







 PageRank是Google创始人拉里·佩奇提出的一种衡量网页重要性的技术。该算法通过网页间的超链接关系进行计算。在示例中,介绍了带有阻尼系数的PageRank计算过程,以及如何在Python中实现这一算法。经过多次迭代,确定网页的PageRank值,直到达到预设的误差阈值或达到最大循环次数。
PageRank是Google创始人拉里·佩奇提出的一种衡量网页重要性的技术。该算法通过网页间的超链接关系进行计算。在示例中,介绍了带有阻尼系数的PageRank计算过程,以及如何在Python中实现这一算法。经过多次迭代,确定网页的PageRank值,直到达到预设的误差阈值或达到最大循环次数。
一、简介
PageRank,又称网页排名、谷歌左侧排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。
假设一个由4个网页组成的群体:A,B,C和D。如果所有页面都只链接至A,那么A的PR(PageRank)值将是B,C及D的Pagerank总和。
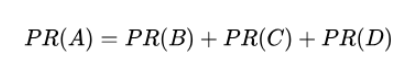
重新假设B链接到A和C,C只链接到A,并且D链接到全部其他的3个页面。一个页面总共只有一票。所以B给A和C每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
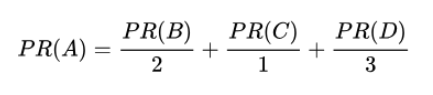

阻尼系数是根据上网者使用浏览器书签的平均频率估算而得,通常d=0.85。
二、计算实例

为了便于计算,我们假设每个页面的PR初始值为1,d为0.5。

下面是迭代计算12轮之后,各个页面的PR值:

那么什么时候,迭代结束哪?
比如上次迭代结果与本次迭代结果小于某个误差,我们结束程序运行;
比如还可以设置最大循环次数。
三、Python实现
'''
读取数据:
A B
A C
B C
C A
注意:在code中我们是每一次epoch更新一轮,
与前面的手动计算不同。
'''
import numpy as np
if __name__ == '__main__':
# 读入有向图,存储边
file = open( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3680
3680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









