






背景:最近一段时间对彩票感兴趣,选择福彩3D试试运气,因为只有1000种组合,感觉要容易些。也在网上看了大量的帖子,各种各样的方法都有,比较热的有LSTM、随机森林。
开干:第一阶段使用LSTM预测的,没啥效果,放弃。第二阶段再加了注意力机制,依然没啥效果,放弃。第三阶段,换成随机森林,效果稍微好一点。先说结论,两次训练,共458个样本,最高收益分别是80%+,18%+,看结果就知道是运气成分了,图个乐子。
过程:爬取了全部的福彩3d历史数据,想了一些乱七八糟的特征,不管有没有用先写上:
# 4. 基础特征(无未来数据)=============================================
def map_to_zone(value):
zones = [(0,124),(125,249),(250,374),(375,499),
(500,624),(625,749),(750,874),(875,999)]
for zone_id, (low, high) in enumerate(zones):
if low <= value <= high: return zone_id
return 8
df['区间'] = df['开奖号码'].apply(map_to_zone)
# 位数特征
df['百位'] = df['开奖号码'] // 100
df['十位'] = (df['开奖号码'] // 10) % 10
df['个位'] = df['开奖号码'] % 10
# 基本统计特征
df['和值'] = df['百位'] + df['十位'] + df['个位']
df['跨度'] = df[['百位','十位','个位']].max(axis=1) - df[['百位','十位','个位']].min(axis=1)
#计算历史平均值特征
columns_to_calculate = ['百位', '十位', '个位', '和值', '区间', '开奖号码']
for col in columns_to_calculate:
# 计算从第一期到当前期的累积平均值(含当前期)
df[f'{col}_历史平均'] = df[col].expanding().mean()
# 计算多窗口移动平均特征
# 定义所有需要的窗口大小
window_sizes12 = [3, 5, 7, 10, 20, 30, 60, 90, 120, 150, 180]
for window_size in window_sizes12:
for col in columns_to_calculate:
# 计算移动平均值,min_periods=1 表示即使数据不足窗口大小也会计算
df[f'{col}_移动平均_{window_size}期'] = df[col].rolling(
window=window_size,
min_periods=1
).mean()
# 奇偶特征
for pos in ['百位','十位','个位']:
df[f'{pos}奇偶'] = df[pos] % 2
df['奇偶比'] = df['百位奇偶'] + df['十位奇偶'] + df['个位奇偶']
# 大小特征
for pos in ['百位','十位','个位']:
df[f'{pos}大小'] = (df[pos] >= 5).astype(int)
df['大小比'] = df['百位大小'] + df['十位大小'] + df['个位大小']
# 质合特征
for pos in ['百位','十位','个位']:
df[f'{pos}质合'] = df[pos].apply(lambda x: int(isprime(x)))
df['质合比'] = df['百位质合'] + df['十位质合'] + df['个位质合']
# 差值特征
df['百十差'] = df['百位'] - df['十位']
df['十个差'] = df['十位'] - df['个位']
df['首尾差'] = df['百位'] - df['个位']
# 组合特征
df['百十和'] = df['百位'] + df['十位']
df['百十积'] = df['百位'] * df['十位']
df['十个和'] = df['十位'] + df['个位']
df['十个积'] = df['十位'] * df['个位']
df['百个和'] = df['百位'] + df['个位']
df['百个积'] = df['百位'] * df['个位']
df['百十商'] = df['百位'] / (df['十位'] + 1e-6) # 防止除以零
df['十个商'] = df['十位'] / (df['个位'] + 1e-6)
df['百个商'] = df['百位'] / (df['个位'] + 1e-6)
# 提取前一期号码及其位数,计算与当前期的差值
df['前期号码'] = df['开奖号码'].shift(1)
df['前期百位'] = df['百位'].shift(1)
df['前期十位'] = df['十位'].shift(1)
df['前期个位'] = df['个位'].shift(1)
# 当前期与前一期号码的差值
df['号码差'] = df['开奖号码'] - df['前期号码']
df['百位差'] = df['百位'] - df['前期百位']
df['十位差'] = df['十位'] - df['前期十位']
df['个位差'] = df['个位'] - df['前期个位']
#提取重复号码特征(与前一期比较)
df['重复号码标记'] = (df['开奖号码'] == df['前期号码']).astype(int)
# 时间特征
df['星期几'] = df['日期'].dt.dayofweek
df['星期几_sin'] = np.sin(2 * np.pi * df['星期几'] / 7)
df['星期几_cos'] = np.cos(2 * np.pi * df['星期几'] / 7)
# ---- 新增数字特征 ----
df['数字均值'] = df[['百位', '十位', '个位']].mean(axis=1)
