







1. 研究问题
如何结合全局上下文信息,提高在ill-posed regions(比如遮挡,重复纹理,弱纹理,高光反射等区域)的视差估计精度。
2. 研究方法
针对上述研究问题,作者提出了一个端到端的网络PSM-Net,该网络的两个核心模块是SPP模块和堆叠的沙漏3D CNN模块。其中,SPP模块(金字塔池化模块)通过聚合不同尺度和位置的特征信息(上下文)来构造4D成本量,而堆叠的沙漏3D CNN模块通过skip connection重复的进行自上而下和自下而上的过程,进一步提高全局上下文信息的利用率,并结合中间监督对成本量进行正则化。
2.1 Network Architecture
PSMNet由CNN特征提取,SPP模块,4D 成本量,3D CNN模块组成。如下图所示。
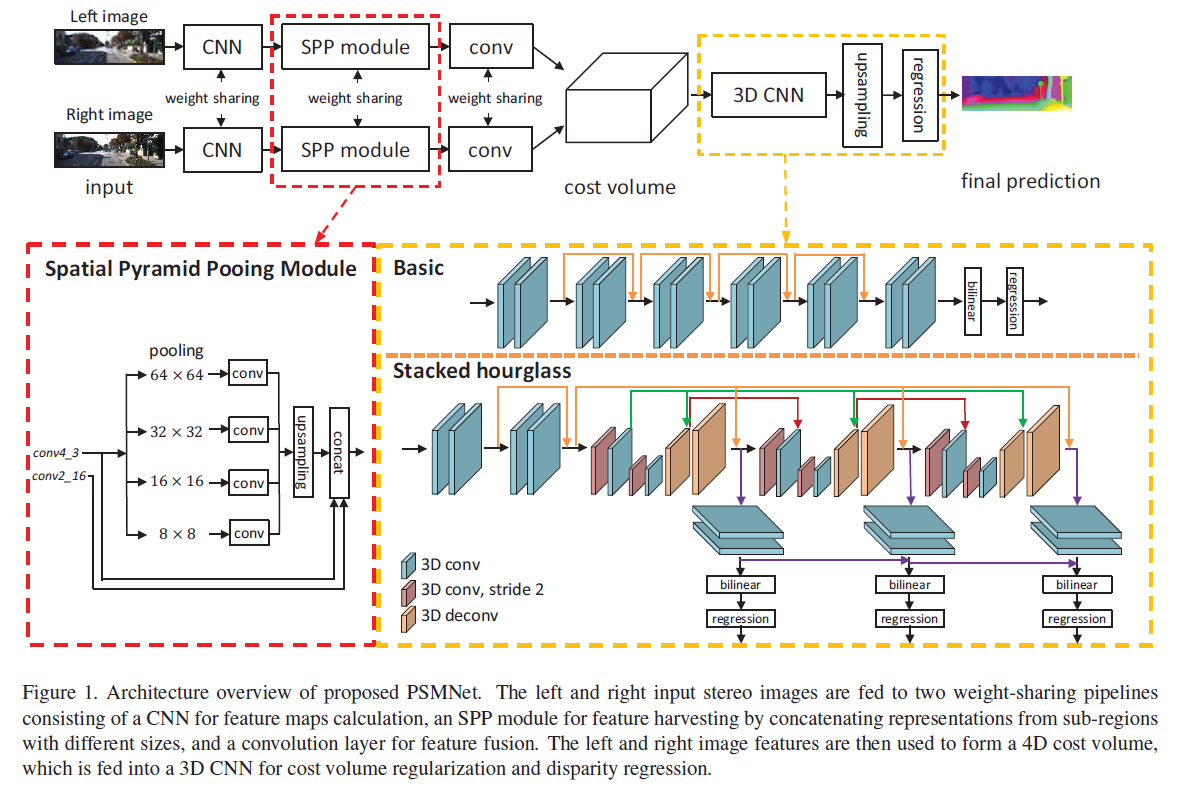
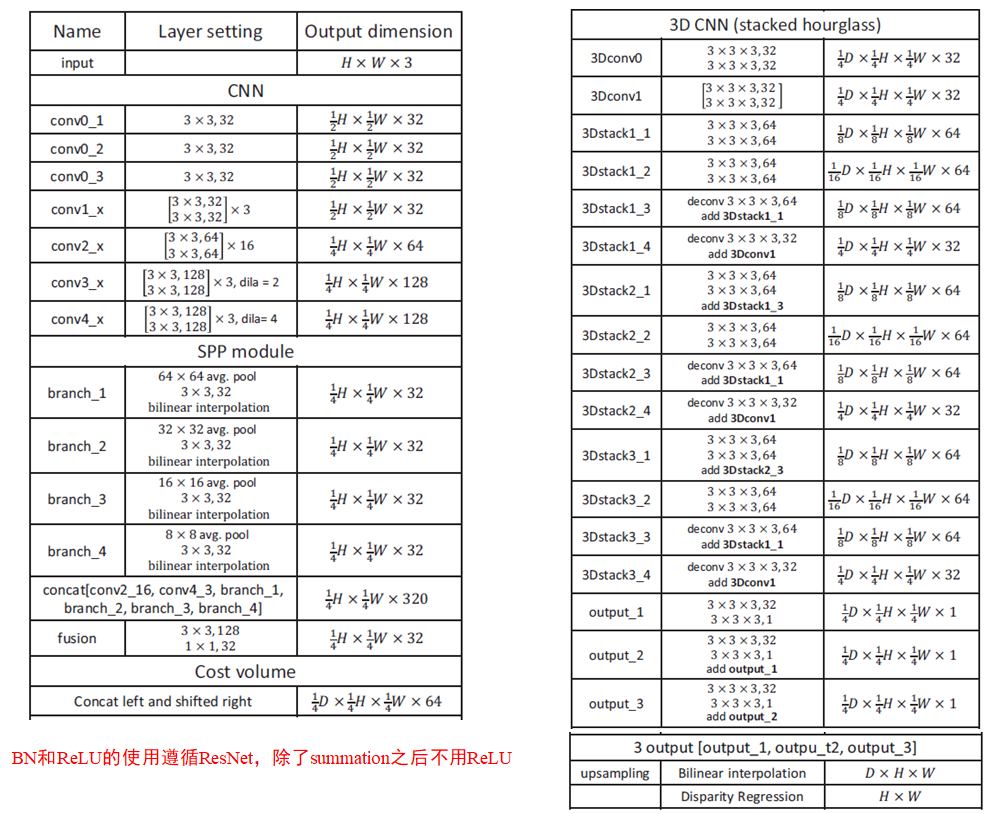
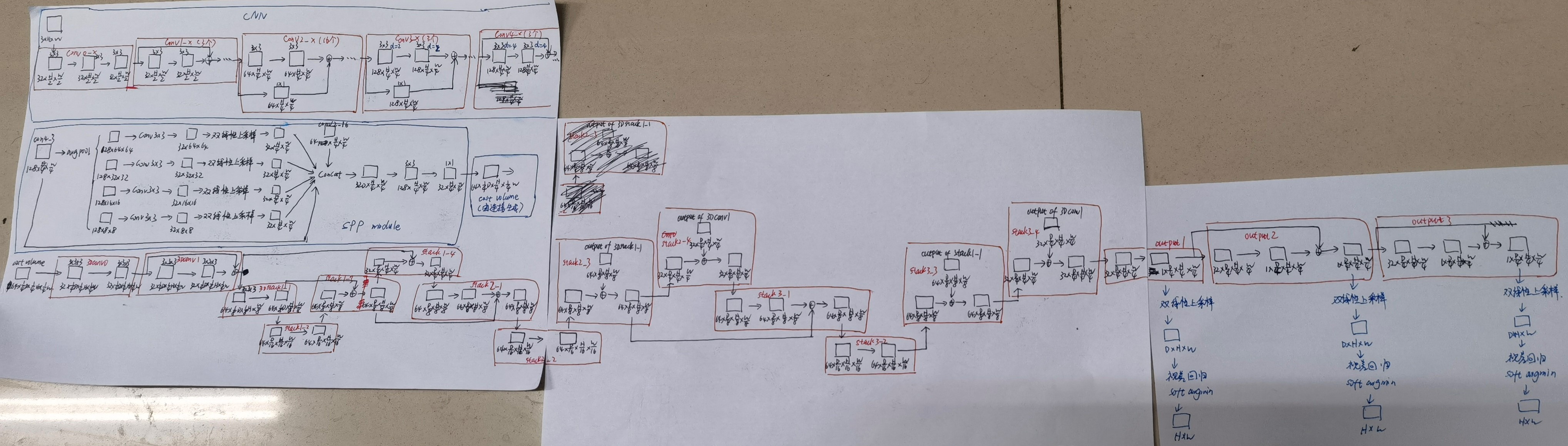
- 特征提取模块借鉴ResNet和空洞卷积,提取精细的局部特征,输出 1 / 4 1/4 1/4原始分辨率的特征图。
- 空间金字塔模块聚合多尺度上下文信息,形成表达能力更强的特征表示。
- 在各个视差下连接左右特征向量,构建4D成本量。
- 堆叠的沙漏3D CNN模块结合中间监督,对成本量进行正则化。
- soft argmin回归视差图。
2.2 Spatial Pyramid Pooling Module
借鉴PSPNet中的4级金字塔池化模块,捕获分层上下文信息,然后通过卷积、上采样到相同分辨率,再经过concat聚合多尺度上下文信息。
2.3 3D CNN
为了沿视差维度和空间维度聚合特征信息,我们提出了两种用于成本量正则化的 3D CNN 架构:基本和堆叠沙漏架构。
(1)基本架构:包含十二个 3 × 3 × 3 3 × 3 × 3 3×3×3 卷积层。 然后我们通过双线性插值将成本量上采样回大小 H × W × D H×W×D H×W×D。最后,我们应用回归来计算大小为 H × W H × W H×W 的视差图。
