







一、引言
数据清洗过程中常见的数据处理方式之一是:数据匹配,其中包括精确匹配与模糊匹配。精确匹配主要是指:需要匹配的两列数据数值或字符串完全一致,而在实际处理中需要匹配的两个变量并不总是存在完美的连接,此时就需要对两变量进行模糊匹配,如变量A(红富士苹果)与变量B(苹果(红富士))这类相似却并不完全相同的名称匹配。
二、精确匹配
stata中常用的精确匹配函数为:merge函数,可实现一对多、多对一、一对一、多对多,具体参考stata软件中的help merge。
excel中常用的精确匹配函数为:VLOOKUP函数,最近发现一款较为好用的插件(方方格子),如果处理数据为中文且数据量不大,建议使用,如果为英文且数据量万以上不建议使用,匹配效果有偏差且excel容易崩溃。
三、stata模糊匹配
本节介绍stata模糊匹配常用到的matchit 函数。主要包括:函数中参数的含义、代码、实例、报错原因以及解决方法。
1.matchit函数
官网给出的解释为:根据相似的文本模式匹配两个列或两个数据集。Raffo, J., & Lhuillery, S. (2009):matchit通过采用不同的基于字符串的匹配技术,在两个不同的文本字符串之间提供相似性评分。执行操作后会返回一个新的匹配程度变量( similscore ),取值为 0 到 1 ,similscore 为 1 时代表完全匹配,取值越小,相似度越低,匹配程度是一个相对量,不同的匹配方法通常产生不同的相似度评分,详见help matchit。
2.代码
如果是同一表单中的两列数据,一对一模糊匹配,可直接使用
matchit varname1 varname2 [, options]
如果是两个表单中的两列数据匹配,要相对复杂一些
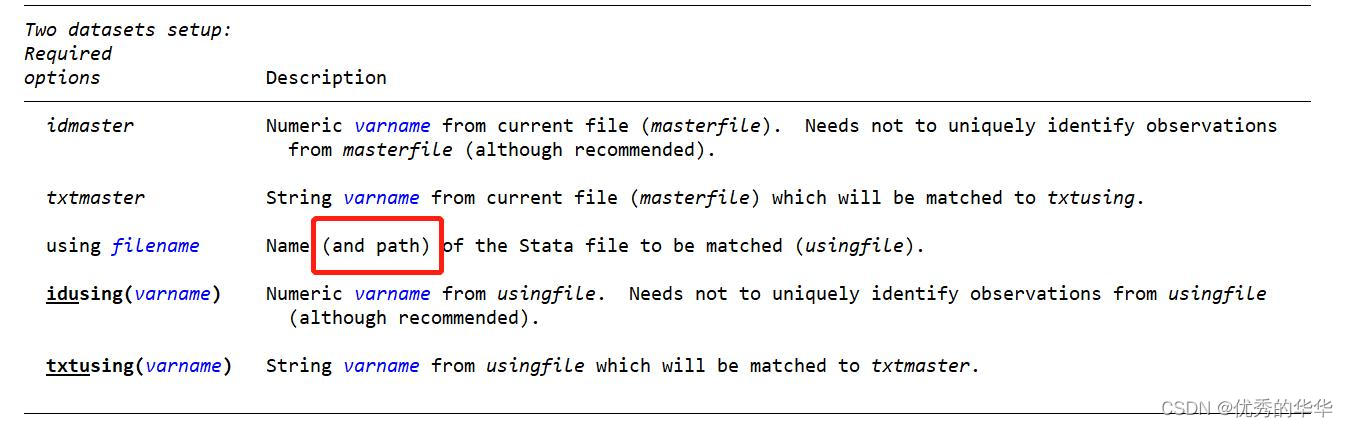
matchit idmaster txtmaster using filename.dta , idusing (varname) txtusing(varname) [options]

注:方括号中的单词不可当作代码,不能直接粘贴到代码行运行。
notation:varname1、 varname2、分别代表同一表单中匹配源与待匹配列的变量名称。idmaster指的是来自当前文件(主文件)的数值型变量名。txtmaster 指的是当前文件(主文件)中要进行匹配的字符型变量名。(注:idmaster 应该唯一识别txtmaster)。idusing(varname)与 txtusing(varname)同理,分别指来自于filename.dta数据集中待匹配的数值型变量以及字符型变量。
3.实例:模糊匹配两个数据集中的公司名称
(1)安装加权包:freqindex
ssc install freqindex, replace
ssc install matchit, replace(2)将xlsx文件转化为dta
安装xls2dta命令
ssc install xls2dta,replace创建文件夹,改变缺省路径。
capture mkdir e:/xls2dta
cd e:/xls2dta此时会看到E盘中会产生一个空的xls2dta文件夹,将待转化的两个表格放在此文件夹下。