df['数字方差'] = df[['百位', '十位', '个位']].var(axis=1)
df['数字标准差'] = df[['百位', '十位', '个位']].std(axis=1)
df['数字偏度'] = df[['百位', '十位', '个位']].apply(lambda x: skew(x) if x.nunique() > 1 else 0, axis=1)
df['数字峰度'] = df[['百位', '十位', '个位']].apply(lambda x: kurtosis(x) if x.nunique() > 1 else 0, axis=1)
df['数字平方和'] = df['百位']**2 + df['十位']**2 + df['个位']**2
df['数字立方和'] = df['百位']**3 + df['十位']**3 + df['个位']**3
# 号码特征
df['号码'] = df['百位']*100 + df['十位']*10 + df['个位']
# 号码大小分类
def classify_number(num):
if num <= 333:
return 0 # 小号
elif num <= 666:
return 1 # 中号
else:
return 2 # 大号
df['号码大小分类'] = df['号码'].apply(classify_number)
# 号码奇偶性
df['号码奇偶'] = df['号码'] % 2
# 号码是否质数
df['号码是否质数'] = df['号码'].apply(lambda x: int(isprime(x)))
# 号码是否为特定数的倍数
df['号码是否3的倍数'] = (df['号码'] % 3 == 0).astype(int)
df['号码是否5的倍数'] = (df['号码'] % 5 == 0).astype(int)
df['号码是否7的倍数'] = (df['号码'] % 7 == 0).astype(int)
# 数字和、数字积
df['数字和'] = df['号码'].apply(lambda x: sum(int(digit) for digit in str(int(x))))
df['数字积'] = df['百位'] * df['十位'] * df['个位']
# 约数个数
def count_divisors(n):
n = int(n)
count = 0
for i in range(1, int(n ** 0.5) + 1):
if n % i == 0:
if i == n // i:
count += 1
else:
count += 2
return count
df['约数个数'] = df['号码'].apply(count_divisors)
# 质因数个数
df['质因数个数'] = df['号码'].apply(lambda x: len(factorint(int(x))))
# 号码哈希编码
df['号码哈希编码'] = df['号码'] % 1000
# 二进制1的个数
df['二进制1的个数'] = df['号码'].apply(lambda x: bin(int(x)).count('1'))
# 周期余数
df['周期余数_7'] = df['号码'] % 7
df['周期余数_13'] = df['号码'] % 13
# 是否顺子
def is_straight(row):
digits = sorted([row['百位'], row['十位'], row['个位']])
return int((digits[1] - digits[0] == 1) and (digits[2] - digits[1] == 1))
df['是否顺子'] = df.apply(is_straight, axis=1)
# ---- 互信息特征 ----
# 定义一个函数来计算滑动窗口内的互信息
def calculate_mutual_info(window, col1, col2):
return mutual_info_score(window[col1], window[col2])
# 使用滑动窗口计算互信息
df['百十互信息'] = df['百位'].rolling(window=30).apply(lambda x: calculate_mutual_info(df.loc[x.index], '百位', '十位'), raw=False)
df['十个互信息'] = df['十位'].rolling(window=30).apply(lambda x: calculate_mutual_info(df.loc[x.index], '十位', '个位'), raw=False)
df['百个互信息'] = df['百位'].rolling(window=30).apply(lambda x: calculate_mutual_info(df.loc[x.index], '百位', '个位'), raw=False)
# ---- 进制转换特征 ----
# 二进制转换,计算二进制数字和(转为整数)
df['号码_二进制'] = df['号码'].apply(lambda x: int(bin(int(x))[2:], 2))
df['二进制数字和'] = df['号码_二进制'].apply(lambda x: bin(x).count('1'))
# 八进制转换,计算八进制数字和(转为整数)
df['号码_八进制'] = df['号码'].apply(lambda x: int(oct(int(x))[2:], 8))
df['八进制数字和'] = df['号码_八进制'].apply(lambda x: sum(int(digit) for digit in str(x)))
# 十六进制转换,计算十六进制数字和(转为整数)
df['号码_十六进制'] = df['号码'].apply(lambda x: int(hex(int(x))[2:], 16))
df['十六进制数字和'] = df['号码_十六进制'].apply(lambda x: sum(int(digit, 16) for digit in str(hex(x))[2:]))