(2)堆叠沙漏架构:具有三个主要的沙漏网络,每个沙漏网络都会生成一个视差图。也就是说,堆叠沙漏架构具有三个输出和损失(Loss 1、Loss 2 和 Loss 3)。在训练阶段,总损失计算为三个损失的加权和。在测试阶段,最终的视差图是三个输出中的最后一个。 堆叠沙漏架构可以学习更多的上下文信息。该架构借鉴了GC-Net的编码器-解码器架构。
2.4 视差回归

2.5 损失

3. 实验结果
训练:
- Adam优化器, β 1 = 0.9 \beta_1=0.9 β1=0.9, β 2 = 0.999 \beta_2=0.999 β2=0.999。
- 数据预处理:颜色归一化。代码中使用了与ImageNet一样的颜色归一化。
__imagenet_stats = {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}
- 训练期间,图像被随机裁剪为大小 H = 256 和 W = 512。最大视差 (D) 设置为 192。
- 使用场景流数据集从头开始训练我们的模型,一共训练10 个Epoch,恒定学习率为 0.001。
- 对于 Scene Flow,训练后的模型直接用于测试。对于 KITTI,我们使用在场景流数据训练的模型,在 KITTI 训练集训练 300 个 epoch 进行微调。学习率在前 200 个时期从 0.001 开始,在其余 100 个时期从 0.0001 开始。
- 批量大小设置为 12,在四个 nNvidia Titan-Xp GPU上进行训练,每个GPU上分配 3 个数据。
数据集文件结构:
SceneFlowData
-----driving_frames_cleanpass
----------35mm_focallength
---------------scene_backwards
--------------------fast
-------------------------left+img
-------------------------right+img
--------------------slow
-------------------------left+img