转化:
ssc install filelist,replace
xls2dta,replace recursive : import excel using e:/xls2dta此时,在该文件夹下的表格都会生成dta版本。具体的其它转化详见https://blog.csdn.net/crack6677/article/details/105346854。
(3)匹配
use sampleA.dta, replace
matchit IDmaster sub_nameA using sampleB.dta , idusing (IDusing) txtusing(sub_nameB)其中sampleA.dta属于源文件,IDmaster是源变量中的唯一标识符(数值型),sub_nameA源变量的变量名称,sampleB.dta属于待匹配文件,相对的IDusing是数值型唯一标识符,sub_nameB则为待匹配变量的变量名。详见:https://www.lianxh.cn/news/7aba3c217a016.html
(4)报错及解决办法(第一次用stata者重点)
第一个:variable IDmaster not found
检查数据导入是否直接从“文件——导入——excel电子表格”中导入stata软件的,如果是则需要检查数据第一行是否没有被识别成为变量名,如果默认导入的话系统给出的变量名会是很直接的A、B、C、。。。
建议使用以下代码,将excel中第一行定义为变量名称,其中sampleA为excel文件名(注意本文sampleA已经在默认路径下,前文提到了更改路径的方法,请参考,如果出错,试试加上路径)。
import excel sampleA,first更简单的方法:不用IDmaster作为变量名,直接使用A。
第二个:no; dataset in memory has changed since last saved
出现此问题的原因很简单:数据集冲突了,之前引入了sampleA.dta,后续引入sampleB.dta数据集就会报错,只需要在引入新数据集之前加一行代码即可:
clear第三个:weights not allowed
出现此错误的原因是:把官网给出代方括号和方括号里面的option也加到了运行代码里面,去掉就可以了。
第四个:XXXX not found
仔细看一下,官网给出的参数解析:待匹配数据集需要加上路径,查阅网友解答发现,stata在同时引入两个文件时好像比较麻烦,建议加上路径,避免出错。
四、本人代码
matchit A B using E:\xls2dta\sampleB.dta , idusing (A) txtusing(B)五、结果
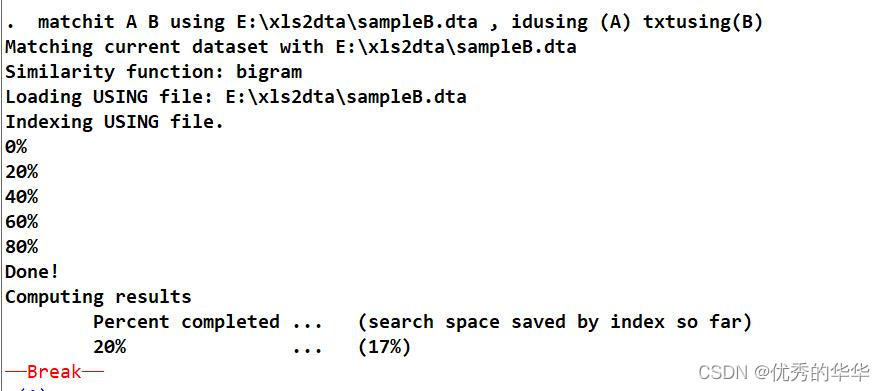
注:Break ,本人选择运行终止了,不属于报错范围。不详细的地方建议参考连享会https://www.lianxh.cn/news/7aba3c217a016.html,与官方帮助文档help matchit。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