df.fillna(1, inplace=True)
# 质数余数特征
prime_numbers = [x for x in range(3,31) if isprime(x)]
for prime in prime_numbers:
df[f'号码_mod_{prime}'] = df['号码'] % prime
# 三角函数特征:对百位、十位、个位、号码进行 sin、cos、tanh 变换
positions = ['百位', '十位', '个位', '号码']
transforms = ['sin', 'cos', 'tanh']
for pos in positions:
for func in transforms:
if func == 'sin':
df[f'{pos}_{func}'] = np.sin(df[pos])
elif func == 'cos':
df[f'{pos}_{func}'] = np.cos(df[pos])
elif func == 'tanh':
df[f'{pos}_{func}'] = np.tanh(df[pos])
# 熵特征
def calc_entropy(row):
digits = [row['百位'], row['十位'], row['个位']]
return entropy(pd.Series(digits).value_counts(), base=2)
df['数字熵'] = df.apply(calc_entropy, axis=1)
然后又添加了一个比较实用的特征工程,在线的STL时序分解,这里最最重要的是不能混入未来数据。
# 5. 时间敏感特征(防泄露处理)=======================================
# ============== 时间敏感特征(统一30期窗口) ==============
window_size = 30 # 统一窗口大小
lag_period = 1 # 特征滞后期数
# 安全移动统计量(30期窗口)
# 严格滞后处理移动统计量
df['号码_移动平均_30'] = df['号码'].shift(lag_period + 1).rolling(
window=window_size, min_periods=1, closed='left'
).mean()
df['号码_移动方差_30'] = df['号码'].shift(lag_period + 1).rolling(
window=window_size, min_periods=1, closed='left'
).var()
# #===OnlineSTL===#模块开始
class OnlineSTL:
def __init__(self, period=7, window_size=60):
self.period = period
self.window_size = window_size
self.trend_buffer = deque(maxlen=window_size)
self.seasonal_coeffs = np.zeros(period)
self.residual_mean = 0
def update(self, new_value, current_index):
# 趋势计算(仅使用历史窗口数据)
if len(self.trend_buffer) < 2:
current_trend = {'level': new_value, 'trend': 0}
else:
# 使用窗口数据进行双指数平滑
alpha = 0.2
beta = 0.1
window_data = list(self.trend_buffer)[-self.window_size:]
last_level = window_data[-1]['level']
last_trend = window_data[-1]['trend']
current_level = alpha*new_value + (1-alpha)*(last_level + last_trend)
current_trend_val = beta*(current_level - last_level) + (1-beta)*last_trend
current_trend = {'level': current_level, 'trend': current_trend_val}
# 季节性更新(滞后窗口计算)
pos = (current_index - 1) % self.period # 使用上期位置
if current_index > self.period:
gamma = 0.15
historical_seasonal = self.seasonal_coeffs[pos]
deseason_value = new_value - historical_seasonal
self.seasonal_coeffs[pos] = historical_seasonal + gamma * deseason_value
# 残差填充机制
residual = new_value - (current_trend['level'] + self.seasonal_coeffs[pos])
if current_index < self.window_size:
residual = self.residual_mean # 使用历史残差均值填充
else:
self.residual_mean = np.mean([x['residual'] for x in self.trend_buffer])
self.trend_buffer.append({
'level': current_trend['level'],
'trend': current_trend.get('trend', 0),
'seasonal': self.seasonal_coeffs[pos],
'residual': residual
})
return current_trend['level'], self.seasonal_coeffs[pos], residual