-------------------------right+img
---------------scene_forwards
--------------------fast
-------------------------left+img
-------------------------right+img
--------------------slow
-------------------------left+img
-------------------------right+img
----------15mm_focallength
---------------scene_backwards
--------------------fast
-------------------------left+img
-------------------------right+img
--------------------slow
-------------------------left+img
-------------------------right+img
---------------scene_forwards
--------------------fast
-------------------------left+img
-------------------------right+img
--------------------slow
-------------------------left+img
-------------------------right+img
-----driving_disparity
---------------scene_backwards
--------------------fast
-------------------------left+disp
--------------------slow
-------------------------left+disp
---------------scene_forwards
--------------------fast
-------------------------left+disp
--------------------slow
-------------------------left+disp
-----monkaa_frames_cleanpass
----------dd+left+im
----------dd+right+im
-----monkaa_disparity
----------dd+left+disp
-----frames_cleanpass
----------TRAIN
---------------A
-------------------ff+left+im
-------------------ff+right+im
---------------B
-------------------ff+left+im
-------------------ff+right+im
---------------C
-------------------ff+left+im
-------------------ff+right+im
----------TEST
---------------A
-------------------ff+left+im
-------------------ff+right+im
---------------B
-------------------ff+left+im
-------------------ff+right+im
---------------C
-------------------ff+left+im
-------------------ff+right+im
-----frames_disparity
----------TRAIN
---------------A
-------------------ff+left+disp
---------------B
-------------------ff+left+disp
---------------C
-------------------ff+left+disp
----------TEST
