






比如我们常用的map就可以当做一个缓存的容器来使用,伪代码如下
data = map.get(“缓存”);//从缓存加载数据
If(data == null){
data = db.load(id);//从数据库加载数据
map.put(id,data);//保存到 cache 中
}
//有的话直接返回数据
return data;
这种方式在单体服务下是没有问题的,但是在分布式系统下,就会出现问题,比如:
商品服务
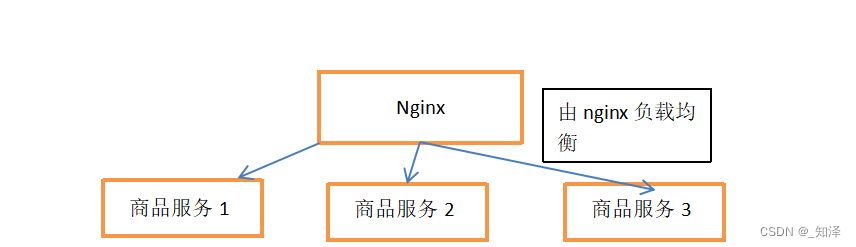
可能你的本地缓存只是在商品服务1中,但是如果n下次请求来了之后,由ginx下次负载均衡到商品服务2,那么你的本地缓存就会失效。
解决的方法就是添加一个缓存中间件,比如redis,让每个服务都去访问redis如下:
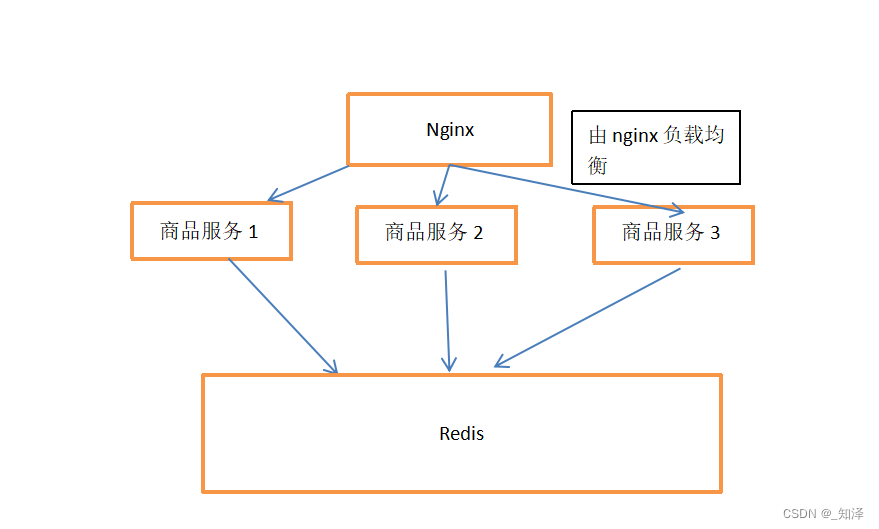
都去访问同一个redis,那么就可以在分布式使用缓存。
高并发的概念:
二、大并发下缓存失效问题
大并发读情况下的缓存失效问题;
1、缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数
据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次
请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是
漏洞。
解决:
缓存空结果、并且设置短的过期时间(未来如果有数据就会有数据,因为有过期时间,查询数据库有数据,就不造成该数据在缓存中一直是null了)。
2、缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失
效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决:
原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的
重复率就会降低,就很难引发集体失效的事件。
3、缓存击穿
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,
是一种非常“热点”的数据。
这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所
有对这个 key 的数据查询都落到 db,我们称为缓存击穿。
解决:
加锁(这个锁要是分布式锁,本地锁是锁不住的)
下期:加锁的问题
缓存一致性问题(博文链接:https://blog.csdn.net/cristianoxm/article/details/118936327)。
(为什么要有过期时间?
这种方式有个问题就是如果第4行之前出现错误,执行不到第4行的话,锁会释放不了,然后锁死。
//试图获得锁 1.if (redisClient.setnx(xx,xx)){ 2. do xxxxx something 3. //释放锁 4. redisClient.del(xx) 5.}
//试图获得锁 1.if (redisClient.setnx(xx,xx)){ 2. //设置过期时间 3. expire xx 5 4. do xxxxx something 5. //释放锁 6. redisClient.del(xx) 7.}
给锁设置过期时间,这样一来,即使执行不到第6行(释放锁的哪一行),等过期时间到了,也会自动释放锁。
这个方案明面上一看没有问题,但是,加锁和设置过期时间不是原子操作,所以,相当于没有做。。
)
数据库的数据和缓存的数据是不可能一致的,数据分为最终一致和强一致两类。强一致:不可以使用缓存缓存能做的只能保证数据的最终一致性。我们能做的只能是尽可能的保证数据的一致性。不管是先删库再删缓存 还是 先删缓存再删库,都可能出现数据不一致的情况,因为读和写操作是并发的,我们没办法保证他们的先后顺序。具体应对策略根据业务需求来制订。首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列,分布式锁。
本地缓存与分布式缓存
1、适用场景
1)即时性、数据一致性要求不高,比如博客的热帖更新,就可以使用。
2)访问量大,更新频率不高的数据(读多,写少)
举例:电商类应用,商品分类,商品列表等适合缓存并添加一个,商家发布商品一般五分钟是可以看到的
2、分布式缓存
若干台服务器共享一个缓存,
缓存中使用json存放数据,优点:可以跨语言解析数据,因为直接放入信息,Java会自动序列化,Java自己的,别的语言拿不到。
使用缓存有:
因为缓存的一致性,本地缓存与分布式缓存,缓存穿透,缓存击穿,缓存雪崩
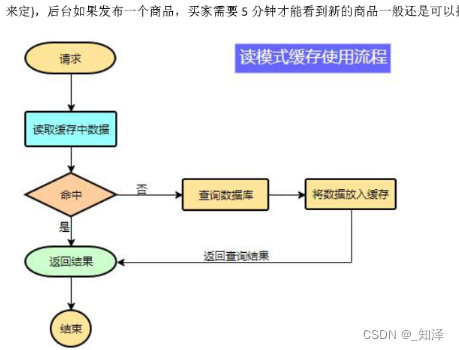
缓存流程:
下面链接讲解缓存击穿:https://blog.csdn.net/sanyaoxu_2/article/details/79472465
https://blog.csdn.net/qq_38826019/article/details/115026820















 2177
2177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