# 使用时传入当前索引
ostl = OnlineSTL(period=7, window_size=60)
trends, seasonals, residuals = [], [], []
for idx, num in enumerate(df['号码']):
trend, seasonal, residual = ostl.update(num, idx)
trends.append(trend)
seasonals.append(seasonal)
residuals.append(residual)
# 带时序校验的特征赋值
for i in range(len(df)):
if i < len(trends):
df.at[i, '号码_趋势Online'] = trends[i]
df.at[i, '号码_季节性Online'] = seasonals[i]
# 残差计算使用滞后窗口
residual_window = residuals[max(0, i-window_size):i]
df.at[i, '号码_残差Online'] = residual_window[-1] if residual_window else 0
ostl2 = OnlineSTL(period=7, window_size=60)
trends2, seasonals2, residuals2 = [], [], []
for idx, num in enumerate(df['百位']):
trend2, seasonal2, residual2 = ostl2.update(num, idx)
trends2.append(trend2)
seasonals2.append(seasonal2)
residuals2.append(residual2)
# 带时序校验的特征赋值
for i in range(len(df)):
if i < len(trends2):
df.at[i, '百位_趋势Online'] = trends2[i]
df.at[i, '百位_季节性Online'] = seasonals2[i]
# 残差计算使用滞后窗口
residual_window = residuals2[max(0, i-window_size):i]
df.at[i, '百位_残差Online'] = residual_window[-1] if residual_window else 0
#===OnlineSTL===#模块结束然后就开始训练,做好训练集和测试集分割,不能引入未来数据。我是按照一个月的跨度测试,选择180期为窗口长度,输出下一期预测值。测试集和训练集完全分开。比如我要测试2023.12的30期数据,测试集的开始日期是2023.5.31,这个就和2023.12.01中间差了180期,完全不会有未来数据。
# === 严格时序分割 ===
# 定义分割时间点
train_end = pd.Timestamp('2023-05-30')
test_start = pd.Timestamp('2023-05-31')
# 创建布尔掩码
train_mask = df['日期'] <= train_end
test_mask = df['日期'] >= test_start
# 深拷贝生成数据集
df_train = df.loc[train_mask].copy()
df_test = df.loc[test_mask].copy()
# === 保留原始变量结构 ===
# 提取特征矩阵(保持numbers变量)
numbers_train = df_train[features].values
numbers_test = df_test[features].values
# 保留日期和期号信息
dates_train = df_train['日期'].values
dates_test = df_test['日期'].values
periods_train = df_train['期号'].values
periods_test = df_test['期号'].values
# 目标变量(保持targets变量)
targets_train = df_train[['百位', '十位', '个位', '区间']].values
targets_test = df_test[['百位', '十位', '个位', '区间']].values
# === 安全序列生成 ===
def create_isolated_sequences(data, labels, seq_length, pred_length):
"""生成隔离时序窗口"""
X, Y = [], []
for i in range(len(data) - seq_length - pred_length + 1):
X.append(data[i:i+seq_length])
Y.append(labels[i+seq_length:i+seq_length+pred_length])
return np.array(X), np.array(Y)
# 参数设置
SEQ_LENGTH = 180
PREDICT_LENGTH = 1
# 独立生成序列(保持X_all/Y_all结构但实际隔离)
X_train_all, Y_train_all = create_isolated_sequences(numbers_train, targets_train, SEQ_LENGTH, PREDICT_LENGTH)
X_test_all, Y_test_all = create_isolated_sequences(numbers_test, targets_test, SEQ_LENGTH, PREDICT_LENGTH)
# === 合并变量(仅用于后续非训练用途)===
# 注意:此处的合并仅用于保持原始变量结构,实际训练不应使用
X_all = np.concatenate([X_train_all, X_test_all], axis=0)
Y_all = np.concatenate([Y_train_all, Y_test_all], axis=0)