---------------A
-------------------ff+left+disp
---------------B
-------------------ff+left+disp
---------------C
-------------------ff+left+disp
KITTI 2015 training data folder
-----image_2
-----image_3
-----disp_occ_0
-----disp_occ_1
注意:'_10'结尾的图像是训练集,'_11'结尾的图像是测试集
KITTI 2012 training data folder
-----colored_0
-----colored_1
-----disp_occ
注意:'_10'结尾的图像是训练集,'_11'结尾的图像是测试集
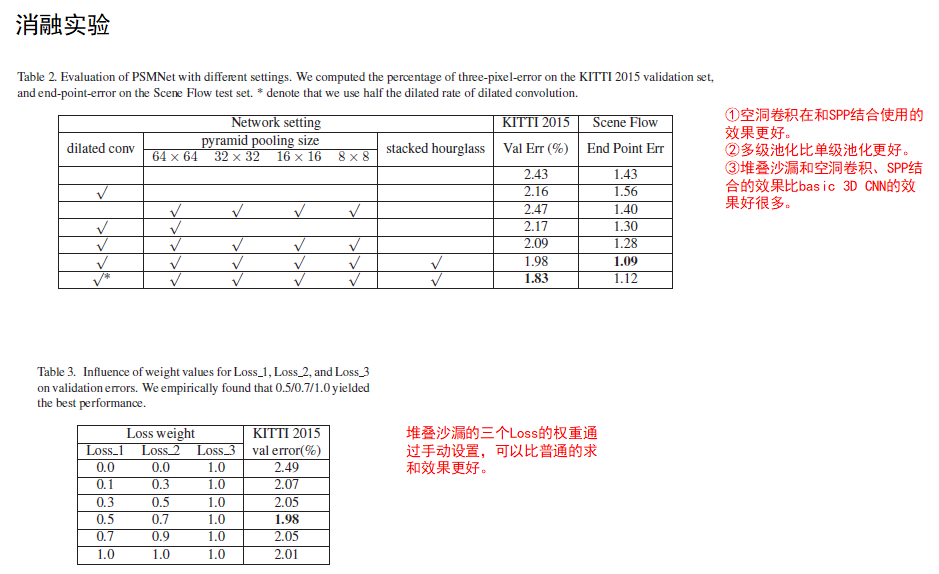
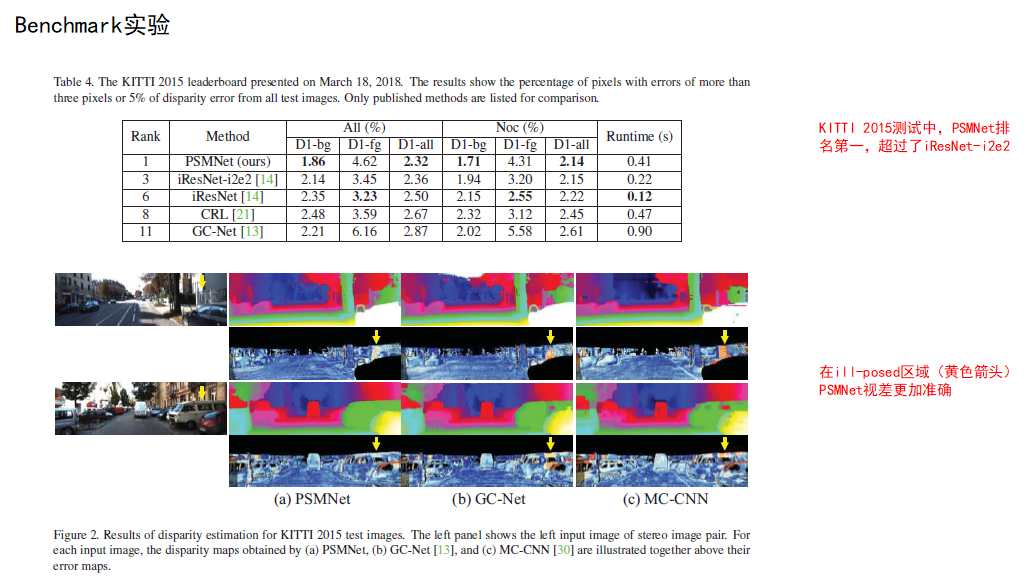
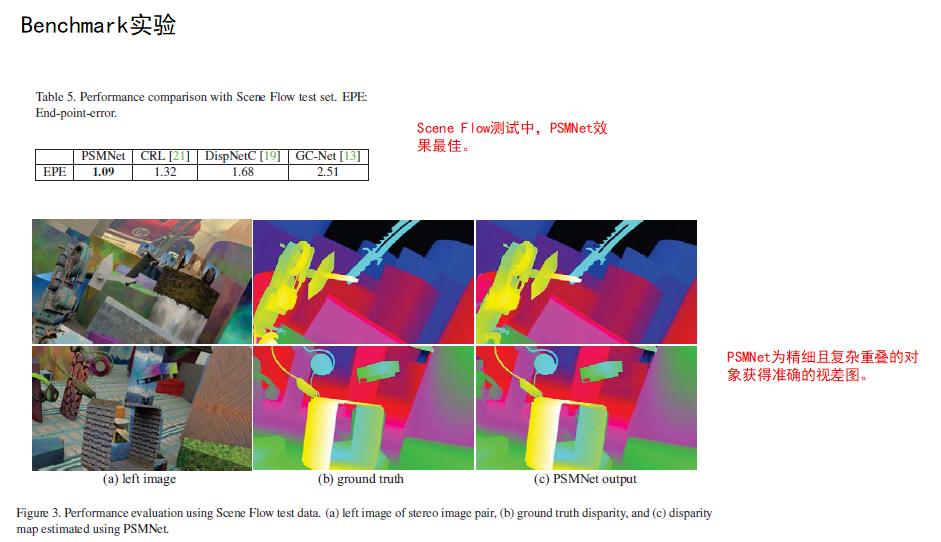
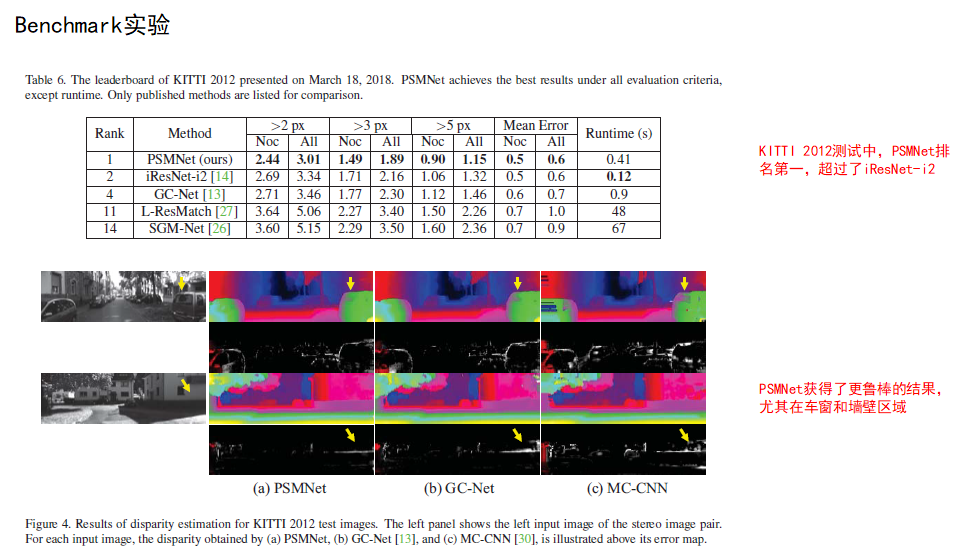
4. 结论
(1)所提出的PSMNet 能够很好的捕获上下文信息,显著提高了不适定区域(病态区域)的视差估计精度。
(2)PSMNet在 2018 年 3 月 18 日之前在 KITTI 2012 和 2015 排行榜中排名第一。
5. 局限性
(1)运行时间较长,相当于iResNet运行时间的4倍,iResNet-i2运行时间的2倍。
(2)重复的上采样和下采样的过程会导致薄结构和边缘的模糊。(GA-Net反映的)。
6. 启发
(1)在语义分割中,上下文信息的聚合很重要,这篇文章就是受到这个启发,从而采用SPP模块和stacked hourglass模块来利用多尺度的上下文信息,以提高视差估计的精度。
(2)利用多尺度的信息有利于提高视差估计的精度。















 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









