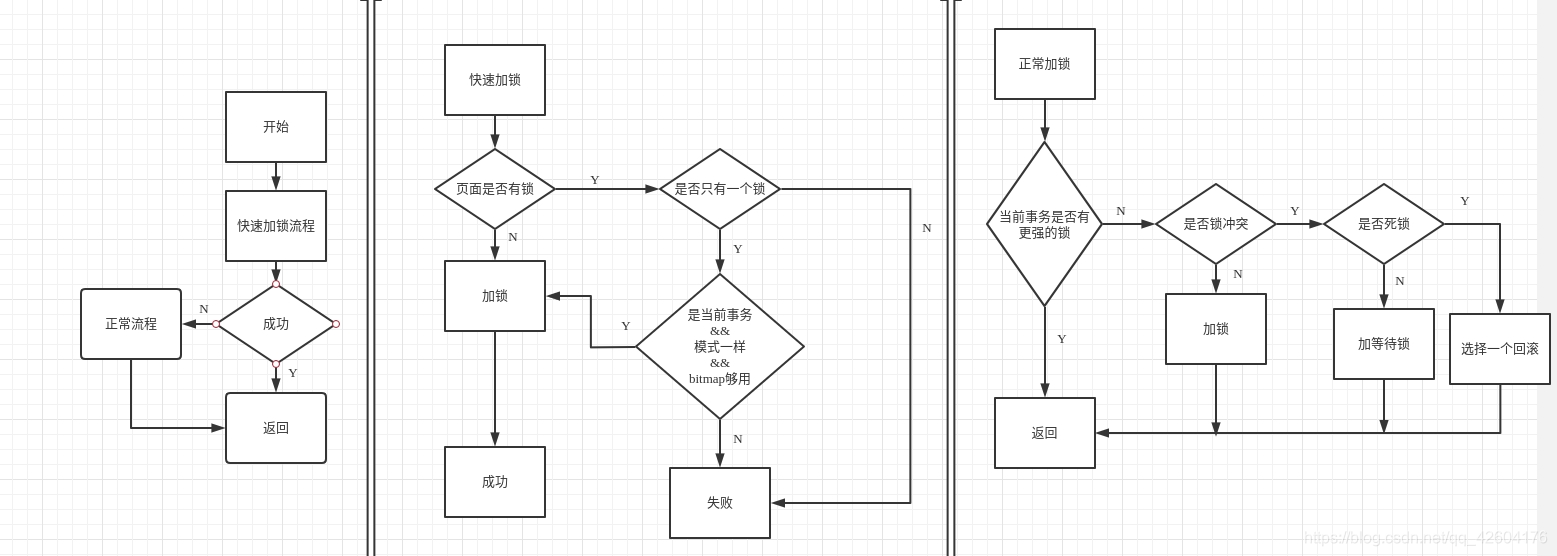
插入加锁流程
1、对表加IX锁
2、对修改的页面加X锁
3、如果需要检测唯一键冲突,尝试给需要加的唯一键加一个S | next-key lock。可能会产生锁等待
4、判断是否插入意向锁冲突,冲突的话加等待的插入意向锁,不冲突直接插入数据
5、释放页面锁
删除加锁流程带来的死锁
删除加锁有个问题,删除并发的时候的加锁会导致死锁。
1、事务1获取表IX锁
2、事务1获取页面X锁
3、事务1获取第n行的 x | not gap锁
4、事务1删除第n行
5、事务1释放页面X锁
6、事务2获取页面X锁
7、事务2尝试获取第n行的 x | not gap锁,发现冲突,等待
8、事务2释放页面X锁
9、事务1释放第n行的锁,提交事务
10、释放第n行锁的时候,检查到事务2有一个等待锁,发现可以加锁了,唤醒事务2,成功加锁
11、事务3获取页面X锁
12、事务3尝试删除第n行,发现第n行已经被删除,尝试获取第n行的next-key lock,发现事务2有个 x| gap锁冲突,等待
13、事务3释放页面X锁
14、事务2获取页面X锁,检查页面是否改动,重新检查第n行数据,发现被删,尝试获取该行next- key lock,发现事务3在等待这个锁,事务2冲突,进入等待
15、造成死锁
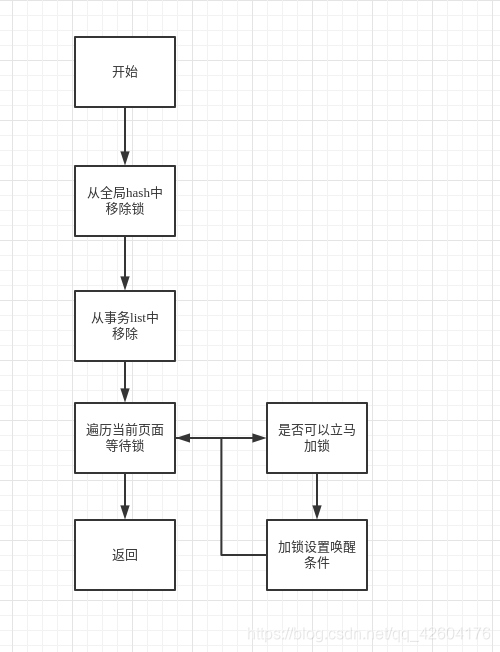
释放锁流程
死锁流程
构造wait-for graph
构造一个有向图,图中的节点代表一个事务,图的一个边A->B代表着A事务等待B事务的一个锁
具体实现是在死锁检测时,从当前锁的事务开始搜索,遍历当前行的所有锁,判断当前事务是否需要等待现有锁释放,是的话,代表有一条边,进行一次入栈操作
死锁检测
有向图判断环,用栈的方式,如果有依赖等待,进行入栈,如果当前事务所有依赖的事务遍历完毕,进行一次出栈
回滚事务选择
如果发现循环等待,选择当前事务和等待的事务其中权重小的一个回滚,具体的权重比较函数是 trx_weight_ge, 如果一个事务修改了不支持事务的表,那么认为它的权重较高,否则认为 undo log 数加持有的锁数之和较大的权重较高。
5、参考
1、https://segmentfault.com/a/1190000017076101?utm_source=coffeephp.com
2、Mysql 8.022源代码
3、深入浅出MySQL 8.0 lock_sys锁相关优化


















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