seq_indices = np.arange(len(X_all)) # 生成模拟索引
# === 时间索引对齐 ===
# 保持seq_dates变量(实际应分开)
def get_seq_dates(source_dates, seq_length, pred_length):
"""获取序列对应的结束日期"""
dates = []
for i in range(len(source_dates) - seq_length - pred_length + 1):
dates.append(source_dates[i + seq_length + pred_length - 1])
return np.array(dates)
seq_dates_train = get_seq_dates(dates_train, SEQ_LENGTH, PREDICT_LENGTH)
seq_dates_test = get_seq_dates(dates_test, SEQ_LENGTH, PREDICT_LENGTH)
seq_dates = np.concatenate([seq_dates_train, seq_dates_test])
# === 数据格式化(保持原有变量名)===
# 训练集处理
X_train = X_train_all
Y_train = Y_train_all.astype(int)
train_indices = np.where(seq_dates < np.datetime64('2023-05-30'))[0]
# 测试集处理
X_test = X_test_all
Y_test = Y_test_all.astype(int)
test_indices = np.where(seq_dates >= np.datetime64('2023-05-31'))[0]
# === 异常值处理(保持原有逻辑)===
# 注意:实际应分开处理,此处为兼容原有代码
X_all_processed = np.nan_to_num(X_all, nan=0, posinf=0, neginf=0)
Y_all_processed = np.nan_to_num(Y_all, nan=0, posinf=0, neginf=0).astype(int)
# === 数据重塑(保持原有变量)===
X_train_flat = X_train.reshape(X_train.shape[0], -1)
X_test_flat = X_test.reshape(X_test.shape[0], -1)
# === 验证数据隔离 ===
print("[隔离验证] 训练集最后日期:", seq_dates_train[-1])
print("[隔离验证] 测试集最早日期:", seq_dates_test[0])
print("[维度检查] X_train_flat:", X_train_flat.shape, "X_test_flat:", X_test_flat.shape)这边训练之前先做一个特征重要性筛选,然后分别训练测试,预测个位、十位、百位、区间。
# ------------------------- 特征重要性功能 -------------------------
def select_features(X_train, X_test, feature_importances, features, threshold=0.00005):
"""基于特征重要性筛选特征(带自动修正功能)"""
# 处理长度不一致问题
min_length = min(len(features), len(feature_importances))
if len(features) != len(feature_importances):
print(f"⚠️ 特征数量不匹配,进行自动截断 (特征名:{len(features)}, 重要性值:{len(feature_importances)})")
features = features[:min_length]
feature_importances = feature_importances[:min_length]
# 创建重要性DF
importance_df = pd.DataFrame({
'feature': features,
'importance': feature_importances
}).sort_values('importance', ascending=False)
# === 新增诊断信息 ===
print("\n=== 特征重要性诊断 ===")
print(f"总特征数: {len(importance_df)}")
print(f"最大重要性: {importance_df['importance'].max():.4f}")
print(f"平均重要性: {importance_df['importance'].mean():.4f}")
print("重要性分位数:")
print(importance_df['importance'].quantile([0.1, 0.25, 0.5, 0.75, 0.9]))
# 选择重要特征
selected_features = importance_df[importance_df['importance'] > threshold]['feature'].tolist()
# 筛选特征索引
try:
selected_indices = [features.index(f) for f in selected_features]
except ValueError as e:
print(f"❌ 特征选择错误: {str(e)}")
print("可能原因:特征列表中存在重复特征名")
# 自动生成唯一特征名
features = [f"feature_{i}" for i in range(len(features))]
selected_indices = [features.index(f) for f in selected_features]
# 筛选数据
X_train_selected = X_train[:, selected_indices]
