






Java技术快速突击网站:http://www.susan.net.cn
在我们日常的工作中,经常需要做对象的拷贝或转化,例如在传递参数时,把入参的DTO转化为PO存入数据库,在返回前端时把PO再转化为VO。如果再分的细一点,可能还会有DO(Domain Object),TO(Transfer Object) ,BO(business object)等对象,随着业务的划分越来越细,对象的拷贝工作也越来越频繁,所以本文就来梳理一下常用的对象拷贝工具和它们的差异。
常用的工具大概有以下几种:
-
Apache BeanUtils
-
Spring BeanUtils
-
cglib BeanCopier
-
Hutool BeanUtil
-
Mapstruct
-
Dozer
准备工作,创建两个类PO和DTO:
@Data
public class OrderPO {
Integer id;
String orderNumber;
List<String> proId;
}
@Data
public class OrderDTO {
int id;
String orderNumber;
List<String> proId;
}
01
Apache BeanUtils
引入依赖坐标:
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
进行测试,初始化PO对象,并创建DTO空对象,使用BeanUtils进行:
@org.junit.Test
public void test(){
OrderPO orderPO=new OrderPO();
orderPO.setId(1);
orderPO.setOrderNumber("orderNumber");
ArrayList<String> list = new ArrayList<String>() {{
add("1");
add("2");
}};
orderPO.setProId(list);
OrderDTO orderDTO=new OrderDTO();
BeanUtils.copyProperties(orderDTO,orderPO);
}
打印两个对象,具有相同的属性:
OrderPO(id=1, orderNumber=orderNumber, proId=[1, 2])
OrderDTO(id=1, orderNumber=orderNumber, proId=[1, 2])
可以看出,在Bean中具有相同名称的属性分别是基本数据类型和包装类时,比如分别是int和Integer时,可以正常进行拷贝。那么再深究一点,拷贝Bean过程中,使用的是深拷贝还是浅拷贝呢?
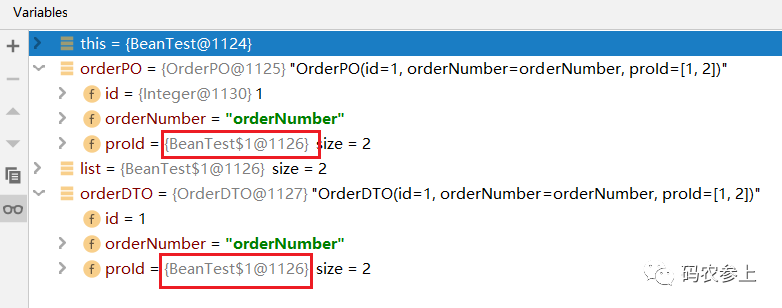
两个List对象使用的是同一个对象,因此在拷贝中,如果存在引用对象,那么使用的是浅拷贝。在完成拷贝后,如果再修改这个对象:
list.add("3");
log.info(orderDTO.getProId());
再次打印DTO对象,发现即使不再次重新拷贝,修改的值也会被添加过去
OrderDTO(id=1, orderNumber=orderNumber, proId=[1, 2, 3])
02
Spring BeanUtils
如果使用的spring项目时不需要单独引入依赖,单独使用时需要引入坐标:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>5.2.2.RELEASE</version>
</dependency>
使用方式与apache的BeanUtils方法名相同,但参数顺序相反,第一个参数是源对象,第二个参数是目标对象:
BeanUtils.copyProperties(orderPO,orderDTO);
过程省略,这里使用的还是浅拷贝。spring的BeanUtils还提供了额外的方法,这个可变参数的方法可以忽略某些属性进行拷贝:
void copyProperties(Object source, Object target, String... ignoreProperties);
忽略orderNumber属性进行拷贝:
BeanUtils.copyProperties(orderPO,orderDTO,"orderNumber");
输出结果:
OrderPO(id=1, orderNumber=orderNumber, proId=[1, 2])
OrderDTO(id=1, orderNumber=null, proId=[1, 2])
