







 本文深入介绍了决策树算法,包括其分类原理、信息熵和信息增益的概念,以及如何在泰坦尼克号乘客生存预测案例中应用。通过示例解释了如何选择最佳特征,并探讨了决策树的可视化和优缺点,强调了其在实际决策中的应用价值。
本文深入介绍了决策树算法,包括其分类原理、信息熵和信息增益的概念,以及如何在泰坦尼克号乘客生存预测案例中应用。通过示例解释了如何选择最佳特征,并探讨了决策树的可视化和优缺点,强调了其在实际决策中的应用价值。
认识决策树
决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
决策树算法构造决策树来发现数据中蕴涵的分类规则.如何构造精度高、规模小的决策树是决策树算法的核心内容。决策树构造可以分两步进行。第一步,决策树的生成:由训练样本集生成决策树的过程。一般情况下,训练样本数据集是根据实际需要有历史的、有一定综合程度的,用于数据分析处理的数据集。第二步,决策树的剪枝:决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修下的过程,主要是用新的样本数据集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预衡准确性的分枝剪除。
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
通过一个对话例子
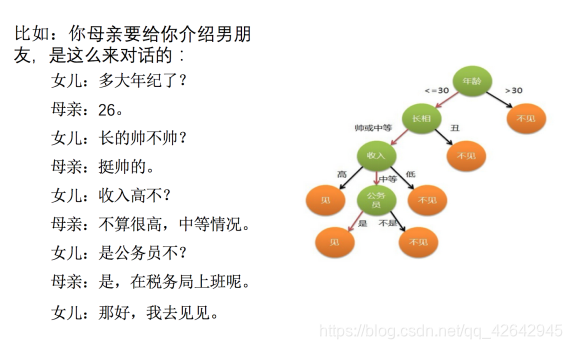
想一想这个女生为什么把年龄放在最上面判断!!!!!!!!!
决策树分类原理详解
为了更好理解决策树具体怎么分类的,我们通过一个问题例子?
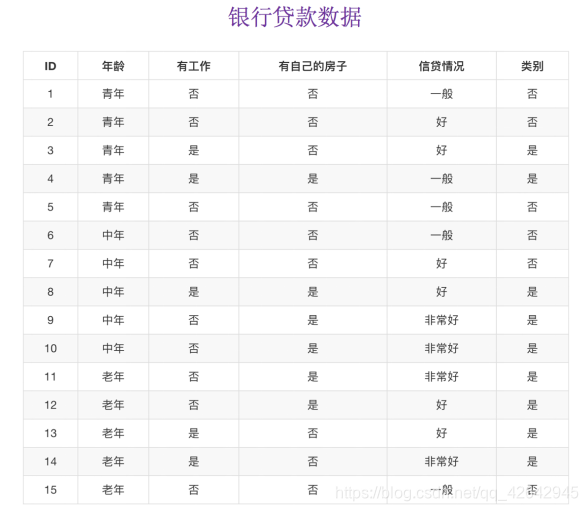
问题:如何对这些客户进行分类预测?你是如何去划分?
有可能你的划分是这样的
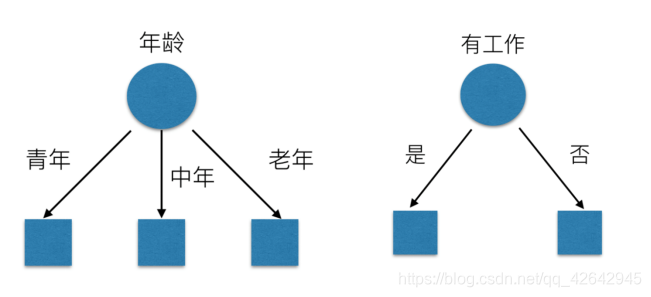
那么我们怎么知道这些特征哪个更好放在最上面,那么决策树的真是划分是这样的
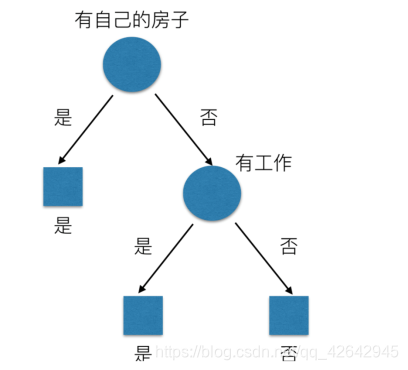
原理
信息熵、信息增益等
需要用到信息论的知识!!!问题:通过例子引入信息熵
信息熵的定义
H的专业术语称之为信息熵,单位为比特。
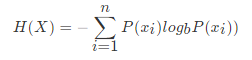
例如:16个数bool中,9个是,6个否
是的概率:p(x是)= 9/15
否的概率:p(x否)= 6/15
信息熵:H(x) = -(9/15log(9/15)+6/15log(6/15))
决策树的划分依据之一------信息增益
- 定义与公式
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
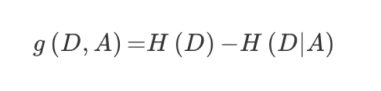
公式的详细解释:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1557
1557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