X_test_selected = X_test[:, selected_indices]
return X_train_selected, X_test_selected, selected_features, importance_df
def evaluate_feature_importance(importance_df, model_name, save_dir):
"""可视化并保存特征重要性"""
plt.figure(figsize=(12, 8))
top_n = min(50, len(importance_df))
sns.barplot(x='importance', y='feature', data=importance_df.head(top_n))
plt.title(f'{model_name} - Top 30 重要特征')
plt.tight_layout()
plot_path = os.path.join(save_dir, f'{model_name}_feature_importance.png')
plt.savefig(plot_path)
plt.close()
print(f"特征重要性图已保存至: {plot_path}")
# --------------------------------------------------------------------
# 修改后的训练函数
def train_and_predict(model_class, X_train, y_train, X_test, hyperparameters, model_name="model"):
ensemble_predictions = defaultdict(list)
feature_importances = [] # 存储特征重要性
for iteration in range(hyperparameters['n_iterations']):
# [原有代码保持不变...]
print(f"\n=== 开始迭代 {iteration + 1}/{hyperparameters['n_iterations']} ===")
seed = 42 + iteration
# 模型初始化必须在此处完成
model = model_class(
n_estimators=hyperparameters['n_estimators'],
random_state=seed,
n_jobs=hyperparameters['n_jobs'],
max_depth=hyperparameters['max_depth']
)
model.fit(X_train, y_train)
# 保存模型
model_dir = "随机森林V3.1十_saved_models"
os.makedirs(model_dir, exist_ok=True) # 创建保存模型的目录
timestamp = datetime.datetime.now().strftime('%Y%m%d_%H%M%S') # 使用 datetime.datetime.now()
# model_filename = os.path.join(model_dir, f"{model_name}_iter{iteration}_{timestamp}.joblib")
model_filename = os.path.join(model_dir, f"{model_name}_iter{iteration}.joblib")
joblib.dump(model, model_filename) # 保存模型
print(f"模型已保存至: {model_filename}")
# 预测概率
proba = model.predict_proba(X_test)
for idx in range(len(proba)):
preds = proba[idx].argsort()[::-1] # 按概率降序排列
preds_top5 = preds[:3]
# print(f"样本 {idx} 的预测结果(前3): {preds_top5.tolist()}") # 打印前五个预测结果
ensemble_predictions[idx].extend(preds_top5.tolist()) # 将前五个预测结果保存到 ensemble_predictions
# === 新增:保存特征重要性 ===
feature_importances.append(model.feature_importances_)
importance_path = os.path.join("随机森林V3.1十_saved_models", f"{model_name}_iter{iteration}_importance.pkl")
with open(importance_path, 'wb') as f:
pickle.dump(model.feature_importances_, f)
# === 新增:计算平均特征重要性 ===
avg_importance = np.mean(feature_importances, axis=0)
return ensemble_predictions, avg_importance # 返回预测结果和特征重要性
# ===================== 修改后的主训练流程 =====================
def train_model_with_selection(model_class, X_train, y_train, X_test, features, hyperparams, model_name):
# 第一阶段:初始训练获取特征重要性
print(f"\n=== 第一阶段:初始训练 {model_name} ===")
predictions, avg_importance = train_and_predict(
model_class, X_train, y_train, X_test, hyperparams, model_name)