此外,在阿里巴巴的开发手册中,强制避免使用apache BeanUtils进行拷贝,建议使用Spring BeanUtils或下面要介绍的BeanCopier。主要原因还是在于Spring并没有与 apache一样对反射做了过多校验,另外Spring BeanUtils内部使用了缓存,加快转换的速度。此外,由于我们的大多项目已经集成了Spring ,如果没有其他特殊的需求,直接使用它的BeanUtils就能满足我们的基本需求。
03
cglib BeanCopier
如果工程内含有spring-core包的依赖,也不需要额外引入依赖,否则需要引入坐标:
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
使用示例:
BeanCopier beanCopier = BeanCopier.create(
orderPO.getClass(),
orderDTO.getClass(), false);
beanCopier.copy(orderPO,orderDTO,null);
测试结果:
OrderPO(id=1, orderNumber=orderNumber, proId=[1, 2])
OrderDTO(id=0, orderNumber=orderNumber, proId=[1, 2])
在上面的例子中,id字段没有被正常拷贝,两个字段不同的是在PO中使用的是包装类型Integer,但DTO中使用的是基本类型int。因此,使用BeanCopier时,如果存在基本类型和包装类,是无法被正常拷贝,改为相同类型后才能被正常拷贝。另外,BeanCopier使用的仍然是浅拷贝,验证过程大家可以自己进行实验。
04
Hutool BeanUtil
hutool是个人平常使用比较频繁的一个工具包,对文件、加密解密、转码、正则、线程、XML等JDK方法进行封装,并且也可以进行对象的拷贝。在使用前引入坐标:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.1.0</version>
</dependency>
使用方法如下,并且使用的也是浅拷贝方式:
BeanUtil.copyProperties(orderPO,orderDTO);
和Spring BeanUtils相同,也可以进行属性的忽略:
void copyProperties(Object source, Object target, String... ignoreProperties);
除此之外,hutool的BeanUtil还提供了很多其他实用的方法:
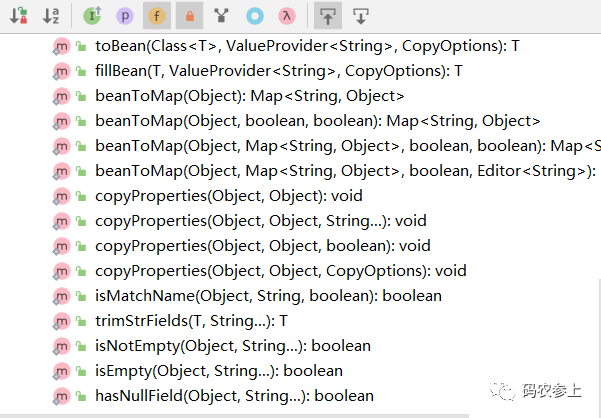
个人在使用中感觉Bean和Map的互相转换还是很常用的,有时在使用Map接收参数时,后期能够很方便的把Map转换为Bean
05
Mapstruct
Mapstruct的使用和上面几种方式有些不同,因为上面的几种方式,spring和apache,hutool使用的都是反射,cglib是基于字节码文件的操作,都是在都代码运行期间动态执行的,但是Mapstruct不同,它在编译期间就生成了 Bean属性复制的代码,运行期间就无需使用反射或者字节码技术,所以具有很高的性能。
使用Mapstruct需要需要引入下面的依赖:
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-jdk8</artifactId>
<version>1.3.0.Final</version>
</dependency>
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>1.3.0.Final</version>
</dependency>
需要额外写一个接口来实现:
@Mapper
public interface ConvertMapper {
OrderDTO po2Dto(OrderPO orderPO);
}
这里的@Mapper注解不是用于mybatis的注解,而是org.mapstruct.Mapper。使用起来也非常简单:
ConvertMapper mapper = Mappers.getMapper(ConvertMapper.class);
OrderDTO orderDTO=mapper.po2Dto(orderPO);
查看编译后的target目录,编译时将我们定义的ConvertMapper 接口,生成了ConvertMapperImpl实现类,并实现了po2Dto方法。看一下编译生成的文件:
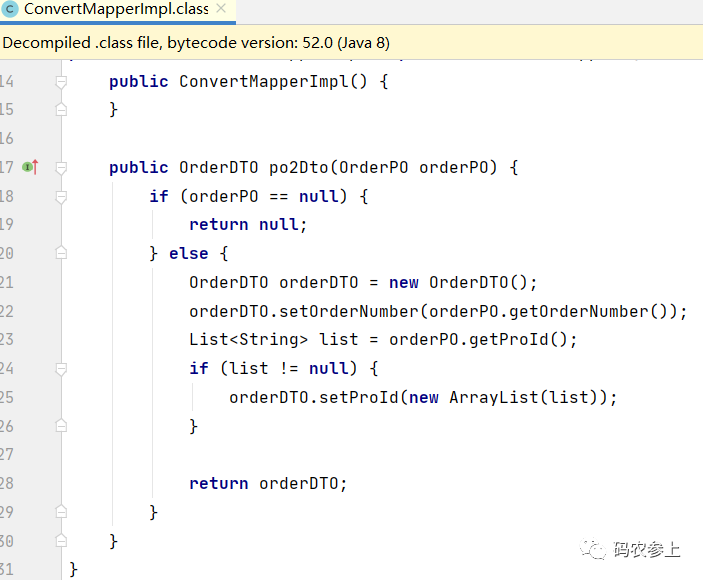
可以看到方法中为每一个属性生成了set方法,并且对于引用对象,生成了一个新的对象,使用深拷贝的方式,所以修改之前的引用对象,这里的值也不会改变。并且,这种使用set/get的方式比使用反射的速度更快。
06
Dozer
Dozer是一个Bean到Bean映射器,它以递归方式将数据从一个对象复制到另一个对象,并且这些Bean可以具有不同的复杂类型。使用前引入依赖坐标:
<dependency>
<groupId>net.sf.dozer</groupId>
<artifactId>dozer</artifactId>
<version>5.4.0</version>
</dependency>
调用方式非常简单:
DozerBeanMapper mapper = new DozerBeanMapper();
OrderDTO orderDTO=mapper.map(orderPO,OrderDTO.class);
查看运行时生成的对象,可以看见使用的深拷贝的方式:
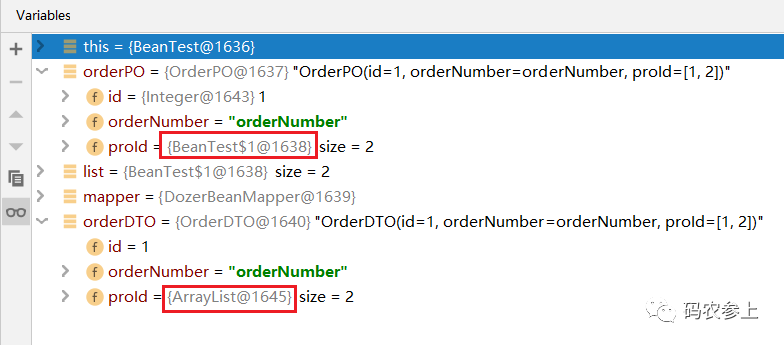
除此之外,还可以配置不同属性名称的映射,修改DTO和PO,在PO中添加一个name属性,在DTO中添加value属性:
@Data
public class OrderPO {
Integer id;
String orderNumber;
List<String> proId;
String name;
}
@Data
public class OrderDTO {
int id;
String orderNumber;
List<String> proId;
String value;
}
新建一个配置文件,在mapping中可以添加字段的映射关系:
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozer.sourceforge.net" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozer.sourceforge.net
http://dozer.sourceforge.net/schema/beanmapping.xsd">
<mapping>
<class-a>com.cn.entity.OrderPO</class-a>
<class-b>com.cn.entity.OrderDTO</class-b>
<field>
<a>name</a>
<b>value</b>
</field>
</mapping>
</mappings>DozerBeanMapper使用上面的配置文件进行配置,再次拷贝对象:
...
orderPO.setName("hydra");
DozerBeanMapper mapper = new DozerBeanMapper();
List<String> mappingFiles = new ArrayList<>();
mappingFiles.add("dozer.xml");
mapper.setMappingFiles(mappingFiles);
OrderDTO orderDTO=mapper.map(orderPO,OrderDTO.class);
查看测试结果,不同名称的字段也可以进行拷贝了:
OrderPO(id=1, orderNumber=orderNumber, proId=[1, 2], name=hydra)
OrderDTO(id=1, orderNumber=orderNumber, proId=[1, 2], value=hydra)
如果业务场景中的Bean具有很多不同的属性,这么配置起来还是很麻烦的,需要额外手写很多xml文件。以上就是工作中常被接触到的几种对象拷贝工具,在具体的使用中,更多的要结合拷贝效率等要求,以及工作场景中需要使用的是深拷贝还是浅拷贝等诸多因素。
欢迎大家加入苏三的知识星球【Java突击队】,一起学习。
星球中有很多独家的干货内容,比如:Java后端学习路线,分享实战项目,源码分析,百万级系统设计,系统上线的一些坑,MQ专题,真实面试题,每天都会回答大家提出的问题。
这几天星球开通了3个优质专栏:痛点问题、高频面试题 和 性能优化。
















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