# 特征选择
X_train_selected, X_test_selected, selected_features, importance_df = select_features(
X_train, X_test, avg_importance, features)
# 保存重要性结果
importance_df.to_csv(f"{model_name}_feature_importance.csv", index=False)
evaluate_feature_importance(importance_df, model_name, DATA_dir)
# 第二阶段:使用筛选特征重新训练
print(f"\n=== 第二阶段:优化训练 {model_name} ===")
print(f"特征数量: {len(features)} → {len(selected_features)}")
predictions_selected, _ = train_and_predict(
model_class, X_train_selected, y_train, X_test_selected, hyperparams, f"{model_name}_selected")
return predictions_selected
hyperparameters = {
'n_iterations': 20, # 迭代次数
'n_estimators': 400, # 树的数量
'n_jobs': -1, # 使用所有核心
'max_depth': 10 # 最大深度
}
# 训练四个模型分别预测百位、十位、个位、区间
y_train_hundreds = Y_train[:, 0, 0]
y_train_tens = Y_train[:, 0, 1]
y_train_units = Y_train[:, 0, 2]
y_train_zone = Y_train[:, 0, 3]
# 初始化预测结果存储
ensemble_predictions = {
'hundreds': defaultdict(list),
'tens': defaultdict(list),
'units': defaultdict(list),
'zone': defaultdict(list)
}
# 训练四个模型
ensemble_predictions['hundreds'] = train_model_with_selection(
RandomForestClassifier, X_train_flat, y_train_hundreds, X_test_flat,
features, hyperparameters, "hundreds_model")
ensemble_predictions['tens'] = train_model_with_selection(
RandomForestClassifier, X_train_flat, y_train_tens, X_test_flat,
features, hyperparameters, "tens_model")
ensemble_predictions['units'] = train_model_with_selection(
RandomForestClassifier, X_train_flat, y_train_units, X_test_flat,
features, hyperparameters, "units_model")
ensemble_predictions['zone'] = train_model_with_selection(
RandomForestClassifier, X_train_flat, y_train_zone, X_test_flat,
features, hyperparameters, "zone_model")
# ============================================================训练测试完之后,想看看预测效果,搞了一些组合,看哪些组合收益最高。这里的K值就是取预测的前几个值,我是取概率最大的前五个值。按照每一注2元的成本,收益是1040元。
#######################################
# 二、组合覆盖率 & 收益的新增逻辑(多K) #
#######################################
# -- 组合定义:单独、两两、三三、四个 --
combo_definitions = {
'hundreds': ('hundreds',),
'tens': ('tens',),
'units': ('units',),
'zone': ('zone',),
'hundreds+tens': ('hundreds','tens'),
'hundreds+units': ('hundreds','units'),
'tens+units': ('tens','units'),
'hundreds+zone': ('hundreds','zone'),
'tens+zone': ('tens','zone'),
'units+zone': ('units','zone'),
'hundreds+tens+units': ('hundreds','tens','units'),
'hundreds+tens+zone': ('hundreds','tens','zone'),
'hundreds+units+zone': ('hundreds','units','zone'),
'tens+units+zone': ('tens','units','zone'),
'hundreds+tens+units+zone': ('hundreds','tens','units','zone'),
}
def to_num(h,t,u):
return h*100 + t*10 + u
def build_bet_numbers(sample_topk_keys, combo_slots):
"""和之前一样,略"""
if 'hundreds' in combo_slots:
h_candidates = sample_topk_keys['hundreds']
else:
h_candidates = range(10)
if 'tens' in combo_slots:
t_candidates = sample_topk_keys['tens']
else:
t_candidates = range(10)
if 'units' in combo_slots:
u_candidates = sample_topk_keys['units']
else:
u_candidates = range(10)
if 'zone' in combo_slots:
z_candidates = sample_topk_keys['zone']
else:
z_candidates = range(1,9)
bet_nums = []
for num in range(1000):
h = num // 100
t = (num // 10) % 10
u = num % 10
z = map_to_zone(num)
if (h in h_candidates) and (t in t_candidates) and (u in u_candidates) and (z in z_candidates):
bet_nums.append(num)
return bet_nums
def compute_bet_outcome(real_num, real_zone, bet_nums):
"""2元/注, 若覆盖 => 中奖1040"""
num_bets = len(bet_nums)
cost = num_bets * 2
covered = (real_num in bet_nums)
reward = 1040 if covered else 0
net = reward - cost
return {
'num_bets': num_bets,
'cost': cost,
'reward': reward,
'covered': covered,
'net_profit': net
}
# 用于存放所有 (sample × combo × K) 的明细
all_combo_results = []
# 对组合做一个全局 summary => combo->k-> {samples, covered_count, cost_sum, reward_sum, net_sum}
# 或者直接在后面聚合也可以,这里先示例
summary_all = [] # 用 DataFrame 方式保存
for res in final_results:
idx = res['sample_index']
date_str = res['date']
tv = res['true_values']
real_num = to_num(tv['hundreds'], tv['tens'], tv['units'])
real_zone = tv['zone']
# 'all_topk_keys' => { k: {'hundreds': [...], 'tens': [...], 'units': [...], 'zone': [...]}, ... }
topk_candidates = res['all_topk_keys']
# 针对 1..MAX_TOP_K
for k, topk_map in topk_candidates.items():
# 针对每个组合
for combo_name, combo_slots in combo_definitions.items():
bet_nums = build_bet_numbers(topk_map, combo_slots)
outcome = compute_bet_outcome(real_num, real_zone, bet_nums)
record = {
'sample_index': idx,
'date': date_str,
'K': k, # 关键:区分这是Top1还是Top2...TopK
'combo': combo_name,
'true_num': real_num,
'true_zone': real_zone,
'num_bets': outcome['num_bets'],
'cost': outcome['cost'],
'reward': outcome['reward'],
'covered': outcome['covered'],
'net_profit': outcome['net_profit']
}
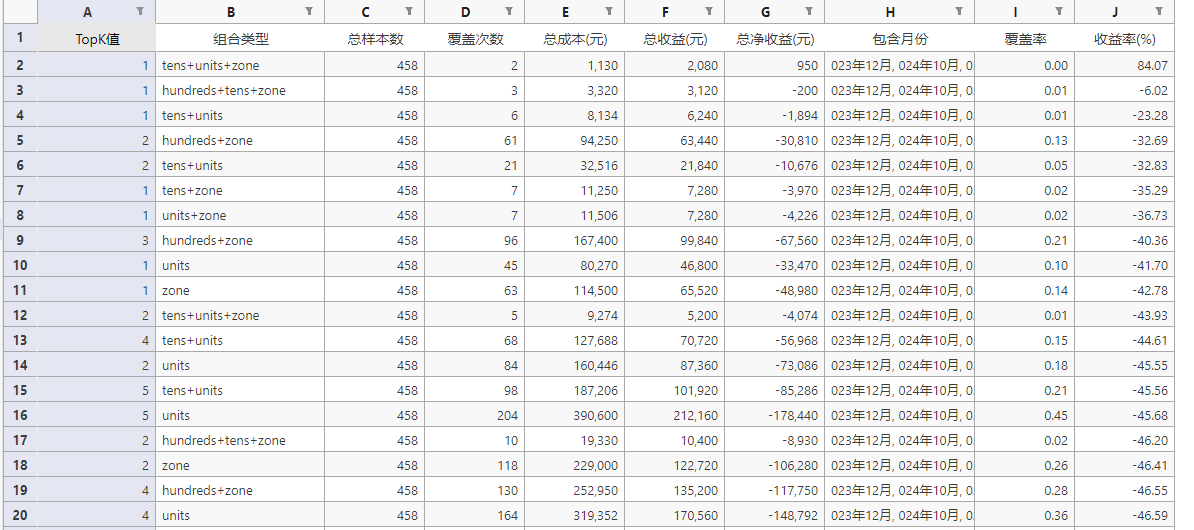
all_combo_results.append(record)这是部分结果图:
2023年12月的预测结果
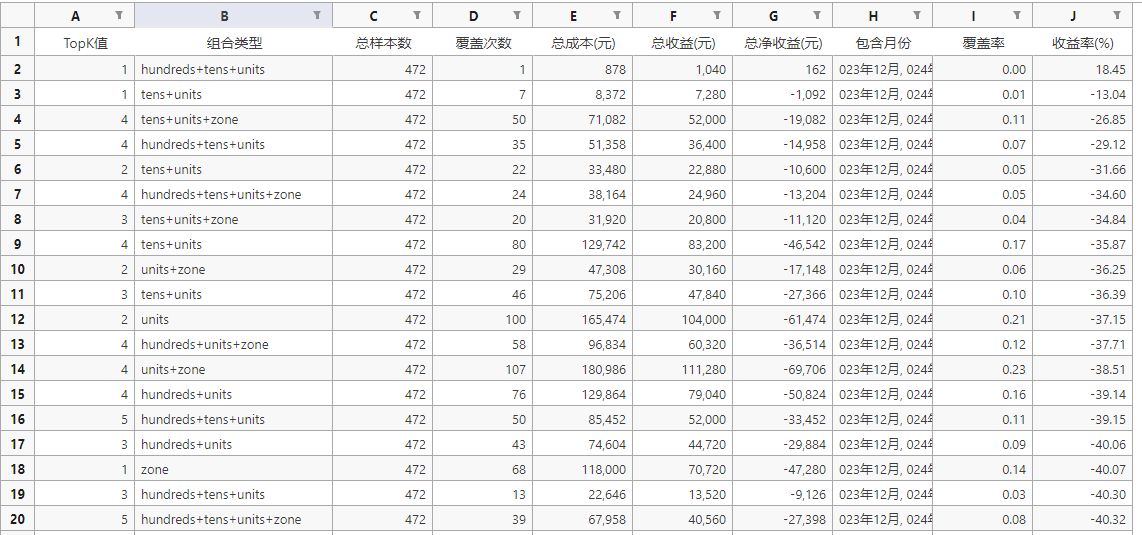
2024年1月的预测结果
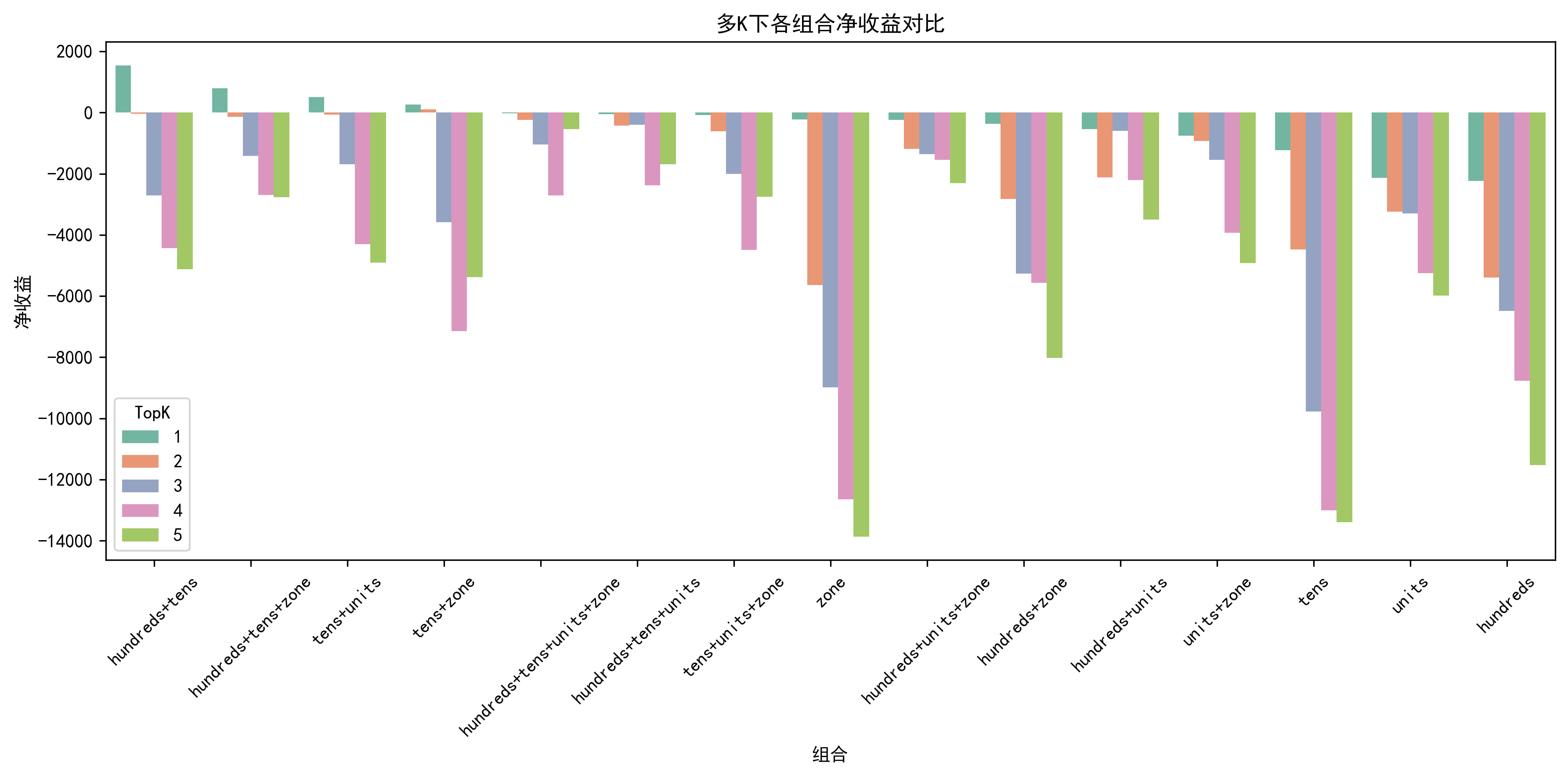
2024年12月的预测结果
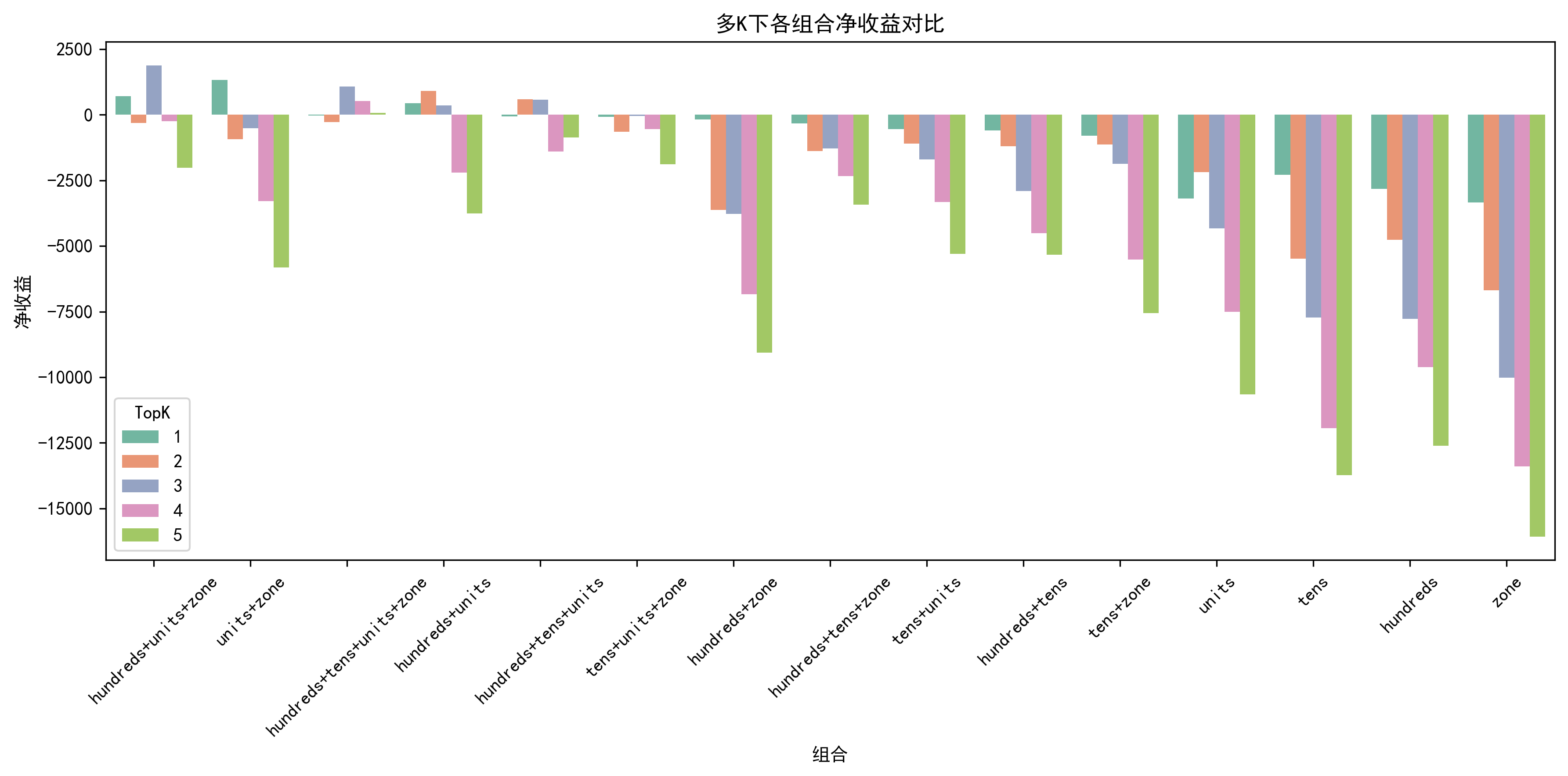
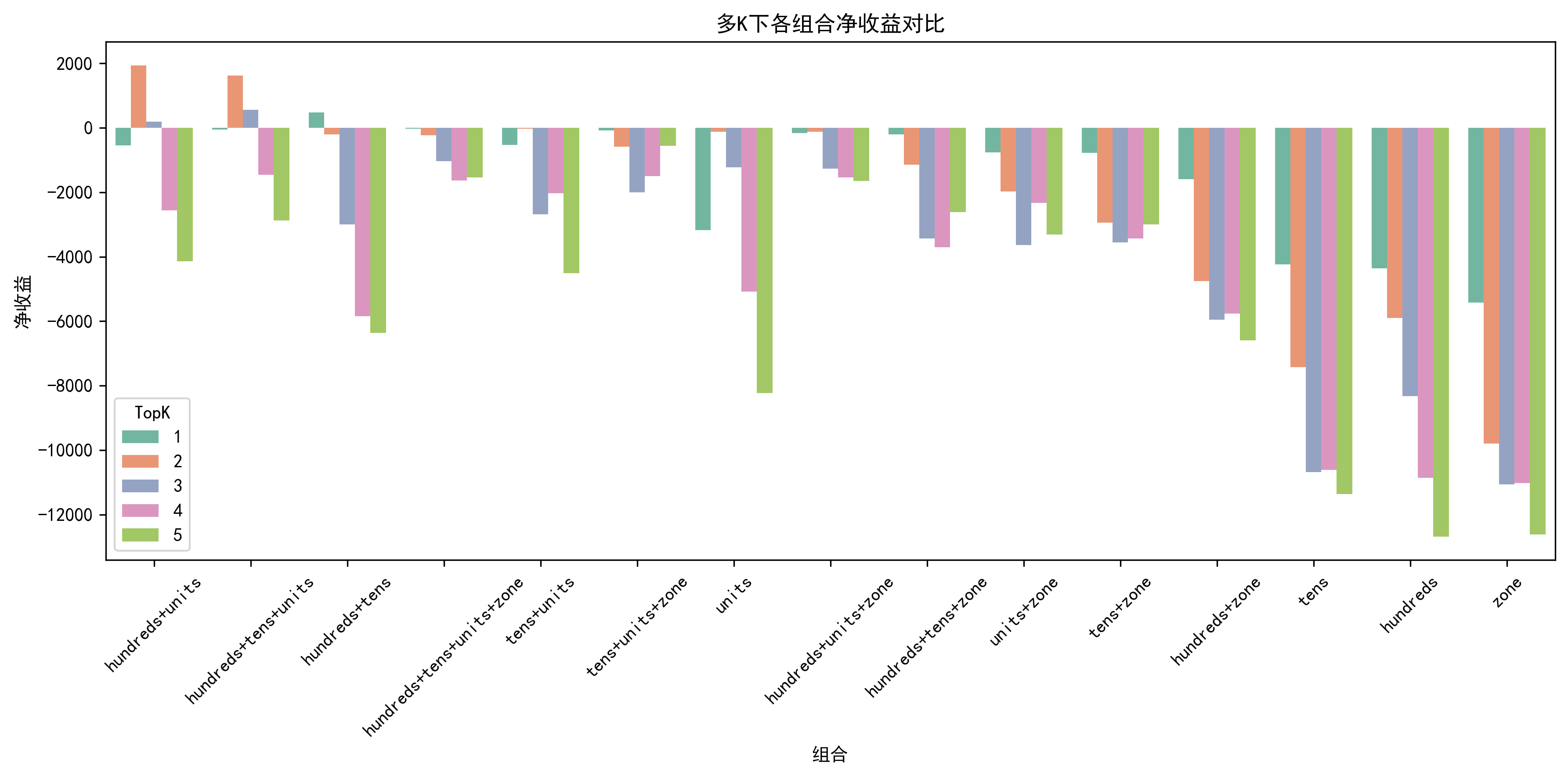
2025年2月的预测结果
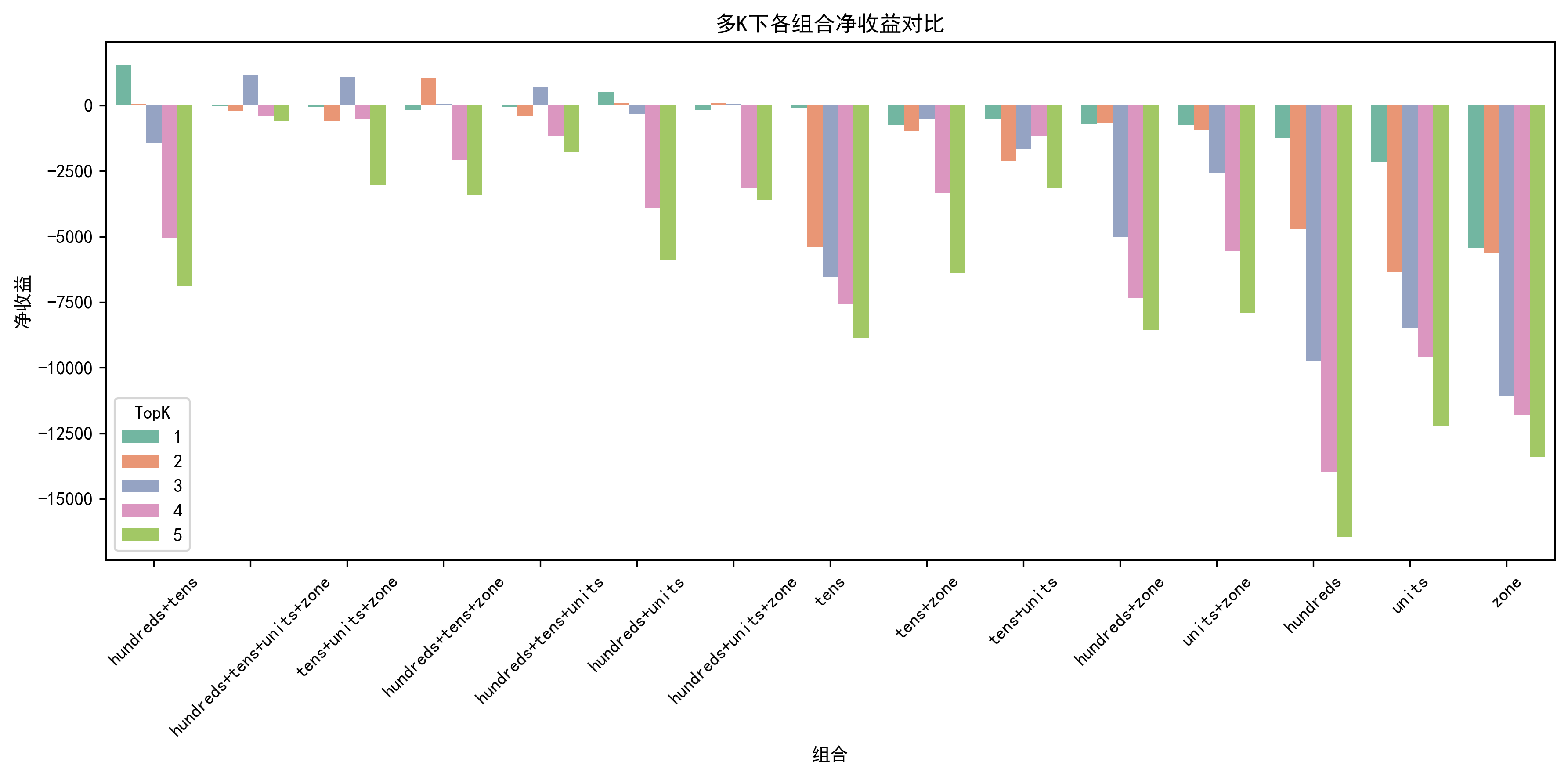
可以看到,每个月基本上都有部分组合能实现正收益,但是收益也不会很高。还有一个关键的点就是,每个月能实现正收益的组合不能提前知道,纯属运气了。再者,很多时候也就是一个月中1次就能实现正收益,要是没中,就会变成负收益,噪声成分大。所以我统计汇总了15个月458期的测试数据,计算出15个月汇总能实现盈利的组合,最终发现只有一种组合,也是靠着一两注盈利,才有这么高的收益。这里有个比较重要的特征工程就是在线STL时序分解,对预测的结果影响比较大,不加这个特征,每个月那就没有能盈利的组合了,盈利能力大幅下降。
仅供参考,欢迎讨论交流。
PS:以上代码均由deepseek+豆包完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









